QoE-Aware Resource Allocation for Crowdsourced Live Streaming: A Machine Learning Approach
Pith reviewed 2026-05-25 19:24 UTC · model grok-4.3
The pith
Machine learning predictions of viewer numbers near cloud sites enable proactive resource allocation that maximizes QoE while minimizing costs in crowdsourced live streaming.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
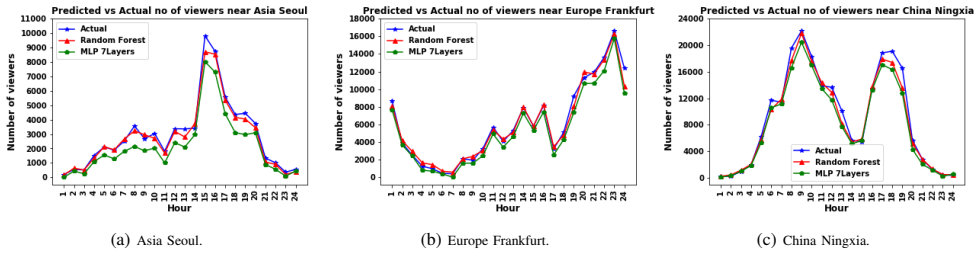
By exploiting the viewers locations available in our unique dataset, we implement a machine learning model to predict the viewers number near each geo-distributed cloud site. Based on the predicted results that showed to be close to the actual values, we formulate an optimization problem to proactively allocate resources at the viewers proximity. This prediction-driven framework maximizes the QoE of viewers and minimizes the resource allocation cost while presenting a trade-off between the video access delay and the cost of resource allocation.
What carries the argument
Machine learning model that predicts viewer counts near each geo-distributed cloud site, used as input to an optimization problem that decides proactive resource allocation.
If this is right
- Resources placed near predicted viewer clusters reduce access delay and video stalls.
- Avoiding both over-provisioning and under-provisioning lowers service-provider costs.
- The explicit delay-cost trade-off lets operators choose operating points on a curve rather than a single fixed allocation.
- The framework runs proactively before viewers arrive, using only the location predictions as input.
Where Pith is reading between the lines
- The same prediction-plus-optimization loop could be tested on non-crowdsourced video services that also rely on geo-distributed servers.
- Retraining the model on streaming data collected after the original dataset might tighten prediction error and further reduce the observed cost-delay trade-off.
- If viewer locations become available in real time rather than in batch, the optimization could be rerun periodically to correct allocation mid-event.
Load-bearing premise
The machine learning predictions of viewer numbers are close enough to actual future counts that the resulting optimization improves QoE and controls cost better than allocation without those predictions.
What would settle it
Running the same optimization on new viewer-location traces where the machine learning predictions deviate substantially from observed counts and checking whether QoE drops or total cost rises compared with a non-predictive baseline.
Figures







read the original abstract
Driven by the tremendous technological advancement of personal devices and the prevalence of wireless mobile network accesses, the world has witnessed an explosion in crowdsourced live streaming. Ensuring a better viewers quality of experience (QoE) is the key to maximize the audiences number and increase streaming providers' profits. This can be achieved by advocating a geo-distributed cloud infrastructure to allocate the multimedia resources as close as possible to viewers, in order to minimize the access delay and video stalls. Moreover, allocating the exact needed resources beforehand avoids over-provisioning, which may lead to significant costs by the service providers. In the contrary, under-provisioning might cause significant delays to the viewers. In this paper, we introduce a prediction driven resource allocation framework, to maximize the QoE of viewers and minimize the resource allocation cost. First, by exploiting the viewers locations available in our unique dataset, we implement a machine learning model to predict the viewers number near each geo-distributed cloud site. Second, based on the predicted results that showed to be close to the actual values, we formulate an optimization problem to proactively allocate resources at the viewers proximity. Additionally, we will present a trade-off between the video access delay and the cost of resource allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a prediction-driven resource allocation framework for crowdsourced live streaming. It exploits viewer location data from a unique dataset to train a machine learning model that predicts the number of viewers near each geo-distributed cloud site; these predictions are then used to formulate an optimization problem that proactively allocates resources to maximize viewer QoE while minimizing allocation cost, including an explicit trade-off between video access delay and resource cost.
Significance. If the ML predictions are shown to be sufficiently accurate via quantitative validation and the resulting optimization yields measurable QoE gains at controlled cost, the framework could support more efficient, proactive provisioning in geo-distributed clouds for live streaming, reducing both stalls and over-provisioning expenses.
major comments (2)
- [Abstract] Abstract (paragraph beginning 'First, by exploiting...'): the central claim that 'the predicted results ... showed to be close to the actual values' supplies no quantitative error metrics (MAE, MAPE, etc.), no training/validation split or cross-validation procedure, no feature set or model architecture details, and no baseline comparisons, rendering it impossible to assess whether prediction error is small enough to avoid harmful under- or over-provisioning in the subsequent optimization.
- [Abstract] Abstract (optimization formulation paragraph): the optimization problem is stated but neither solved nor evaluated on the predicted viewer counts; without reported objective values, QoE metrics, or cost figures under the ML predictions versus baselines, the claim that the framework 'maximize[s] the QoE of viewers and minimize[s] the resource allocation cost' remains unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the abstract requires additional quantitative details to support its claims and will revise it in the next version. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'First, by exploiting...'): the central claim that 'the predicted results ... showed to be close to the actual values' supplies no quantitative error metrics (MAE, MAPE, etc.), no training/validation split or cross-validation procedure, no feature set or model architecture details, and no baseline comparisons, rendering it impossible to assess whether prediction error is small enough to avoid harmful under- or over-provisioning in the subsequent optimization.
