Probing Chemical Language Models: Effects of Pre-training and Fine-tuning
Pith reviewed 2026-07-03 17:07 UTC · model grok-4.3
The pith
Pre-training improves chemical language models' molecular structure awareness in upper layers while fine-tuning targets task-relevant substructures
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
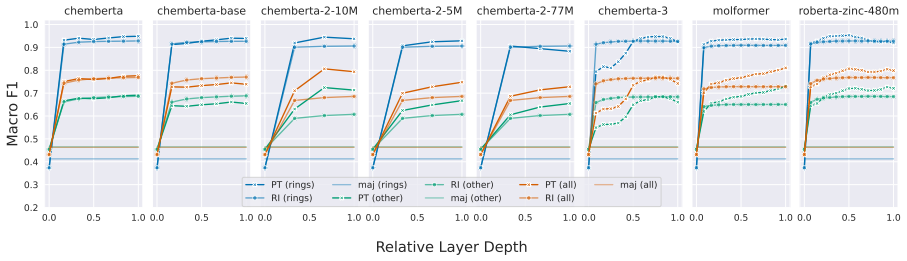
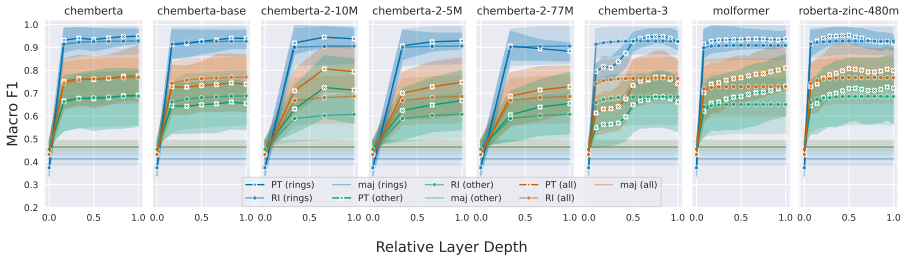
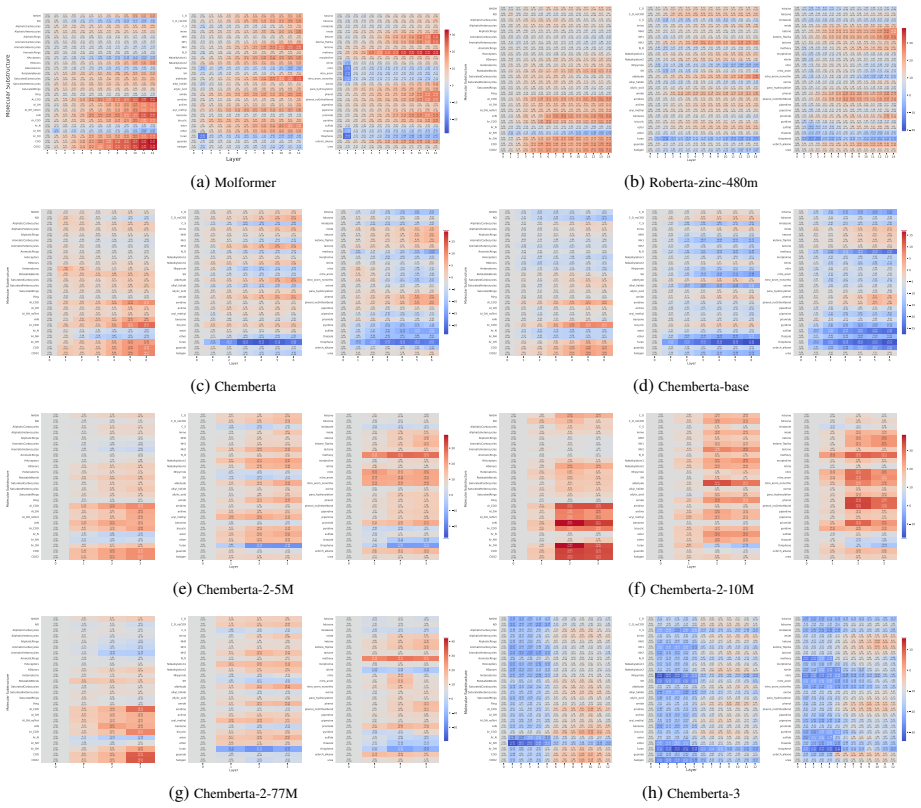
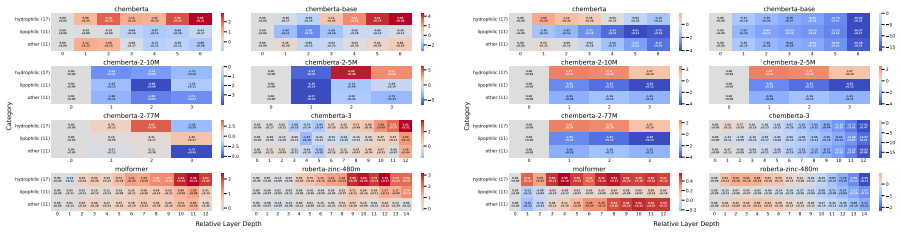
