CausalSteward: An Agentic Divide-Conquer-Combine Copilot for Causal Discovery
Pith reviewed 2026-07-03 03:13 UTC · model grok-4.3
The pith
A multi-agent system divides high-dimensional causal discovery into partitions that agents analyze separately before recombining with prior knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
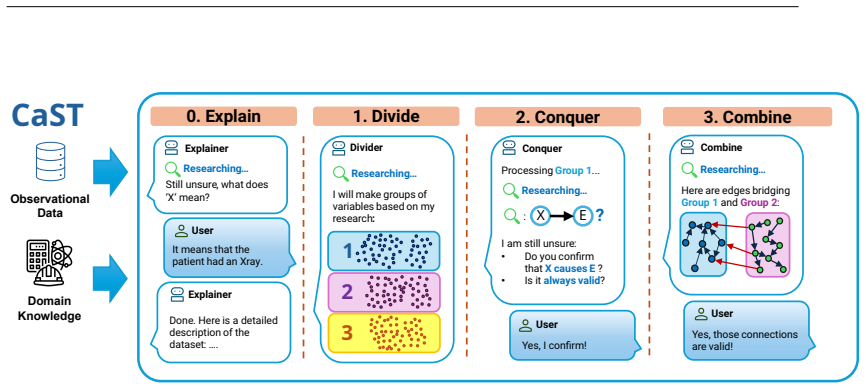
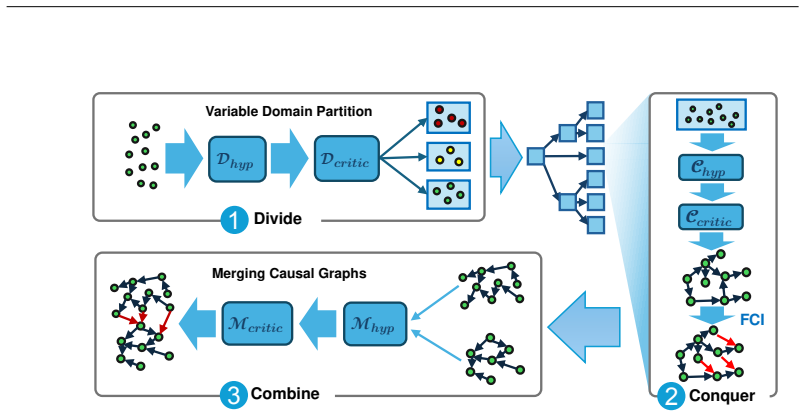
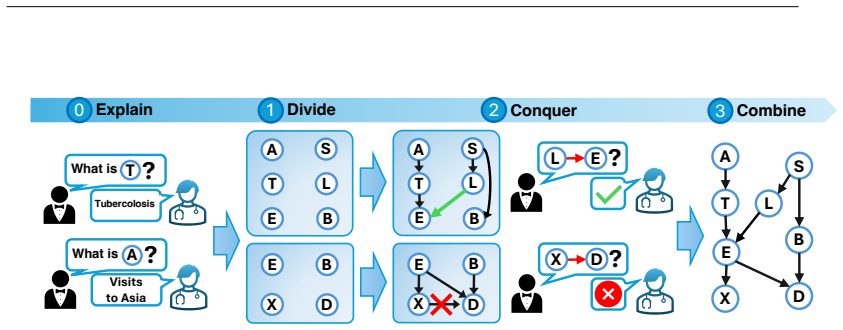
We introduce CausalSTeward (CAST), a novel human-in-the-loop framework for interactively assembling large causal models. CausalSteward is a multi-agent collaborative system that tackles high-dimensional causality through a divide-and-conquer approach where large clusters of variables are iteratively partitioned and then separately analyzed. Our framework fuses prior knowledge with a data-driven approach by using tailored tools such as retrieval augmented generation and conditional independence tests. Finally, we use this work to examine the capabilities and limitations of causal reasoning in multi-agent frameworks, and how the human-in-the-loop can contribute to accurate and trustworthy resu
What carries the argument
Divide-and-conquer multi-agent architecture that partitions variable clusters for separate analysis, then recombines outputs using retrieval-augmented generation for priors and conditional independence tests on data.
