HCMS: Head-Chunked Multi-Stream Pipeline for Communication-Computation Overlap in Long-Sequence Parallel Attention
Pith reviewed 2026-07-03 06:20 UTC · model grok-4.3
The pith
Head chunking with dual CUDA streams overlaps communication and computation in sequence-parallel attention.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
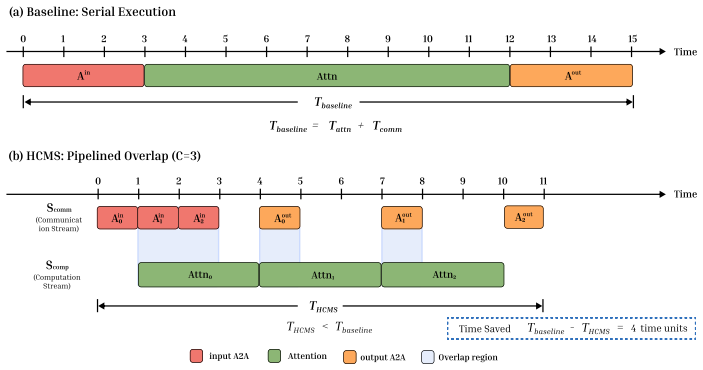
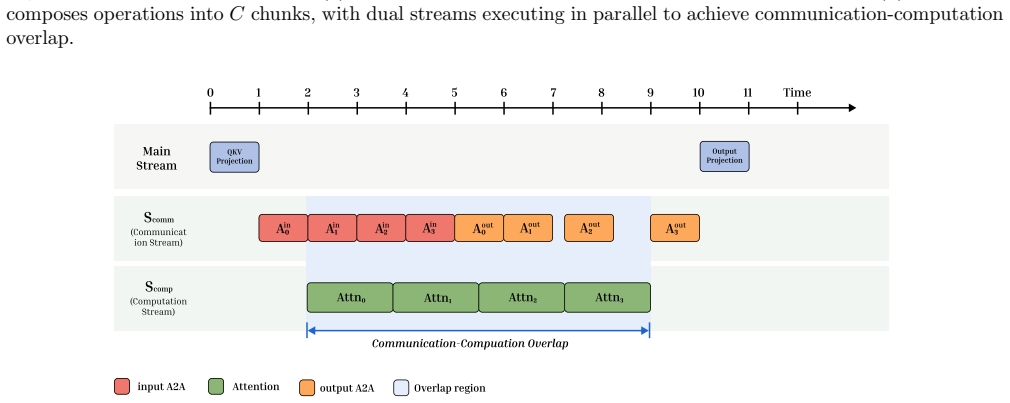
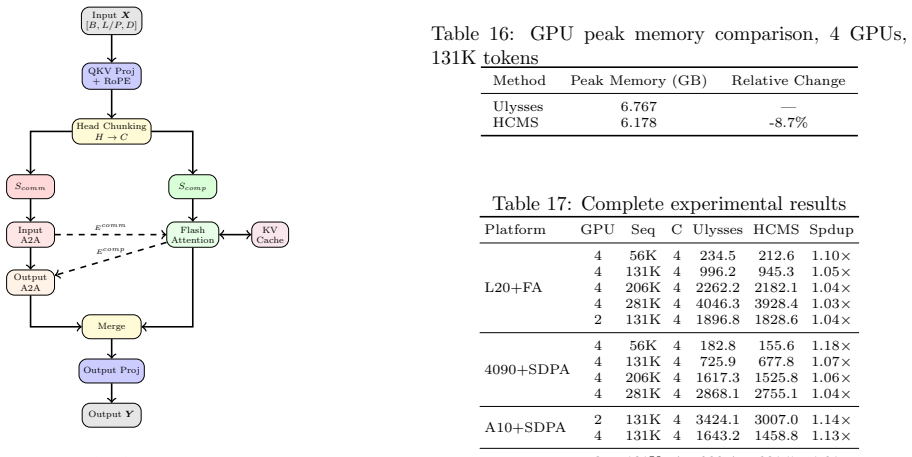
HCMS partitions the heads of multi-head attention into multiple chunks and pipelines their all-to-all communication and local computation across dual CUDA streams, achieving fine-grained overlap that remains numerically equivalent to the baseline even under uneven partitioning.
