OmniPilot: An Uncertainty-Aware LLM Inference Advisor for Heterogeneous GPU Clusters
Pith reviewed 2026-07-03 06:28 UTC · model grok-4.3
The pith
OmniPilot predicts aggregate LLM serving throughput on heterogeneous GPUs with 6.2% MAPE and abstains from out-of-distribution configurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OmniPilot pairs a conformally calibrated quantile cost model spanning eight serving targets with an out-of-distribution abstention layer. It ranks configurations using an economic utility metric calibrated to an operator's revealed preferences. In evaluations, it predicts aggregate throughput with 6.2% mean absolute percentage error and log-space R² of 0.92, while achieving 95% top-1 accuracy with mean utility regret of 0.003. On OOD holdouts, it flags all unsupported cases despite higher prediction error.
What carries the argument
The conformally calibrated quantile cost model with OOD abstention layer that ranks configurations by economic utility metric.
Load-bearing premise
The 460 benchmark runs form a representative sample of real cluster behavior and the conformal calibration and OOD detection layers function without post-hoc tuning affecting the reported metrics.
What would settle it
Running the advisor on new model families or hardware types not in the benchmarks and observing whether prediction errors stay below 10% on in-support cases or the OOD layer correctly abstains in all high-error cases.
Figures
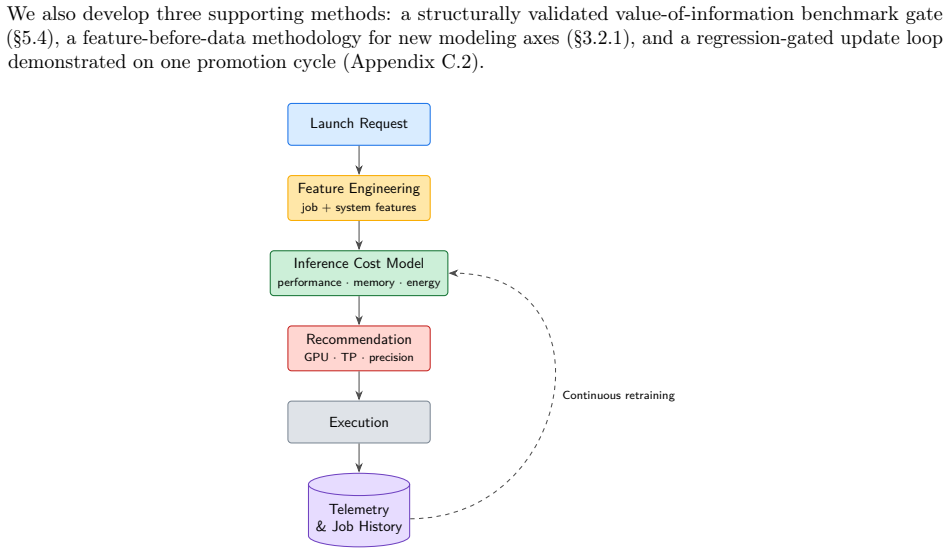
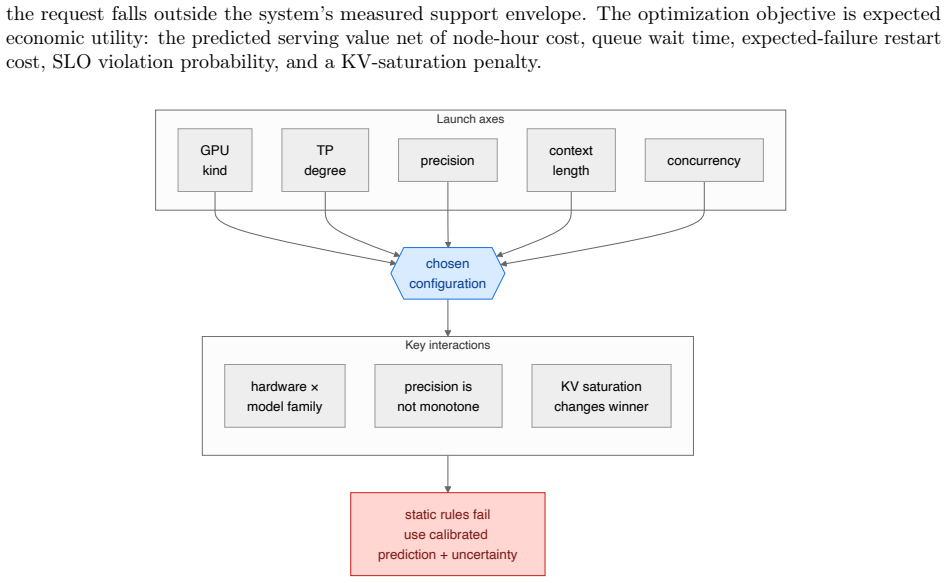

read the original abstract
Serving large language models (LLMs) on a shared, heterogeneous GPU cluster requires users and operators to select the GPU type, tensor-parallel degree, and precision before committing valuable node-hours. Making these choices is challenging because effective throughput, launch-success rates, and cluster demand and utilization continuously fluctuate. Furthermore, static configuration recipes miss critical interactions: quantization effects depend heavily on the model family, key-value cache pressure creates size-by-precision trade-offs, and failure rates vary by more than twofold across different tensor-parallel degrees. Additionally, cluster resources are frequently constrained by unpredictable hardware failures. To address these challenges, we present \textbf{OmniPilot}, a launch advisor that predicts serving costs for feasible configurations and abstains when requests fall outside its measured support envelope. OmniPilot pairs a conformally calibrated quantile cost model (spanning eight serving targets) with an out-of-distribution (OOD) abstention layer. It ranks configurations using an economic utility metric calibrated to an operator's revealed preferences. In evaluations across 460 benchmark runs on A100, H100, and H200 hardware across four precisions, OmniPilot predicts aggregate throughput with a 6.2\% mean absolute percentage error (MAPE) and a log-space $R^2=0.92$. The advisor achieves 95\% top-1 accuracy with a mean utility regret of just 0.003. When tested on an OOD holdout of unsupported cells, prediction error climbs to 24-46\% and conformal intervals cover 0 of 5 points; however, the abstention layer successfully flags all five as low-confidence. Over time, these OOD scenarios will be integrated into the training dataset to continuously expand the advisor's support envelope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OmniPilot, an uncertainty-aware launch advisor for LLM serving on heterogeneous GPU clusters (A100/H100/H200). It combines a conformally calibrated quantile regression model over eight serving targets with an OOD abstention layer and ranks configurations via an economic utility metric. On 460 benchmark runs across four precisions, it reports 6.2% MAPE and log-space R²=0.92 for aggregate throughput prediction, 95% top-1 accuracy, and 0.003 mean utility regret; OOD holdouts trigger abstention with 24-46% error and zero coverage.
