Code-Aware Combinatorial Interaction Testing
Pith reviewed 2026-05-24 18:25 UTC · model grok-4.3
The pith
Combinatorial testing can weigh parameters by their code impact to detect faults missed when all parameters are treated equally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that incorporating impact measures derived from the internal code structure of the software under test into the combinatorial interaction testing process allows for the generation of test suites that detect new faults compared to the conventional approach where all parameters are treated as having equal impact. This was demonstrated through application to five reliable case studies.
What carries the argument
The code-derived impact measure for each input parameter that reweights its contribution during CIT test generation.
If this is right
- Test generation can prioritize combinations involving high-impact parameters extracted from code.
- The same number of tests can expose faults that the equal-impact method misses.
- CIT can be used as a gray-box rather than purely black-box technique when source code is available.
- The method applies directly to any system whose parameter-to-code mapping can be analyzed statically.
Where Pith is reading between the lines
- Static analysis tools could automate the extraction of impact scores and make the method easier to adopt in continuous integration pipelines.
- The weighting might interact with other test prioritization techniques such as mutation testing or coverage-based ordering.
- If the impact measure proves stable across versions, it could support regression testing by reusing weights from prior releases.
Load-bearing premise
That an accurate and unbiased measure of each parameter's impact can be extracted from the internal code structure.
What would settle it
Executing the weighted and unweighted CIT generators on the same five case studies and finding that the set of faults detected is identical or that any extra faults found by the weighted version disappear when the weighting is removed.
Figures














read the original abstract
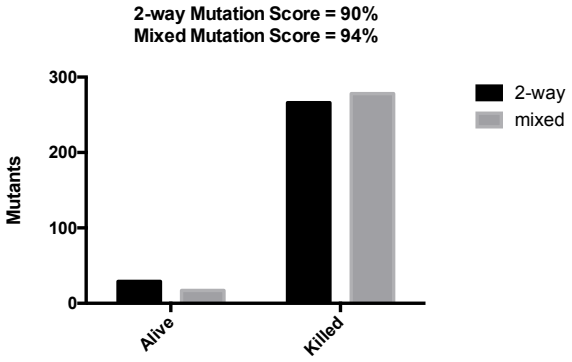
Combinatorial interaction testing (CIT) is a useful testing technique to address the interaction of input parameters in software systems. In many applications, the technique has been used as a systematic sampling technique to sample the enormous possibilities of test cases. In the last decade, most of the research activities focused on the generation of CIT test suites as it is a computationally complex problem. Although promising, less effort has been paid for the application of CIT. In general, to apply the CIT, practitioners must identify the input parameters for the Software-under-test (SUT), feed these parameters to the CIT tool to generate the test suite, and then run those tests on the application with some pass and fail criteria for verification. Using this approach, CIT is used as a black-box testing technique without knowing the effect of the internal code. Although useful, practically, not all the parameters having the same impact on the SUT. This paper introduces a different approach to use the CIT as a gray-box testing technique by considering the internal code structure of the SUT to know the impact of each input parameter and thus use this impact in the test generation stage. We applied our approach to five reliable case studies. The results showed that this approach would help to detect new faults as compared to the equal impact parameter approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a gray-box variant of combinatorial interaction testing (CIT) that extracts an impact score for each input parameter from the internal code structure of the software under test (SUT) and uses these scores to weight the test-suite generation process. It reports that this yields detection of additional faults relative to conventional equal-impact CIT on five case studies.
Significance. A validated, reproducible method for deriving unbiased parameter-impact scores from code and demonstrating improved fault detection would strengthen the practical utility of CIT by moving it from purely black-box sampling toward structure-aware prioritization. The five-case-study evaluation provides an initial empirical signal, but the absence of defined extraction procedures and controls prevents any assessment of whether the claimed improvement is generalizable or artifactual.
major comments (3)
- [Abstract] Abstract: the central claim that the code-aware approach 'would help to detect new faults' rests on an empirical comparison whose metrics, baselines, impact-extraction procedure, and case-study characteristics are never stated, rendering the result unevaluable.
- [Methodology] Methodology section (presumably §3–4): no algorithm, static-analysis rule, dependency metric, or weighting formula is supplied for converting internal code structure into per-parameter impact values; without this definition the gray-box claim cannot be reproduced or falsified.