What carries the argument
Head-Chunked Multi-Stream Pipeline, which divides attention heads into chunks and alternates their communication and computation on two independent CUDA streams.
If this is right
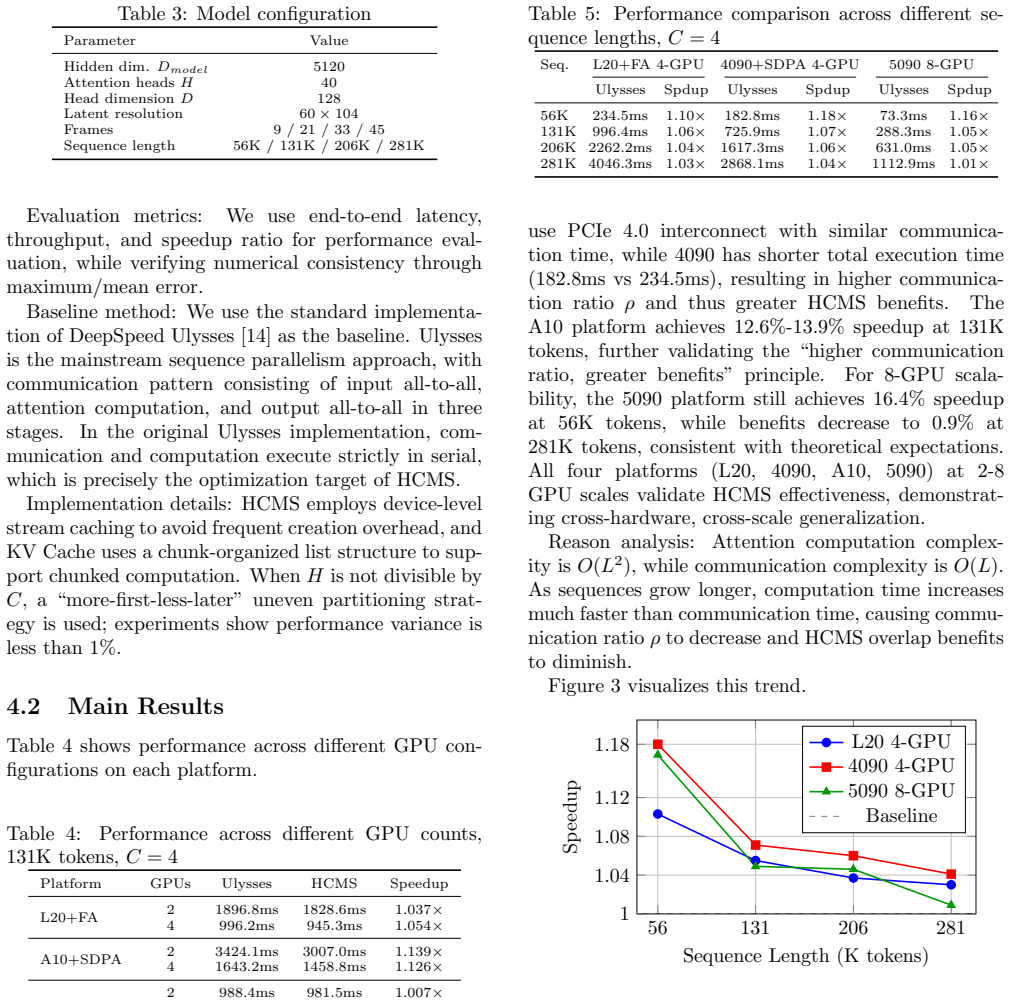
- 10%-17.5% speedup over Ulysses baseline at 31K-56K tokens
- 5%-14.5% speedup over Ring Attention at the same lengths
- 6.8% end-to-end acceleration on the Wan2.2 video model
- Benefits increase with communication ratio ρ and are advised when ρ exceeds 20%
Where Pith is reading between the lines
- The same head-chunking pattern could be applied to other collective operations that commute across heads.
