Development of a Retrieval-Augmented Generation Virtual Assistant for Enhanced Information Discovery at Rubin Observatory
Pith reviewed 2026-07-03 05:29 UTC · model grok-4.3
The pith
A prototype RAG virtual assistant retrieves from Rubin Observatory's distributed documentation to deliver accurate answers to LSST-related questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
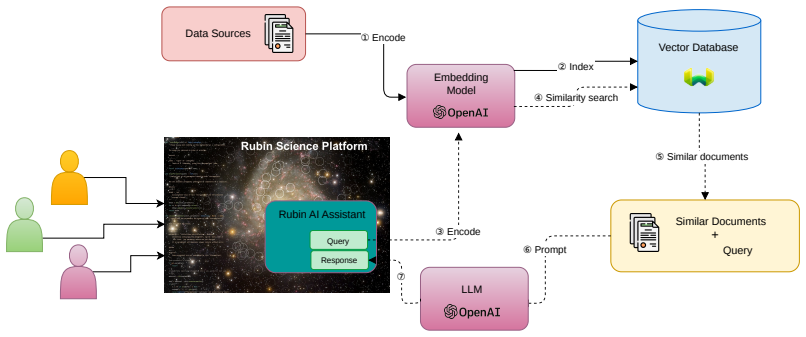
The authors present a working RAG prototype that ingests material from multiple Rubin sources, stores embeddings in Weaviate, orchestrates queries with LangChain, and uses an OpenAI GPT model to generate responses. By anchoring every answer in retrieved domain documents rather than the model's parametric knowledge alone, the assistant produces context-aware, factual replies to questions about observatory operations and LSST data products.
What carries the argument
Retrieval-Augmented Generation pipeline that first retrieves relevant passages from a vector database of Rubin documentation and then conditions the LLM response on those passages.
If this is right
- Staff and scientists obtain faster, more reliable answers to questions about observatory procedures and data products.
- Responses are grounded in the retrieved documentation, lowering the rate of hallucinations on Rubin-specific topics.
- The same architecture can be extended to additional internal and external Rubin resources as they become available.
- Workflows that currently require manual searching across platforms become partially automated through the conversational interface.
Where Pith is reading between the lines
- Similar RAG systems could be deployed at other large observatories or surveys facing comparable documentation fragmentation.
- Periodic re-indexing of the vector store would be needed to keep the assistant current with new technical notes and papers.
- Evaluation against real user questions rather than synthetic tests would be required to measure practical time savings.
Load-bearing premise
The chosen combination of Weaviate embeddings, LangChain orchestration, and OpenAI GPT backend will reliably retrieve and synthesize accurate Rubin-specific information across heterogeneous internal and external sources without significant coverage gaps or outdated content.
What would settle it
A test set of Rubin-specific queries for which the assistant returns answers that contradict or omit key facts present in the actual source documents.
Figures
read the original abstract
The NSF-DOE Vera C. Rubin Observatory will generate petabytes of data through the Legacy Survey of Space and Time (LSST) over the next decade, enabling discoveries across a broad range of astrophysical fields. Alongside these data products, Rubin maintains a large but heterogeneous collection of supporting documentation, including operational guides, technical notes, and scientific papers. Because this material is distributed across multiple platforms and formats, staff and scientists often struggle to efficiently locate accurate, up-to-date information. Many resources also reside on internal systems, limiting the ability of general-purpose language models to provide reliable answers to Rubin-specific questions. To address these challenges, we explore the use of Retrieval Augmented Generation (RAG) to improve information discovery. We present a prototype RAG-based virtual assistant that delivers context-aware, factual, conversational access to Rubin's vast and heterogenous documentation ecosystem. The system integrates material from multiple sources and enables semantic search through a conversational interface, using Weaviate for embeddings, LangChain for query orchestration, and an OpenAI GPT model as the LLM backend. By grounding responses in domain-specific knowledge, the assistant reduces hallucinations, improves accuracy, and demonstrates the potential of RAG to enhance access to distributed knowledge, streamline workflows, and support effective use of LSST data products.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the development of a prototype Retrieval-Augmented Generation (RAG) virtual assistant for Rubin Observatory documentation. It integrates heterogeneous sources via Weaviate embeddings, LangChain orchestration, and an OpenAI GPT backend, claiming that domain-specific grounding reduces hallucinations and improves accuracy for LSST-related queries.