Authors: We agree that the abstract is insufficiently quantitative on this point. The body of the manuscript contains the ML model details, cross-validation procedure, feature set, MAE/MAPE results, and baseline comparisons, but these are not summarized in the abstract. We will revise the abstract to report the key error metrics and validation approach so that readers can directly assess suitability for the downstream optimization. revision_made: yes revision: yes
-
Referee: [Abstract] Abstract (optimization formulation paragraph): the optimization problem is stated but neither solved nor evaluated on the predicted viewer counts; without reported objective values, QoE metrics, or cost figures under the ML predictions versus baselines, the claim that the framework 'maximize[s] the QoE of viewers and minimize[s] the resource allocation cost' remains unsupported.
Authors: We agree that the abstract does not report the optimization outcomes. The manuscript evaluates the proactive allocation under the ML predictions and compares QoE and cost against baselines, but these numerical results are not reflected in the abstract. We will add a concise summary of the objective values, QoE gains, and cost reductions to the abstract. revision_made: yes revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes training an ML model on viewer-location data from a unique dataset to predict viewer numbers per geo-site, then formulating (but not solving) an optimization problem that uses those predictions for resource allocation. This is a standard predictive-modeling pipeline and does not reduce any claimed result to its inputs by construction, via self-definition, or via load-bearing self-citation. No equations are presented that equate a prediction to a fitted input, and the abstract's statement that predictions 'showed to be close to the actual values' is presented as an empirical observation rather than a definitional identity. The central framework therefore retains independent content outside its training data.
Axiom & Free-Parameter Ledger
free parameters (2)
- ML model parameters
- Delay-cost trade-off weights
axioms (2)
- domain assumption Viewer locations recorded in the dataset are sufficient features for accurate prediction of future viewer counts at each cloud site.
- domain assumption The optimization problem correctly captures the relationship between allocated resources, resulting access delay, and total cost.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
R² = 1−∑(Ai−Pi)²/∑(Ai−Ā)²; RF achieves R² 0.91 for Seoul, 0.89 for Sao Paulo
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2016-2021 White Paper . Mar. 2017. URL: https://www.cisco.com/c/en/us/solutions/collateral/service- provider/visual- networking- index- vni/mobile- white- paper- c11-520862.html
work page 2016
-
[2]
Facebook users worldwide 2018 . 2018. URL: https : / / www. statista . com / statistics / 264810 / number - of - monthly - active - facebook-users-worldwide/
work page 2018
-
[3]
Facebook Statistics for 2018 . URL: https://www.wordstream. com/blog/ws/2017/11/07/facebook-statistics
work page 2018
-
[4]
Developing a predictive model of quality of experience for internet video
Athula Balachandran et al. “Developing a predictive model of quality of experience for internet video”. In: ACM SIGCOMM. V ol. 43. 4. 2013, pp. 339–350
work page 2013
-
[5]
Video stream quality impacts viewer behavior: inferring causality us- ing quasi-experimental designs
S Shunmuga Krishnan and Ramesh K Sitaraman. “Video stream quality impacts viewer behavior: inferring causality us- ing quasi-experimental designs”. In: IEEE/ACM Transactions on Networking (TON) 21.6 (2013), pp. 2001–2014
work page 2013
-
[6]
Scaling social media applications into geo- distributed clouds
Yu Wu et al. “Scaling social media applications into geo- distributed clouds”. In: IEEE/ACM Transactions on Network- ing (TON) 23.3 (2015), pp. 689–702
work page 2015
-
[7]
Qiyun He et al. “Coping with heterogeneous video contributors and viewers in crowdsourced live streaming: A cloud-based approach”. In: IEEE Transactions on Multimedia 18.5 (2016), pp. 916–928
work page 2016
-
[8]
QoE-aware distributed cloud-based live streaming of multisourced multiview videos
K Bilal, A Erbad, and M Hefeeda. “QoE-aware distributed cloud-based live streaming of multisourced multiview videos”. In: Journal of Network and Computer Applications 120 (2018), pp. 130–144
work page 2018
-
[9]
A machine learning-based framework for preventing video freezes in HTTP adaptive streaming
Stefano Petrangeli et al. “A machine learning-based framework for preventing video freezes in HTTP adaptive streaming”. In: Journal of Network and Computer Applications 94 (2017), pp. 78–92
work page 2017
-
[10]
Improving Adaptive Video Streaming through Machine Learning
Anh Minh Le. “Improving Adaptive Video Streaming through Machine Learning”. In: (2018)
work page 2018
-
[11]
User Mapping Strategies in Multi-Cloud Streaming: A Data-Driven Approach
Guowei Zhu et al. “User Mapping Strategies in Multi-Cloud Streaming: A Data-Driven Approach”. In: GLOBECOM, 2016 IEEE, pp. 1–6
work page 2016
-
[12]
URL: https://sites.google.com/ view/facebookvideoslive18/home
FacebookVideosLive18 Dataset. URL: https://sites.google.com/ view/facebookvideoslive18/home
-
[13]
URL: https://aws.amazon.com/ about-aws/global-infrastructure/
Amazon Web Services— AWS . URL: https://aws.amazon.com/ about-aws/global-infrastructure/
-
[14]
Feature hashing for large scale multitask learning
Kilian Weinberger et al. “Feature hashing for large scale multitask learning”. In: Proceedings of the 26th annual in- ternational conference on machine learning . ACM. 2009, pp. 1113–1120
work page 2009
-
[15]
URL: https://aws.amazon.com/s3/ pricing/
Cloud Storage Pricing — S3 Pricing by Region — Amazon Simple Storage Service . URL: https://aws.amazon.com/s3/ pricing/
-
[16]
URL: https://wondernetwork.com/pings
Global Ping Statistics. URL: https://wondernetwork.com/pings
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.