The Grammar Does the Work: Functional vs. Lexical Dependency Length Minimization Across Universal Dependencies
Pith reviewed 2026-07-03 15:09 UTC · model grok-4.3
The pith
Grammar keeps functional dependencies short and fixed across languages while processing shapes the longer lexical ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
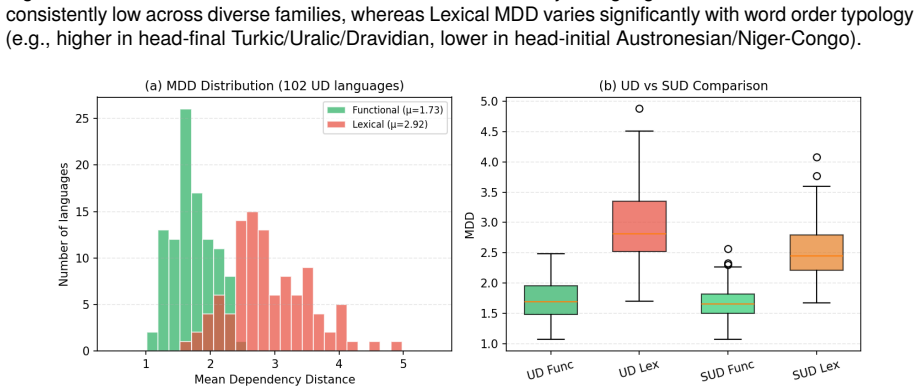
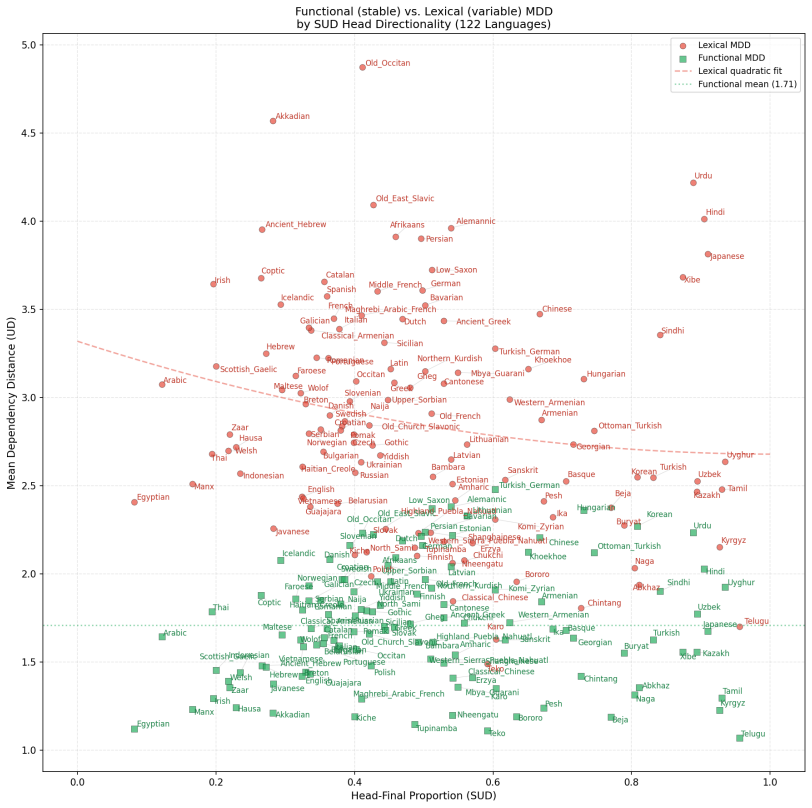
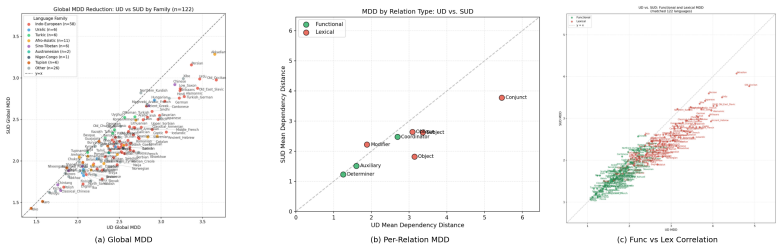
Dependency length minimization operates on two distinct levels. Grammar-driven optimization targets functional dependencies (det, case, aux), which are universally short (mean 1.71, σ = 0.33) and invariant across typologically diverse languages. Processing-driven optimization operates on lexical dependencies (nsubj, obj, obl), which are longer (mean 2.87), highly variable (σ = 0.63), and constrained by word-order typology. This asymmetry holds in SUD despite reversed head direction (r = 0.92). The grammar therefore does the work of minimization by scaffolding sentences with local functional attachments, leaving processing pressures to determine the ordering of lexical heads.
