RED: A ReRAM-based Deconvolution Accelerator
Pith reviewed 2026-05-25 01:31 UTC · model grok-4.3
The pith
RED accelerator speeds deconvolution 3.69x on ReRAM hardware using pixel mapping and zero skipping
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RED integrates the pixel-wise mapping scheme for reducing redundancy caused by zero-inserting operations and the zero-skipping data flow for increasing the computation parallelism, delivering speedups from 3.69x down to 1.15x and energy reductions from 8 percent to 88.36 percent versus prior ReRAM designs.
What carries the argument
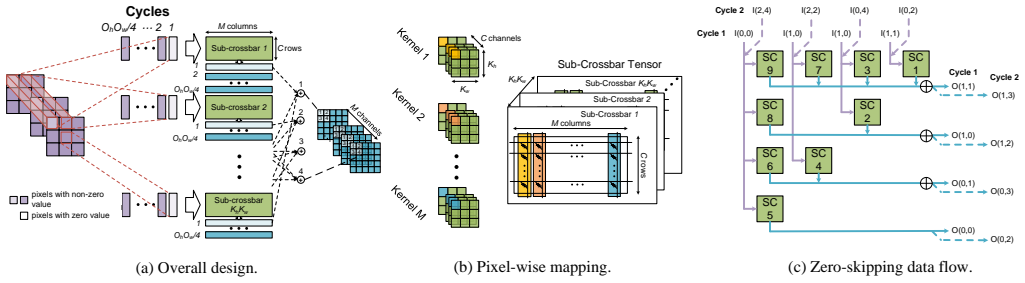
The RED accelerator design that pairs pixel-wise mapping with zero-skipping data flow to handle deconvolution directly in ReRAM crossbars.
If this is right
- Deconvolution layers can run on ReRAM without the previous long latency from zero padding.
- Energy per operation drops substantially for networks that rely on transposed convolutions.
- Computation parallelism rises because skipped zeros no longer occupy cycles or array space.
- The same ReRAM substrate can now support both convolution and deconvolution workloads at comparable efficiency.
Where Pith is reading between the lines
- Similar mapping and skipping tactics could apply to other neural-network operations that introduce structured sparsity or padding.
- Edge devices running generative models might become feasible if the energy reductions hold across full networks.
- Designers could test whether combining RED with existing convolution accelerators yields further system-level gains.
Load-bearing premise
The pixel-wise mapping and zero-skipping dataflow can be realized in ReRAM hardware without new latency, area, or accuracy penalties that erase the reported gains.
What would settle it
A hardware prototype of RED whose measured end-to-end latency or energy exceeds that of the baseline accelerator once mapping and skipping overheads are included.
Figures






read the original abstract
Deconvolution has been widespread in neural networks. For example, it is essential for performing unsupervised learning in generative adversarial networks or constructing fully convolutional networks for semantic segmentation. Resistive RAM (ReRAM)-based processing-in-memory architecture has been widely explored in accelerating convolutional computation and demonstrates good performance. Performing deconvolution on existing ReRAM-based accelerator designs, however, suffers from long latency and high energy consumption because deconvolutional computation includes not only convolution but also extra add-on operations. To realize the more efficient execution for deconvolution, we analyze its computation requirement and propose a ReRAM-based accelerator design, namely, RED. More specific, RED integrates two orthogonal methods, the pixel-wise mapping scheme for reducing redundancy caused by zero-inserting operations and the zero-skipping data flow for increasing the computation parallelism and therefore improving performance. Experimental evaluations show that compared to the state-of-the-art ReRAM-based accelerator, RED can speed up operation 3.69x~1.15x and reduce 8%~88.36% energy consumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RED, a ReRAM-based processing-in-memory accelerator for deconvolution operations. It introduces two orthogonal techniques: a pixel-wise mapping scheme to reduce redundancy from zero-insertion operations and a zero-skipping dataflow to increase computation parallelism. The central claim is that these methods enable 3.69×–1.15× speedup and 8%–88.36% energy reduction relative to prior ReRAM-based accelerators for workloads in GANs and FCNs.
Significance. If the net gains hold after accounting for implementation overheads, the work would be significant for addressing a known inefficiency in ReRAM PIM designs when handling deconvolution, which is increasingly important in generative and segmentation networks. The orthogonal combination of mapping and skipping is a conceptual strength.
major comments (2)
- [Abstract] Abstract: the reported 3.69×–1.15× speedup and 8%–88.36% energy savings are presented without any quantitative breakdown of added latency, area, or power from the pixel-wise mapping circuitry and zero-skipping control logic; this is load-bearing because the central claim requires that these mechanisms produce net improvements rather than being offset by new overheads.
