When Token Compression Breaks: Structural Pruning vs. Token Reduction for Robust ViT Segmentation under High Compression
Pith reviewed 2026-07-03 15:49 UTC · model grok-4.3
The pith
Token compression in ViT segmentation works at mild rates but collapses under severe compression, while structural pruning degrades more smoothly and a prune-then-merge pipeline improves the accuracy-robustness trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
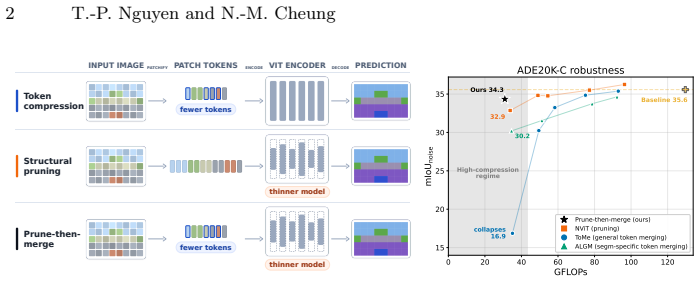
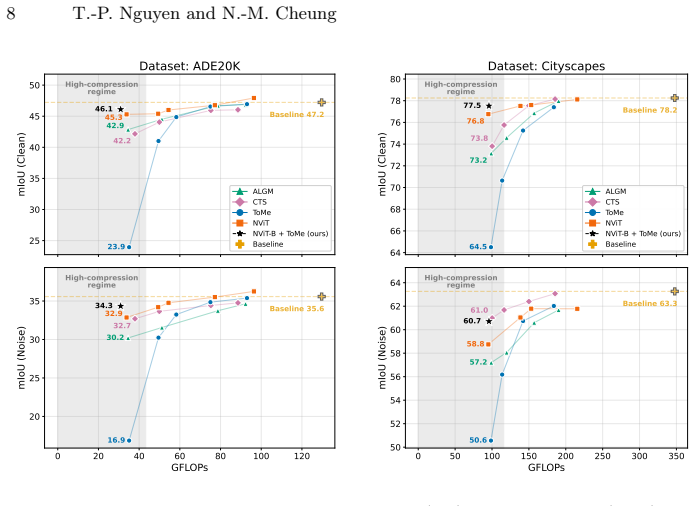
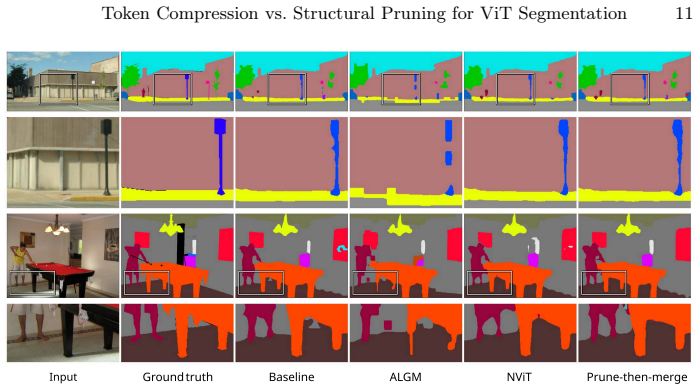
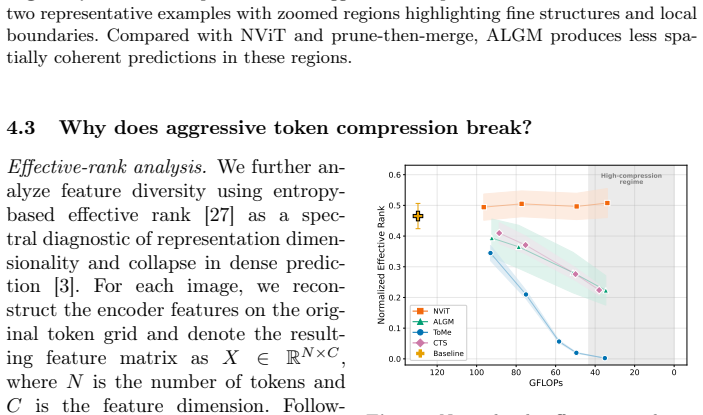
Token compression is highly effective at mild reductions but degrades sharply when compression becomes severe, consistent with substantial information loss from overly aggressive token reduction. In contrast, structural pruning exhibits a smoother degradation curve and is more stable at high compression. A prune-then-merge pipeline that applies moderate token compression on top of a moderately pruned backbone consistently achieves a better accuracy-robustness trade-off at high compression on both clean and corrupted inputs.
