The Resale Price Prediction of Secondhand Jewelry Items Using a Multi-modal Deep Model with Iterative Co-Attention
Pith reviewed 2026-05-25 12:03 UTC · model grok-4.3
The pith
Iterative co-attention on images and attributes enables resale price prediction for secondhand jewelry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We build a multimodal model for secondhand jewelry resale price prediction that uses images and attributes processed through iterative co-attention networks to model expert observation, and we demonstrate its effectiveness on a large dataset from a collaborating fashion retailer.
What carries the argument
Iterative co-attention networks that iteratively observe the appearance and attributes of the product to model expert pricing.
If this is right
- The model autonomously assesses resale prices without professional knowledge.
- It achieves practical performance using state-of-the-art multimodal deep neural networks.
- The iterative co-attention process operates effectively for resale price prediction.
- The architecture applies widely to other fashion items where appearance and specifications matter.
Where Pith is reading between the lines
- Automating jewelry pricing this way could standardize valuations across different retailers and reduce discrepancies caused by individual expert judgment.
- Similar iterative attention models might be tested on predicting prices for other secondhand goods like electronics or clothing.
- Adding temporal market data as an additional input could allow the model to account for fluctuating demand in resale prices.
Load-bearing premise
The pricing procedure of an expert can be modeled using iterative co-attention networks in which the appearance and attributes of the product are carefully and iteratively observed.
What would settle it
Running the model on a new set of jewelry items and finding that its price predictions deviate substantially from actual market resale prices or expert valuations would falsify the claim of practical effectiveness.
Figures
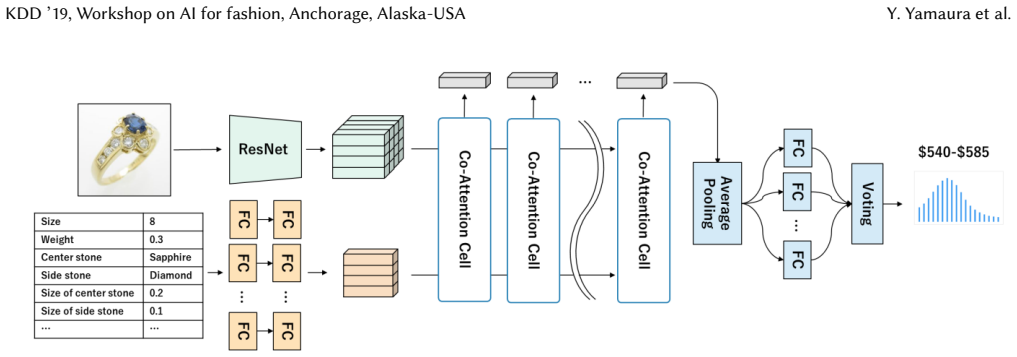
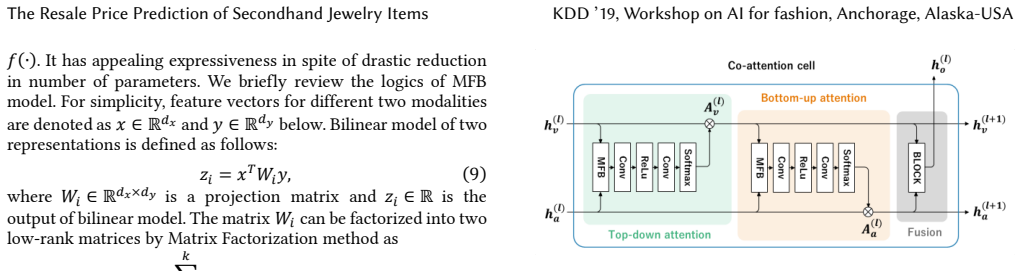

read the original abstract
The resale price assessment of secondhand jewelry items relies heavily on the individual knowledge and skill of domain experts. In this paper, we propose a methodology for reconstructing an AI system that autonomously assesses the resale prices of secondhand jewelry items without the need for professional knowledge. As shown in recent studies on fashion items, multimodal approaches combining specifications and visual information of items have succeeded in obtaining fine-grained representations of fashion items, although they generally apply simple vector operations through a multimodal fusion. We similarly build a multimodal model using images and attributes of the product and further employ state-of-the-art multimodal deep neural networks applied in computer vision to achieve a practical performance level. In addition, we model the pricing procedure of an expert using iterative co-attention networks in which the appearance and attributes of the product are carefully and iteratively observed. Herein, we demonstrate the effectiveness of our model using a large dataset of secondhand no brand jewelry items received from a collaborating fashion retailer, and show that the iterative co-attention process operates effectively in the context of resale price prediction. Our model architecture is widely applicable to other fashion items where appearance and specifications are important aspects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multimodal deep neural network for predicting resale prices of secondhand no-brand jewelry items. It combines product images and attributes via iterative co-attention to model the expert pricing procedure of carefully and iteratively observing appearance and specifications. The authors claim this yields practical performance on a large proprietary dataset from a collaborating fashion retailer and that the co-attention process operates effectively; the architecture is presented as applicable to other fashion items.
