Few-Shot Video Classification via Temporal Alignment
Pith reviewed 2026-05-25 15:14 UTC · model grok-4.3
The pith
A temporal alignment module improves few-shot video classification by respecting frame order in videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that explicitly leveraging temporal ordering information through temporal alignment produces strong data-efficiency for few-shot video classification; TAM calculates the distance of a query video to novel-class proxies by averaging the per-frame distances along its alignment path, with continuous relaxation enabling end-to-end optimization that yields significant gains over baselines on real-world datasets.
What carries the argument
Temporal Alignment Module (TAM), which averages per-frame distances along a continuous relaxation of the alignment path to produce class distances while preserving temporal order.
If this is right
- Significant accuracy gains on Kinetics and Something-Something-V2 in few-shot regimes.
- End-to-end training directly optimizes the few-shot classification objective.
- Explicit use of long-term temporal ordering that prior methods neglected.
- Improved data-efficiency when only a few labeled videos per novel class are supplied.
Where Pith is reading between the lines
- The same alignment idea could be tested on other ordered data such as audio clips or motion-capture sequences.
- If alignment proves robust, it might reduce reliance on large-scale pretraining for video tasks.
- A natural extension would measure whether the gains hold when frame sampling rates or video lengths vary widely.
- Alignment artifacts might appear most clearly on datasets where actions are defined more by object appearance than by sequence.
- keywords:[
Load-bearing premise
The premise that averaging distances along an alignment path will reliably improve classification accuracy without introducing artifacts from imperfect alignments or frame sampling choices.
What would settle it
An experiment in which a non-aligned baseline (identical architecture but without the alignment-path averaging) matches or exceeds TAM accuracy on Kinetics and Something-Something-V2 under identical few-shot protocols would falsify the claimed benefit of the temporal component.
Figures




read the original abstract
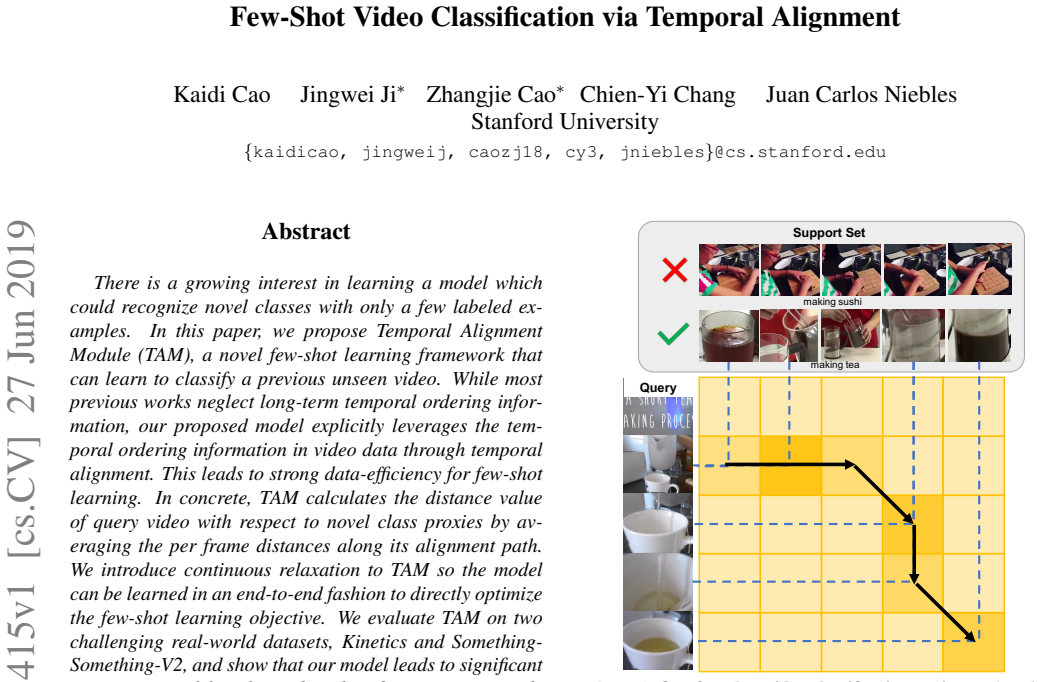
There is a growing interest in learning a model which could recognize novel classes with only a few labeled examples. In this paper, we propose Temporal Alignment Module (TAM), a novel few-shot learning framework that can learn to classify a previous unseen video. While most previous works neglect long-term temporal ordering information, our proposed model explicitly leverages the temporal ordering information in video data through temporal alignment. This leads to strong data-efficiency for few-shot learning. In concrete, TAM calculates the distance value of query video with respect to novel class proxies by averaging the per frame distances along its alignment path. We introduce continuous relaxation to TAM so the model can be learned in an end-to-end fashion to directly optimize the few-shot learning objective. We evaluate TAM on two challenging real-world datasets, Kinetics and Something-Something-V2, and