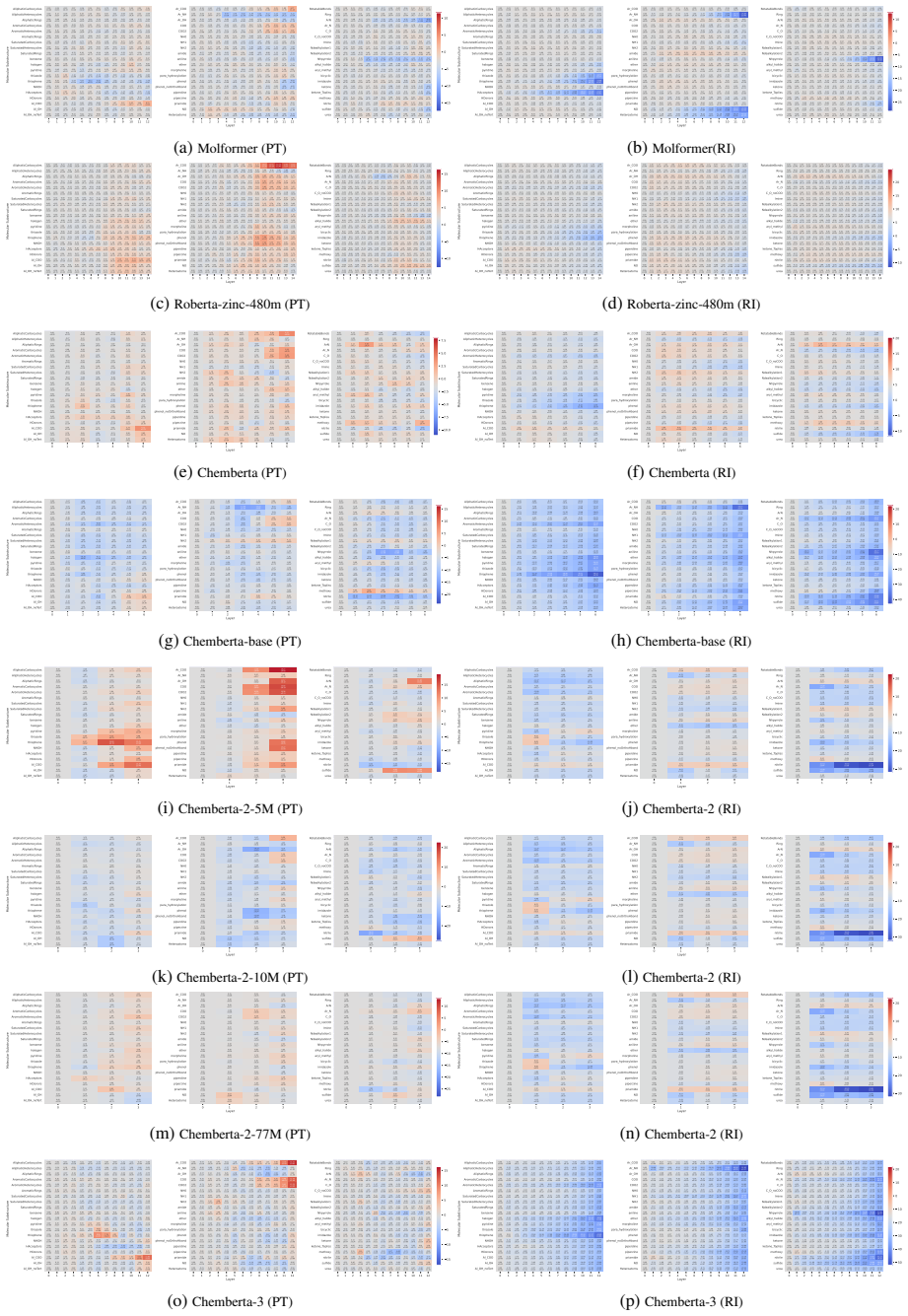
Our results show that pre-training generally improves molecular structure awareness of CLMs, particularly in the upper layers. Moreover, randomly initialized models already encode ring structures well in the first layer. Our analysis on two chemical downstream tasks further reveals that, interestingly, fine-tuning affects task-relevant molecular substructures more than others, indicating that the changes in the representations follow chemical theory.