Significance. If the empirical results generalize beyond the evaluated runs, the approach offers a practical, uncertainty-quantified tool for reducing wasted node-hours in dynamic clusters where static recipes fail due to quantization, KV-cache, and failure-rate interactions. The conformal + OOD design is a clear strength for safe deployment.
major comments (2)
- [Evaluation / Results] Evaluation section (implicit in abstract and results): the headline metrics (6.2% MAPE, R²=0.92, 95% top-1 accuracy) rest on an unstratified sample of 460 runs. No replicate counts, cell-wise coverage across (model family, precision, TP degree), or sampling frame are supplied, so it is impossible to assess whether high-throughput stable cells are over-represented relative to rare failure or high-KV-pressure regimes; this directly affects whether the conformal quantiles and utility ranking are load-bearing or artifactual.
- [Methods] Methods (model training and calibration): the abstract and description provide no derivation, hyper-parameter search, cross-validation procedure, or independence check between the utility metric and the reported accuracy numbers. Without these, post-hoc exclusions or circular fitting cannot be ruled out, undermining the claim that the 0.003 regret is a genuine out-of-sample property.
minor comments (2)
- [Introduction] The claim that failure rates vary by more than twofold across TP degrees is stated without a supporting table or figure; adding the raw per-TP failure counts would strengthen the motivation.
- [Approach] Notation for the eight serving targets and the exact form of the economic utility function should be defined explicitly rather than left to the reader to infer from context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation and methods. We address each major comment below and commit to revisions that supply the requested details without altering the reported results.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section (implicit in abstract and results): the headline metrics (6.2% MAPE, R²=0.92, 95% top-1 accuracy) rest on an unstratified sample of 460 runs. No replicate counts, cell-wise coverage across (model family, precision, TP degree), or sampling frame are supplied, so it is impossible to assess whether high-throughput stable cells are over-represented relative to rare failure or high-KV-pressure regimes; this directly affects whether the conformal quantiles and utility ranking are load-bearing or artifactual.
Authors: We agree that the manuscript does not report replicate counts, cell-wise coverage, or an explicit sampling frame for the 460 runs. While the runs span multiple model families, four precisions, and varying tensor-parallel degrees on A100/H100/H200 hardware, the absence of a breakdown prevents readers from evaluating potential over-representation of stable high-throughput cells. We will revise the Evaluation section to include a table documenting the number of runs per (model family, precision, TP degree) cell along with a description of the benchmark collection procedure. This addition will allow assessment of whether the conformal quantiles and 0.003 utility regret rest on balanced coverage. revision: yes
-
Referee: [Methods] Methods (model training and calibration): the abstract and description provide no derivation, hyper-parameter search, cross-validation procedure, or independence check between the utility metric and the reported accuracy numbers. Without these, post-hoc exclusions or circular fitting cannot be ruled out, undermining the claim that the 0.003 regret is a genuine out-of-sample property.
