CADS: Core-Aware Dynamic Scheduler for Multicore Memory Controllers
Pith reviewed 2026-05-24 19:40 UTC · model grok-4.3
The pith
CADS uses reinforcement learning to dynamically adjust memory scheduling for multiple cores at runtime, delivering 20% better CPI on PARSEC benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CADS is a core-aware dynamic scheduler for multicore memory controllers that employs reinforcement learning to alter its scheduling strategy dynamically at runtime, utilizing locality among data requests from multiple cores, exploiting parallelism in accessing multiple banks of DRAM, and sharing the DRAM while guaranteeing fairness to all cores. Using CADS policy, we achieve 20% better cycles per instruction (CPI) in running memory intensive and compute intensive PARSEC parallel benchmarks simultaneously, and 16% better CPI with SPEC 2006 benchmarks.
What carries the argument
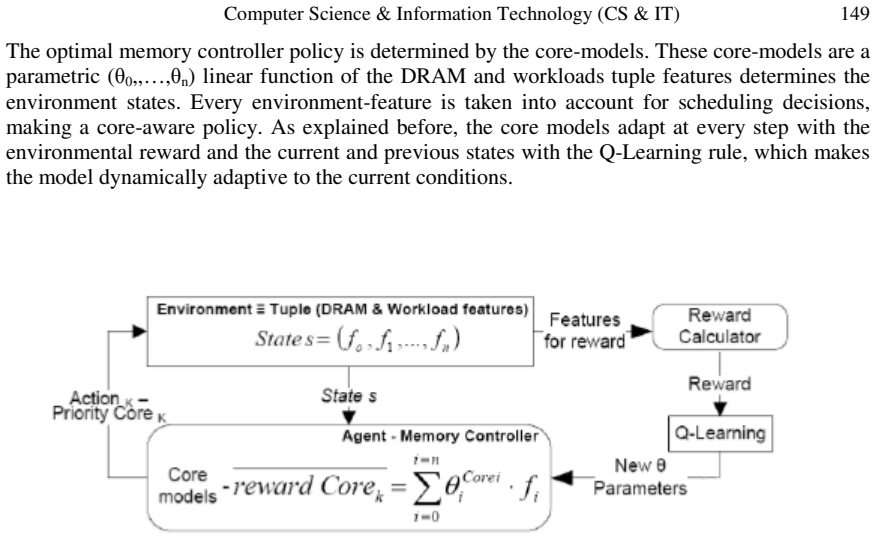
Core-Aware Dynamic Scheduler (CADS) that uses a reinforcement learning agent to choose among scheduling strategies according to observed per-core memory access patterns.
If this is right
- Mixed memory-intensive and compute-intensive workloads on the same multicore chip run with higher effective processor throughput.
- Memory controllers no longer require workload-specific static tuning.
- DRAM bandwidth is divided fairly among cores without manual intervention.
- The same gains appear across both parallel application suites and standard single-program benchmarks.
Where Pith is reading between the lines
- The same runtime-learning method could be applied to scheduling decisions at other shared resources such as last-level cache or on-chip interconnect.
- If the learned policies remain stable on workloads never seen during design, future processors could ship with less hand-tuned scheduling logic.
- Extending the fairness and locality objectives to include power or thermal limits would produce an energy-aware variant of the same scheduler.
Load-bearing premise
A reinforcement learning agent can learn effective, stable scheduling policies at runtime that generalize beyond the training workloads while adding negligible overhead to the memory controller hardware.
What would settle it
A cycle-accurate simulation or hardware prototype of CADS on a multicore processor running the listed PARSEC workload mix that reports CPI improvement below 10 percent or controller area overhead above 5 percent.
Figures





read the original abstract
Memory controller scheduling is crucial in multicore processors, where DRAM bandwidth is shared. Since increased number of requests from multiple cores of processors becomes a source of bottleneck, scheduling the requests efficiently is necessary to utilize all the computing power these processors offer. However, current multicore processors are using traditional memory controllers, which are designed for single-core processors. They are unable to adapt to changing characteristics of memory workloads that run simultaneously on multiple cores. Existing schedulers may disrupt locality and bank parallelism among data requests coming from different cores. Hence, novel memory controllers that consider and adapt to the memory access characteristics, and share memory resources efficiently and fairly are necessary. We introduce Core-Aware Dynamic Scheduler (CADS) for multicore memory controller. CADS uses Reinforcement Learning (RL) to alter its scheduling strategy dynamically at runtime. Our scheduler utilizes locality among data requests from multiple cores and exploits parallelism in accessing multiple banks of DRAM. CADS is also able to share the DRAM while guaranteeing fairness to all cores accessing memory. Using CADS policy, we achieve 20% better cycles per instruction (CPI) in running memory intensive and compute intensive PARSEC parallel benchmarks simultaneously, and 16% better CPI with SPEC 2006 benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Core-Aware Dynamic Scheduler (CADS), a reinforcement learning-based memory controller scheduler for multicore processors. CADS dynamically adapts its policy at runtime to exploit request locality and bank parallelism while maintaining fairness across cores. The central empirical claim is a 20% CPI improvement on simultaneously running memory- and compute-intensive PARSEC benchmarks and a 16% CPI improvement on SPEC 2006 benchmarks relative to conventional schedulers.