If this is right
- Large causal models become feasible to construct even when the number of variables makes direct analysis intractable.
- Prior knowledge retrieved from external sources can be fused with data-driven tests without introducing new identifiability issues.
- Multi-agent collaboration clarifies both the strengths and limits of automated causal reasoning.
- Human-in-the-loop guidance yields models that are more accurate and trustworthy than fully automated alternatives.
Where Pith is reading between the lines
- The partitioning step may need safeguards so that early splits do not force later agents into inconsistent subproblems.
- The same divide-and-conquer pattern could be tested on other structured reasoning tasks such as large-scale Bayesian network learning.
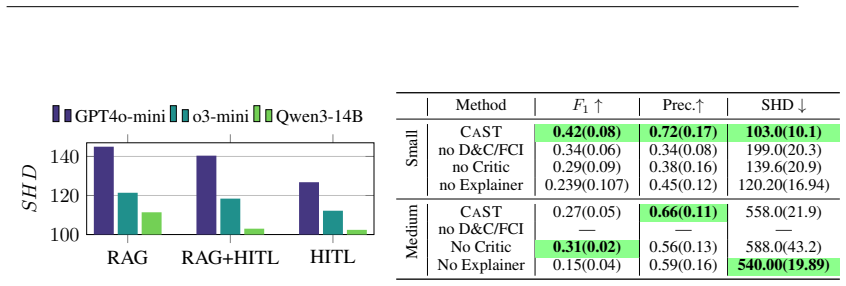
- Benchmark experiments on known graphs would show whether retrieval-augmented priors measurably improve recovery rates over data-only baselines.
Load-bearing premise
The multi-agent divide-and-conquer process with retrieval augmented generation and conditional independence tests integrates prior knowledge without creating fresh identifiability problems, and human oversight reliably produces accurate models.
What would settle it
Apply the system to a high-dimensional synthetic dataset whose true causal graph is known in advance and check whether the final assembled graph recovers the true edges or correctly predicts the outcomes of interventions.
Figures

read the original abstract
Learning causal models from high-dimensional data is a significant challenge, particularly in real-world settings where violations of core assumptions lead to causal identifiability issues. Although massive amounts of prior knowledge are available, and contain valuable causal information, effectively integrating this knowledge into the causal discovery process remains an open problem. We introduce CausalSTeward (CAST), a novel human-in-the-loop framework for interactively assembling large causal models. CausalSteward is a multi-agent collaborative system that tackles high-dimensional causality through a divide-and-conquer approach where large clusters of variables are iteratively partitioned and then separately analyzed. Our framework fuses prior knowledge with a data-driven approach by using tailored tools such as retrieval augmented generation and conditional independence tests. Finally, we use this work to examine the capabilities and limitations of causal reasoning in multi-agent frameworks, and how the human-in-the-loop can contribute to accurate and trustworthy results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CausalSteward (CAST), a human-in-the-loop multi-agent collaborative framework for assembling large causal models from high-dimensional data. It proposes an iterative divide-and-conquer strategy that partitions variables into clusters for separate analysis using conditional independence tests and retrieval-augmented generation to fuse prior knowledge, followed by a combine phase, with the aim of mitigating identifiability issues and exploring the role of multi-agent systems and human input in causal reasoning.
Significance. If the framework were shown to work, it could meaningfully advance scalable causal discovery by combining agentic collaboration, RAG-based prior integration, and human oversight to handle settings where standard algorithms struggle with dimensionality and identifiability. The divide-conquer-combine structure and explicit human-in-the-loop component represent a novel direction worth exploring. No machine-checked proofs, reproducible code, or falsifiable predictions are presented, so these potential strengths remain unrealized in the current manuscript.
major comments (3)
- [Abstract] Abstract: the central claims that the multi-agent divide-and-conquer approach with RAG and CI tests 'effectively integrates prior knowledge' and yields 'accurate and trustworthy results' rest entirely on description; the manuscript supplies no experiments, datasets, error analysis, identifiability proofs, or quantitative results to support these assertions.