What carries the argument
The functional versus lexical dependency split, with grammar fixing short lengths for the former and processing varying longer lengths for the latter.
If this is right
- Functional dependencies average 1.71 words apart with low variation in all 122 languages examined.
- Lexical dependency lengths average 2.87 words and track basic word-order typology.
- The functional-lexical length asymmetry survives reversal of head direction in the SUD scheme.
- Overall mean dependency distance is largely set by the short functional scaffold.
Where Pith is reading between the lines
- Sentence production models could treat functional attachments as fixed grammar rules separate from variable processing costs on lexical heads.
- Acquisition studies might test whether children first master the short functional links before adjusting lexical orders to their target language.
- Cross-linguistic measures of processing load could improve by computing separate distances for the two dependency layers.
Load-bearing premise
Classifying syntactic relations as functional or lexical accurately separates two different optimization regimes rather than simply reflecting annotation choices.
What would settle it
A language in which functional dependency lengths vary as widely as lexical ones or fail to stay shorter on average would falsify the two-level claim.
Figures
read the original abstract
Dependency length minimization (DLM) is a well-documented processing universal, but previous studies report a single mean dependency distance (MDD) per language, obscuring variation across syntactic relation types. We analyze 122 languages in UD and SUD (version 2.17), showing that DLM operates on two distinct levels. Grammar-driven optimization targets functional dependencies (det, case, aux), which are universally short (mean 1.71, $\sigma$ = 0.33) and invariant across typologically diverse languages. Processing-driven optimization operates on lexical dependencies (nsubj, obj, obl), which are longer (mean 2.87), highly variable ($\sigma$ = 0.63), and constrained by word-order typology. This asymmetry holds in SUD despite reversed head direction (r = 0.92). We conclude that ''the grammar does the work'' of minimization by scaffolding sentences with local functional attachments, leaving processing pressures to determine the ordering of lexical heads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes dependency length minimization (DLM) across 122 languages in UD v2.17 and SUD treebanks. It claims DLM operates on two distinct levels: grammar-driven optimization produces universally short and invariant functional dependencies (det, case, aux; mean 1.71, σ=0.33), while processing-driven optimization produces longer and typologically variable lexical dependencies (nsubj, obj, obl; mean 2.87, σ=0.63). The asymmetry persists in SUD despite reversed head direction (r=0.92), supporting the conclusion that grammar scaffolds sentences via local functional attachments.
Significance. If the functional/lexical distinction is shown to reflect distinct optimization regimes rather than annotation artifacts, the result would refine DLM theory by separating grammatical scaffolding from processing pressures. The large cross-linguistic sample and the SUD control for head directionality are clear strengths that allow a direct test of directionality invariance.
major comments (2)
- [§2 (Methods) and §3 (Results)] §2 (Methods) and §3 (Results): The partition of dependencies into functional (det/case/aux) versus lexical (nsubj/obj/obl) categories is taken directly from the UD label inventory with no independent validation, alternative partitioning, or control for closed-class status. This partition is load-bearing for the central claim that low variance (σ=0.33) reflects grammar scaffolding while high variance (σ=0.63) reflects processing; an annotation-convention account is not ruled out.