Significance. The work addresses a practical need for improved access to distributed observatory documentation. The clear description of the architecture and multi-source integration provides a useful case study for astro-ph.IM, even if performance assertions remain unquantified.
major comments (1)
- [Abstract] Abstract: the central claims that the assistant 'reduces hallucinations, improves accuracy' and 'demonstrates the potential of RAG' rest entirely on general RAG properties rather than any reported metrics, test-query results, hallucination-rate measurements, baseline comparisons to non-RAG GPT, coverage audits, or user studies. This absence directly undermines the performance assertions that constitute the paper's primary motivation.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the assistant 'reduces hallucinations, improves accuracy' and 'demonstrates the potential of RAG' rest entirely on general RAG properties rather than any reported metrics, test-query results, hallucination-rate measurements, baseline comparisons to non-RAG GPT, coverage audits, or user studies. This absence directly undermines the performance assertions that constitute the paper's primary motivation.
Authors: We agree that the abstract overstates performance benefits without supporting quantitative evidence from the prototype. The manuscript focuses on system architecture, multi-source integration, and implementation details as a case study rather than on evaluation. We will revise the abstract to remove or qualify the claims about reduced hallucinations and improved accuracy, limiting assertions to the description of the prototype and noting that systematic evaluation remains future work. revision: yes
Circularity Check
No circularity: descriptive software prototype with no derivation chain
full rationale
The paper presents a descriptive account of building and integrating a RAG prototype (Weaviate embeddings, LangChain orchestration, OpenAI GPT backend) for Rubin documentation. It contains no mathematical derivations, equations, fitted parameters, predictions of derived quantities, or self-citation chains. Claims about reduced hallucinations rest on the untested architectural description rather than any self-referential reduction. This is a normal non-finding for an engineering report; the derivation chain is absent by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LSST: From Science Drivers to Reference Design and Anticipated Data Products,
Ivezi´ c,ˇZ., Kahn, S. M., Tyson, J. A., Abel, B., Acosta, E., Allsman, R., Alonso, D., AlSayyad, Y., Anderson, S. F., Andrew, J., Angel, J. R. P., Angeli, G. Z., Ansari, R., Antilogus, P., Araujo, C., Armstrong, R., Arndt, K. T., Astier, P., Aubourg, ´E., Auza, N., Axelrod, T. S., Bard, D. J., Barr, J. D., Barrau, A., Bartlett, J. G., Bauer, A. E., Bauma...
-
[2]
Guidelines for User Support with the Rubin Community Forum,
Graham, M. L., “Guidelines for User Support with the Rubin Community Forum,” Technical Note RTN-097, NSF-DOE Vera C. Rubin Observatory (March 2026).https://rtn-097.lsst.io/. 2
2026
-
[3]
Rubin Observatory’s Approach to Providing Sustainable Scientific User Support at Scale,
Graham, M. L., “Rubin Observatory’s Approach to Providing Sustainable Scientific User Support at Scale,” Technical Note RTN-121, NSF-DOE Vera C. Rubin Observatory (May 2026).https://rtn-121.lsst.io/. 2
2026
-
[4]
The LSST Science Pipelines Software: Optical Survey Pipeline Reduction and Analysis Environment,
Rubin Observatory Science Pipelines Developers, “The LSST Science Pipelines Software: Optical Survey Pipeline Reduction and Analysis Environment,” Project Science Technical Note PSTN-019, NSF-DOE Vera C. Rubin Observatory (December 2025). DOI:https://doi.org/10.71929/rubin/2570545. 2
-
[5]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., K¨ uttler, H., Lewis, M., Yih, W.-t., Rockt¨ aschel, T., Riedel, S., and Kiela, D., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” in [Advances in Neural Information Processing Systems], Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H., eds.,33, ...
2020
-
[6]
RAG vs finetuning: which is the best tool to boost your LLM ap- plication?