- [Framework description] Framework description (divide-and-conquer section): the claim that iterative partitioning followed by per-cluster analysis and combination assembles accurate global causal models lacks any algorithm or procedure for cross-cluster conditional independence testing; without such a mechanism, inter-cluster edges may be lost or rendered unidentifiable, violating the global Markov condition required for consistent recovery in the combine step.
- [Framework description] Framework description (combine phase): no analysis is given of how RAG-derived priors from separate clusters are reconciled when they conflict or how human input is formalized to guarantee consistency with the data-driven CI tests across partitions.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the multi-agent divide-and-conquer approach with RAG and CI tests 'effectively integrates prior knowledge' and yields 'accurate and trustworthy results' rest entirely on description; the manuscript supplies no experiments, datasets, error analysis, identifiability proofs, or quantitative results to support these assertions.
Authors: The manuscript presents a novel framework conceptually, without empirical evaluation at this stage. We will revise the abstract to moderate the claims, emphasizing that the work introduces the approach and discusses its potential rather than asserting proven effectiveness. We will also include a new section on limitations and future empirical work. revision: yes
-
Referee: [Framework description] Framework description (divide-and-conquer section): the claim that iterative partitioning followed by per-cluster analysis and combination assembles accurate global causal models lacks any algorithm or procedure for cross-cluster conditional independence testing; without such a mechanism, inter-cluster edges may be lost or rendered unidentifiable, violating the global Markov condition required for consistent recovery in the combine step.
Authors: We agree that the description is incomplete regarding cross-cluster dependencies. In the revised manuscript, we will specify that the combine phase includes a step where agents propose potential inter-cluster edges, which are then validated using global conditional independence tests on the full dataset, with human oversight to resolve ambiguities. revision: yes
-
Referee: [Framework description] Framework description (combine phase): no analysis is given of how RAG-derived priors from separate clusters are reconciled when they conflict or how human input is formalized to guarantee consistency with the data-driven CI tests across partitions.
Authors: This point is well-taken. We will expand the combine phase description to include a reconciliation protocol for conflicting priors, such as weighting by retrieval confidence scores and using human input as a final arbiter for consistency. This will be formalized as part of the iterative process. revision: yes
Circularity Check
No circularity: framework proposal contains no derivations or fitted predictions
full rationale
The manuscript introduces a multi-agent divide-and-conquer framework for causal discovery but presents no equations, parameter fits, uniqueness theorems, or quantitative predictions. The abstract and description remain at the level of system architecture (partitioning, RAG, CI tests, human-in-the-loop) without any step that reduces a claimed result to its own inputs by construction. No self-citations are shown to bear the load of a central premise, and the work is self-contained as a descriptive proposal rather than a deductive chain. This is the expected honest outcome for a framework paper lacking mathematical derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Prior knowledge contains valuable causal information that can be fused with data-driven methods via RAG and conditional independence tests
- domain assumption Divide-and-conquer partitioning of variable clusters preserves causal identifiability when recombined
invented entities (1)
-
CausalSteward (CAST) multi-agent collaborative system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Featured Certification
URLhttps://openreview.net/forum?id=mqoxLkX210. Featured Certification. Neville K Kitson and Anthony C Constantinou. Causal discovery using dynamically requested knowledge,
-
[2]
S´ebastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien
URLhttps://arxiv.org/abs/2310.11154. S´ebastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient-based neural DAG learning. In8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020. URLhttps://openreview.net/forum? id=rklbKA4YDS. S. L. Lauritzen ...
-
[3]
URLhttps://openreview.net/forum?id=C9wTM5xyw2. Joris M. Mooij, Jonas Peters, Dominik Janzing, Jakob Zscheischler, and Bernhard Sch¨olkopf. Distinguishing cause from effect using observational data: Methods and benchmarks.Journal of Machine Learning Research, 17(32):1–102, 2016. URLhttp://jmlr.org/papers/v17/14-518.html. Achille Nazaret and David Blei. Ext...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.24963/ijcai.2022/675 2016
-
[4]
doi: 10.7551/mitpress/1754.001.0001
ISBN 9780262284158. doi: 10.7551/mitpress/1754.001.0001. URLhttps://doi.org/10. 7551/mitpress/1754.001.0001. Nicholas Tagliapietra, Juergen Luettin, Lavdim Halilaj, Moritz Willig, Tim Pychynski, and Kristian Kerst- ing. Causalman: A physics-based simulator for large-scale causality, 2025. URLhttps://arxiv. org/abs/2502.12707. Masayuki Takayama, Tadahisa O...