Authors: The manuscript provides no derivation of the utility metric, no hyper-parameter search details, no cross-validation procedure, and no explicit check that the utility metric is independent of the accuracy and regret calculations. We acknowledge this omission leaves open the possibility of circularity or post-hoc adjustments. We will add a dedicated Methods subsection that (i) derives the economic utility function from operator preferences, (ii) describes the grid search and validation split used for hyper-parameter selection in the quantile regression, (iii) states the cross-validation scheme for conformal calibration, and (iv) confirms that all accuracy and regret figures were computed on a held-out test set disjoint from training and calibration data. Any exclusions will be documented. revision: yes
Circularity Check
No circularity; purely empirical evaluation on benchmark data
full rationale
The paper describes an empirical advisor built from 460 benchmark runs across hardware and precisions. It reports standard performance metrics (MAPE, R², top-1 accuracy, regret) on those runs plus an OOD holdout. No equations, first-principles derivations, or predictions are presented that reduce by construction to fitted parameters or self-citations. The conformal quantile model and utility ranking are trained and evaluated on the collected data in the usual supervised manner; the reported numbers are direct empirical outcomes rather than tautological restatements of inputs. Self-citation is absent from the provided text. This is the normal non-circular case for an applied ML systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” inProc. 29th ACM Symp. Operating Systems Principles (SOSP), 2023. doi:10.1145/3600006.3613165. arXiv:2309.06180
-
[2]
Orca: A Distributed Serving System for Transformer-Based Generative Models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A Distributed Serving System for Transformer-Based Generative Models,” inProc. 16th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2022
2022
-
[3]
Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, A. Tumanov, and R. Ramjee, “Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve,” inProc. 18th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2024. arXiv:2403.02310
-
[4]
SGLang: Efficient Execution of Structured Language Model Programs
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y. Sheng, “SGLang: Efficient Execution of Structured Language Model Programs,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024. arXiv:2312.07104
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving,
Z. Li, L. Zheng, Y. Zhong, V. Liu, Y. Sheng, X. Jin, Y. Huang, Z. Chen, H. Zhang, J. E. Gonzalez, and I. Stoica, “AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving,” inProc. 17th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2023. arXiv:2302.11665
-
[6]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
J. Lin, J. Tang, H. Tang, S. Yang, W.-M. Chen, W.-C. Wang, G. Xiao, X. Dang, C. Gan, and S. Han, “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,” inProc. Machine Learning and Systems (MLSys), 2024. arXiv:2306.00978
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,” inProc. Int. Conf. Learning Representations (ICLR), 2023. arXiv:2210.17323. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
P. Micikevicius, D. Stosic, N. Burgess, M. Cornea, P. Dubey, R. Grisenthwaite, S. Ha, A. Heinecke, P. Judd, J. Kamalu et al., “FP8 Formats for Deep Learning,” arXiv:2209.05433, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Conformalized Quantile Regression
Y. Romano, E. Patterson, and E. J. Candès, “Conformalized Quantile Regression,” inAdvances in Neural Information Processing Systems (NeurIPS), 2019, pp. 3538–3548. arXiv:1905.03222
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
A. N. Angelopoulos and S. Bates, “A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification,” arXiv:2107.07511, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
R. A. Howard, “Information Value Theory,”IEEE Trans. Systems Science and Cybernetics, vol. 2, no. 1, pp. 22–26, 1966. doi:10.1109/TSSC.1966.300074
-
[12]
doi:10.48550/arXiv.2402.14992 , shorttitle =
F. M. Polo, L. Weber, L. Choshen, Y. Sun, G. Xu, and M. Yurochkin, “tinyBenchmarks: Evaluating LLMs with Fewer Examples,” inProc. Int. Conf. Machine Learning (ICML), 2024. arXiv:2402.14992
-
[13]
Habitat: A Runtime-Based Computational Performance Predictor for Deep Neural Network Training,
G. X. Yu, Y. Gao, P. Golikov, and G. Pekhimenko, “Habitat: A Runtime-Based Computational Performance Predictor for Deep Neural Network Training,” inProc. USENIX Annual Technical Conf. (ATC),
-
[14]
