Hessian based analysis of SGD for Deep Nets: Dynamics and Generalization
Pith reviewed 2026-05-24 16:40 UTC · model grok-4.3
The pith
The Hessian of the training loss characterizes SGD dynamics through gradient moments and yields a scale-invariant generalization bound for deep nets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that the Hessian of the training loss is linked to the second moment of stochastic gradients, which in turn governs the stochastic dynamics of SGD for fixed and adaptive step sizes with diagonal preconditioning. They further derive a generalization bound expressed in terms of the Hessian that is invariant to scaling of the network parameters, supported by experiments on synthetic data, MNIST, and CIFAR-10 across varying batch sizes and label noise levels.
What carries the argument
The Hessian matrix of the training loss, which connects loss curvature to the second moment of stochastic gradients and supplies the basis for a scale-invariant bound.
If this is right
- SGD with fixed step sizes follows dynamics determined by the first and second moments of stochastic gradients.
- Adaptive step sizes and diagonal preconditioning admit analogous characterizations using the same moments.
- A generalization bound for deep nets can be stated directly from the Hessian in a form that remains unchanged under parameter scaling.
- Empirical verification on MNIST and CIFAR-10 across batch sizes and label noise supports the characterizations.
Where Pith is reading between the lines
- Step-size schedules could be chosen by tracking the evolving Hessian during training rather than by cross-validation alone.
- The same Hessian-moment link might be used to compare the trajectories of other first-order methods such as momentum variants.