Hsia, D., “RAG vs finetuning: which is the best tool to boost your LLM ap- plication?.” Towards Data Science (2023).https://towardsdatascience.com/ rag-vs-finetuning-which-is-the-best-tool-to-boost-your-llm-application-94654b1eaba7. 2
2023
-
[7]
Rubin Observatory Plans for an Early Science Program,
Guy, L. P., AlSayyad, Y., Bechtol, K., Bellm, E. C., Blum, R. D., Dubois-Felsmann, G. P., Economou, F., Graham, M. L., Ivezi´ c,ˇZ., Lupton, R. H., Marshall, P., O’Mullane, W., Slater, C. T., and Strauss, M. A., “Rubin Observatory Plans for an Early Science Program,” Technical Note RTN-011, NSF-DOE Vera C. Rubin Observatory (April 2026). DOI:https://doi.o...
-
[8]
The Vera C. Rubin Observatory Data Preview 1,
Vera C. Rubin Observatory Team, “The Vera C. Rubin Observatory Data Preview 1,” Technical Note RTN-095, NSF-DOE Vera C. Rubin Observatory (May 2026). DOI:https://doi.org/10.71929/rubin/ 2570536. 3
-
[9]
Data Products Definition Document,
Juri´ c, M., Axelrod, T. S., Becker, A. C., Becla, J., Bellm, E. C., Bosch, J. F., Ciardi, D. R., Connolly, A. J., Dubois-Felsmann, G. P., Economou, F., Freemon, M. D., Johnson, M. W. G., Gill, R. K., Graham, M. L., Guy, L. P., Ivezi´ c,ˇZ., Jenness, T., Kantor, J. P., Krughoff, K. S., Lim, K.-T., Lupton, R. H., Mueller, F., Nidever, D. L., O’Mullane, W.,...
-
[10]
The Vera C. Rubin Observatory Data Butler and pipeline execution system,
Jenness, T., Bosch, J. F., Salnikov, A., Lust, N. B., Pease, N. M., Gower, M., Kowalik, M., Dubois-Felsmann, G. P., Mueller, F., and Schellart, P., “The Vera C. Rubin Observatory Data Butler and pipeline execution system,” in [Software and Cyberinfrastructure for Astronomy VII],Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series121...
work page doi:10.1117/12 2022
-
[11]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., and Wang, H., “Retrieval- augmented generation for large language models: a survey,”arXiv preprint arXiv:2312.10997(2024). DOI: https://doi.org/10.48550/arXiv.2312.10997. 4
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2024
-
[12]
Weaviate
Dilocker, E., van Luijt, B., Voorbach, B., Hasan, M. S., Rodriguez, A., Kulawiak, D. A., Antas, M., and Duckworth, P., “Weaviate.”https://github.com/weaviate/weaviate. 4, 5
-
[13]
Langchain,
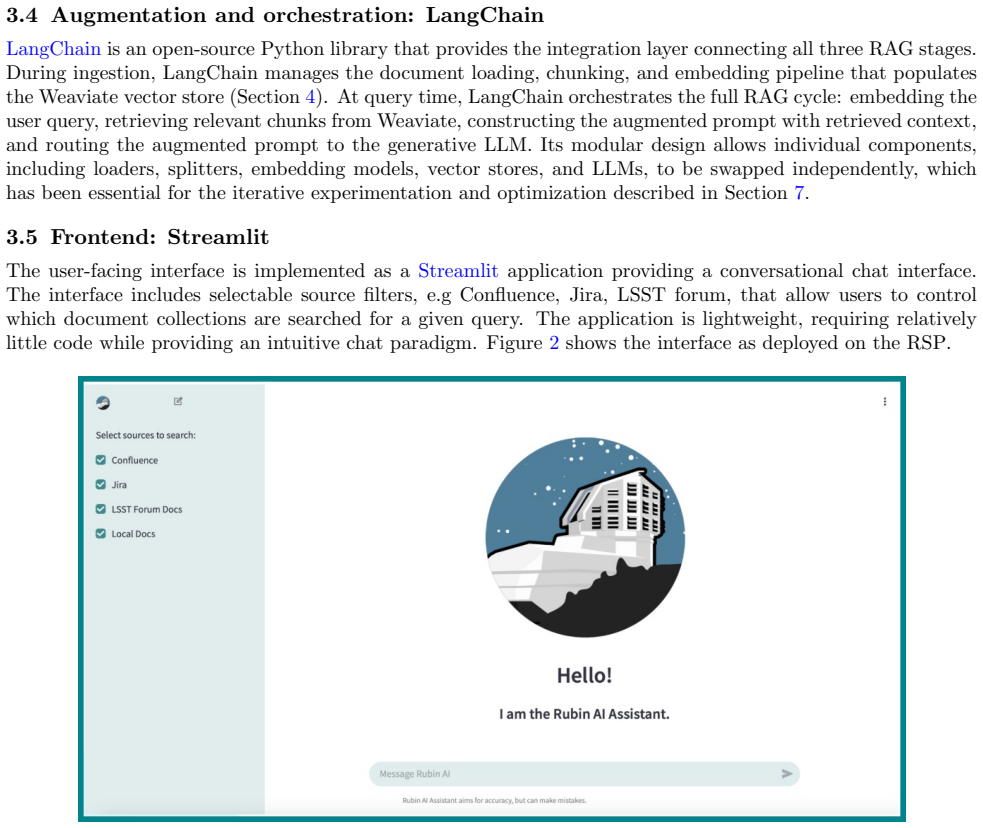
Chase, H., “Langchain,” (10 2022).https://github.com/langchain-ai/langchain. 5
2022
-
[14]
Guidelines for gated updates for SQuaRE services (including Science Platform),