What carries the argument
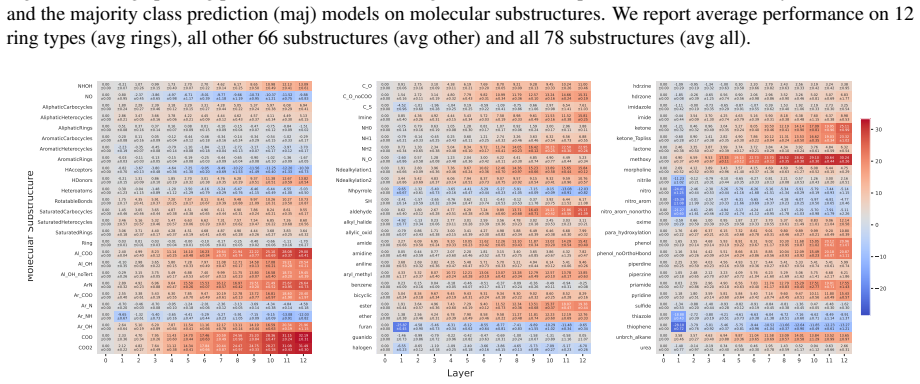
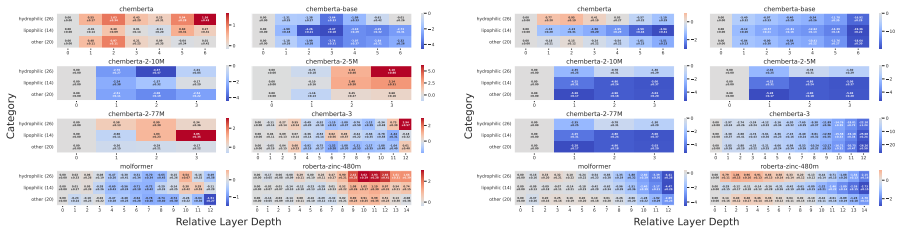
Probing activations for 78 molecular substructures across layers in eight pre-trained and six randomly initialized CLMs, before and after fine-tuning on chemical tasks.
Load-bearing premise
The chosen set of 78 substructures and the activation-based probing method accurately reflect the models' chemically meaningful internal encodings without selection bias from the tasks.
What would settle it
Finding no greater change in representations of task-relevant substructures than irrelevant ones after fine-tuning on a chemical task would falsify the claim that changes follow chemical theory.
Figures


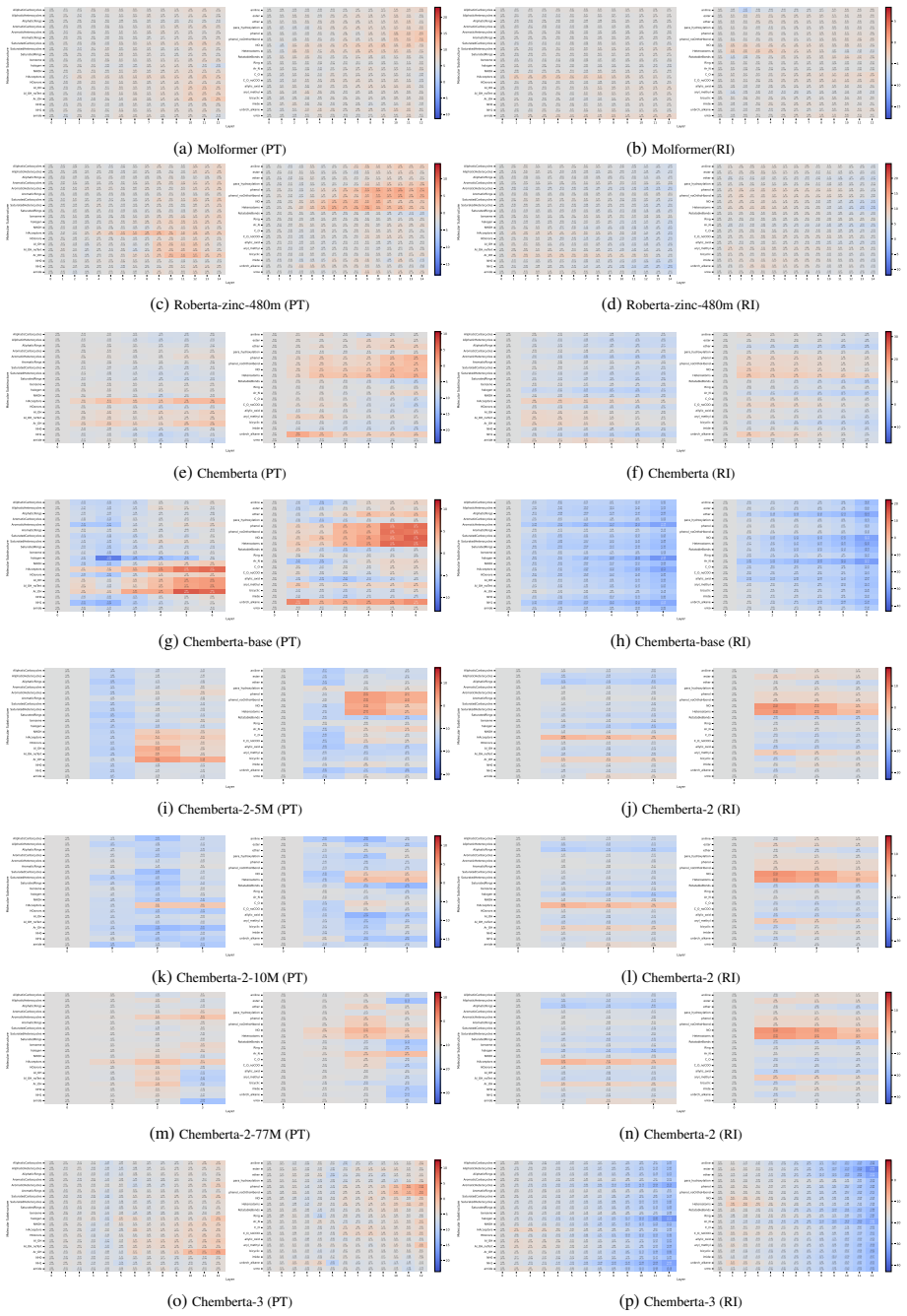
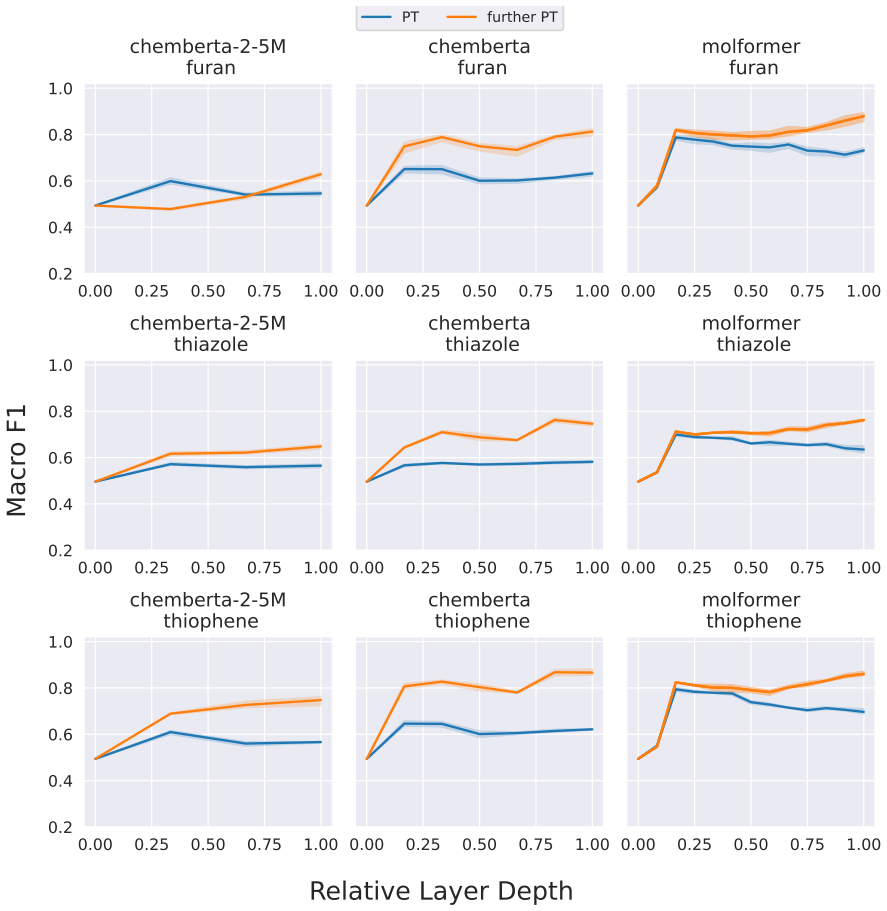

read the original abstract
Chemical language models (CLMs) are trained with linearized representations such as SMILES, yet it remains unclear which chemically meaningful substructures they encode. To foster a better understanding of CLMs, we conduct a systematic study and probe for 78 molecular substructures across eight pre-trained and six randomly initialized models. We furthermore study how fine-tuning on chemical downstream tasks affects the learned representations of molecular substructures. Our results show that pre-training generally improves molecular structure awareness of CLMs, particularly in the upper layers. Moreover, randomly initialized models already encode ring structures well in the first layer. Our analysis on two chemical downstream tasks further reveals that, interestingly, fine-tuning affects task-relevant molecular substructures more than others, indicating that the changes in the representations follow chemical theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper probes eight pre-trained and six randomly initialized chemical language models (CLMs) on SMILES strings for the presence of 78 molecular substructures. It reports that pre-training improves molecular structure awareness (especially in upper layers), that randomly initialized models already encode ring structures well in layer 1, and that fine-tuning on two downstream tasks selectively alters representations of task-relevant substructures in a manner consistent with chemical theory.