-
[5]
Ruibo Tu, Kun Zhang, Bo Christer Bertilson, Hedvig Kjellstr ¨om, and Cheng Zhang
URLhttps://arxiv.org/abs/2402.01454. Ruibo Tu, Kun Zhang, Bo Christer Bertilson, Hedvig Kjellstr ¨om, and Cheng Zhang. Neuropathic pain diagnosis simulator for causal discovery algorithm evaluation, 2019. URLhttps://arxiv.org/ abs/1906.01732. Ruibo Tu, Chao Ma, and Cheng Zhang. Causal-discovery performance of chatgpt in the context of neuro- pathic pain d...
-
[6]
CAUSALSTEWARD: ANAGENTICDIVIDE-CONQUER-COMBINE COPILOT FORCAUSALDISCOVERY
doi: 10.1109/TCYB.2020.3010004. Jiji Zhang. Causal reasoning with ancestral graphs.Journal of Machine Learning Research, 9(47):1437– 1474, 2008. URLhttp://jmlr.org/papers/v9/zhang08a.html. Kun Zhang and Aapo Hyvarinen. On the identifiability of the post-nonlinear causal model, 2012. URL https://arxiv.org/abs/1205.2599. Yizhou Zhang, Lun Du, Defu Cao, Qian...
-
[7]
We know that 23 and can be violated with probabilityδ/2, and by union bound it holds that ifP(A)< δ/2 andP(B)< δ/2, thenP(A∪B)≤P(A) +P(B)< δ/2 +δ/2 =δ
Similarly, for false positives we have that∀t >0it holds that P r(F Pinter −E[F P inter]≥t)≤exp − 2t2 m ,(24) which, with a procedure completely identical to the one above, we can obtain, F Pinter ≤E[F P inter] + r m·ln(2/δ) 2 ,(25) holding with probability≥1−δ/2. We know that 23 and can be violated with probabilityδ/2, and by union bound it holds that if...
-
[8]
This pro- duces a spurious adjacencies
The conditioning setZnot being present within the partition due to a bad partitioning. This pro- duces a spurious adjacencies
-
[9]
This results in aF PLLM term
The LLM agentsC hyp andC critic choosing a wrong prior constraint. This results in aF PLLM term. Therefore we haveF P intra =SA+E[F P LLM]. For the By summing those terms, we get SHD intra =SA+F P LLM +F N intra,(32) and by linearity of expectation, we also have E[SHD intra] =SA+E[F P LLM] +E[F N intra],(33) which terminates our proof. The precision of th...
-
[10]
SinceZ⊂P 2 ⊂V=⇒u⊥v|Zwithu, v,Z∈V=⇒ No edge betweenuandv
An edge (any type) is present inG 1 but not inG 2: In this case, it means there exist a conditioning set s.t.u⊥v|ZwithZ∈P 2 andZ/∈P 1. SinceZ⊂P 2 ⊂V=⇒u⊥v|Zwithu, v,Z∈V=⇒ No edge betweenuandv
-
[11]
If the edgeu→vis present inG 1, but the edgev◦ − ◦uis present inG 2, we insert theu◦ −> vedge
For all other cases, we ”overlap” the causal relationship: If the edgeu→vis present inG 1, but the opposite onev→uis also present inG 2, we insert a bi-directed edge. If the edgeu→vis present inG 1, but the edgev◦ − ◦uis present inG 2, we insert theu◦ −> vedge. Also other available methods leveraging Divide&Conquer adopt approximations to manage conflicts...
