Hidden-Shot: Towards One-Shot Task Generalization for Low-Level Vision Generalist Models
Pith reviewed 2026-07-03 20:44 UTC · model grok-4.3
The pith
Hidden-Shot lets low-level vision generalist models adapt to new tasks from one example image.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
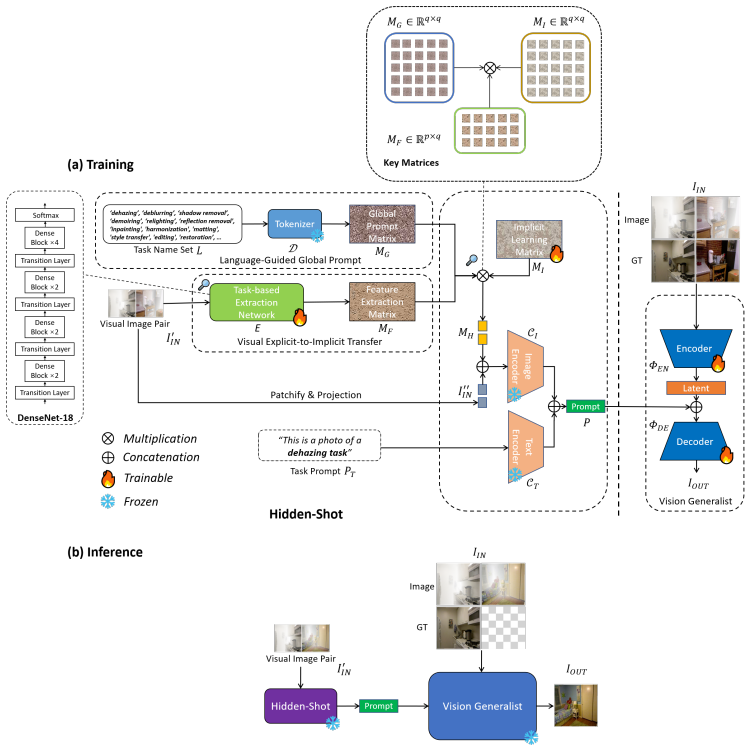
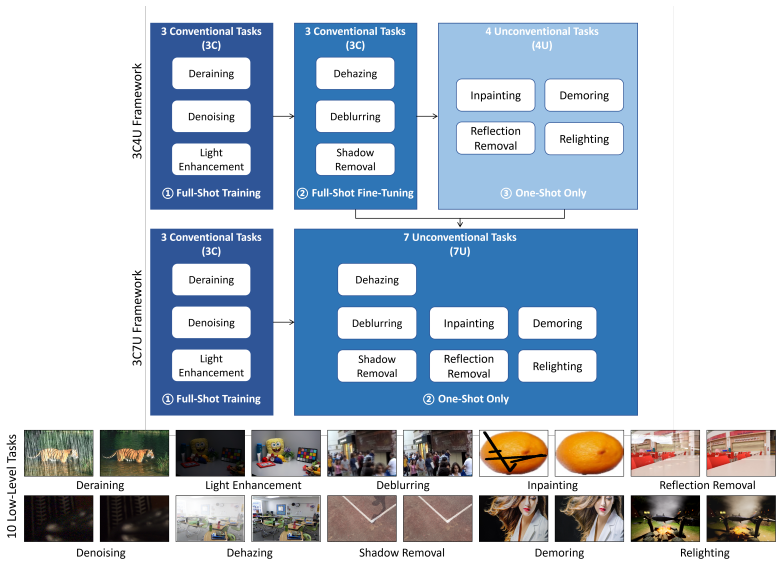
The central claim is that the Hidden-Shot implicit prompt mechanism extracts visual task-based information from a single example image, applies a global task-aware textural prompt, and selectively merges the implicit information with in-task processing information, allowing the original generalist model to achieve one-shot generalization on unseen low-level tasks through direct, low-cost injection with minimal architectural change. Experiments on seven and ten datasets show the method beats the prior state-of-the-art generalist under the 3C4U framework for retraining and the 3C7U framework for training from scratch, while keeping performance steady on the original tasks.
What carries the argument
Hidden-Shot, the implicit prompt mechanism that extracts task information from one image and merges it into the generalist model's processing via a task-aware textural prompt.
If this is right
- The model outperforms prior generalist models on one-shot adaptation to four unconventional tasks after retraining on three conventional ones.
- It also outperforms on seven unconventional tasks when trained from scratch alongside three conventional ones.