Significance. If the probing methodology is shown to be robust against SMILES-syntax confounds and substructure-selection bias, the work would provide useful empirical insight into the internal representations of CLMs for chemistry. The multi-model design and downstream-task analysis are positive features; however, the current lack of methodological detail and controls limits the strength of the conclusions.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the directional claims (pre-training improves upper-layer structure awareness; fine-tuning selectively affects task-relevant substructures) are stated without any description of the probing technique, the precise activation metric, statistical tests, error bars, or controls for model size and token frequency. This prevents verification that the data support the stated findings.
- [Results (fine-tuning analysis)] Results on fine-tuning (presumably §4 or equivalent): the claim that fine-tuning affects task-relevant substructures 'more than others' is load-bearing on the a-priori selection of the 78 substructures. If the substructure list was informed by inspection of the two downstream tasks, the 'follows chemical theory' interpretation becomes circular.
- [Results (random-init models)] Results on random initialization (layer-1 ring encoding): the observation that randomly initialized models encode rings well in the first layer is consistent with learning frequent local SMILES token patterns. Without baselines such as scrambled SMILES or frequency-matched null substructures, it is unclear whether the encoding reflects chemically meaningful structure rather than syntax.
minor comments (2)
- [Methods / Appendix] The manuscript should include a table or appendix listing the exact 78 substructures and the criteria used for their selection.
- [Experimental setup] Clarify whether model-size and architecture are matched between pre-trained and random-initialization cohorts; if not, this is a potential confound for the pre-training effect.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional methodological detail and controls can strengthen the manuscript. We address each major comment point by point below, indicating planned revisions where the manuscript requires clarification or expansion.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the directional claims (pre-training improves upper-layer structure awareness; fine-tuning selectively affects task-relevant substructures) are stated without any description of the probing technique, the precise activation metric, statistical tests, error bars, or controls for model size and token frequency. This prevents verification that the data support the stated findings.
Authors: We agree that the abstract is brief and that the Methods section would benefit from expanded detail. The full manuscript describes the probing of activations for substructure presence across layers, but we will revise both the abstract and Methods to explicitly state the activation metric (e.g., thresholded or averaged activations indicating substructure detection), the statistical tests employed, inclusion of error bars, and controls for model size and token frequency. These additions will allow readers to verify the support for the directional claims. revision: yes
-
Referee: [Results (fine-tuning analysis)] Results on fine-tuning (presumably §4 or equivalent): the claim that fine-tuning affects task-relevant substructures 'more than others' is load-bearing on the a-priori selection of the 78 substructures. If the substructure list was informed by inspection of the two downstream tasks, the 'follows chemical theory' interpretation becomes circular.
Authors: The 78 substructures were selected a priori from established chemical substructure libraries and common molecular motifs, without reference to the two downstream tasks. This independent selection avoids circularity and supports the interpretation that changes align with chemical theory. We will add a clarifying statement in the Methods and Results sections to make the selection process explicit. revision: partial
-
Referee: [Results (random-init models)] Results on random initialization (layer-1 ring encoding): the observation that randomly initialized models encode rings well in the first layer is consistent with learning frequent local SMILES token patterns. Without baselines such as scrambled SMILES or frequency-matched null substructures, it is unclear whether the encoding reflects chemically meaningful structure rather than syntax.