- [Abstract and §3 (Results)] Abstract and §3 (Results): Means and standard deviations are reported for the two classes but no statistical tests (e.g., Levene’s test for equality of variances, or permutation tests across languages) are described to establish that the difference in σ (0.33 vs 0.63) is reliable or that functional lengths are significantly more invariant than lexical ones.
minor comments (2)
- [Abstract] Abstract: the correlation coefficient r=0.92 is cited without stating the two variables being correlated (e.g., functional lengths in UD vs SUD).
- [§4 (Discussion)] §4 (Discussion): the phrase “the grammar does the work” is placed in quotation marks but is not attributed to a prior source; either remove the quotes or supply the reference.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, indicating revisions where appropriate to strengthen the analysis.
read point-by-point responses
-
Referee: [§2 (Methods) and §3 (Results)] §2 (Methods) and §3 (Results): The partition of dependencies into functional (det/case/aux) versus lexical (nsubj/obj/obl) categories is taken directly from the UD label inventory with no independent validation, alternative partitioning, or control for closed-class status. This partition is load-bearing for the central claim that low variance (σ=0.33) reflects grammar scaffolding while high variance (σ=0.63) reflects processing; an annotation-convention account is not ruled out.
Authors: The functional/lexical distinction follows standard linguistic categories of function words versus content words, as encoded in the UD inventory. The invariance result replicates in SUD treebanks, which apply a different annotation scheme with reversed head directions, providing evidence against a purely UD-specific artifact. To further validate the partition, we will add an alternative classification based on closed-class status independent of dependency labels and report whether the variance asymmetry persists. revision: partial
-
Referee: [Abstract and §3 (Results)] Abstract and §3 (Results): Means and standard deviations are reported for the two classes but no statistical tests (e.g., Levene’s test for equality of variances, or permutation tests across languages) are described to establish that the difference in σ (0.33 vs 0.63) is reliable or that functional lengths are significantly more invariant than lexical ones.
Authors: We agree that statistical confirmation of the variance difference is required. In the revision we will add Levene’s test for equality of variances together with permutation tests across languages to assess whether functional dependency lengths are significantly more invariant than lexical ones; these results will be reported in §3 and referenced in the abstract. revision: yes
Circularity Check
No circularity; direct empirical measurements on public treebanks
full rationale
The paper reports observed mean dependency lengths and standard deviations computed directly from the 122-language UD v2.17 and SUD corpora for the predefined UD relation labels (det/case/aux vs. nsubj/obj/obl). No equations, fitted parameters, or derived predictions appear; the reported invariance (σ=0.33) and variability (σ=0.63) are raw statistics on the labeled data, and the SUD head-reversal correlation is likewise a direct measurement. No self-citations, uniqueness theorems, or ansatzes are invoked to support the central partition or conclusions. The functional/lexical split is taken from the existing annotation scheme rather than being constructed inside the paper, so the reported asymmetry does not reduce to its own inputs by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mean dependency distance is an appropriate scalar summary for comparing optimization across relation types.
Reference graph
Works this paper leans on
-
[1]
dependency distance minimizationisnotuniversalacrossalldependency types,
Introduction The tendency to minimize the linear distance be- tween syntactically related words — dependency length minimization (DLM) — is one of the best- supported universals in quantitative linguistics (Futrell et al., 2015; Temperley and Gildea, 2018). Within dependency grammar, Hudson (1995) was the first to link dependency distance with process- in...
2015
-
[2]
hard-code
Grammar-driven minimization:Functional heads (determiners, case markers, auxiliaries) areclosed-classitemswhosepositionisstrictly constrained by grammatical linearization rules. These rules “hard-code” minimization by man- dating adjacency (e.g., Det adjacent to Noun)
-
[3]
Processing-drivenminimization: Lexicalde- pendencies (subjects, objects, modifiers) in- volve open-class elements whose ordering is more flexible. Here, minimization is a soft con- straint competing with information structure and other communicative needs. We test this hypothesis on122 languages(all UD/SUD v2.17 languages with≥500 sentences; see §3.1) in ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
typolog- ical/cognitive universal
Related Work 2.1. Dependency Length Minimization DLM has a rich empirical history. Liu (2008) pro- posed MDD as a metric of language comprehen- sion difficulty and was the first to test the DLM hy- pothesis quantitatively across languages; we note that MDD (the mean of per-dependency distances) differs from the dependency length (DL) sum used by Futrell e...