- Performance on the original trained tasks stays consistent rather than degrading.
- The approach works through cost-effective direct injection that leaves the base architecture almost untouched.
Where Pith is reading between the lines
- The same single-example extraction idea could let deployed models accept user-provided reference images for quick custom adaptation in editing tools.
- The C/U assessment framework supplies a concrete template other researchers could reuse to test generalization claims in future generalist work.
- If implicit task signals prove reliable, similar merging steps might reduce reliance on explicit task identifiers across a wider range of vision architectures.
Load-bearing premise
The implicit visual task-based information extracted from a single example image is sufficient to drive meaningful adaptation in the generalist model without task-specific labels or architecture changes.
What would settle it
A head-to-head test on the 3C7U framework in which the Hidden-Shot model shows no gain over the unmodified baseline on the seven unconventional tasks would falsify the central claim.
Figures


read the original abstract
Despite the intense engagement surrounding low-level vision generalist models, their effectiveness in zero/few-shot scenarios beyond learned tasks remains unverified. The primary challenge of developing an ideal generalist lies in achieving the ability to generalize from new unseen tasks, which also can be assessed by matched quantitative criteria. Existing methods have made some progress in prompt engineering but have not systematically explored this gap across a wide range of low-level visual tasks. Stimulated by the problem, we propose Hidden-Shot, an implicit prompt mechanism aimed at exploring low-level task adaptation in a vision generalist model. Specifically, the method extracts implicit visual task-based information, utilizes a global task-aware textural prompt, and selectively merges implicit information with in-task processing information to enhance one-shot capabilities in new tasks. The overall design performs direct injection in a cost-effective manner, while minimally altering the architecture of the original generalist model. Additionally, we introduce a data-driven evaluation framework termed C/U assessment to cover two basic scenarios, 3C4U (3 conventional and 4 unconventional tasks) for retraining existing models and 3C7U (3 conventional and 7 unconventional tasks) for training from scratch, as a comprehensive assessment to systematically test the generalization ability of low-level generalist models. Experiments on seven and ten datasets outperform the state-of-the-art vision generalist model, respectively verified by 3C4U and 3C7U framework. Our presented Hidden-Shot approach demonstrates superior performance on one-shot new tasks while maintaining consistent performance on existing tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hidden-Shot, an implicit prompt mechanism for enabling one-shot task generalization in low-level vision generalist models. The method extracts implicit visual task-based information from a single example image, employs a global task-aware textural prompt, and selectively merges this information with the in-task processing to enhance adaptation to new tasks without significant architectural changes. The authors introduce the C/U assessment framework, including the 3C4U (3 conventional and 4 unconventional tasks) and 3C7U (3 conventional and 7 unconventional tasks) suites, to systematically evaluate generalization capabilities. Experiments on seven and ten datasets respectively demonstrate outperformance over the state-of-the-art vision generalist model while maintaining consistent performance on existing tasks.
Significance. If the empirical results hold, this work could be significant for the field of low-level vision by providing a practical approach to task adaptation in generalist models using only one example image. The introduction of a data-driven evaluation framework for assessing one-shot generalization on both conventional and unconventional tasks fills a gap in the current literature and could serve as a standard for future evaluations. The cost-effective design that minimally alters the original model architecture is a practical strength.
minor comments (3)
- [Abstract] Abstract: The abstract claims outperformance on the 3C4U and 3C7U frameworks but does not provide any quantitative numbers, error bars, dataset details, or ablation results. Including key performance metrics in the abstract would strengthen the presentation of the central claims.
- [Abstract] Abstract: The term 'textural prompt' appears to be a possible typo for 'textual prompt'; please verify the intended terminology.