Significance. If the empirical claims hold with proper validation, the work could offer a practical multimodal approach for automated valuation in secondhand fashion markets, extending prior multimodal fusion techniques with iterative co-attention. The modeling of expert procedure via attention is conceptually interesting for interpretability in e-commerce, though the proprietary data limits generalizability and reproducibility.
major comments (2)
- [Abstract] Abstract: The central empirical claim that the model demonstrates effectiveness and that iterative co-attention operates effectively is unsupported by any metrics (e.g., MAE, RMSE), baselines, error bars, dataset statistics, or ablation results. This is load-bearing because the paper's contribution is framed as an empirical demonstration on retailer data.
- [Abstract] Abstract and proposed method section: The claim that iterative co-attention networks model the expert pricing procedure (i.e., that appearance and attributes are 'carefully and iteratively observed' in a manner analogous to a human expert) lacks supporting evidence such as attention visualizations, expert comparison, or ablation removing the iterative component. Superior regression could arise from standard multimodal fusion rather than from reconstructing the expert procedure.
minor comments (1)
- [Abstract] The abstract refers to 'state-of-the-art multimodal deep neural networks applied in computer vision' without naming the specific architectures or citing the relevant papers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the presentation of empirical results and supporting evidence for the modeling claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim that the model demonstrates effectiveness and that iterative co-attention operates effectively is unsupported by any metrics (e.g., MAE, RMSE), baselines, error bars, dataset statistics, or ablation results. This is load-bearing because the paper's contribution is framed as an empirical demonstration on retailer data.
Authors: We agree that the abstract should be self-contained with quantitative support. The full manuscript reports MAE, RMSE, baseline comparisons, and dataset statistics in the experiments section, but these are not summarized in the abstract. We will revise the abstract to include key performance metrics with error bars, dataset size and split statistics, and a brief mention of ablation results demonstrating the contribution of iterative co-attention. revision: yes
-
Referee: [Abstract] Abstract and proposed method section: The claim that iterative co-attention networks model the expert pricing procedure (i.e., that appearance and attributes are 'carefully and iteratively observed' in a manner analogous to a human expert) lacks supporting evidence such as attention visualizations, expert comparison, or ablation removing the iterative component. Superior regression could arise from standard multimodal fusion rather than from reconstructing the expert procedure.
Authors: The iterative co-attention mechanism is motivated by the expert pricing workflow described in the introduction. We acknowledge that the current manuscript does not include attention visualizations or a dedicated ablation isolating the iterative component versus standard fusion. We will add (i) qualitative attention map visualizations showing iterative refinement across image and attribute modalities and (ii) a quantitative ablation comparing the full iterative model against a non-iterative multimodal baseline to demonstrate the incremental benefit. revision: yes
Circularity Check
No derivation chain; purely empirical model evaluation on external retailer dataset
full rationale
The paper proposes a multimodal architecture with iterative co-attention for resale price regression and reports performance on a proprietary dataset from a collaborating retailer. No first-principles derivation, uniqueness theorem, or parameter fitting that is then relabeled as prediction is present. The central claim is an empirical demonstration that the model 'operates effectively,' which does not reduce to any input by construction. Self-citations are absent from the provided text. This is a standard applied ML paper whose validity rests on external data and benchmarks rather than internal definitional closure.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network weights and attention parameters
axioms (2)
- domain assumption Multimodal approaches combining specifications and visual information succeed in obtaining fine-grained representations of fashion items.
- ad hoc to paper Iterative co-attention networks can model the pricing procedure of an expert.
