Bandit Learning for Diversified Interactive Recommendation
Pith reviewed 2026-05-25 12:19 UTC · model grok-4.3
The pith
DC²B integrates determinantal point processes into contextual combinatorial bandits to deliver diverse interactive recommendations with regret guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
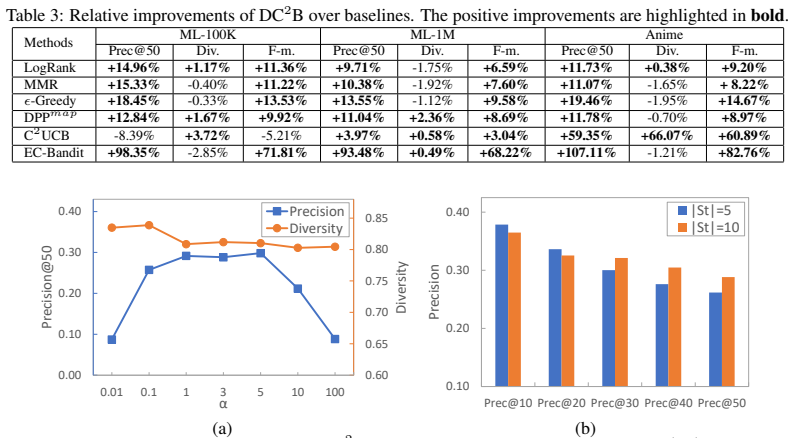
The paper establishes that DC²B employs determinantal point process in the recommendation procedure to promote diversity of the recommendation results. To learn the model parameters, a Thompson sampling-type algorithm based on variational Bayesian inference is proposed. In addition, theoretical regret analysis is also provided to guarantee the performance of DC²B.
What carries the argument
Determinantal point process integrated into the combinatorial bandit selection step to promote diversity while preserving regret bounds
Load-bearing premise
The determinantal point process can be integrated into the combinatorial bandit selection step without invalidating the regret analysis or requiring post-hoc adjustments that affect the claimed performance guarantees.
What would settle it
An experiment on a real dataset where the observed cumulative regret under DPP-based selection exceeds the paper's derived theoretical bound.
Figures
read the original abstract
Interactive recommender systems that enable the interactions between users and the recommender system have attracted increasing research attentions. Previous methods mainly focus on optimizing recommendation accuracy. However, they usually ignore the diversity of the recommendation results, thus usually results in unsatisfying user experiences. In this paper, we propose a novel diversified recommendation model, named Diversified Contextual Combinatorial Bandit (DC$^2$B), for interactive recommendation with users' implicit feedback. Specifically, DC$^2$B employs determinantal point process in the recommendation procedure to promote diversity of the recommendation results. To learn the model parameters, a Thompson sampling-type algorithm based on variational Bayesian inference is proposed. In addition, theoretical regret analysis is also provided to guarantee the performance of DC$^2$B. Extensive experiments on real datasets are performed to demonstrate the effectiveness of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DC²B, a diversified contextual combinatorial bandit model for interactive recommendation with implicit feedback. It integrates a determinantal point process (DPP) into the recommendation step to promote diversity, learns parameters via a Thompson-sampling algorithm that uses variational Bayesian inference, supplies a theoretical regret analysis, and reports experiments on real datasets demonstrating effectiveness.
Significance. If the regret bound is shown to hold after the DPP modification, the work would provide a concrete algorithmic mechanism for trading off accuracy against diversity inside a combinatorial bandit framework together with a supporting analysis; this is a practically relevant direction for interactive recommenders.
major comments (1)
- [theoretical regret analysis (as described in the abstract and introduction)] The central claim that the Thompson-sampling regret analysis continues to hold after replacing standard combinatorial selection with DPP sampling is load-bearing. DPP introduces negative dependence across items that changes the joint sampling distribution; standard concentration arguments used in combinatorial TS proofs rely on independence or positive association properties that are no longer present. The manuscript must therefore either re-derive the relevant concentration or exploration terms under the DPP kernel or explicitly invoke a lemma that already accounts for the DPP-induced correlations.
minor comments (2)
- [Abstract] Abstract: 'attracted increasing research attentions' should read 'attention'; 'usually results in unsatisfying user experiences' should read 'result'.