show that our model leads to significant improvement of few-shot video classification over a wide range of competitive baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Temporal Alignment Module (TAM) as a few-shot video classification framework. It claims that most prior methods neglect long-term temporal ordering, whereas TAM explicitly computes query-to-class distances by averaging per-frame distances along an alignment path; a continuous relaxation renders the module differentiable for end-to-end optimization of the few-shot objective. Empirical evaluation on Kinetics and Something-Something-V2 is said to yield significant gains over competitive baselines and improved data efficiency.
Significance. If the reported gains are reproducible and attributable to the ordering-preserving alignment rather than relaxation artifacts, the work would usefully extend few-shot video methods by supplying an explicit mechanism for temporal structure. The choice of two challenging real-world datasets is appropriate for the claim.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('significant improvement ... over a wide range of competitive baselines' and 'strong data-efficiency') is stated without any quantitative values for the baselines, metrics, effect sizes, number of shots, or statistical significance; this information is load-bearing for assessing whether the temporal-alignment mechanism actually delivers the asserted benefit.
- [Abstract] Abstract (TAM description): the method rests on averaging distances along a continuously relaxed alignment path, yet no analytic bound, sensitivity analysis, or ablation is referenced that would demonstrate the relaxed path remains faithful to discrete ordering under realistic frame-sampling variation; without such verification the observed gains could be artifacts of the relaxation rather than evidence for the ordering signal the paper claims to exploit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the TAM formulation. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('significant improvement ... over a wide range of competitive baselines' and 'strong data-efficiency') is stated without any quantitative values for the baselines, metrics, effect sizes, number of shots, or statistical significance; this information is load-bearing for assessing whether the temporal-alignment mechanism actually delivers the asserted benefit.
Authors: We agree that the abstract would benefit from concrete quantitative anchors. In the revised version we will insert the key reported numbers (e.g., 5-shot and 1-shot top-1 accuracies on Kinetics and Something-Something-V2 together with the absolute gains over the strongest baselines) while remaining within the word limit. revision: yes
-
Referee: [Abstract] Abstract (TAM description): the method rests on averaging distances along a continuously relaxed alignment path, yet no analytic bound, sensitivity analysis, or ablation is referenced that would demonstrate the relaxed path remains faithful to discrete ordering under realistic frame-sampling variation; without such verification the observed gains could be artifacts of the relaxation rather than evidence for the ordering signal the paper claims to exploit.