- Models with higher attention compute intensity than video generation may see smaller relative gains.
- Uneven chunk sizes could be tuned dynamically to balance load when head counts are not multiples of the number of streams.
Load-bearing premise
That partitioning heads preserves exact numerical equivalence and adds negligible synchronization cost when the two streams run concurrently.
What would settle it
Measure the wall-clock time of one attention layer at 31K-56K sequence length with and without the dual-stream scheduling on identical hardware; the measured difference should match the overlap predicted from the communication ratio ρ.
Figures
read the original abstract
All-to-all based sequence parallelism methods execute communication and computation strictly in serial when processing medium-long sequences, resulting in hardware resource underutilization. This paper proposes Head-Chunked Multi-Stream Pipeline (HCMS), which exploits the computational independence of multi-head attention by partitioning attention heads into multiple chunks and achieving fine-grained communication-computation overlap through dual CUDA streams. HCMS is orthogonally compatible with existing optimizations such as FlashAttention and SDPA, requires no modification to underlying kernels, supports uneven partitioning while maintaining numerical equivalence. Experiments validate the effectiveness across four GPU platforms at 2-8 GPU scales: for typical video generation sequence lengths of 31K-56K tokens, HCMS achieves 10\%-17.5\% speedup over the Ulysses baseline and 5\%-14.5\% speedup over Ring Attention; end-to-end acceleration of 6.8\% is achieved on the Wan2.2 model. Theoretical analysis shows that HCMS benefits are positively correlated with communication ratio $\rho$, and its use is recommended when $\rho>20\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Head-Chunked Multi-Stream Pipeline (HCMS) for all-to-all sequence parallelism in long-sequence multi-head attention. It partitions heads into chunks to enable fine-grained communication-computation overlap via dual CUDA streams, claims orthogonality to FlashAttention/SDPA, support for uneven partitioning with numerical equivalence, and no kernel modifications. Experiments across four GPU platforms at 2-8 GPU scales report 10%-17.5% speedup over Ulysses and 5%-14.5% over Ring Attention for 31K-56K token sequences typical in video generation, plus 6.8% end-to-end on Wan2.2; theoretical analysis links benefits positively to communication ratio ρ and recommends HCMS when ρ>20%.
Significance. If the measured speedups hold under controlled conditions, HCMS would offer a practical, kernel-agnostic method to improve hardware utilization in distributed long-sequence attention, particularly for communication-bound regimes in video and long-context models. The ρ correlation provides actionable guidance on applicability.
major comments (1)
- [Abstract] Abstract: the abstract states empirical speedups and a correlation with communication ratio but supplies no experimental details, error bars, baseline implementations, or controls for confounding factors; full text required to verify whether measurements support the claims as stated.
minor comments (1)
- [Abstract] The symbol ρ for communication ratio is used without definition or formula in the provided text.
Simulated Author's Rebuttal
We thank the referee for the review. The sole major comment addresses the level of detail provided in the abstract. We respond point-by-point below, directing the reader to the relevant sections of the full manuscript for verification of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract states empirical speedups and a correlation with communication ratio but supplies no experimental details, error bars, baseline implementations, or controls for confounding factors; full text required to verify whether measurements support the claims as stated.
Authors: Abstracts are intentionally concise summaries. All requested details appear in the full manuscript: baselines (Ulysses and Ring Attention) are defined in Section 4.1; platforms, scales (2-8 GPUs), and sequence lengths (31K-56K tokens) are specified in Section 4; end-to-end results on Wan2.2 are in Section 4.3; the ρ correlation and recommendation threshold are derived in Section 3.3. Multiple-run statistics and controls for confounding factors (e.g., kernel orthogonality, uneven partitioning) are reported in the experimental methodology of Section 4.2. The abstract claims are therefore directly supported by the controlled experiments presented in the body of the paper. revision: no
Circularity Check
No significant circularity
full rationale
The paper introduces HCMS as an engineering optimization exploiting multi-head independence for dual-stream overlap, with all central claims (speedups of 10-17.5% over Ulysses, 5-14.5% over Ring Attention, 6.8% end-to-end on Wan2.2, and ρ>20% recommendation) resting on direct experimental measurements across four GPU platforms rather than any derivation chain. No equations, fitted parameters, self-citations, or ansatzes are described that reduce a result to its own inputs by construction; the theoretical correlation with communication ratio ρ is presented as an observed property of the method, not a self-referential prediction. The approach is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-head attention heads are computationally independent, allowing partitioning into chunks while preserving numerical equivalence even with uneven splits.