- Notation for the DPP kernel and the variational posterior should be introduced with explicit definitions before they appear in algorithmic descriptions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a substantive gap in the theoretical analysis. The concern about whether the regret bound remains valid under DPP sampling is well-taken and requires a substantive revision.
read point-by-point responses
-
Referee: The central claim that the Thompson-sampling regret analysis continues to hold after replacing standard combinatorial selection with DPP sampling is load-bearing. DPP introduces negative dependence across items that changes the joint sampling distribution; standard concentration arguments used in combinatorial TS proofs rely on independence or positive association properties that are no longer present. The manuscript must therefore either re-derive the relevant concentration or exploration terms under the DPP kernel or explicitly invoke a lemma that already accounts for the DPP-induced correlations.
Authors: We agree that the negative dependence induced by the DPP kernel invalidates direct application of standard concentration arguments that assume independence or positive association. The original manuscript adapted combinatorial TS regret bounds without explicitly re-deriving the relevant terms or citing a lemma that handles DPP correlations. We will revise the theoretical section to either (a) derive concentration inequalities that account for the negative dependence or (b) invoke an appropriate existing result from the DPP literature. This constitutes a major revision to the analysis. revision: yes
Circularity Check
No circularity: derivation remains independent of fitted inputs or self-citations
full rationale
The provided abstract and description outline a model (DC²B) that integrates DPP sampling into combinatorial selection, a variational Bayesian Thompson sampling procedure, and an asserted theoretical regret bound. No equations, parameter-fitting steps, or self-citations are visible that would reduce the regret guarantee or diversity promotion to a quantity defined in terms of itself or to a fitted parameter renamed as a prediction. The central claims rest on external combinatorial bandit machinery and DPP properties rather than on any self-definitional loop or load-bearing self-citation chain within the paper. This is the normal case of a self-contained proposal whose performance guarantees, if valid, are not forced by construction from the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DC²B employs determinantal point process in the recommendation procedure to promote diversity... Thompson sampling-type algorithm based on variational Bayesian inference... theoretical regret analysis
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Regret(T, π) = ∑ E[max f_θ(s) − f_θ(St)] ... O(d ln(α s e^{2α s T} √d) √T)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Interactive recommender systems: Tutorial
Harald Steck, Roelof van Zwol, and Chris Johnson. Interactive recommender systems: Tutorial. In RecSys’15. ACM, 2015
work page 2015
-
[2]
A contextual-bandit approach to personalized news article recommendation
Lihong Li, Wei Chu, John Langford, and Robert E Schapire. A contextual-bandit approach to personalized news article recommendation. In WWW’10, 2010
work page 2010
-
[3]
Interactive collaborative filtering
Xiaoxue Zhao, Weinan Zhang, and Jun Wang. Interactive collaborative filtering. In CIKM’13. ACM, 2013
work page 2013
-
[4]
Personalized recommendation via parameter-free contextual bandits
Liang Tang, Yexi Jiang, Lei Li, Chunqiu Zeng, and Tao Li. Personalized recommendation via parameter-free contextual bandits. In SIGIR’15, 2015
work page 2015
-
[5]
Factorization bandits for interactive recommendation
Huazheng Wang, Qingyun Wu, and Hongning Wang. Factorization bandits for interactive recommendation. In AAAI’17, 2017
work page 2017
-
[6]
Bandit learning with implicit feedback
Yi Qi, Qingyun Wu, Hongning Wang, Jie Tang, and Maosong Sun. Bandit learning with implicit feedback. In NIPS’18, 2018
work page 2018
-
[7]
Yue Shi, Martha Larson, and Alan Hanjalic. Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Computing Surveys, 47(1):3, 2014
work page 2014
-
[8]
Exploiting geographical neighborhood characteristics for location recommendation
Yong Liu, Wei Wei, Aixin Sun, and Chunyan Miao. Exploiting geographical neighborhood characteristics for location recommendation. In CIKM’14, 2014
work page 2014
-
[9]
A boosting algorithm for item recom- mendation with implicit feedback
Yong Liu, Peilin Zhao, Aixin Sun, and Chunyan Miao. A boosting algorithm for item recom- mendation with implicit feedback. In IJCAI’15, 2015. 9
work page 2015
-
[10]