Authors: The full manuscript already contains ablations that replace the continuous relaxation with discrete DTW and with random alignments, showing that the ordering signal is responsible for the gains. Nevertheless, we acknowledge that an explicit sensitivity study under varied frame sampling rates is not presented. We will add this analysis (both quantitative tables and qualitative alignment visualizations) to the supplementary material. revision: partial
Circularity Check
No circularity; TAM is an independent empirical addition
full rationale
The paper's central derivation introduces TAM as a new module that averages per-frame distances along an alignment path and applies continuous relaxation for differentiability. No provided equations, self-citations, or claims reduce the claimed data-efficiency gains to a quantity defined by the paper's own fitted inputs or prior self-work by construction. The improvement is presented as arising from the added temporal alignment mechanism and is evaluated on external datasets (Kinetics, Something-Something-V2), rendering the chain self-contained against benchmarks rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://20bn.com/ datasets/jester
The 20bn-jester dataset v1. https://20bn.com/ datasets/jester. 5
-
[2]
S. F. Altschul, T. L. Madden, A. A. Sch ¨affer, J. Zhang, Z. Zhang, W. Miller, and D. J. Lipman. Gapped blast and psi-blast: a new generation of protein database search pro- grams. Nucleic acids research, 25(17):3389–3402, 1997. 3
work page 1997
-
[3]
L. Bottou. Large-scale machine learning with stochastic gra- dient descent. In Proceedings of COMPSTAT’2010, pages 177–186. Springer, 2010. 6
work page 2010
-
[4]
J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 6299–6308, 2017. 1, 2, 4
work page 2017
-
[5]
C.-Y . Chang, D.-A. Huang, Y . Sui, L. Fei-Fei, and J. C. Niebles. D3TW : Discriminative differentiable dynamic time warping for weakly supervised action alignment and seg- mentation. arXiv preprint arXiv:1901.02598 , 2019. 3, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[6]
W.-Y . Chen, Y .-C. Liu, Z. Kira, Y .-C. Wang, and J.-B. Huang. A closer look at few-shot classification. In International Conference on Learning Representations, 2019. 1, 6
work page 2019
-
[7]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. 2009. 6
work page 2009
- [8]
-
[9]
C. Finn, P. Abbeel, and S. Levine. Model-agnostic meta- learning for fast adaptation of deep networks. InProceedings of the 34th International Conference on Machine Learning- Volume 70, pages 1126–1135. JMLR. org, 2017. 2, 6
work page 2017
-
[10]
V . Garcia and J. Bruna. Few-shot learning with graph neural networks. In ICLR, 2017. 1, 2
work page 2017
-
[11]
S. Gidaris and N. Komodakis. Dynamic few-shot visual learning without forgetting. InProceedings of the IEEE Con- ference on Computer Vision and Pattern Recognition, pages 4367–4375, 2018. 6
work page 2018
- [12]
-
[13]
B. Hariharan and R. Girshick. Low-shot visual recogni- tion by shrinking and hallucinating features. In Proceedings of the IEEE International Conference on Computer Vision , pages 3018–3027, 2017. 2
work page 2017
-
[14]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learn- ing for image recognition. In Proceedings of the IEEE con- ference on computer vision and pattern recognition , pages 770–778, 2016. 6
work page 2016
-
[15]
Learning to Remember Rare Events
Ł. Kaiser, O. Nachum, A. Roy, and S. Bengio. Learning to remember rare events. arXiv preprint arXiv:1703.03129,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
A. Karpathy, G. Toderici, S. Shetty, T. Leung, R. Sukthankar, and L. Fei-Fei. Large-scale video classification with convo- lutional neural networks. In Proceedings of the IEEE con- ference on Computer Vision and Pattern Recognition, pages 1725–1732, 2014. 5
work page 2014
-
[17]
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vi- jayanarasimhan, F. Viola, T. Green, T. Back, P. Natsev, et al. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950, 2017. 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [18]
-
[19]
O. Kliper-Gross, T. Hassner, and L. Wolf. One shot similar- ity metric learning for action recognition. In International Workshop on Similarity-Based Pattern Recognition , pages 31–45. Springer, 2011. 2
work page 2011
-
[20]