2025
-
[12]
A Query agent receives the queryQ, and translates it into keywords to be used on a search engine. 28
-
[13]
A web-search API is executed with the keywords, and we extract the 5 best results
-
[14]
A summary agent aggregates all results by writing a summary
-
[15]
A reflection agent reflects on the summary and extrapolate further causal information
-
[16]
A” causes “B
A final summary agent provides a conclusive answer with a comprehensive explanation. D DIVIDE-CONQUER-COMBINEALGORITHM Before detailing the logic of the process, we clarify the organization of variable partitions and their local causal graphs. Each partition is represented asP i, with its corresponding local causal graph defined as Gi :=G(P i,E i), whereE...
2025
-
[17]
You can use the tools to search for more information
Understand the context, about what are the variables modeling at a causal level. You can use the tools to search for more information
-
[18]
Suc- cessively, reason on the relationships between those root nodes and the other child variables
Reason on which might be the root nodes which are not influenced by other variables. Suc- cessively, reason on the relationships between those root nodes and the other child variables. Then reason between children of children, and so on
-
[19]
DO NOT BE TOO CONSERV ATIVE
Output a preliminary list of all edges that COULD POTENTIALLY be present between those variables. DO NOT BE TOO CONSERV ATIVE. AN EDGE MORE IS BETTER THAN AN EDGE LESS
-
[20]
Finally, output a cumulative list of directed edges between the provided variables
Reflect and improve your estimate. Finally, output a cumulative list of directed edges between the provided variables. IMPORTANT: Make sure the the list of edges are within the<edges>tags. For example: <edges>(Variable1, Variable2), (Variable2, Variable3)</edges> IMPORTANT: ABSOLUTELY RESPECT THE FORMAT. DO NOT USE ARROWS OR ANY- THING SIMILAR TO REPRESEN...
-
[24]
If available, use the human expert for confirmation or for contextual knowledge
Utilize the available tools to gather additional information and evidence to support your analysis. If available, use the human expert for confirmation or for contextual knowledge. Finally, provide a cumulative list of directed edges identified at each iteration for every group of variables. IMPORTANT: Ensure that the list of edges is enclosed within<edge...
-
[25]
Understand how each groups is related to each other
Understand the context, about what is each group of variables modeling at a causal level. Understand how each groups is related to each other. You can use the tools to search for more information
-
[26]
DO NOT BE TOO CONSERV ATIVE
Output a preliminary list of bridging edges that COULD POTENTIALLY be present be- tween those groups of variables. DO NOT BE TOO CONSERV ATIVE. AN EDGE MORE IS BETTER THAN AN EDGE LESS
-
[27]
Finally, present a single list of directed edges that connect the groups
Reflect and improve your estimate. Finally, present a single list of directed edges that connect the groups. IMPORTANT: Ensure the list of edges is enclosed within<edges>tags. For example: <edges>(Variable1, Variable2), (Variable2, Variable3)</edges> IMPORTANT: ABSOLUTELY RESPECT THE FORMAT. DO NOT USE ARROWS OR ANY- THING SIMILAR TO REPRESENT EDGES. ONLY...
-
[28]