2008
-
[5]
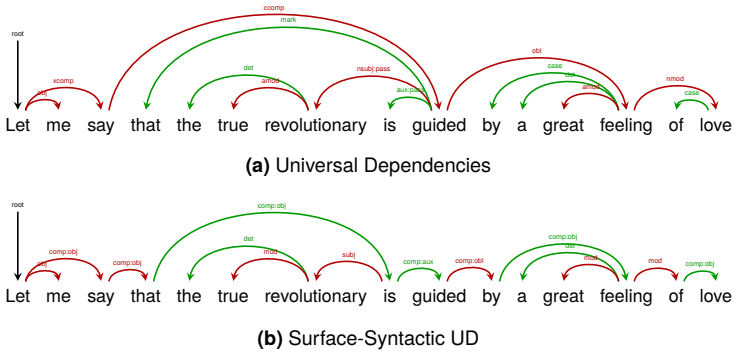
addresses this by promoting function words to head status where distributionally motivated: auxiliaries govern their verbs, adpositions govern their complements, complementizers govern their clauses. This reversal provides a natural test of robustness: since |pos(head) − pos(dep)| is sym- metric, the same word pair produces the same dis- tance regardless ...
1998
-
[6]
Treebank Selection We analyze all treebanks from UD v2.17 (Zeman et al., 2025)
Data and Methodology 3.1. Treebank Selection We analyze all treebanks from UD v2.17 (Zeman et al., 2025). To ensure validity, we aggregate data at the language level: for each language, we concatenate all treebanks into a single corpus. We exclude languages with fewer than 500 sen- tences.1 This yields a matched set of122 lan- guages in UD and SUD, encomp...
2025
-
[7]
MDD: Mean absolute distance|pos(head) − pos(dep)|over non-punctuation tokens, exclud- ing root dependencies (Liu et al., 2017)
2017
-
[8]
Random baseline: To estimate the expected distance under no DLM pressure, we ran- domly permute thelinear positionsof all non- punctuation tokens in a sentence while keep- ing the dependency tree structure (i.e., who depends on whom) fixed. Each permutation reassignseverytokentoanewposition, sothe same tree is linearized in a different random order; depen...
2015
-
[9]
Optimality ratio(OR): MDDobs/MDDrand, fol- lowing the formalization of Ferrer-i Cancho et al. (2022). This provides a normalized mea- sure of optimization: an OR of 1.0 suggests a language is no more optimized than chance, while values approaching 0.0 indicate extreme minimization
2022
-
[10]
Figure 1: Distribution of Functional vs
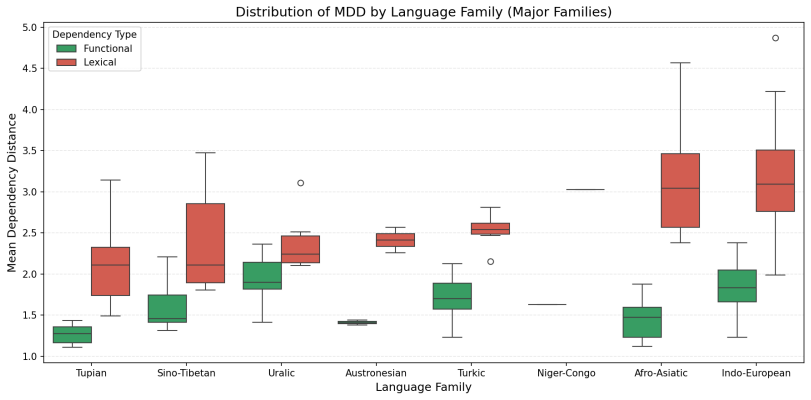
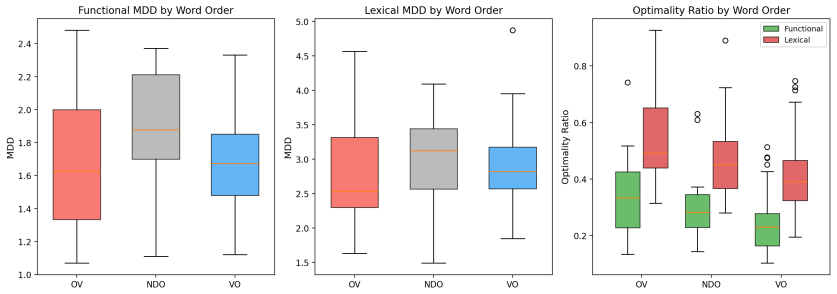
HeadDirectionality: Theproportionofdepen- dencieswheretheheadfollowsthedependent (pos(head) > pos(dependent)). Figure 1: Distribution of Functional vs. Lexical MDD across major language families. Functional MDD is consistentlylowacrossdiversefamilies, whereasLexicalMDDvariessignificantlywithwordordertypology (e.g., higher in head-final Turkic/Uralic/Dravi...