Authors: We acknowledge that the current analysis would be strengthened by explicit controls for syntax versus chemical meaning. We will incorporate additional baselines, including scrambled SMILES strings and frequency-matched null substructures, into the revised results for the random-initialization experiments to better isolate chemically meaningful encodings. revision: yes
Circularity Check
No circularity: empirical probing study with independent measurements
full rationale
The paper performs direct activation probing of 78 substructures across pre-trained and randomly initialized CLMs, followed by comparison of fine-tuning effects on two downstream tasks. No equations, fitted parameters, or derivations are present that could reduce claims to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. Results rest on observable activation patterns rather than any self-referential definition or renaming of known quantities, satisfying the criteria for a self-contained empirical analysis.
Axiom & Free-Parameter Ledger
free parameters (2)
- Selection of 78 molecular substructures
- Choice of eight pre-trained and six random models
axioms (1)
- domain assumption Activation patterns in transformer layers directly indicate encoding of specific molecular substructures
Reference graph
Works this paper leans on
-
[1]
ChemBERTa: Large-Scale Self- Supervised Pretraining for Molecular Property Prediction
PMID: 30887799. Raymond E. Carhart, Dennis H. Smith, and R. Venkataraghavan. 1985. Atom pairs as molec- ular features in structure-activity studies: definition and applications.Journal of Chemical Information and Computer Sciences, 25(2):64–73. Seyone Chithrananda, Gabriel Grand, and Bharath Ramsundar. 2020. Chemberta: Large-scale self- supervised pretrai...
-
[2]
Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji
Limitations of representation learning in small molecule property prediction.Nature Communica- tions, 14:6394. Carl Edwards, Tuan Lai, Kevin Ros, Garrett Honke, Kyunghyun Cho, and Heng Ji. 2022. Translation between molecules and natural language. InPro- ceedings of the 2022 Conference on Empirical Meth- ods in Natural Language Processing, pages 375–413, A...
-
[3]
David Fooshee, Aaron Mood, Eugene Gutman, Mo- hammadamin Tavakoli, Gregor Urban, Frances Liu, Nancy Huynh, David Van Vranken, and Pierre Baldi
Beyond performance: how design choices shape chemical language models.Journal of Chem- informatics, 17(1):1–15. David Fooshee, Aaron Mood, Eugene Gutman, Mo- hammadamin Tavakoli, Gregor Urban, Frances Liu, Nancy Huynh, David Van Vranken, and Pierre Baldi
-
[4]
Deep learning for chemical reaction prediction. 10 Molecular Systems Design & Engineering, 3(3):442– 452. Veronika Ganeeva, Kuzma Khrabrov, Artur Kadurin, and Elena Tutubalina. 2025. Two steps from hell: Compositionality on chemical LMs. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1042–1049, Suzhou, China. As- sociation ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Association for Computational Linguistics
What does BERT learn about the structure of language? InProceedings of the 57th Annual Meet- ing of the Association for Computational Linguistics, pages 3651–3657, Florence, Italy. Association for Computational Linguistics. 11 Chen-Yang Jia, Jing-Yi Li, Ge-Fei Hao, and Guang-Fu Yang. 2020. A drug-likeness toolbox facilitates ad- met study in drug discover...
2020
-
[6]
ap- plication to the study of biodegradation.Journal of Chemical Information and Computer Sciences, 32(5):474–482
Estimation of aqueous solubility of organic molecules by the group contribution approach. ap- plication to the study of biodegradation.Journal of Chemical Information and Computer Sciences, 32(5):474–482. PMID: 1400663. Mario Krenn, Florian Häse, AkshatKumar Nigam, Pas- cal Friederich, and Alan Aspuru-Guzik. 2020. Self- referencing embedded strings (selfi...
2020
-
[7]
release. Matthew L. Landry and James J. Crawford. 2020. Logd contributions of substituents commonly used in medicinal chemistry.ACS Medicinal Chemistry Letters, 11(1):72–76. Miguelangel Leon, Yuriy Perezhohin, Fernando Peres, Aleš Popoviˇc, and Mauro Castelli. 2024. Comparing smiles and selfies tokenization for enhanced chemical language modeling.Scientif...
-
[8]
InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4609–4622, Online
Information-theoretic probing for linguistic structure. InProceedings of the 58th Annual Meet- ing of the Association for Computational Linguistics, pages 4609–4622, Online. Association for Computa- tional Linguistics. Douglas E. V . Pires, Tom L. Blundell, and David B. Ascher. 2015. pkcsm: Predicting small-molecule pharmacokinetic and toxicity properties...