Dynamic bayesian logistic matrix factorization for recommendation with implicit feedback
Yong Liu, Lifan Zhao, Guimei Liu, Xinyan Lu, Peng Gao, Xiao-Li Li, and Zhihui Jin. Dynamic bayesian logistic matrix factorization for recommendation with implicit feedback. In IJCAI’18, 2018
work page 2018
-
[11]
Modeling user exposure in recommendation
Dawen Liang, Laurent Charlin, James McInerney, and David M Blei. Modeling user exposure in recommendation. In WWW’16, 2016
work page 2016
-
[12]
Diversity in recommender systems–a survey
Matevž Kunaver and Tomaž Požrl. Diversity in recommender systems–a survey. Knowledge- Based Systems, 123:154–162, 2017
work page 2017
-
[13]
Determinantal point processes for machine learning
Alex Kulesza, Ben Taskar, et al. Determinantal point processes for machine learning. Founda- tions and Trends R⃝ in Machine Learning, 5(2–3), 2012
work page 2012
-
[14]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. In SIGIR’98, 1998
work page 1998
-
[15]
Promoting diversity in recommendation by entropy regularizer
Lijing Qin and Xiaoyan Zhu. Promoting diversity in recommendation by entropy regularizer. In IJCAI’13, 2013
work page 2013
-
[16]
A framework for recommending relevant and diverse items
Chaofeng Sha, Xiaowei Wu, and Junyu Niu. A framework for recommending relevant and diverse items. In IJCAI’16, 2016
work page 2016
-
[17]
Avoiding monotony: improving the diversity of recommendation lists
Mi Zhang and Neil Hurley. Avoiding monotony: improving the diversity of recommendation lists. In RecSys’08, 2008
work page 2008
-
[18]
Post processing recommender systems for diversity
Arda Antikacioglu and R Ravi. Post processing recommender systems for diversity. In KDD’17, 2017
work page 2017
-
[19]
Learning to recommend accurate and diverse items
Peizhe Cheng, Shuaiqiang Wang, Jun Ma, Jiankai Sun, and Hui Xiong. Learning to recommend accurate and diverse items. In WWW’17, 2017
work page 2017
-
[20]
Fast greedy map inference for determinantal point process to improve recommendation diversity
Laming Chen, Guoxin Zhang, and Eric Zhou. Fast greedy map inference for determinantal point process to improve recommendation diversity. In NIPS’18, 2018
work page 2018
-
[21]
Practical diversified recommendations on youtube with determinantal point pro- cesses
Mark Wilhelm, Ajith Ramanathan, Alexander Bonomo, Sagar Jain, Ed H Chi, and Jennifer Gillenwater. Practical diversified recommendations on youtube with determinantal point pro- cesses. In CIKM’18, 2018
work page 2018
-
[22]
Pd-gan: Adversarial learning for personalized diversity-promoting recommendation
Qiong Wu, Yong Liu, Chunyan Miao, Binqiang Zhao, Yin Zhao, and Lu Guan. Pd-gan: Adversarial learning for personalized diversity-promoting recommendation. In IJCAI’19, 2019
work page 2019
-
[23]
Interactive social recommendation
Xin Wang, Steven CH Hoi, Chenghao Liu, and Martin Ester. Interactive social recommendation. In CIKM’17, 2017
work page 2017
-
[24]
Contextual combinatorial bandit and its application on diversified online recommendation
Lijing Qin, Shouyuan Chen, and Xiaoyan Zhu. Contextual combinatorial bandit and its application on diversified online recommendation. In SDM’14, 2014
work page 2014
-
[25]
Variational inference: A review for statisticians
David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518), 2017
work page 2017
-
[26]
A variational approach to bayesian logistic regression models and their extensions
T Jaakkola and M Jordan. A variational approach to bayesian logistic regression models and their extensions. In Sixth International Workshop on Artificial Intelligence and Statistics, volume 82, page 4, 1997
work page 1997
-
[27]
Learning to optimize via posterior sampling.Mathematics of Operations Research, 39(4), 2014
Daniel Russo and Benjamin Van Roy. Learning to optimize via posterior sampling.Mathematics of Operations Research, 39(4), 2014
work page 2014
-
[28]
Bpr: Bayesian personalized ranking from implicit feedback
Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. Bpr: Bayesian personalized ranking from implicit feedback. In UAI’09, 2009
work page 2009
-
[29]
Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms
Lihong Li, Wei Chu, John Langford, and Xuanhui Wang. Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms. In WSDM’11, 2011
work page 2011
-
[30]
Concentration inequalities and model selection
Pascal Massart. Concentration inequalities and model selection. 2007. 10 Appendices A Proof of Lemma 1 and Lemma 2 A.1 Preliminaries For simplicity, we first use fθ to represent fθ(St), and define Lt(f) = ∑t−1 k=1 (f(Sk) − Rk)2, ˆfLS t = arg minf∈F Lt(f), and ∥f ∥2 Et = ∑t−1 k=1 f 2 (Sk). Then, we introduce the following two important inequalities. Martinga...
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.