-
[11]
Overall DLM Confirmation All 122 UD languages exhibit strong DLM
Results 4.1. Overall DLM Confirmation All 122 UD languages exhibit strong DLM. Ob- served MDD ranges from 1.44 to 3.67, far be- low random baselines (optimality ratios 0.17–0.89, mean 0.41). This confirms Futrell et al. (2015) at scale and extends the finding to new languages. 4.2. The Functional–Lexical Asymmetry Table1presentsthecentralresult,showingbot...
2015
-
[12]
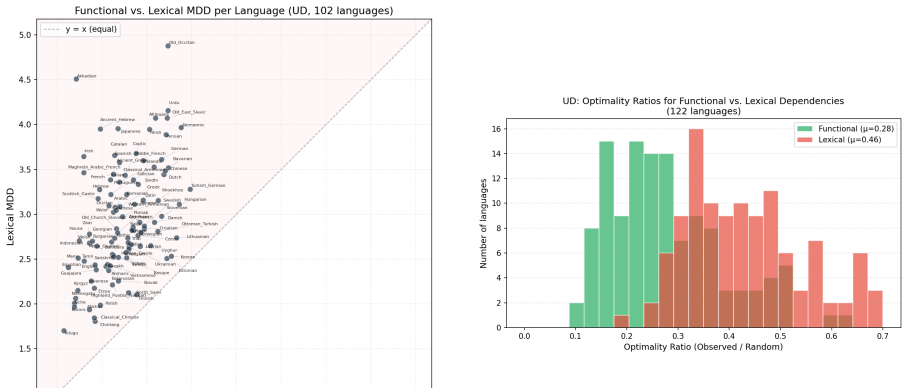
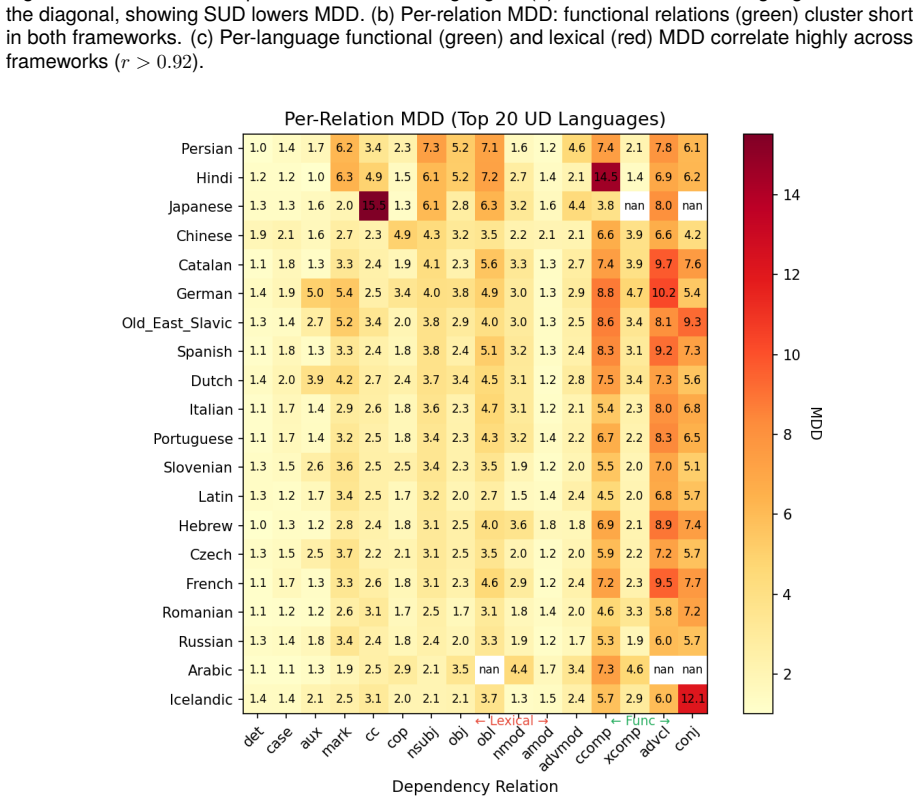
Functional MDD is universally low.Across 122 UD languages, functional MDD averages 1.71 with a standard deviation of only 0.33. This nar- row distribution (Figure 2) shows that grammars universally constrain function words to appear ad- jacent to their hosts, regardless of language family Figure 3: (a) Functional vs. lexical MDD per lan- guage (122 UD lan...
-
[13]
less optimized than functional
Lexical dependencies also show strong DLM. Crucially, lexical dependencies are not merely “less optimized than functional”: with a mean optimality ratio of 0.46 (σ = 0.15), they are 54% shorter than random baselines in every single language (122/122, OR range 0.20–0.93). This confirms that genuine processing-driven minimiza- tion operates on lexical depen...
2023
-
[14]
no dominant order
The two levels differ in optimization depth. The mean functional optimality ratio is 0.28, versus 0.46 for lexical — both well below chance, but func- tional OR is 39% lower. This gap reflects different optimization mechanisms: functional adjacency is categorically enforced by grammar, while lexical ordering is a softer, gradient optimization that com- pe...
2010
-
[15]