Reference graph
Works this paper leans on
-
[1]
Aaron Kessler. 2019. Rise of the Fashion Resale Marketplaces. Raymond James & Associates Industry Report
work page 2019
-
[2]
Imran Amed, Achim Berg, Anita Balchandani, Johanna Andersson, Saskia Hedrich, Robb Young, Marco Beltrami, Dale Kim, and Felix Rölkenes. 2019. The State of Fashion 2019. McKinsey & Company
work page 2019
-
[3]
Gordon S. Linoff and Michael. J. A. Berry, John. 2011. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management. Wiley & Sons, Inc
work page 2011
-
[4]
Ian H. Witten , Eibe Frank, Mark A. Hall, an d Christopher J. Pal. 2016. Data Mining: Practical Machine Learning Tools and Techniques. Morgan Kaufmann
work page 2016
-
[5]
Bo Zhao, Jiashi Feng, Xiao Wu, and Shuicheng Yan. 2017. Memory-Augmented Attribute Manipulation Networks for Interactive Fashion Search. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 6156-6164
work page 2017
-
[6]
Lizi Liao, Xiangnan He, Bo Zhao, Chong -Wah Ngo, and Tat -Seng Chua. 2018. Interpretable Multimodal Retrieval for Fashion Products. In Proceedings of the 26th ACM International Conference on Multimedia (MM). 1571-1579
work page 2018
-
[7]
Ivona Tautkute, Tomasz Trzcinski, Aleksander Skorupa, Lukasz Brocki, and Krzysztof Marasek. 2019. DeepStyle: Multimodal Search Engine for Fashion and Interior Design. IEEE Access 2019
work page 2019
- [8]
-
[9]
Ruining He and Julian McAuley. 2016. VBPR: Visual Bayesian Personaliz ed Ranking from Implicit Feedback. In Proceedings of the 30th AAAI Conference on Artificial Intelligence (AAAI). 144-150
work page 2016
-
[10]
Ruining He, Chunbin Lin, Jianguo Wang, and Julian McAuley. 2016. Sherlock: Sparse Hierarchical Embeddings for Visually -aware One -class Collaborative Filtering. In Proceedings of the 35th International Joint Conference on Artificial Intelligence (IJCAI). 3740-3746
work page 2016
-
[11]
Qiang Liu, Shu Wu, and Liang Wang. 2017. DeepStyle: Learning User Preferences for Visual Recommendation. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval . ACM, 841-844
work page 2017
-
[12]
Lawrence Zitnick, and Devi Parikh
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. 2015. VQA: Vis ual Question Answering. IEEE International Conference on Computer Vision (ICCV). 2425-2433
work page 2015
-
[13]
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. 2016. Multimodal Compact Bilinear Pooling for Visual Question Answ ering and Visual Grounding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP) . The Association for Computational Linguistics. 457-468
work page 2016
-
[14]
Jin-Hwa Kim, Kyoung-Woon On, Woosang Lim, Jeonghee Kim, Jung -Woo Ha, Byoung-Tak Zhang. 2017. Hadamard Product for Low-rank Bilinear Pooling. In the 5th International Conference on Learning Representations (ICLR)
work page 2017
-
[15]
Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. 2017. Multi-modal Factorized Bilinear Pooling with Co -Attention Learning for Visual Question Answering. IEEE International Conference on Computer Vision (ICCV). 1839-1848
work page 2017
-
[16]
Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. 2018. Beyond Bilinear: Generalized Multimodal Factorized High -Order Pooling for Visual Que stion Answering. IEEE Transactions on Neural Networks and Learning Systems (TNNLS). 5947-5959
work page 2018
-
[17]
Hedi Ben -Younes, R émi Cadene, Matthieu Cord, and Nicolas Thome. 2017. Mutan: Multimodal Tucker Fusion for Visual Question Answering. IEEE International Conference on Computer Vision (ICCV). 2631-2639
work page 2017
-
[18]
Hedi Ben -Younes, R émi Cadene, Nicolas Thome and Matthieu Cord. 2019. BLOCK: Bilinear Superdiagonal Fusion for Visual Question Answering and Visual Relationship Detection. In Proceedings of the 33th AAAI Con ference on Artificial Intelligence (AAAI)
work page 2019
-
[19]
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. 2016. Hierarchical Question-Image Co-Attention for Visual Question Answering. In Proceedings of the 30th International Conference on Neural Information P rocessing Systems (NIPS). 289-297
work page 2016
-
[20]
Hyeonseob Nam, Jung-Woo Ha, and Jeonghee. 2017. Dual Attention Networks for Multimodal Reasoning and Matching. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2156-2164
work page 2017
-
[21]
Duy-Ken Nguyen and Takayuki Okatani. 2018. Improved Fusion of Visual and Language Representations by Dense Symmetric Co -Attention for Visual Question Answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 6087-6096
work page 2018
-
[22]
Rémi Cadene, Hedi Ben -Younes, Matthieu Cord, and Nicolas Thome. 2019. MUREL: Multimodal Relational Reasoning for Visual Question Answering, In IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
work page 2019
-
[23]
Charles E. Connor, Howard E. Egeth, and Steven Yantis, 2004. Visual Attention: Bottom-Up Versus Top-Down. Current Biology. R850-R852
work page 2004
-
[24]
Lucia Melloni, Sara van Leeuwen, Arjen Alink, Notger G. M üller. 2012. Interaction Between Bottom-up Saliency and Top-down Control: How Saliency Maps Are Created in the Human Brain. Cerebral Cortex. 2943-2952
work page 2012
-
[25]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. 2016. Deep Residual Learning for Image Recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770-778
work page 2016
-
[26]
Jia Deng , Wei Dong, Richard Socher, Li -Jia Li, Kai Li, and Li Fei -Fei. 2009. ImageNet: A Large -Scale Hierarchical Image Database. IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 248-255
work page 2009
-
[27]
Tomas Mikolov, llya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems (NIPS). 3111-3119
work page 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.