Modeling Severe Traffic Accidents With Spatial And Temporal Features
Pith reviewed 2026-05-25 16:37 UTC · model grok-4.3
The pith
Road network complexity improves prediction of severe traffic accidents in aggregated NYC models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In aggregated area-level models, spatial variables that measure road network complexity carry significant predictive weight for accident severity when combined with temporal and situational features drawn from open NYC sources; gradient boosting models quantify this importance while Gaussian processes model spatial dependencies.
What carries the argument
Gradient boosting models that rank feature importance for road network complexity variables, paired with Gaussian processes to account for spatial autocorrelation.
If this is right
- Policy makers could prioritize areas with high road network complexity for safety interventions.
- Aggregated models may offer a practical scale for city-wide planning compared with point-level predictions.
- Feature importance rankings can highlight which additional data sources would most improve severity forecasts.
- The approach separates the contribution of spatial structure from purely temporal or situational drivers.
Where Pith is reading between the lines
- The same complexity measures could be tested as early-warning indicators in cities that release similar open data.
- Extending the models to incorporate real-time traffic volume might strengthen the link between complexity and observed severity.
- If complexity proves robust, urban planners could simulate network changes to estimate effects on future accident rates.
Load-bearing premise
The chosen area-level spatial variables, temporal features, and open NYC situational data capture the main drivers of accident severity without large omitted factors or measurement error.
What would settle it
Re-running the same gradient boosting pipeline on a held-out year of NYC data or on data from another city and finding that the complexity features add no lift in prediction accuracy over a baseline without them would falsify the importance claim.
Figures


read the original abstract
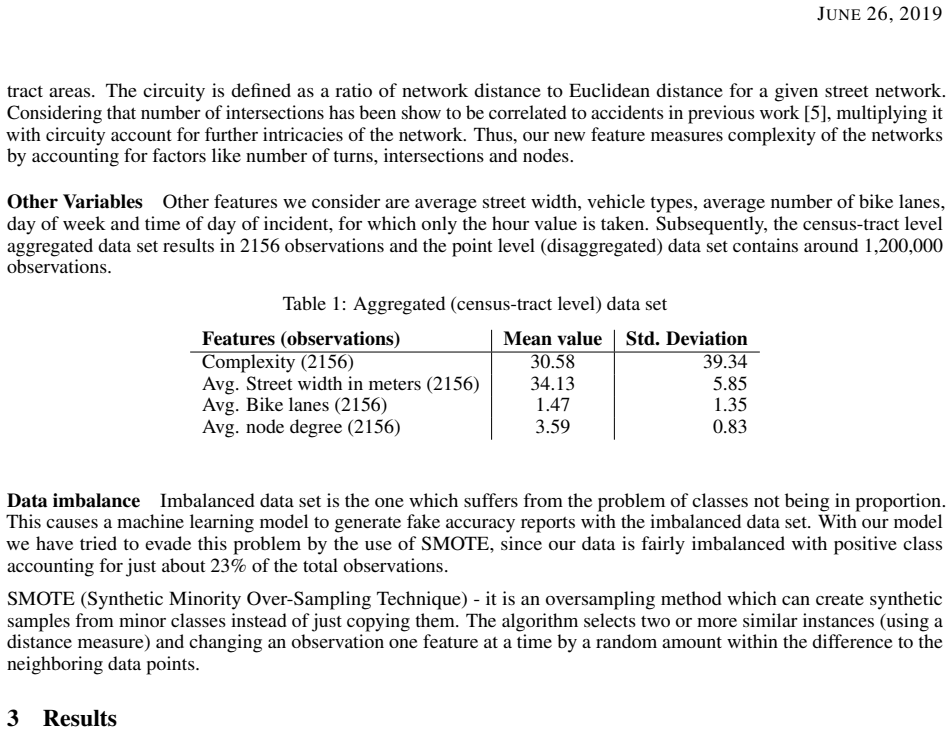
We present an approach to estimate the severity of traffic related accidents in aggregated (area-level) and disaggregated (point level) data. Exploring spatial features, we measure complexity of road networks using several area level variables. Also using temporal and other situational features from open data for New York City, we use Gradient Boosting models for inference and measuring feature importance along with Gaussian Processes to model spatial dependencies in the data. The results show significant importance of complexity in aggregated model as well as as other features in prediction which may be helpful in framing policies and targeting interventions for preventing severe traffic related accidents and injuries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Gradient Boosting models (with Gaussian Processes for spatial modeling) to predict traffic accident severity on both aggregated (area-level) and disaggregated (point-level) NYC data. It extracts spatial complexity measures of road networks plus temporal and situational covariates from open sources, and reports that complexity features exhibit significant importance in the aggregated GB model, with potential utility for policy and intervention targeting.
Significance. If the reported feature importances prove robust under proper validation and controls for omitted variables, the work could provide a practical demonstration of how area-level network complexity correlates with severe accident outcomes and thereby support data-driven safety policies. The combination of off-the-shelf GB with spatial GP modeling is straightforward and reproducible in principle, but the current lack of quantitative support reduces immediate significance.
major comments (3)
- [Abstract] Abstract and results sections: the central claim that complexity variables show 'significant importance' in the aggregated GB model is stated without any reported performance metrics (accuracy, AUC, F1, cross-validation details, or error bars on importances), leaving the quantitative basis for the policy recommendation unsupported.
- [Methods] Methods and data sections: reliance on open NYC sources without traffic-volume, enforcement, or exposure covariates raises a material risk of omitted-variable bias; the GB feature importances cannot be interpreted as policy-relevant without robustness checks that add or proxy these drivers.