What carries the argument
Matched-FLOPs comparison of token compression versus structural pruning on corrupted segmentation benchmarks (ADE20K-C, Cityscapes-C), with the prune-then-merge pipeline as the proposed practical combination.
If this is right
- Token compression should be restricted to moderate ratios to avoid large accuracy drops on both clean and corrupted data.
- Structural pruning provides a more reliable route to extreme efficiency when high compression is required.
- Combining moderate pruning with moderate token compression produces a superior accuracy-robustness operating point at high compression.
- The relative stability of pruning holds across both clean and corrupted inputs under matched computational budgets.
Where Pith is reading between the lines
- Hybrid efficiency recipes may be worth testing on other dense prediction tasks such as object detection or depth estimation.
- Real-world deployment pipelines could incorporate input-quality checks to decide between pruning-heavy and compression-heavy operating modes.
- The information-loss interpretation suggests that token-merging heuristics might be redesigned to preserve semantic boundaries under corruption.
Load-bearing premise
The specific representative token-compression and structural-pruning methods, the matched-FLOPs protocol, and the common-corruption variants of ADE20K and Cityscapes are sufficient to reveal the general behavior of the two efficiency approaches under aggressive compression.
What would settle it
A new token compression method that maintains segmentation accuracy and corruption robustness at the highest tested compression ratios on ADE20K-C and Cityscapes-C under the same matched-FLOPs protocol would contradict the observed sharp degradation.
Figures
read the original abstract
Vision Transformers (ViTs) are strong backbones for semantic segmentation, but their computational cost limits deployment. Recent token compression methods for efficient transformer-based segmentation reduce this cost by decreasing the number of tokens. However, existing evaluations primarily focus on low-to-moderate compression, leaving their behavior under aggressive compression and corrupted inputs unclear. Meanwhile, structural pruning provides an orthogonal route to efficiency by removing redundant components in the ViT architecture, but is rarely compared to token compression under a unified protocol. To bridge this gap, we benchmark representative token compression and structural pruning methods for ViT-based semantic segmentation under matched FLOPs on ADE20K and Cityscapes, together with their common-corruption variants ADE20K-C and Cityscapes-C. Our results reveal a consistent trend on both clean and corrupted inputs: token compression is highly effective at mild reductions but degrades sharply when compression becomes severe, consistent with substantial information loss from overly aggressive token reduction. In contrast, structural pruning exhibits a smoother degradation curve and is more stable at high compression. Motivated by these findings, we study a prune-then-merge pipeline that applies moderate token compression on top of a moderately pruned backbone. At comparable FLOPs, this combined strategy consistently achieves a better accuracy-robustness trade-off at high compression, offering a practical recipe for deployment-oriented ViT segmentation. Code is available at https://github.com/phatnguyencs/vit-seg-compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks representative token compression and structural pruning methods for ViT-based semantic segmentation under a matched-FLOPs protocol on ADE20K, Cityscapes, and their common-corruption variants (ADE20K-C, Cityscapes-C). It reports that token compression performs well at mild compression ratios but degrades sharply at high compression due to information loss, while structural pruning shows smoother degradation and greater stability; a prune-then-merge pipeline combining moderate pruning with token compression yields a superior accuracy-robustness trade-off at high compression levels.