2015
-
[9]
Ian Tenney, Dipanjan Das, and Ellie Pavlick
Evolving concept of activity cliffs.ACS omega, 4(11):14360–14368. Ian Tenney, Dipanjan Das, and Ellie Pavlick. 2019a. BERT rediscovers the classical NLP pipeline. In Proceedings of the 57th Annual Meeting of the Asso- ciation for Computational Linguistics, pages 4593– 4601, Florence, Italy. Association for Computational Linguistics. Ian Tenney, Patrick Xi...
2024
-
[10]
MoleculeNet: A Benchmark for Molecular Machine Learning
An analysis of the attrition of drug candidates from four major pharmaceutical companies.Nature Reviews Drug Discovery, 14(7):475–486. David Weininger. 1988. Smiles, a chemical language and information system. 1. introduction to methodol- ogy and encoding rules.Journal of Chemical Infor- mation and Computer Sciences, 28(1):31–36. Zhenqin Wu, Bharath Ramsu...
work page internal anchor Pith review Pith/arXiv arXiv 1988
-
[11]
roberta-zinc-480m (Heyer, 2023) is a RoBERTa- based 14 layer, ∼102M parameter model trained on 480M molecules sampled from the ZINC database (Irwin and Shoichet,
with 44,375,040 parameters. roberta-zinc-480m (Heyer, 2023) is a RoBERTa- based 14 layer, ∼102M parameter model trained on 480M molecules sampled from the ZINC database (Irwin and Shoichet,
2023
-
[12]
For the experiments, we select models that are comparable and only differ with respect to their architecture and training data sizes
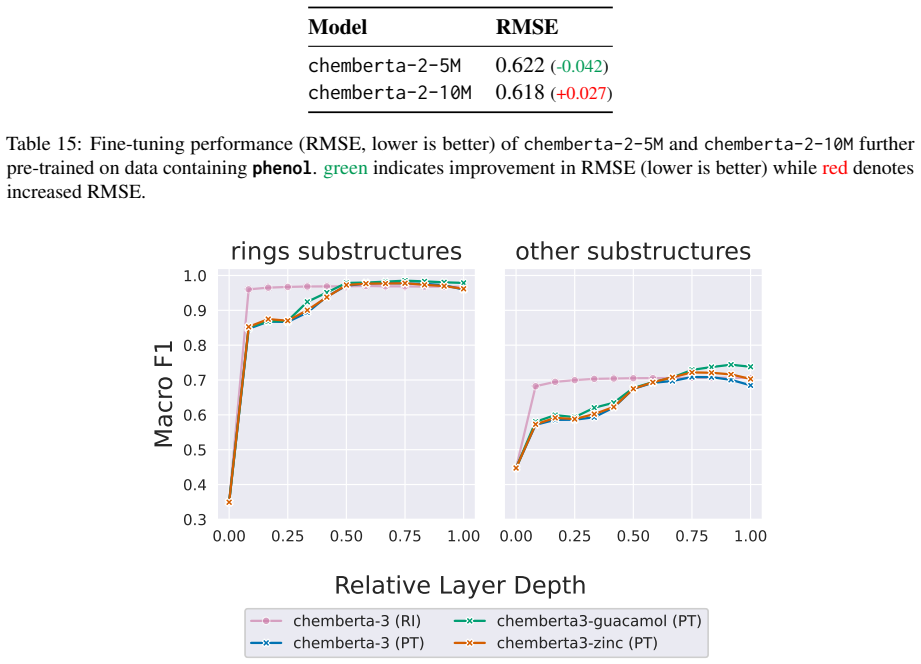
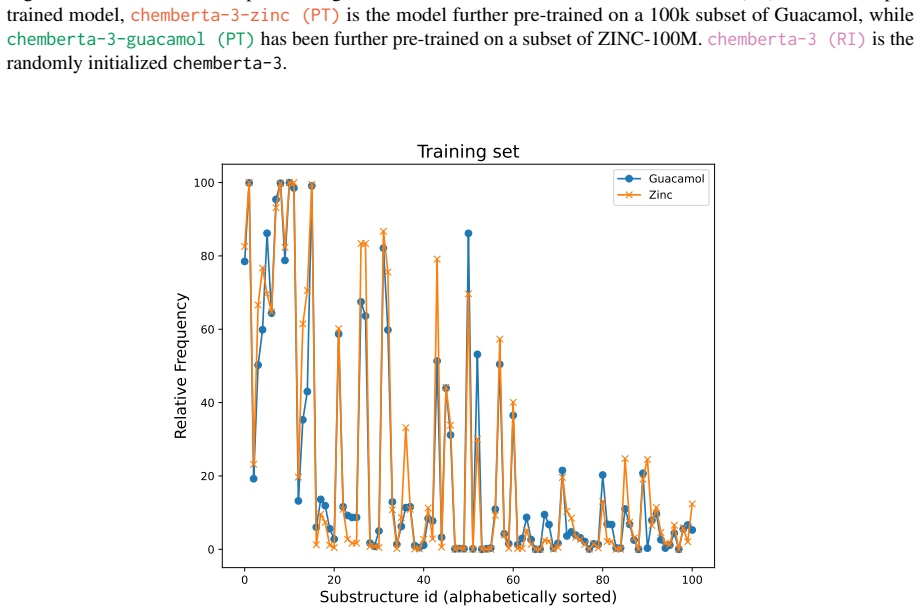
available on Huggingface under entropy/roberta_zinc_480m. For the experiments, we select models that are comparable and only differ with respect to their architecture and training data sizes. We thus omit models trained with domain-specific auxiliary ob- jectives such as MolBERT (Fabian et al., 2020), SELFormer (Yüksel et al., 2023), Mol-BERT (Li and Jian...