- [Method] The description of the selective merging mechanism and the global task-aware prompt is high-level in the provided summary; expanding on implementation details in the method section would improve reproducibility and clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive summary, positive assessment of significance, and recommendation of minor revision. No specific major comments were listed in the report.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical proposal of the Hidden-Shot method for one-shot task generalization in low-level vision models, with no mathematical derivation chain, first-principles predictions, or equations that could reduce to inputs by construction. Claims rest on experimental outperformance under the newly introduced C/U assessment framework (3C4U/3C7U), which is presented as external to the method itself rather than derived from it. No self-citations, fitted parameters renamed as predictions, or ansatzes are load-bearing in the provided description, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J.Lu, C.Clark, R.Zellers, R.Mottaghi, A.Kembhavi, Unified-io: Auni- fied model for vision, language, and multi-modal tasks, in: The Eleventh International Conference on Learning Representations, 2022
2022
-
[2]
P. Wang, A. Yang, R. Men, J. Lin, S. Bai, Z. Li, J. Ma, C. Zhou, J. Zhou, H. Yang, Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework, in: International Con- ference on Machine Learning, PMLR, 2022, pp. 23318–23340
2022
-
[3]
T. Chen, S. Saxena, L. Li, T.-Y. Lin, D. J. Fleet, G. E. Hinton, A uni- fied sequence interface for vision tasks, Advances in Neural Information Processing Systems 35 (2022) 31333–31346
2022
-
[4]
K. He, X. Chen, S. Xie, Y. Li, P. Dollár, R. Girshick, Masked autoen- coders are scalable vision learners, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 16000– 16009
2022
-
[5]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., Language models arefew-shotlearners, Advancesinneuralinformationprocessingsystems 33 (2020) 1877–1901
2020
-
[6]
A. Bar, Y. Gandelsman, T. Darrell, A. Globerson, A. Efros, Visual prompting via image inpainting, Advances in Neural Information Pro- cessing Systems 35 (2022) 25005–25017
2022
-
[7]
6830–6839
X.Wang, W.Wang, Y.Cao, C.Shen, T.Huang, Imagesspeakinimages: A generalist painter for in-context visual learning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 6830–6839. 23
2023
- [8]
-
[9]
Y. Liu, X. Chen, X. Ma, X. Wang, J. Zhou, Y. Qiao, C. Dong, Unifying image processing as visual prompting question answering, in: Proceed- ings of the 41st International Conference on Machine Learning, 2024, pp. 30873–30891
2024
-
[10]
Potlapalli, S
V. Potlapalli, S. W. Zamir, S. H. Khan, F. Shahbaz Khan, Promptir: Prompting for all-in-one image restoration, Advances in Neural Infor- mation Processing Systems 36 (2023) 71275–71293
2023
-
[11]
M. V. Conde, G. Geigle, R. Timofte, Instructir: High-quality image restoration following human instructions, in: European Conference on Computer Vision, Springer, 2024, pp. 1–21
2024
-
[12]
H. Yu, I. Mineyev, L. R. Varshney, J. A. Evans, Learning from one and only one shot, npj Artificial Intelligence 1 (1) (2025) 13
2025
-
[13]
D.Pereg, One-shotimagerestoration, in: EuropeanConferenceonCom- puter Vision, Springer, 2024, pp. 34–50
2024
-
[14]
X. Chen, Y. Liu, Y. Pu, W. Zhang, J. Zhou, Y. Qiao, C. Dong, Learning a low-level vision generalist via visual task prompt, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 2671– 2680
2024
-
[15]
S. Wang, J. Zhang, J. Huang, F. Zhao, Image-free pre-training for low- level vision, in: Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 8825–8834
2024
- [16]
-
[17]
D. Shi, S. Huang, Image dehazing algorithm based on deep transfer learning and local mean adaptation, Scientific Reports 15 (1) (2025) 27956. 24
2025
-
[18]
Y. Liu, J. He, J. Gu, X. Kong, Y. Qiao, C. Dong, Degae: A new pre- trainingparadigmforlow-levelvision, in: ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 23292–23303
2023
-
[19]
H. Duan, X. Min, S. Wu, W. Shen, G. Zhai, Uniprocessor: a text- induced unified low-level image processor, in: European Conference on Computer Vision, Springer, 2024, pp. 180–199
2024
-
[20]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, P. J. Liu, Exploring the limits of transfer learning with a unified text-to-text transformer, Journal of machine learning research 21 (140) (2020) 1–67
2020
-
[21]
Kolesnikov, A
A. Kolesnikov, A. Susano Pinto, L. Beyer, X. Zhai, J. Harmsen, N. Houlsby, Uvim: A unified modeling approach for vision with learned guiding codes, Advances in Neural Information Processing Systems 35 (2022) 26295–26308