Significance. If the observed trends hold under the described protocol, the work supplies actionable empirical guidance for deploying efficient ViT segmentation models in resource-constrained settings that also require robustness to input corruptions. The matched-FLOPs comparison, inclusion of corruption benchmarks, and open-sourced code are strengths that support reproducibility and practical utility.
major comments (1)
- [Experimental protocol] Experimental protocol (assumed §4): the central claim that the observed trends reveal general behavior of the two efficiency families rests on the representativeness of the selected token-compression and structural-pruning methods; the manuscript should provide explicit justification or sensitivity analysis showing that alternative methods within each family produce qualitatively similar degradation curves, otherwise the generalizability of the prune-then-merge recommendation is weakened.
minor comments (2)
- [Abstract] Abstract: the specific token-compression and pruning algorithms chosen as representatives are not named, which reduces immediate clarity about the scope of the benchmark.
- [Results] Results presentation: tables or figures reporting the accuracy-robustness trade-off for the prune-then-merge pipeline should include error bars or multiple-run statistics to confirm that the reported gains are stable.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's practical utility. We address the single major comment below and will incorporate the suggested clarification in the revision.
read point-by-point responses
-
Referee: [Experimental protocol] Experimental protocol (assumed §4): the central claim that the observed trends reveal general behavior of the two efficiency families rests on the representativeness of the selected token-compression and structural-pruning methods; the manuscript should provide explicit justification or sensitivity analysis showing that alternative methods within each family produce qualitatively similar degradation curves, otherwise the generalizability of the prune-then-merge recommendation is weakened.
Authors: We agree that explicit justification strengthens the generalizability claim. In the revised manuscript we will expand the experimental protocol section with a new paragraph that (i) motivates the selected representatives by their prevalence in the literature and coverage of core mechanisms (token merging/pruning for compression; head/layer/channel removal for structural pruning), and (ii) cites prior studies reporting qualitatively similar sharp vs. smooth degradation curves under high compression for other methods in each family. This addition directly addresses the concern without requiring new experiments. revision: yes
Circularity Check
Empirical benchmark with no derivation chain
full rationale
The paper is a standard empirical benchmark study comparing token compression and structural pruning methods for ViT-based semantic segmentation. It reports observed trends from experiments under a matched-FLOPs protocol on ADE20K, Cityscapes and their corruption variants, then proposes a prune-then-merge pipeline as a practical outcome of those observations. No equations, fitted parameters, predictions, uniqueness theorems, or self-citation load-bearing steps appear in the abstract or described design. The central claims rest on external experimental results rather than any reduction to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard ViT backbones, semantic-segmentation heads, and evaluation protocols on ADE20K/Cityscapes remain valid when compression is applied.
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Represen- tations (2023)
Bolya, D., Fu, C.Y., Dai, X., Zhang, P., Feichtenhofer, C., Hoffman, J.: Token merging: Your ViT but faster. In: International Conference on Learning Represen- tations (2023)
2023
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cai, H., Li, J., Hu, M., Gan, C., Han, S.: Efficientvit: Lightweight multi-scale attention for high-resolution dense prediction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17302–17313 (2023)
2023
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