Significance. If the RL policy can be shown to generalize stably to unseen workloads and to incur only negligible hardware overhead, the work would demonstrate a practical adaptive alternative to static FR-FCFS scheduling in shared DRAM systems, potentially improving multicore performance under varying memory pressure.
major comments (3)
- [Abstract] Abstract: the headline CPI gains (20% PARSEC, 16% SPEC) are stated without any description of the RL state/action representation, reward function, training procedure, baseline schedulers, or statistical error bars, making it impossible to assess whether the central performance claim is supported by the data.
- [Evaluation] Evaluation sections: the results appear to train and test the RL agent on the same benchmark suites without held-out workload cross-validation or transfer experiments, leaving the claim that the learned policy generalizes beyond the training workloads unsupported.
- [Hardware Implementation] Hardware overhead discussion: the assertion that the RL component adds negligible area, power, and latency is made without any synthesis results, gate counts, or comparison against a baseline FR-FCFS controller, so the practicality of the approach cannot be verified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our work. We address each major point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline CPI gains (20% PARSEC, 16% SPEC) are stated without any description of the RL state/action representation, reward function, training procedure, baseline schedulers, or statistical error bars, making it impossible to assess whether the central performance claim is supported by the data.
Authors: The abstract is intentionally concise per conference guidelines. The body of the paper details the RL formulation (state includes per-core request queues and bank states; actions are priority assignments; reward combines weighted CPI and fairness metric; trained via online Q-learning updates during simulation) and baselines (FR-FCFS and other static policies). Results are averaged over multiple runs with variance shown in plots. We will revise the abstract to include one sentence summarizing the RL approach and baselines while retaining the performance claims. revision: partial
-
Referee: [Evaluation] Evaluation sections: the results appear to train and test the RL agent on the same benchmark suites without held-out workload cross-validation or transfer experiments, leaving the claim that the learned policy generalizes beyond the training workloads unsupported.
Authors: The policy is updated online at runtime using RL, allowing adaptation to workload changes without offline retraining on specific suites. The reported results use standard, diverse PARSEC and SPEC mixes to show consistent gains. To further support generalization, we will add a subsection with held-out cross-validation (train on half the benchmarks, test on the remainder) and note transfer behavior on additional synthetic traces in the revised evaluation section. revision: yes
-
Referee: [Hardware Implementation] Hardware overhead discussion: the assertion that the RL component adds negligible area, power, and latency is made without any synthesis results, gate counts, or comparison against a baseline FR-FCFS controller, so the practicality of the approach cannot be verified.
Authors: The manuscript argues negligibility based on the small size of the Q-table and lookup logic relative to a standard memory controller. We agree quantitative data would strengthen this. In revision we will add estimated gate counts and latency overheads drawn from comparable lightweight RL hardware designs in the literature, along with a direct comparison table versus FR-FCFS. Full place-and-route synthesis remains future work. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents CADS as an RL-based scheduler and reports CPI gains as direct empirical outcomes from running PARSEC and SPEC benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text to support the central claims. The results are framed as experimental measurements rather than quantities derived from the paper's own inputs by construction, rendering the evaluation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Jun Shao and B. T. Davis. A Burst Scheduling Ac cess Reordering Mechanism. In HPCA 13, 2007
work page 2007
-
[3]
Zhao Zhang et al., A permutation based Page Int erleaving Scheme to Reduce Row Buffer Conflicts and Exploit Data Locality. In MICRO 33, 2000