2022
-
[22]
16804–16815
X.Zhu, J.Zhu, H.Li, X.Wu, H.Li, X.Wang, J.Dai, Uni-perceiver: Pre- training unified architecture for generic perception for zero-shot and few- shot tasks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16804–16815
2022
-
[23]
W. Wang, Z. Chen, X. Chen, J. Wu, X. Zhu, G. Zeng, P. Luo, T. Lu, J.Zhou, Y.Qiao, etal., Visionllm: Largelanguagemodelisalsoanopen- ended decoder for vision-centric tasks, Advances in Neural Information Processing Systems 36 (2024)
2024
-
[24]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[25]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High- resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, 2022, pp. 10684–10695. 25
2022
- [26]
- [27]
-
[28]
Oorloff, V
T. Oorloff, V. Sindagi, W. G. C. Bandara, A. Shafahi, A. Ghiasi, C. Prakash, R. Ardekani, Stable diffusion models are secretly good at visual in-context learning, in: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2025, pp. 23604–23613
2025
-
[29]
Z. Wang, Y. Jiang, Y. Lu, P. He, W. Chen, Z. Wang, M. Zhou, et al., In-context learning unlocked for diffusion models, Advances in Neural Information Processing Systems 36 (2023) 8542–8562
2023
-
[30]
Z. Geng, B. Yang, T. Hang, C. Li, S. Gu, T. Zhang, J. Bao, Z. Zhang, H. Li, H. Hu, et al., Instructdiffusion: A generalist modeling interface for vision tasks, in: Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2024, pp. 12709–12720
2024
-
[31]
Z. Gu, S. Yang, J. Liao, J. Huo, Y. Gao, Analogist: Out-of-the-box vi- sual in-context learning with image diffusion model, ACM Transactions on Graphics (TOG) 43 (4) (2024) 1–15
2024
- [32]
-
[33]
J. Gao, Y. Sun, Y. Liu, Y. Tang, Y. Zeng, D. Qi, K. Chen, C. Zhao, Styleshot: A snapshot on any style, IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2025)
2025
-
[34]
Tzeng, J
E. Tzeng, J. Hoffman, T. Darrell, K. Saenko, Simultaneous deep transfer across domains and tasks, in: Proceedings of the IEEE international conference on computer vision, 2015, pp. 4068–4076
2015
-
[35]
A. R. Zamir, A. Sax, W. Shen, L. J. Guibas, J. Malik, S. Savarese, Taskonomy: Disentangling task transfer learning, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3712–3722. 26
2018
-
[36]
A. Pal, V. N. Balasubramanian, Zero-shot task transfer, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2189–2198
2019
-
[37]
A. Wang, M. Tarr, L. Wehbe, Neural taskonomy: Inferring the simi- larity of task-derived representations from brain activity, in: H. Wal- lach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, R. Garnett (Eds.), Advances in Neural Information Processing Systems, Vol. 32, Curran Associates, Inc., 2019
2019
-
[38]
Dwivedi, G
K. Dwivedi, G. Roig, Representation similarity analysis for efficient task taxonomy & transfer learning, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2019, pp. 12387– 12396
2019
-
[39]
Bhattacharjee, S
D. Bhattacharjee, S. Süsstrunk, M. Salzmann, Vision transformer adapters for generalizable multitask learning, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 19015–19026
2023
-
[40]
Cheng, I
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, R. Girdhar, Masked- attention mask transformer for universal image segmentation, in: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 1290–1299
2022
-
[41]
Huang, Z
G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely con- nected convolutional networks, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708
2017
-
[42]
Zhang, A
L. Zhang, A. Rao, M. Agrawala, Adding conditional control to text-to- image diffusion models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3836–3847
2023
-
[43]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[44]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transfer- able visual models from natural language supervision, in: International conference on machine learning, PMLR, 2021, pp. 8748–8763. 27
2021
-
[45]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, Restormer: Efficient transformer for high-resolution image restoration, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5728–5739
2022
-
[46]
Jiang, Z
J. Jiang, Z. Zuo, G. Wu, K. Jiang, X. Liu, A survey on all-in-one image restoration: Taxonomy, evaluation and future trends, IEEE Transac- tions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[47]
Y. Cui, S. W. Zamir, S. Khan, A. Knoll, M. Shah, F. S. Khan, Adair: Adaptive all-in-one image restoration via frequency mining and mod- ulation, in: 13th International Conference on Learning Representa- tions, ICLR 2025, International Conference on Learning Representa- tions, ICLR, 2025, pp. 57335–57356