Chen, L., Gu, L., Fu, Y.: Frequency-dynamic attention modulation for dense pre- diction. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (2025)
2025
-
[4]
arXiv preprint arXiv:2305.17997 (2023)
Chen, M., Shao, W., Xu, P., Lin, M., Zhang, K., Chao, F., Ji, R., Qiao, Y., Luo, P.: Diffrate: Differentiable compression rate for efficient vision transformers. arXiv preprint arXiv:2305.17997 (2023)
-
[5]
In: CVPR (2022)
Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
2022
-
[6]
In: NeurIPS (2021)
Cheng, B., Schwing, A.G., Kirillov, A.: Per-pixel classification is not all you need for semantic segmentation. In: NeurIPS (2021)
2021
-
[7]
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding (2016)
2016
-
[8]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021)
2021
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fang,G.,Ma,X.,Song,M.,Mi,M.B.,Wang,X.:Depgraph:Towardsanystructural pruning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16091–16101 (2023) Token Compression vs. Structural Pruning for ViT Segmentation 15
2023
-
[10]
arXiv preprint arXiv:2407.04616 (2024)
Fang, G., Ma, X.T., Mi, M.B., Wang, X.: Isomorphic pruning for vision models. arXiv preprint arXiv:2407.04616 (2024)
-
[11]
European Conference on Computer Vision (ECCV) (2022)
Fayyaz, M., Abbasi Kouhpayegani, S., Rezaei Jafari, F., Sommerlade, E., Vaezi Joze, H.R., Pirsiavash, H., Gall, J.: Adaptive token sampling for efficient vision transformers. European Conference on Computer Vision (ECCV) (2022)
2022
-
[12]
In: 2023 IEEE/CVF Interna- tional Conference on Computer Vision Workshops (ICCVW)
Haurum, J.B., Escalera, S., Taylor, G.W., Moeslund, T.B.: Which tokens to use? investigating token reduction in vision transformers. In: 2023 IEEE/CVF Interna- tional Conference on Computer Vision Workshops (ICCVW). pp. 773–783 (2023). https://doi.org/10.1109/ICCVW60793.2023.00085
- [13]
-
[14]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW)
Hou, Z., Kung, S.Y.: Multi-dimensional vision transformer compression via de- pendency guided gaussian process search. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). pp. 3668–3677 (2022).https://doi.org/10.1109/CVPRW56347.2022.00411
-
[15]
In: ICLR (2024)
Huang, H., Campello, R.J.G.B., Erfani, S.M., Ma, X., Houle, M.E., Bailey, J.: Ldreg: Local dimensionality regularized self-supervised learning. In: ICLR (2024)
2024
-
[16]
In: CVPR (2023)
Jain, J., Li, J., Chiu, M., Hassani, A., Orlov, N., Shi, H.: OneFormer: One Trans- former to Rule Universal Image Segmentation. In: CVPR (2023)
2023
-
[17]
In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kamann, C., Rother, C.: Benchmarking the robustness of semantic segmentation models. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). p. 8825–8835. IEEE (Jun 2020).https://doi.org/10.1109/ cvpr42600.2020.00885
-
[18]
Kim, M., Gao, S., Hsu, Y.C., Shen, Y., Jin, H.: Token fusion: Bridging the gap between token pruning and token merging. In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1372–1381 (2024).https:// doi.org/10.1109/WACV57701.2024.00141
-
[19]
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything (2023)
2023
-
[20]
In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XI
Kong, Z., Dong, P., Ma, X., Meng, X., Niu, W., Sun, M., Shen, X., Yuan, G., Ren, B., Tang, H., et al.: Spvit: Enabling faster vision transformers via latency-aware soft token pruning. In: Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XI. pp. 620–640. Springer (2022)
2022
-
[21]
In: International Conference on Learning Representations (2022)
Liang,Y.,Ge,C.,Tong,Z.,Song,Y.,Wang,J.,Xie,P.:Notallpatchesarewhatyou need: Expediting vision transformers via token reorganizations. In: International Conference on Learning Representations (2022)
2022
-
[22]
Liu, Y., Zhou, Q., Wang, J., Wang, Z., Wang, F., Wang, J., Zhang, W.: Dynamic token-pass transformers for semantic segmentation. In: 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1816–1825 (2024). https://doi.org/10.1109/WACV57701.2024.00184
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[24]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
Lu, C., de Geus, D., Dubbelman, G.: Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[25]
In: Proceedings of the European conference on computer vision (ECCV)