Evaluate the proposed relationships between the variables
-
[29]
Consider that intervening on the effect should not change the cause, but not the viceversa
Assess whether any edges are in the anti-causal direction (i.e., (effect, cause) instead of (cause, effect)). Consider that intervening on the effect should not change the cause, but not the viceversa
-
[30]
Do those causal relationships always hold, or only on some context? Think about counter- factual scenarios
-
[31]
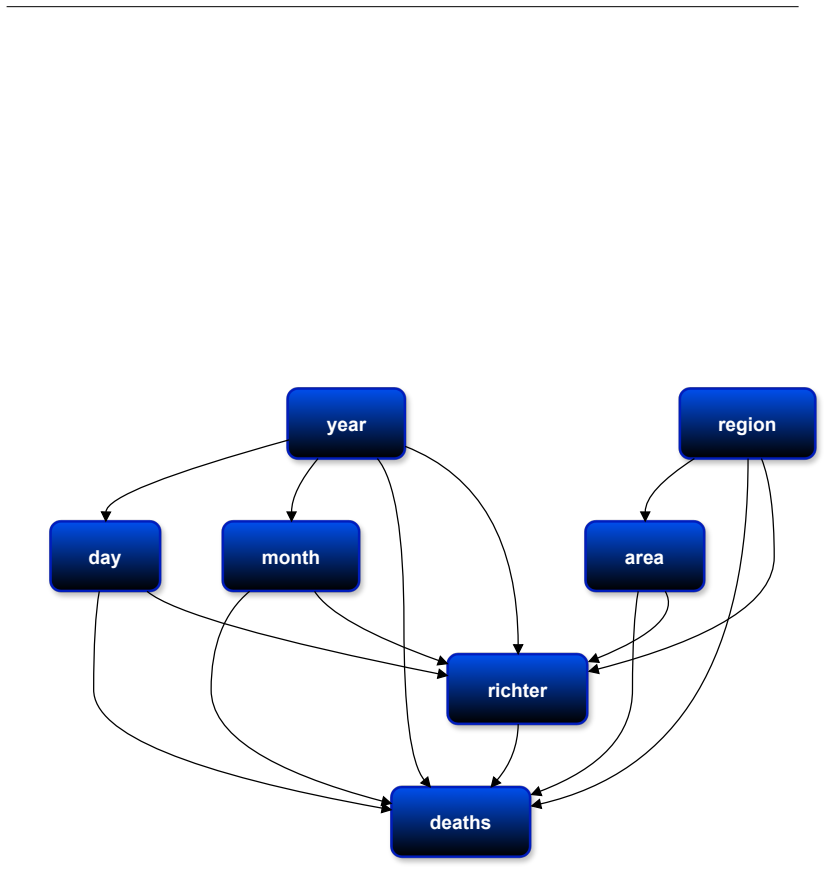
richter
Utilize the available tools to gather additional information and evidence to support your analysis. If available, use the human expert for confirmation or for contextual knowledge. Provide a summary of your findings, including any necessary revisions to the proposed connections. IMPORTANT: Ensure the list of edges is enclosed within<edges>tags. For exampl...
2023
-
[32]
Theyearaffects whether certain days are valid (e.g., February 29 exists only in leap years), so the permissible values ofdaydepend onyearfor some months
EVALUATION OFPROPOSEDRELATIONSHIPS (year, day)Valid as a structural constraint in the Gregorian calendar. Theyearaffects whether certain days are valid (e.g., February 29 exists only in leap years), so the permissible values ofdaydepend onyearfor some months. (month, day)Valid as a structural constraint. Themonthdetermines the range of valid days (e.g., 3...
-
[33]
Intervening ondaydoes not changeyearormonth, whereas intervening onyearormonthcan change whichdayvalues are valid
ANTI-CAUSALDIRECTIONASSESSMENT Neither edge is in the anti-causal direction. Intervening ondaydoes not changeyearormonth, whereas intervening onyearormonthcan change whichdayvalues are valid. Thus, the direction fromyear→dayandmonth→dayis appropriate
-
[34]
Counterfactual examples: • If we setmonth=February and intervene to changeyearfrom a leap year to a non-leap year, the set of validdayvalues changes (29 becomes invalid)
CONTEXTUALVALIDITY ANDCOUNTERFACTUALS These relationships hold under the Gregorian calendar and similar systems where day validity de- pends on month and sometimes year. Counterfactual examples: • If we setmonth=February and intervene to changeyearfrom a leap year to a non-leap year, the set of validdayvalues changes (29 becomes invalid). • If we setyearf...
-
[35]
The relationships are deterministic constraints rather than causal mechanisms in the physical sense, but they are directionally correct for data-generating validity
ADDITIONALCONSIDERATIONS No additional confounders amongyear,month, anddayare necessary for validity constraints. The relationships are deterministic constraints rather than causal mechanisms in the physical sense, but they are directionally correct for data-generating validity. FINALCUMULATIVEEDGES (year,day),(month,day) 46 Conquer Hypothesis Agent for v...
-
[36]
In a gener- ative sense (e.g., administrative structure or modeling of where events occur),regionconstrains the set of possible areas
EVALUATION OFPROPOSEDRELATIONSHIPS The dataset defines a spatial hierarchy whereareais typically nested withinregion. In a gener- ative sense (e.g., administrative structure or modeling of where events occur),regionconstrains the set of possible areas. This supports(region,area). The reverse edge(area,region)implies a causal effect of the specific localit...