work page 2000
-
[4]
Z. Fang, X. H. Sun, Y. Chen, S. Byna, Core awar e Memory Access Scheduling Schemes. In IPDPS 23,2009
work page 2009
- [5]
-
[6]
B.T. Davis. Modern DRAM Architectures. Ph. D . dissertation, Dept. of EECS, University of Michigan,2000
work page 2000
- [7]
-
[8]
S. Russell, P. Norvig, Artificial Intelligence: A Modern Approach. 2nd edition, Prentice Hall, 200 3
-
[9]
R. M. Tomasul o. An efficient algorithm for exp loiting multiple arithmetic units. In IBM Journal o f Research and Development, Volume 11, Number 1, Page 25, 1967 [10 ]K. Murakami et al., SIMP: A novel high Speed S ingle Processor Architecture. In ISCA 16,1989
work page 1967
-
[10]
T. F. Chen and J. L. Baer, Reducing memory lat ency via non blocking and prefetching caches. In ASPLOS V, 1992
work page 1992
-
[11]
W m. A. W ulf, Sally A. McKee, Hitting the mem ory wall: implications of the obvious. In ACMSIGARCH Computer Architecture News,1995
work page 1995
- [12]
-
[13]
M. Irodova, R. H. Sloan. Reinforcement Learni ng and Function Approximation. In FLAIRS 18, 2005
work page 2005
-
[14]
R. Sutton and A. Ba rto. Reinforcement Learnin g. MIT Press, Cambridge, MA, 1998
work page 1998
-
[15]
D. T. Wang. Modern DRAM Memory Systems Perform ance Analysis and a High Performance, Power Constrained DRAM Scheduling Algorithm. Ph. D. Dissertation, Dept. Of ECE, University of Maryland, 2005
work page 2005
- [16]
-
[17]
Family 10h AMD Ph enom™ II Processor Product Data, 2009
Advanced Micro Devices, Inc. Family 10h AMD Ph enom™ II Processor Product Data, 2009
work page 2009
-
[18]
Intel® Core™ i7 Processor Extreme Edition Series and Intel® Core™ i7 Processor Datasheet, 2008
Intel, Inc. Intel® Core™ i7 Processor Extreme Edition Series and Intel® Core™ i7 Processor Datasheet, 2008
work page 2008
-
[19]
Cuppu et.al., A performance comparison of c ontemporary DRAM architectures
V. Cuppu et.al., A performance comparison of c ontemporary DRAM architectures. In ISCA 26,1999
work page 1999
- [20]
- [21]
-
[22]
N. L. Binkert et al., The M5 simulator: Model ing networked systems. In MICRO 39, 2006
work page 2006
- [23]
-
[24]
C. Bienia et.al.. The PARSEC Benchmark Suite: Characterization and Architectural Implications. In PACT 17, 2008
work page 2008
-
[25]
J. L. Henning,. SPEC CPU2006 bench mark descri ptions. ACM SIGARCH Computer Architecture News,2006
work page 2006
-
[26]
E. Ipek et. al., Self Optimizing Memory Contro llers: A Reinforcement Learning Approach. In ISCA 35, 2008
work page 2008
-
[27]
C. Natarajan et. Al. A study of performance im pact of memory controller f eatures in multi proces sor server environment. In WMPI 3, 2004
work page 2004
- [28]
-
[29]
University of Maryland Memory System Simulator Manual.http://w ww.ece.umd.edu/DRAMsim/download/DRAMsimManual.pdf 162 Computer Science & Information Technology (CS & IT)
-
[30]
A Case for Machine Learning to Opt imize Multicore Performance
Ganapathi,. A.., . K.. Datta, . A.. Fox, and . D.. Patterson, “A Case for Machine Learning to Opt imize Multicore Performance”, HotPar09, Berkeley, CA, 3/2009
work page 2009
-
[31]
J ose F. Martinez , Engin Ipek. Dynam ic Multi core Resource Management: A Machine Learning Approach. In Micro 42,2009
work page 2009
-
[32]
Ramazan Bitirgen et. al., Coordinated Manageme nt of Multiple Interacting Resources in Chip Multiprocessors: A Machine Learning Approach . In Micro 41,2008
work page 2008
-
[33]
al., A Reinforcement Learnin g Approach to OnlineWeb System Auto configuration
Xiangpin g Bu et. al., A Reinforcement Learnin g Approach to OnlineWeb System Auto configuration . In ICDCS,2009
work page 2009
-
[34]
Hiroyuki Usui et. al., DASH: Deadline Aware Hi gh Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators . In ACM Transact ions on Architecture and Code Optimization 2016
work page 2016
-
[35]
In Journal of Supercomputing Frontiers and Innovations 2014
Onur Mutlu, Lavanya Subramanian Research Probl ems and Opportunities in Memory Systems. In Journal of Supercomputing Frontiers and Innovations 2014
work page 2014
-
[36]
Rachata Ausavarungnirun et. al. High Performan ce and Energy Effi cient Memory Scheduler Design for Heterogeneous Systems. 2018 A UTHORS Eduardo Olmedo Sanchez, graduated from Technical Un iversity of Madrid as an engineer in Automation and Electronics researcher i n topics related to the application of automation to computer engineering a nd computer arc...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.