Roofline: An Insightful Visual Performance Model for Multicore Architectures,
S. Williams, A. Waterman, and D. Patterson, “Roofline: An Insightful Visual Performance Model for Multicore Architectures,”Communications of the ACM, vol. 52, no. 4, pp. 65–76, 2009. doi:10.1145/1498765.1498785
-
[15]
V. J. Reddi, C. Cheng, D. Kanter, P. Mattson, G. Schmuelling, C.-J. Wu et al., “MLPerf In- ference Benchmark,” inProc. ACM/IEEE 47th Int. Symp. Computer Architecture (ISCA), 2020. doi:10.1109/ISCA45697.2020.00045. arXiv:1911.02549
-
[16]
TFX: A TensorFlow-Based Production-Scale Machine Learning Platform,
D. Baylor, E. Breck, H.-T. Cheng, N. Fiedel, C. Y. Foo, Z. Haque, S. Haykal, M. Ispir, V. Jain, L. Koc et al., “TFX: A TensorFlow-Based Production-Scale Machine Learning Platform,” inProc. 23rd ACM SIGKDD Int. Conf. Knowledge Discovery and Data Mining (KDD), 2017. doi:10.1145/3097983.3098021
-
[17]
Data Validation for Machine Learning,
E. Breck, N. Polyzotis, S. Roy, S. E. Whang, and M. Zinkevich, “Data Validation for Machine Learning,” inProc. Machine Learning and Systems (MLSys), 2019
2019
-
[18]
A Continual Learning Survey: Defying Forgetting in Classification Tasks,
M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A Continual Learning Survey: Defying Forgetting in Classification Tasks,”IEEE Trans. Pattern Analysis and Machine Intelligence, 2021. arXiv:1909.08383
-
[19]
Gandiva: Introspective Cluster Scheduling for Deep Learning,
W. Xiao, R. Bhardwaj, R. Ramjee, M. Sivathanu, N. Kwatra, Z. Han, P. Patel, X. Peng, H. Zhao, Q. Zhang, F. Yang, and L. Zhou, “Gandiva: Introspective Cluster Scheduling for Deep Learning,” inProc. 13th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2018
2018
-
[20]
Tiresias: A GPU Cluster Manager for Distributed Deep Learning,
J. Gu, M. Chowdhury, K. G. Shin, Y. Zhu, M. Jeon, J. Qian, H. Liu, and C. Guo, “Tiresias: A GPU Cluster Manager for Distributed Deep Learning,” inProc. 16th USENIX Symp. Networked Systems Design and Implementation (NSDI), 2019
2019
-
[21]
DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving
Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang, “DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving,” inProc. 18th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2024. arXiv:2401.09670
-
[22]
Splitwise: Efficient generative LLM inference using phase splitting
P. Patel, E. Choukse, C. Zhang, A. Shah, Í. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient Generative LLM Inference Using Phase Splitting,” inProc. 51st ACM/IEEE Int. Symp. Computer Architecture (ISCA), 2024. arXiv:2311.18677
-
[23]
Llumnix: Dynamic Scheduling for Large Language Model Serving,
B. Sun, Z. Huang, H. Zhao, W. Xiao, X. Zhang, Y. Li, and W. Lin, “Llumnix: Dynamic Scheduling for Large Language Model Serving,” inProc. 18th USENIX Symp. Operating Systems Design and Implementation (OSDI), 2024. arXiv:2406.03243
-
[24]
Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow,
Y. Mei, Y. Zhuang, X. Miao, J. Yang, Z. Jia, and R. Vinayak, “Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow,” inProc. 30th ACM Int. Conf. Architectural Support for Programming Languages and Operating Systems (ASPLOS), 2025. doi:10.1145/3669940.3707215. arXiv:2406.01566. 12
-
[25]
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving,
R. Qin, Z. Li, W. He, M. Zhang, Y. Wu, W. Zheng, and X. Xu, “Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving,” inProc. 23rd USENIX Conf. File and Storage Technologies (F AST), 2025. arXiv:2407.00079
-
[26]
vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention,
R. Prabhu, A. Nayak, J. Mohan, R. Ramjee, and A. Panwar, “vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention,” inProc. 30th ACM Int. Conf. Architectural Support for Program- ming Languages and Operating Systems (ASPLOS), 2025. doi:10.1145/3669940.3707256. arXiv:2405.04437
-
[27]
The Kempner AI Cluster,
Kempner Institute for the Study of Natural and Artificial Intelligence, “The Kempner AI Cluster,” Harvard University. https://kempnerinstitute.harvard.edu/kempner-ai-cluster/
-
[28]
HPC_Tools: Utilities for HPC Cluster Telemetry and Job-Data Collection,
D. Balamurugan, “HPC_Tools: Utilities for HPC Cluster Telemetry and Job-Data Collection,” GitHub repository. https://github.com/dmbala/HPC_Tools
-
[29]
Jobstats: A Slurm Job Statistics and Monitoring Platform,
Princeton University Research Computing, “Jobstats: A Slurm Job Statistics and Monitoring Platform,” GitHub repository. https://github.com/PrincetonUniversity/jobstats. Appendix A: Supplementary Figures The following figures supplement the main text; each is referenced from its corresponding section, and all numbers trace to the same measured results as t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.