- [Evaluation] Evaluation section: the five case studies are labeled 'reliable' but supply no information on diversity of domains, ground-truth fault locations, independence of the studies, or controls that would rule out selection bias when low-impact parameters receive fewer tests.
minor comments (2)
- [Abstract] Abstract: the phrase 'equal impact parameter approach' is used without prior definition; it should be explicitly equated to standard CIT.
- [Introduction] Introduction: the related-work discussion is limited; standard CIT generation algorithms and any prior gray-box or code-aware testing papers should be cited for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript lacks sufficient detail for evaluation and reproducibility. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our code-aware CIT approach.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the code-aware approach 'would help to detect new faults' rests on an empirical comparison whose metrics, baselines, impact-extraction procedure, and case-study characteristics are never stated, rendering the result unevaluable.
Authors: We agree the abstract is overly concise and omits key evaluation details. In revision, we will expand it to state the metrics (additional fault detection via mutation analysis), baseline (standard CIT with uniform parameter weights), impact-extraction procedure (static analysis of data/control dependencies), and case-study overview (five open-source systems). This will make the central claim directly evaluable while preserving the abstract's brevity. revision: yes
-
Referee: [Methodology] Methodology section (presumably §3–4): no algorithm, static-analysis rule, dependency metric, or weighting formula is supplied for converting internal code structure into per-parameter impact values; without this definition the gray-box claim cannot be reproduced or falsified.
Authors: The current manuscript describes the gray-box approach at a conceptual level but does not provide the explicit algorithm or formulas. We will add a new subsection detailing the static-analysis rules (e.g., dependency traversal from parameters to statements), the dependency metric (count of affected code elements), and the weighting formula (normalized impact scores fed into the CIT generator). This will enable reproduction. revision: yes
-
Referee: [Evaluation] Evaluation section: the five case studies are labeled 'reliable' but supply no information on diversity of domains, ground-truth fault locations, independence of the studies, or controls that would rule out selection bias when low-impact parameters receive fewer tests.
Authors: We will expand the evaluation section with the requested information: case studies span web, embedded, and library domains from distinct open-source projects (ensuring independence); ground-truth faults are introduced via standard mutation operators; and controls include comparison against random and uniform weighting to address potential bias from uneven test allocation to low-impact parameters. revision: yes
Circularity Check
No circularity; empirical comparison with no fitted predictions or self-referential derivations
full rationale
The paper introduces a gray-box CIT approach that considers internal code structure to assign parameter impacts and applies it empirically to five case studies, claiming improved fault detection over equal-impact baselines. No equations, parameter-fitting steps, predictions that reduce to inputs by construction, or load-bearing self-citations appear in the text. The central claim is an empirical observation rather than a derivation that collapses to its own definitions or prior author results. This is a standard non-circular empirical presentation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Kuhn, R. Kacker, Y. Lei, J. Hunter, Combinatorial software testing, Computer 42 (2009) 94–96
work page 2009
-
[2]
C. Yilmaz, Test case-aware combinatorial interaction testing, IEEE Transactions on Software Engineering 39 (2013) 684–706
work page 2013
-
[3]
R. Tzoref-Brill, Chapter two - advances in combinatorial testing, volume 112 of Advances in Computers, Elsevier, 2019, pp. 79 – 134
work page 2019
-
[4]