- [Results] Results: no external validation, hold-out testing on later years, or sensitivity analysis to aggregation scale (MAUP) is described, so the reported importance ranking may be an artifact of the chosen feature set rather than a stable signal.
minor comments (1)
- [Methods] Notation for the Gaussian Process kernel and the precise definition of the complexity variables should be stated explicitly rather than left to external references.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and commit to revisions that strengthen the quantitative support and robustness of the analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the central claim that complexity variables show 'significant importance' in the aggregated GB model is stated without any reported performance metrics (accuracy, AUC, F1, cross-validation details, or error bars on importances), leaving the quantitative basis for the policy recommendation unsupported.
Authors: We agree that the absence of explicit performance metrics weakens the central claim. The original manuscript emphasized feature importance rankings from the gradient boosting model but did not report cross-validation details or error bars. In the revised version we will add AUC, accuracy, F1 scores, k-fold cross-validation results, and bootstrap-derived error bars on the importance scores to provide the required quantitative foundation. revision: yes
-
Referee: [Methods] Methods and data sections: reliance on open NYC sources without traffic-volume, enforcement, or exposure covariates raises a material risk of omitted-variable bias; the GB feature importances cannot be interpreted as policy-relevant without robustness checks that add or proxy these drivers.
Authors: We acknowledge the risk of omitted-variable bias. The study is restricted to publicly available NYC open data, which lacks direct traffic-volume or enforcement measures. We will expand the revised manuscript with an explicit limitations section discussing this issue and will test the addition of available proxy variables (e.g., time-of-day and day-of-week indicators already present) to assess sensitivity of the complexity-feature importances. revision: partial
-
Referee: [Results] Results: no external validation, hold-out testing on later years, or sensitivity analysis to aggregation scale (MAUP) is described, so the reported importance ranking may be an artifact of the chosen feature set rather than a stable signal.
Authors: We accept that additional validation is needed. The revised manuscript will include temporal hold-out evaluation on later years of the NYC data and a sensitivity analysis across multiple spatial aggregation scales to address the modifiable areal unit problem. These checks will help establish whether the reported importance ordering is robust. revision: yes
Circularity Check
No circularity: standard empirical ML on external open data
full rationale
The paper trains Gradient Boosting and Gaussian Process models on NYC open data to predict accident severity and extract feature importances. No equations, derivations, or self-citations are present that reduce any claimed result to fitted inputs by construction. The modeling pipeline relies on independent external sources and off-the-shelf algorithms without self-referential loops or ansatzes smuggled via prior work.
Axiom & Free-Parameter Ledger
free parameters (2)
- gradient boosting hyperparameters
- Gaussian process kernel hyperparameters
axioms (1)
- domain assumption Open data features capture the primary spatial, temporal, and situational drivers of accident severity
Reference graph
Works this paper leans on
-
[1]
https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries
Road traffic injuries. https://www.who.int/news-room/fact-sheets/detail/road-traffic-injuries
-
[2]
Amirfarrokh Iranitalab, Aemal Khattak. Comparison of four statistical and machine learning methods for crash severity prediction, Accident Analysis & Prevention. V olume 108, 2017, Pages 27-36, ISSN 0001-4575, https://doi.org/10.1016/j.aap.2017.08.008
-
[3]
From racks to pointed Hopf algebras
Mohamed A. Abdel-Aty, A.Essam Radwan. Modeling traffic accident occurrence and involvement, Accident Analysis & Prevention. V olume 32, Issue 5, 2000, Pages 633-642, ISSN 0001-4575, https://doi.org/10.1016/S0001- 4575(99)00094-9
-
[4]
Poul Greibe. Accident prediction models for urban roads, Accident Analysis & Prevention, V olume 35, Issue 2, 2003, Pages 273-285, ISSN 0001-4575, https://doi.org/10.1016/S0001-4575(02)00005-2
-
[5]
Hadayeghi, A., Shalaby, A. S., & Persaud, B. (2003). Macrolevel Accident Prediction Models for Evaluating Safety of Urban Transportation Systems. Transportation Research Record, 1840(1), 87–95. https://doi.org/10.3141/1840-10
-
[6]
Harris MA, Reynolds CCO, Winters M, et al. Comparing the effects of infrastructure on bicycling injury at intersections and non-intersections using a case–crossover design. Injury Prevention 2013;19:303-310
work page 2013
-
[7]
Persaud, B., Lord, D., & Palmisano, J. (2002). Calibration and Transferability of Accident Prediction Models for Urban Intersections. Transportation Research Record, 1784(1), 57–64. https://doi.org/10.3141/1784-08
-
[8]
El-Basyouny, K., & Sayed, T. (2006). Comparison of Two Negative Binomial Regression Tech- niques in Developing Accident Prediction Models. Transportation Research Record, 1950(1), 9–16. https://doi.org/10.1177/0361198106195000102 5 JUNE 26, 2019
-
[9]
Abdelwahab, H. T., & Abdel-Aty, M. A. (2001). Development of Artificial Neural Network Models to Predict Driver Injury Severity in Traffic Accidents at Signalized Intersections. Transportation Research Record, 1746(1), 6–13. https://doi.org/10.3141/1746-02
-
[10]
Mohammed A. Quddus. Time series count data models: An empirical application to traffic acci- dents, Accident Analysis & Prevention. V olume 40, Issue 5, 2008, Pages 1732-1741, ISSN 0001-4575, https://doi.org/10.1016/j.aap.2008.06.011
-
[11]
Z Sawalha and , T Sayed. Traffic accident modeling: some statistical issues Canadian Journal of Civil Engineering, 2006, 33(9): 1115-1124, https://doi.org/10.1139/l06-056 6
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.