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: Shufflenet v2: Practical guidelines for efficient cnn architecture design. In: Proceedings of the European conference on computer vision (ECCV). pp. 116–131 (2018) 16 T.-P. Nguyen and N.-M. Cheung
2018
-
[26]
In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2024)
Norouzi, N., Sorlova, S., de Geus, D., Dubbelman, G.: ALGM: Adaptive Local- then-Global Token Merging for Efficient Semantic Segmentation with Plain Vision Transformers. In: IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR) (2024)
2024
-
[27]
In: 2007 15th European signal processing conference
Roy, O., Vetterli, M.: The effective rank: A measure of effective dimensionality. In: 2007 15th European signal processing conference. pp. 606–610. IEEE (2007)
2007
-
[28]
In: Advances in Neural Information Processing Systems (2022)
Shen, M., Yin, H., Molchanov, P., Mao, L., Liu, J., Alvarez, J.: Structural prun- ing via latency-saliency knapsack. In: Advances in Neural Information Processing Systems (2022)
2022
-
[29]
In: Proceedings of the 40th International Conference on Machine Learning
Shi, D., Tao, C., Jin, Y., Yang, Z., Yuan, C., Wang, J.: UPop: Unified and progres- sive pruning for compressing vision-language transformers. In: Proceedings of the 40th International Conference on Machine Learning. vol. 202, pp. 31292–31311. PMLR (2023)
2023
-
[30]
Strudel, R., Garcia, R., Laptev, I., Schmid, C.: Segmenter: Transformer for seman- tic segmentation (2021)
2021
-
[31]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Tang, Q., Zhang, B., Liu, J., Liu, F., Liu, Y.: Dynamic token pruning in plain vision transformers for semantic segmentation. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 777–786 (2023)
2023
-
[32]
Tang, Y., Wang, Y., Guo, J., Tu, Z., Han, K., Hu, H., Tao, D.: A survey on transformer compression (2024)
2024
-
[33]
In: Meila, M., Zhang, T
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jegou, H.: Training data-efficient image transformers & distillation through attention. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 139, pp. 10347–10357. PMLR (18–24 Jul 2021)
2021
-
[34]
In: Thirty-Sixth Conference on Neural Information Processing Systems (2022)
Wang, Z., Luo, H., WANG, P., Ding, F., Wang, F., Li, H.: VTC-LFC: Vision trans- former compression with low-frequency components. In: Thirty-Sixth Conference on Neural Information Processing Systems (2022)
2022
-
[35]
In: Neural Information Processing Systems (NeurIPS) (2021)
Xie, E., Wang, W., Yu, Z., Anandkumar, A., Alvarez, J.M., Luo, P.: Segformer: Simple and efficient design for semantic segmentation with transformers. In: Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, H., Yin, H., Shen, M., Molchanov, P., Li, H., Kautz, J.: Global vision trans- former pruning with hessian-aware saliency. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 18547– 18557 (June 2023)
2023
-
[37]
IEEE Conf
Zhang, W., Huang, Z., Luo, G., Chen, T., Wang, X., Liu, W., Yu, G., Shen, C.: Topformer:Tokenpyramidtransformerformobilesemanticsegmentation.In:Proc. IEEE Conf. Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[38]
Ad- vances in Neural Information Processing Systems35, 9010–9023 (2022)
Zheng, C., Zhang, K., Yang, Z., Tan, W., Xiao, J., Ren, Y., Pu, S., et al.: Savit: Structure-aware vision transformer pruning via collaborative optimization. Ad- vances in Neural Information Processing Systems35, 9010–9023 (2022)
2022
-
[39]
In: CVPR (2021)
Zheng, S., Lu, J., Zhao, H., Zhu, X., Luo, Z., Wang, Y., Fu, Y., Feng, J., Xiang, T., Torr, P.H., Zhang, L.: Rethinking semantic segmentation from a sequence-to- sequence perspective with transformers. In: CVPR (2021)
2021
-
[40]
International Journal of Computer Vision127(3), 302–321 (2019)
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., Torralba, A.: Se- mantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision127(3), 302–321 (2019)
2019
-
[41]
In: International Conference on Learning Representations (2023)
Zhuo, Z., Wang, Y., Ma, J., Wang, Y.: Towards a unified theoretical understand- ing of non-contrastive learning via rank differential mechanism. In: International Conference on Learning Representations (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.