D. E. Simos, J. Zivanovic, M. Leithner, Automated combinatorial test- ing for detecting sql vulnerabilities in web applications, in: Proceedings of the 14th International Workshop on Automation of Software Test, AST ’19, IEEE Press, Piscataway, NJ, USA, 2019, pp. 55–61
work page 2019
-
[5]
B. S. Ahmed, T. S. Abdulsamad, M. Y. Potrus, Achievement of min- imized combinatorial test suite for configuration-aware software func- tional testing using the cuckoo search algorithm, Information and Soft- ware Technology 66 (2015) 13–29
work page 2015
-
[6]
A. Hartman, Software and Hardware Testing Using Combinatorial Cov- ering Suites, Springer US, Boston, MA, pp. 237–266
-
[7]
B. S. Ahmed, K. Z. Zamli, A variable strength interaction test suites generation strategy using particle swarm optimization, Journal of Sys- tems and Software 84 (2011) 2171–2185
work page 2011
-
[8]
A. B. Nasser, K. Z. Zamli, A. A. Alsewari, B. S. Ahmed, An elitist-flower pollination-based strategy for constructing sequence and sequence-less 26 t-way test suite, International Journal of Bio-Inspired Computation 12 (2018) 115–127
work page 2018
-
[9]
C. J. Colbourn, V. R. Syrotiuk, On a combinatorial framework for fault characterization, Mathematics in Computer Science 12 (2018) 429–451
work page 2018
-
[10]
B. S. Ahmed, A. Pahim, C. R. R. Junior, D. R. Kuhn, M. Bures, Towards an automated unified framework to run applications for combinatorial interaction testing, in: Proceedings of the Evaluation and Assessment on Software Engineering, EASE ’19, ACM, New York, NY, USA, 2019, pp. 252–258
work page 2019
-
[11]
X. Yuan, M. B. Cohen, A. M. Memon, Gui interaction testing: Incor- porating event context, IEEE Transactions on Software Engineering 37 (2011) 559–574
work page 2011
- [12]
-
[13]
J. Tao, Y. Li, F. Wotawa, H. Felbinger, M. Nica, On the industrial ap- plication of combinatorial testing for autonomous driving functions, in: 2019 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), IEEE Computer Society Press, 2019, pp. 234–240
work page 2019
-
[14]
D. R. Kuhn, R. N. Kacker, Y. Lei, Introduction to Combinatorial Test- ing, Chapman & Hall/CRC, 1st edition, 2013
work page 2013
-
[15]
B. S. Ahmed, K. Z. Zamli, W. Afzal, M. Bures, Constrained interaction testing: A systematic literature study, IEEE Access 5 (2017) 25706– 25730
work page 2017
-
[16]
C. Nie, H. Leung, A survey of combinatorial testing, ACM Computing surveys 43 (2011) 11:1–11:29
work page 2011
-
[17]
S. Y. Borodai, I. S. Grunskii, Recursive generation of locally complete tests, Cybernetics and Systems Analysis 28 (1992) 504–508. 27
work page 1992
-
[18]
U. S. Schubert, Experimental design for combinatorial and high through- put materials development. edited by james n. cawse., Angewandte Chemie International Edition 43 (2004) 4123–4123
work page 2004
-
[19]
D. R. Sulaiman, B. S. Ahmed, Using the combinatorial optimization approach for dvs in high performance processors, in: 2013 The Interna- tional Conference on Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), IEEE Computer Society Press, 2013, pp. 105–109
work page 2013
-
[20]
B. S. Ahmed, M. A. Sahib, L. M. Gambardella, W. Afzal, K. Z. Zamli, Optimum design of pid controller for an automatic voltage regulator system using combinatorial test design, PLOS ONE 11 (2016) 1–20
work page 2016
-
[21]
D. E. Shasha, A. Y. Kouranov, L. V. Lejay, M. F. Chou, G. M. Coruzzi, Using combinatorial design to study regulation by multiple input signals. a tool for parsimony in the post-genomics era, Plant Physiology 127 (2001) 1590–1594
work page 2001
-
[22]
D. C. Deacon, C. L. Happe, C. Chen, N. Tedeschi, A. M. Manso, T. Li, N. D. Dalton, Q. Peng, E. N. Farah, Y. Gu, K. P. Tenerelli, V. D. Tran, J. Chen, K. L. Peterson, N. J. Schork, E. D. Adler, A. J. Engler, R. S. Ross, N. C. Chi, Combinatorial interactions of genetic variants in human cardiomyopathy, Nature Biomedical Engineering 3 (2019) 147–157
work page 2019
-
[23]
G. Demiroz, C. Yilmaz, Using simulated annealing for computing cost- aware covering arrays, Applied Soft Computing 49 (2016) 1129–1144
work page 2016
-
[24]
J. Shi, M. B. Cohen, M. B. Dwyer, Integration testing of software prod- uct lines using compositional symbolic execution, in: Proceedings of the 15th International Conference on Fundamental Approaches to Soft- ware Engineering, FASE’12, Springer-Verlag, Berlin, Heidelberg, 2012, pp. 270–284. 28
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.