2025
-
[48]
J. Jain, Y. Zhou, N. Yu, H. Shi, Keys to better image inpainting: Struc- ture and texture go hand in hand, in: Proceedings of the IEEE/CVF winter conference on applications of computer vision, 2023, pp. 208–217
2023
-
[49]
H. Jin, Y. Li, F. Luan, Y. Xiangli, S. Bi, K. Zhang, Z. Xu, J. Sun, N. Snavely, Neural gaffer: Relighting any object via diffusion, Advances in Neural Information Processing Systems 37 (2024) 141129–141152
2024
-
[50]
Cheng, Z
X. Cheng, Z. Fu, J. Yang, Multi-scale dynamic feature encoding network for image demoiréing, in: 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), IEEE, 2019, pp. 3486–3493
2019
-
[51]
S. Kim, Y. Huo, S.-E. Yoon, Single image reflection removal with physically-based training images, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 5164– 5173
2020
-
[52]
Abdelhamed, S
A. Abdelhamed, S. Lin, M. S. Brown, A high-quality denoising dataset for smartphone cameras, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[53]
C. Wei, W. Wang, W. Yang, J. Liu, Deep retinex decomposition for low-light enhancement, arXiv preprint arXiv:1808.04560 (2018). 28
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, L. Shao, Learning enriched features for fast image restoration and en- hancement, IEEE transactions on pattern analysis and machine intelli- gence 45 (2) (2022) 1934–1948
2022
-
[55]
C. Ancuti, C. O. Ancuti, C. De Vleeschouwer, D-hazy: A dataset to evaluate quantitatively dehazing algorithms, in: 2016 IEEE Interna- tional Conference on Image Processing (ICIP), 2016, pp. 2226–2230. doi:10.1109/ICIP.2016.7532754
-
[56]
S. Nah, T. Hyun Kim, K. Mu Lee, Deep multi-scale convolutional neural network for dynamic scene deblurring, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 3883– 3891
2017
-
[57]
J. Wang, X. Li, J. Yang, Stacked conditional generative adversarial net- works for jointly learning shadow detection and shadow removal, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 1788–1797
2018
- [58]
- [59]
-
[60]
X. Yu, P. Dai, W. Li, L. Ma, J. Shen, J. Li, X. Qi, Towards efficient and scale-robust ultra-high-definition image demoiréing, in: European Conference on Computer Vision, Springer, 2022, pp. 646–662
2022
-
[61]
R.Wan, B.Shi, L.-Y.Duan, A.-H.Tan, A.C.Kot, Benchmarkingsingle- image reflection removal algorithms, in: International Conference on Computer Vision (ICCV), 2017
2017
- [62]
-
[63]
Kamali, K
N. Kamali, K. Nakamura, A. Kumar, A. Chatzimparmpas, J. Hullman, M. Groh, Characterizing photorealism and artifacts in diffusion model- generated images, in: Proceedings of the 2025 CHI Conference on Hu- man Factors in Computing Systems, 2025, pp. 1–26
2025
-
[64]
Q. Wu, Y. Liu, H. Zhao, T. Bui, Z. Lin, Y. Zhang, S. Chang, Harness- ing the spatial-temporal attention of diffusion models for high-fidelity text-to-image synthesis, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 7766–7776
2023
-
[65]
Z. Meng, C. Yang, J. Liu, H. Tang, P. Zhao, Y. Wang, Instructgie: Towards generalizable image editing, in: European Conference on Com- puter Vision, Springer, 2024, pp. 18–34
2024
-
[66]
Soria, Y
X. Soria, Y. Li, M. Rouhani, A. D. Sappa, Tiny and efficient model for the edge detection generalization, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 1364–1373
2023
-
[67]
Cheng, Y
D. Cheng, Y. Li, D. Zhang, N. Wang, J. Sun, X. Gao, Progressive negative enhancing contrastive learning for image dehazing and beyond, IEEE Transactions on Multimedia 26 (2024) 8783–8798
2024
-
[68]
Cheng, Y
D. Cheng, Y. Ji, D. Gong, Y. Li, N. Wang, J. Han, D. Zhang, Continual all-in-one adverse weather removal with knowledge replay on a unified network structure, IEEE Transactions on Multimedia 26 (2024) 8184– 8196
2024
-
[69]
M.ElHelou, R.Zhou, S.Susstrunk, R.Timofte, Ntire2021depthguided image relighting challenge, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR) Workshops, 2021, pp. 566–577
2021
-
[70]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, Pytorch: An imperative style, high- performance deep learning library, in: Advances in Neural Information Processing Syste...
2019
-
[71]
Original Painter, Instruct-Diffusion, and Prompt Diffusion all use the officially released weights for inference
tokenizer (with sequences padded to a maximum length of 256) for im- plicit global textural prompt, and a pretrained frozen CLIP [44] model (ViT- B/32) [24] for implicit information combination (implicit learning matrix: q = 256) and embedding space unification. Original Painter, Instruct-Diffusion, and Prompt Diffusion all use the officially released wei...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.