Reference graph
Works this paper leans on
-
[1]
Colossal-ai: A unified deep learning system for large-scale paral- lel training
Zhengda Bian, Hongxin Liu, et al. Colossal-ai: A unified deep learning system for large-scale paral- lel training. In52nd International Conference on Parallel Processing (ICPP), pages 1–10, Salt Lake City, UT, USA, 2023. ACM
2023
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Ku- lal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rom- bach. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, November 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litw...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[4]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. In The Twelfth International Conference on Learning Representations, 2024
2024
-
[5]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Tri Dao, Daniel Y Fu, Stefano Ermon, Atri Rudra, and Christopher R´ e. Flashattention: Fast and memory-efficient exact attention with io-awareness. InAdvances in Neural Informa- tion Processing Systems, volume 35, pages 16377– 16390, 2022
2022
-
[6]
Bert: Pre-training of deep bidirectional transformers for language un- derstanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language un- derstanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapoli...
2019
-
[7]
Association for Computational Linguistics
-
[8]
Diffusion Models Beat GANs on Image Synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion mod- els beat gans on image synthesis.arXiv preprint arXiv:2105.05233, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[10]
Usp: A uni- fied sequence parallelism approach for long context generative ai, 2024
Jiarui Fang and Shangchun Zhao. Usp: A uni- fied sequence parallelism approach for long context generative ai, 2024
2024
-
[11]
Jiarui Fang, Zilin Zhu, Yang Yu, and Xin Liu. Distflashattn: Distributed memory-efficient atten- tion for long-context llms training.arXiv preprint arXiv:2401.07248, 2024
-
[12]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers, 2022
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretrain- ing for text-to-video generation via transformers, 2022
2022
-
[14]
Gpipe: Efficient training of giant neural networks using pipeline parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, and Zhifeng Chen. Gpipe: Efficient training of giant neural networks using pipeline parallelism. InAdvances in Neural Information Processing Sys- tems, volume 32, 2019
2019
-
[15]
Deep- speed ulysses: System optimizations for enabling training of extreme long sequence transformer models, 2023
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. Deep- speed ulysses: System optimizations for enabling training of extreme long sequence transformer models, 2023. 8
2023
-
[16]
Coconet: Co-optimizing computa- tion and communication for distributed machine learning
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sabet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkowicz, and Olli Saarikivi. Coconet: Co-optimizing computa- tion and communication for distributed machine learning. InProceedings of Machine Learning and Systems (MLSys), volume 3, pages 1–14, 2021
2021
-
[17]
Breaking the computation and com- munication abstraction barrier in distributed ma- chine learning workloads
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sabet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkowicz, and Olli Saarikivi. Breaking the computation and com- munication abstraction barrier in distributed ma- chine learning workloads. InProceedings of the 27th ACM International Conference on Architec- tural Support for Programmin...