Discussion Our results disentangle two components of the universal DLM signal reported by Temperley and Gildea (2018) and Futrell et al. (2015).Grammar- driven functional optimization: functional ele- ments are positioned adjacent to their hosts by grammatical rules (Temperley, 2008); the univer- sally low functional MDD (1.71± 0.33) is a pre- dictable co...
2018
-
[16]
I always dreamt of becoming a syntactician and a typologist one day. I want to submit a paper to the UDW workshop. Can you help me?
Conclusion Across 122 languages, we find that depen- dency length minimization is not a monolithic phe- nomenon but a composite of two distinct forces. The grammar does the work— but processing does too. Functional dependencies aregrammat- ically minimized: by mandating local attachment for functional items (det, case, aux), the grammar guarantees a basel...
1965
-
[17]
In Proceedings of the Tenth International Conference on Dependency Linguistics (Depling, GURT/SyntaxFest 2025)
Menzerath’s law in universal dependen- cies. In Proceedings of the Tenth International Conference on Dependency Linguistics (Depling, GURT/SyntaxFest 2025). Ramon Ferrer-i Cancho, Carlos Gómez-Rodríguez, and Juan Luis Esteban. 2022. Optimality of syn- tactic dependency distances.Physical Review E, 105:014308. Richard Futrell, Roger P. Levy, and Edward Gibson
2025
-
[18]
Richard Futrell, Kyle Mahowald, and Edward Gib- son
Dependency locality as an explanatory principle for word order.Language, 96(2):371– 412. Richard Futrell, Kyle Mahowald, and Edward Gib- son. 2015. Large-scale evidence of dependency length minimization in 37 languages. In Pro- ceedings of the National Academy of Sciences, volume 112, pages 10336–10341. Ning Gao and Qingshun He. 2024. A dependency distanc...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.