Economou, F. and Allbery, R., “Guidelines for gated updates for SQuaRE services (including Science Platform),” SQuaRE Technical Note SQR-056, NSF-DOE Vera C. Rubin Observatory (September 2021). https://sqr-056.lsst.io/. 6
2021
-
[15]
Rubin Science Platform on Google: the story so far,
O’Mullane, W., Economou, F., Huang, F., Speck, D., Chiang, H., Graham, M. L., Allbery, R., Banek, C., Sick, J., Thornton, A. J., Masciarelli, J., Lim, K., Mueller, F., Padolsi, S., Jenness, T., Krughoff, K. S., Gower, M., Guy, L. P., and Dubois-Felsmann, G. P., “Rubin Science Platform on Google: the story so far,” in [Astromical Data Analysis Software and...
-
[16]
Recursive retriever and node references
Liu, J. et al., “Recursive retriever and node references.” LlamaIndex Documentation (2024).https:// docs.llamaindex.ai/en/stable/examples/retrievers/recursive_retriever_nodes/. 9
2024
-
[17]
5 levels of text splitting,
Kamradt, G., “5 levels of text splitting,” (2024).https://github.com/FullStackRetrieval-com/ RetrievalTutorials/blob/main/tutorials/LevelsOfTextSplitting/5_Levels_Of_Text_Splitting. ipynb. 9
2024
-
[18]
Evaluating chunking strategies for retrieval,
Smith, B. and Troynikov, A., “Evaluating chunking strategies for retrieval,” (2024).https://research. trychroma.com/evaluating-chunking. 9
2024
-
[19]
LangChain: Building applications with LLMs through composability,
Chase, H., “LangChain: Building applications with LLMs through composability,” (2023).https://www. langchain.com. 9
2023
-
[20]
New embedding models and api updates
OpenAI, “New embedding models and api updates.”https://openai.com/research/ new-embedding-models-and-api-updates/(2024). 9
2024
-
[21]
Robertson, S. and Zaragoza, H., “The probabilistic relevance framework: Bm25 and beyond,”Foundations and Trends in Information Retrieval3(4), 333–389 (2009). DOI:https://doi.org/10.1561/1500000019. 10
-
[22]
Transactions of the Association for Computational Linguistics , volume =
Luan, Y., Eisenstein, J., Toutanova, K., and Collins, M., “Sparse, dense, and attentional representations for text retrieval,”Transactions of the Association for Computational Linguistics9, 329–345 (2021). DOI: https://doi.org/10.1162/tacl_a_00369. 10
-
[23]
Ragas: Automated Evaluation of Retrieval Augmented Generation
Es, S., James, J., Espinosa-Anke, L., and Schockaert, S., “RAGAS: automated evaluation of retrieval aug- mented generation,”arXiv preprint arXiv:2309.15217(2023). DOI:https://doi.org/10.48550/arXiv. 2309.15217. 10
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.