2020
-
[13]
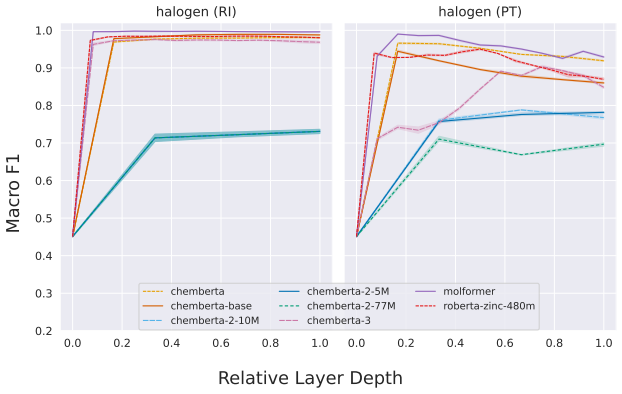
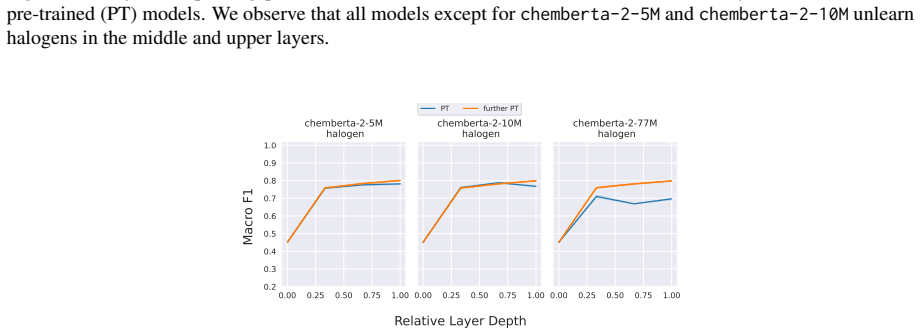
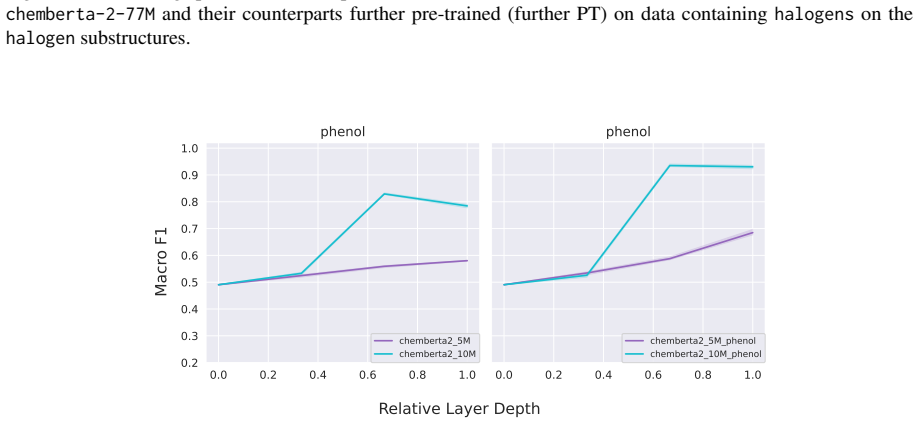
Further pre-training on halogen-containing molecules will improve chemberta-2-5M and chemberta-2-10M’s performance on halo- gens
-
[14]
molecular finger- prints
As further pre-training improves probing per- formance for halogens, we expect smaller probing performance gains on halogens after fine-tuning on lipophilicity. Same architecture, different performanceWe conjecture that probing can furthermore be used to identify molecular substructures that a model has 23 seen less during pre-training and that further pr...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.