2022
-
[18]
Xing, Joseph E
Dacheng Li, Rulin Shao, Anze Xie, Eric P. Xing, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang. Lightseq: Sequence level parallelism for distributed training of long context transform- ers. InInternational Conference on Learning Rep- resentations (ICLR), 2024
2024
-
[19]
Sequence parallelism: Long sequence training from system perspective,
Shenggui Li, Fuzhao Xue, Yongbin Li, and Yang You. Sequence parallelism: Making 4d parallelism possible.arXiv preprint arXiv:2105.13120, 2021
-
[20]
Ring attention with blockwise transformers for near- infinite context, 2023
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near- infinite context, 2023
2023
-
[21]
Yuliang Liu, Zhen Wang, Yizheng Zhang, Dong Li, and Kai Chen. Striped attention: Faster ring attention for causal transformers.arXiv preprint arXiv:2311.09431, 2023
-
[22]
Mixed precision train- ing
Paulius Micikevicius et al. Mixed precision train- ing. InInternational Conference on Learning Rep- resentations (ICLR), 2018
2018
-
[23]
Devanur, Gre- gory R
Deepak Narayanan, Aaron Harlap, Amar Phan- ishayee, Vivek Seshadri, Nikhil R. Devanur, Gre- gory R. Ganger, Phillip B. Gibbons, and Matei Zaharia. Pipedream: Generalized pipeline paral- lelism for dnn training. InProceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP), pages 1–15, Huntsville, Ontario, Canada, October 2019. ACM
2019
-
[24]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vi- jay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. InProceedings of the Interna- tional Conference for Hi...
2021
-
[25]
Nccl: Accelerated multi-gpu collective communications
NVIDIA. Nccl: Accelerated multi-gpu collective communications. Technical report, NVIDIA, 2015
2015
-
[26]
Video generation models as world simu- lators
OpenAI. Video generation models as world simu- lators. Technical report, OpenAI, February 2024
2024
-
[27]
Py- torch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas K¨ opf, Ed- ward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Py- torch: An imperative style, high-pe...
2019
-
[28]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable dif- fusion models with transformers.arXiv preprint arXiv:2212.09748, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Zero bubble (almost) pipeline paral- lelism
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. Zero bubble (almost) pipeline paral- lelism. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[30]
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory opti- mizations toward training trillion parameter mod- els.arXiv preprint arXiv:1910.02054, 2020
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[31]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
2022
-
[32]
Horovod: fast and easy distributed deep learning in TensorFlow
Alexander Sergeev and Mike Del Balso. Horovod: fast and easy distributed deep learning in Tensor- Flow.arXiv preprint arXiv:1802.05799, February 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[33]
Megatron-lm: Training multi-billion parameter language models using model paral- lelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model paral- lelism. InProceedings of the International Confer- ence for High Performance Computing, Network- ing, Storage and Analysis, pages 1–15, 2019
2019
-
[34]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Mur- tadha, Bo Wen, and Yunfeng Liu. Roformer: En- hanced transformer with rotary position embed- ding.arXiv preprint arXiv:2104.09864, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, pages 5998–6008, 2017. 9
2017
-
[37]
Minzheng Wang, Longze Chen, Cheng Fu, Shengyi Liao, Xinghua Zhang, Bingli Wu, Haiyang Yu, Nan Xu, Lei Zhang, Run Luo, Yunshui Li, Min Yang, Fei Huang, and Yongbin Li. Loongtrain: Efficient training of long-sequence llms with head-context parallelism.arXiv preprint arXiv:2406.18485, 2024
-
[38]
Open-sora: Democratiz- ing end-to-end video generation with transformers
Zhaoyang Wang et al. Open-sora: Democratiz- ing end-to-end video generation with transformers. arXiv preprint arXiv:2403.17349, 2024
-
[39]
Overlap communication with dependent computation via decomposition in large deep learning models
Zhen Zhang, Shuai Zheng, Yida Wang, Xiaohan Li, and Kai Chen. Overlap communication with dependent computation via decomposition in large deep learning models. InProceedings of the 29th International Conference on Architectural Support for Programming Languages and Operating Sys- tems (ASPLOS), pages 1–16, 2024
2024
-
[40]
Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16(12):3848–3860, August 2023
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Des- maison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Math- ews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proceedings of the VLDB Endowment, 16(12):...
2023
-
[41]
FlashInfer: Efficient and Customizable Attention Engine for LLM Inference Serving
Zheng Zhong et al. Overlapattention: Tile-based overlap-driven efficient attention for distributed llm.arXiv preprint arXiv:2501.01005, 2025. A Detailed Theoretical Deriva- tions This section provides complete derivations for the HCMS theoretical performance model. A.1 Notation For convenience of analysis, we define the notation shown in Table 11: Table 1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.