- [Abstract] Abstract and design description: no benchmark workload details, mapping parameters, crossbar utilization figures, or error bars are supplied to allow verification that the evaluated deconvolution patterns match those in target applications (e.g., transposed convolutions in GAN generators); without this, the range of reported gains cannot be assessed for generality.
minor comments (1)
- Notation for the two proposed schemes should be introduced with consistent abbreviations on first use to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity in the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 3.69×–1.15× speedup and 8%–88.36% energy savings are presented without any quantitative breakdown of added latency, area, or power from the pixel-wise mapping circuitry and zero-skipping control logic; this is load-bearing because the central claim requires that these mechanisms produce net improvements rather than being offset by new overheads.
Authors: We agree that the abstract should explicitly note that the reported figures are net gains. The cycle-accurate evaluations model and include the latency, area, and power of the pixel-wise mapping circuitry and zero-skipping control logic when comparing against prior accelerators. We will revise the abstract to state that the improvements account for these overheads. revision: yes
-
Referee: [Abstract] Abstract and design description: no benchmark workload details, mapping parameters, crossbar utilization figures, or error bars are supplied to allow verification that the evaluated deconvolution patterns match those in target applications (e.g., transposed convolutions in GAN generators); without this, the range of reported gains cannot be assessed for generality.
Authors: The evaluation section provides workload details from GANs and FCNs, mapping parameters, and crossbar utilization. We will revise the abstract to summarize the workloads and direct readers to the evaluation section for parameters and figures. Error bars are absent because results are from deterministic simulations; we can add a sensitivity discussion if needed. revision: partial
Circularity Check
No significant circularity; claims rest on external experimental comparisons
full rationale
The paper proposes two hardware techniques (pixel-wise mapping and zero-skipping dataflow) for ReRAM-based deconvolution acceleration and reports speedups/energy savings from experimental evaluations against prior accelerators. No equations, fitted parameters, self-citations, or uniqueness theorems appear in the provided text that would reduce the reported gains to quantities defined by the design itself. The derivation chain consists of analysis of deconvolution requirements followed by independent implementation and benchmarking, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling
Jiajun Wu et al. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In NIPS, pages 82–90, 2016
work page 2016
-
[2]
Semantic Image Inpainting with Deep Generative Models
Raymond Yeh et al. Semantic image inpainting with perceptual and contextual losses. arxiv preprint. arXiv:1607.07539
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Fully convolutional networks for semantic segmentation
Jonathan Long et al. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015
work page 2015
-
[4]
Single-shot refinement neural network for object detection
Shifeng Zhang et al. Single-shot refinement neural network for object detection. In IEEE CVPR, 2018
work page 2018
-
[5]
Ping Chi et al. Prime: A novel processing-in-memory archi- tecture for neural network computation in reram-based main memory. In SIGARCH Comput. Archit. News, volume 44, pages 27–39, 2016
work page 2016
-
[6]
Time: A training-in-memory architecture for rram-based deep neural networks
Ming Cheng et al. Time: A training-in-memory architecture for rram-based deep neural networks. TCAD, 2018
work page 2018
-
[7]
Isaac: A convolutional neural network accel- erator with in-situ analog arithmetic in crossbars
Ali Shafiee et al. Isaac: A convolutional neural network accel- erator with in-situ analog arithmetic in crossbars. SIGARCH Comput. Archit. News , 44(3):14–26, 2016
work page 2016
-
[8]
Pipelayer: A pipelined reram-based accel- erator for deep learning
Linghao Song et al. Pipelayer: A pipelined reram-based accel- erator for deep learning. In HPCA, pages 541–552, 2017
work page 2017
-
[9]
Atomlayer: a universal reram-based cnn accelerator with atomic layer computation
Ximing Qiao et al. Atomlayer: a universal reram-based cnn accelerator with atomic layer computation. In DAC
-
[10]
Reram-based accelerator for deep learning
Bing Li et al. Reram-based accelerator for deep learning. In DATE, pages 815–820, 2018
work page 2018
-
[11]
Fcn-engine: Accelerating deconvolutional layers in classic cnn processors
Dawen Xu et al. Fcn-engine: Accelerating deconvolutional layers in classic cnn processors. In ICCAD, 2018
work page 2018
-
[12]
Regan: A pipelined reram-based accelerator for generative adversarial networks
Fan Chen et al. Regan: A pipelined reram-based accelerator for generative adversarial networks. In ASP-DAC
-
[13]
Spectral Normalization for Generative Adversarial Networks
Takeru Miyato et al. Spectral normalization for generative adversarial networks. arXiv:1802.05957, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford et al. Unsupervised representation learn- ing with deep convolutional generative adversarial networks. arXiv:1511.06434, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Improved techniques for training gans
Tim Salimans et al. Improved techniques for training gans. In NIPS, pages 2234–2242, 2016
work page 2016
-
[16]
Pai Yu Chen et al. Neurosim+: An integrated device-to- algorithm framework for benchmarking synaptic devices and array architectures. In IEDM, pages 6–1, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.