-
[37]
ASSESSMENT OFANTI-CAUSALDIRECTIONS The edge(area,region)is anti-causal under intervention semantics. Intervening onarea(e.g., selecting a different locality within the same region) does not change theregion; however, inter- vening onregion(e.g., focusing on a different country) changes the set of permissible areas. Thus, (area,region)is an effect-to-cause...
-
[38]
This yields a functional dependency that may appear as(area,region)in a data-processing DAG
CONTEXTS ANDCOUNTERFACTUALS In practice,regioncan be algorithmically derived fromareadue to hierarchical coding. This yields a functional dependency that may appear as(area,region)in a data-processing DAG. However, causally, the broader spatial context constrains the finer one; therefore, the correct causal direction is(region,area)across typical earthqua...
-
[39]
FINALCUMULATIVEEDGES (region,area) 47 Conquer Hypothesis Agent for Partition Richter/Deaths ANALYSIS OFMAGNITUDE–DEATHRELATIONSHIP
METHODOLOGICALNOTE No additional human input required beyond the dataset’s provided hierarchy; the conclusion follows from the spatial nesting and intervention logic. FINALCUMULATIVEEDGES (region,area) 47 Conquer Hypothesis Agent for Partition Richter/Deaths ANALYSIS OFMAGNITUDE–DEATHRELATIONSHIP
-
[40]
Higher magnitude tends to cause stronger shaking and more potential damage
CONTEXTUNDERSTANDING •richter:Represents earthquake magnitude on a logarithmic scale, which determines ground-motion amplitude and released energy. Higher magnitude tends to cause stronger shaking and more potential damage. •deaths:Represents recorded fatalities due to each event. Fatalities occur downstream of shaking and damage, and are modulated by man...
-
[41]
deathsis downstream ofrichter
ROOTNODES ANDRELATIONSHIPS Among the provided variables,richteris a root cause in the physical sense: the magnitude of the event is generated by tectonic processes and is not influenced by the number of deaths. deathsis downstream ofrichter. The causal pathway is: richter→shaking intensity/damage→casualties (Note: Many mediators/moderators are not in the ...
-
[42]
Larger magnitudes generally increase the risk and extent of damage, increasing fatalities
PRELIMINARYEDGES Potential edge:(richter,deaths). Larger magnitudes generally increase the risk and extent of damage, increasing fatalities
-
[43]
confounders
REFLECTION ANDIMPROVEMENT •Reverse causation(deaths→richter)is not plausible because fatalities do not de- termine physical magnitude. •Confoundingexists (e.g., population density, building standards, depth), but those are not provided variables; the best graph over the two variables isrichter→deaths. •Measurement/reporting biasescan affectdeathsbut do no...
-
[44]
CONTEXTUNDERSTANDING •year:Represents the calendar time of the earthquake event. At a causal level,yearis a proxy for secular changes such as urbanization, exposure, building codes, enforcement, infrastructure resilience, emergency response capacity, and reporting completeness. These time-varying factors can influence the number of recorded deaths per eve...
-
[45]
•yearcan influencedeathsvia: –True vulnerability/exposure changes over time (population growth, urbanization pat- terns)
ROOTNODES ANDRELATIONSHIPS •yearis a root node in this two-variable system: it is exogenous and not caused by deaths. •yearcan influencedeathsvia: –True vulnerability/exposure changes over time (population growth, urbanization pat- terns). –Improvements in building codes and enforcement reducing fatalities. –Changes in emergency response capacity and medi...
-
[46]
•(deaths,year): Considered but likely implausible because outcomes do not set calendar time
PRELIMINARYLIST OFPOTENTIALEDGES (Being expansive) •(year,deaths): Plausible and expected. •(deaths,year): Considered but likely implausible because outcomes do not set calendar time
-
[47]
region/area
REFLECTION ANDIMPROVEMENT The only defensible causal direction between these two variables isyear→deaths. Year func- tions as a surrogate for multiple evolving causal mechanisms that affect fatalities and for reporting- era effects that change recorded deaths. There is no credible mechanism whereby deaths would cause the year of occurrence. FINALEDGEDETER...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.