G. Koch, R. Zemel, and R. Salakhutdinov. Siamese neu- ral networks for one-shot image recognition. In ICML Deep Learning Workshop, volume 2, 2015. 2
work page 2015
- [21]
-
[22]
A. Mensch and M. Blondel. Differentiable dynamic pro- gramming for structured prediction and attention. ICML,
- [23]
- [24]
-
[25]
T. Munkhdalai and H. Yu. Meta networks. In Proceedings of the 34th International Conference on Machine Learning- Volume 70, pages 2554–2563. JMLR. org, 2017. 2
work page 2017
-
[26]
On First-Order Meta-Learning Algorithms
A. Nichol and J. Schulman. Reptile: a scalable metalearning algorithm. arXiv preprint arXiv:1803.02999, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [27]
-
[28]
H. Qi, M. Brown, and D. G. Lowe. Low-shot learning with imprinted weights. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 5822– 5830, 2018. 6
work page 2018
-
[29]
Z. Qiu, T. Yao, and T. Mei. Learning spatio-temporal repre- sentation with pseudo-3d residual networks. In proceedings of the IEEE International Conference on Computer Vision , pages 5533–5541, 2017. 3
work page 2017
-
[30]
S. Ravi and H. Larochelle. Optimization as a model for few- shot learning. 2016. 2
work page 2016
-
[31]
A. Richard, H. Kuehne, A. Iqbal, and J. Gall. Neuralnetwork-viterbi: A framework for weakly su- pervised video learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 7386–7395, 2018. 3
work page 2018
-
[32]
A. A. Rusu, D. Rao, J. Sygnowski, O. Vinyals, R. Pas- canu, S. Osindero, and R. Hadsell. Meta-learning with latent embedding optimization. arXiv preprint arXiv:1807.05960,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
P. Scovanner, S. Ali, and M. Shah. A 3-dimensional sift de- scriptor and its application to action recognition. InProceed- ings of the 15th ACM international conference on Multime- dia, pages 357–360. ACM, 2007. 2
work page 2007
-
[34]
G. A. Sigurdsson, G. Varol, X. Wang, A. Farhadi, I. Laptev, and A. Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In European Confer- ence on Computer Vision , pages 510–526. Springer, 2016. 5
work page 2016
- [35]
-
[36]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
K. Soomro, A. R. Zamir, and M. Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402, 2012. 5
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[37]
D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3d convolutional net- works. In Proceedings of the IEEE international conference on computer vision, pages 4489–4497, 2015. 2, 4
work page 2015
-
[38]
D. Tran, H. Wang, L. Torresani, J. Ray, Y . LeCun, and M. Paluri. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages 6450– 6459, 2018. 3
work page 2018
-
[39]
O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al. Matching networks for one shot learning. In Advances in neural information processing systems , pages 3630–3638,
-
[40]
H. Wang and C. Schmid. Action recognition with improved trajectories. In Proceedings of the IEEE international con- ference on computer vision, pages 3551–3558, 2013. 2
work page 2013
-
[41]
L. Wang, Y . Xiong, Z. Wang, Y . Qiao, D. Lin, X. Tang, and L. Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European confer- ence on computer vision, pages 20–36. Springer, 2016. 1, 2, 4, 6
work page 2016
-
[42]
X. Wang, R. Girshick, A. Gupta, and K. He. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 7794– 7803, 2018. 3, 4
work page 2018
-
[43]
X. Wang and A. Gupta. Videos as space-time region graphs. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 399–417, 2018. 3
work page 2018
-
[44]
Y .-X. Wang, R. Girshick, M. Hebert, and B. Hariharan. Low- shot learning from imaginary data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 7278–7286, 2018. 2
work page 2018
-
[45]
S. Xie, C. Sun, J. Huang, Z. Tu, and K. Murphy. Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. In Proceedings of the European Con- ference on Computer Vision (ECCV), pages 305–321, 2018. 4, 5
work page 2018
-
[46]
B. Zhou, A. Andonian, A. Oliva, and A. Torralba. Temporal relational reasoning in videos. In Proceedings of the Euro- pean Conference on Computer Vision (ECCV) , pages 803– 818, 2018. 3, 4, 5, 7
work page 2018
- [47]
-
[48]
M. Zolfaghari, K. Singh, and T. Brox. Eco: Efficient con- volutional network for online video understanding. In Pro- ceedings of the European Conference on Computer Vision (ECCV), pages 695–712, 2018. 4
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.