- If the bound holds, it supplies a practical diagnostic for when overparameterized models are likely to generalize without explicit regularization terms.
Load-bearing premise
Quantities derived from the Hessian of the training loss alone are sufficient to characterize both the SGD dynamics and a scale-invariant generalization bound without further unstated assumptions on the loss landscape or data distribution.
What would settle it
An experiment on MNIST or CIFAR-10 in which the observed SGD trajectories with fixed or adaptive steps deviate measurably from the paths predicted by the first and second moments of the gradients relative to the computed Hessian, or in which test error violates the proposed Hessian-based bound.
Figures













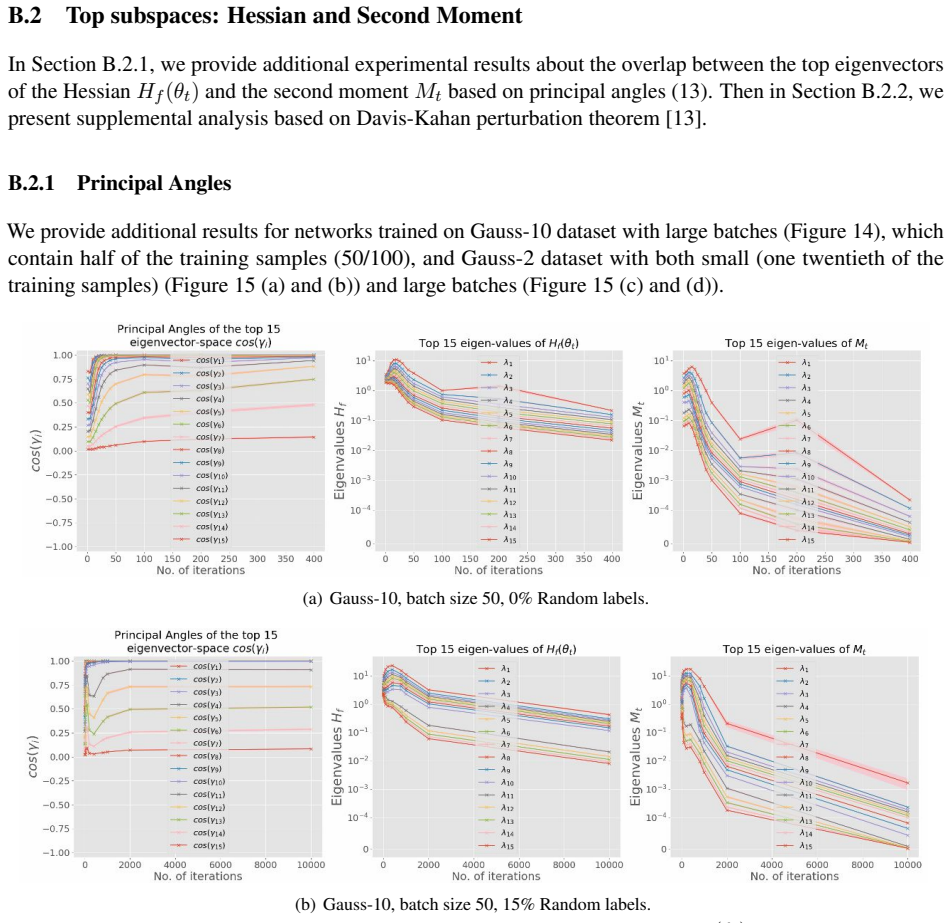

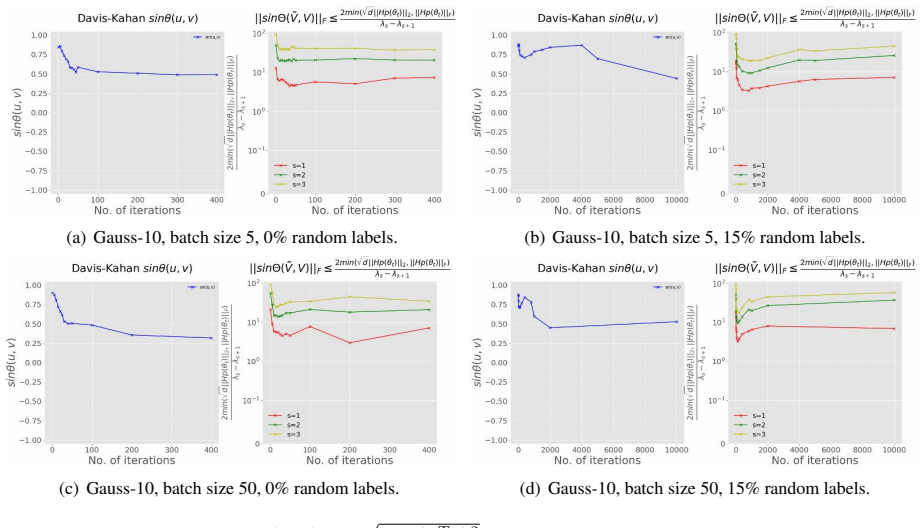


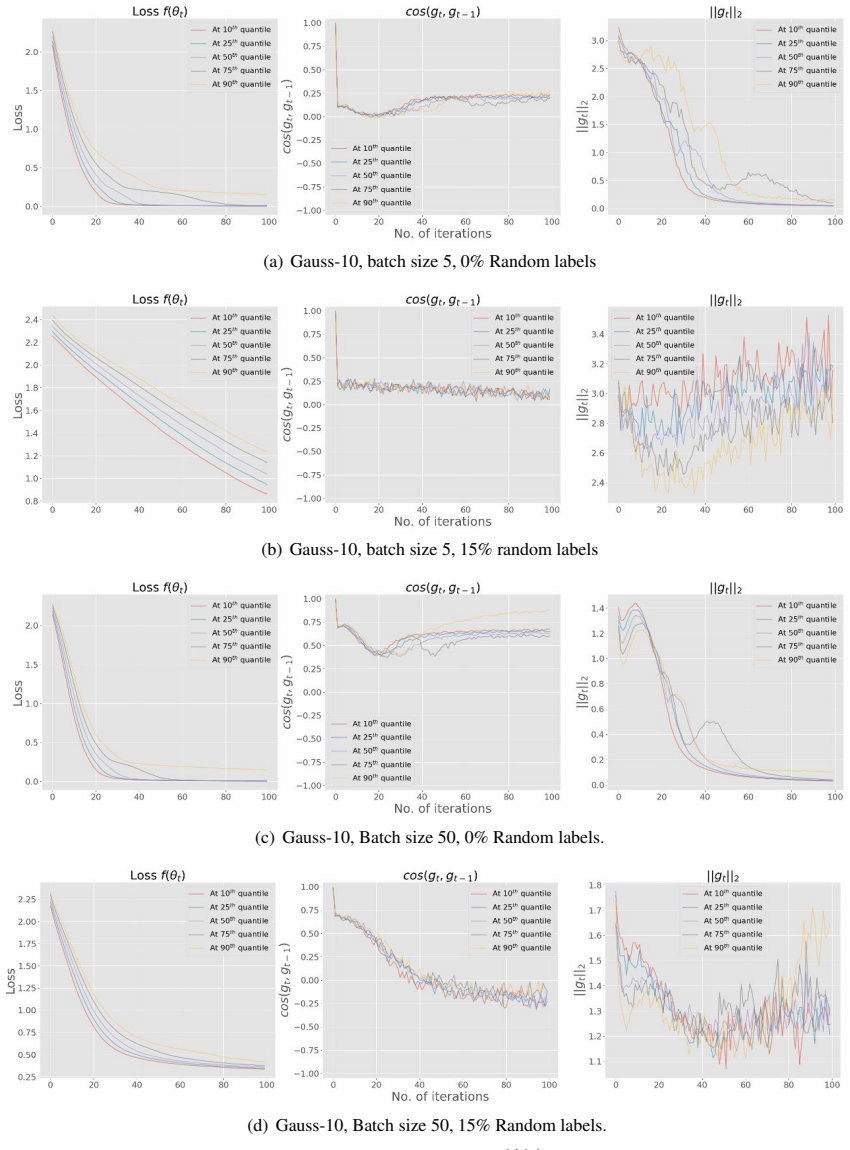




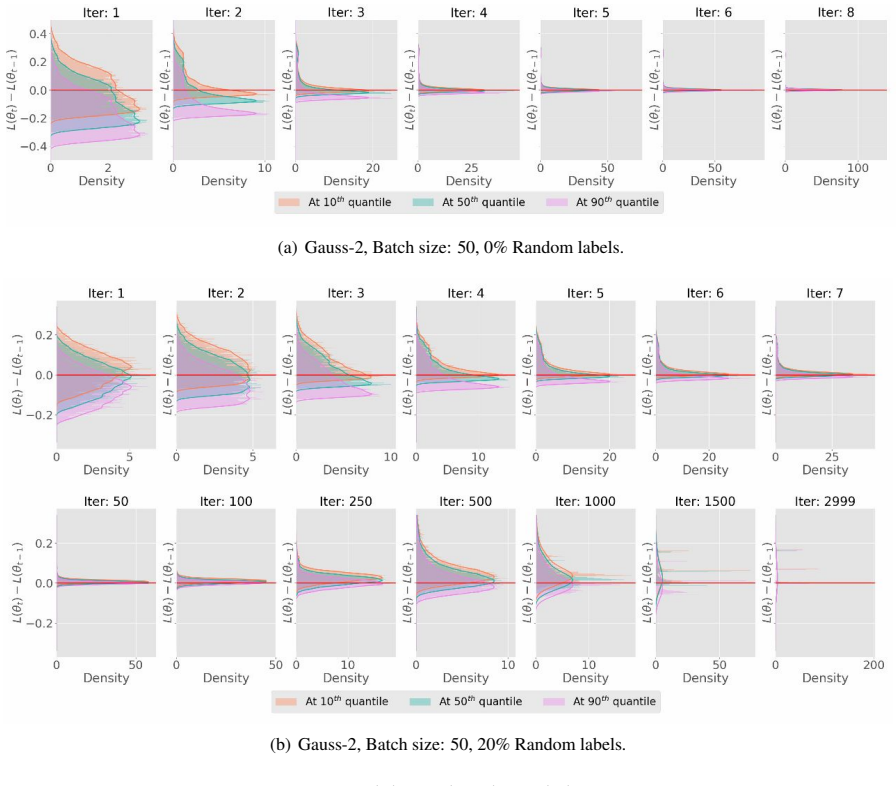
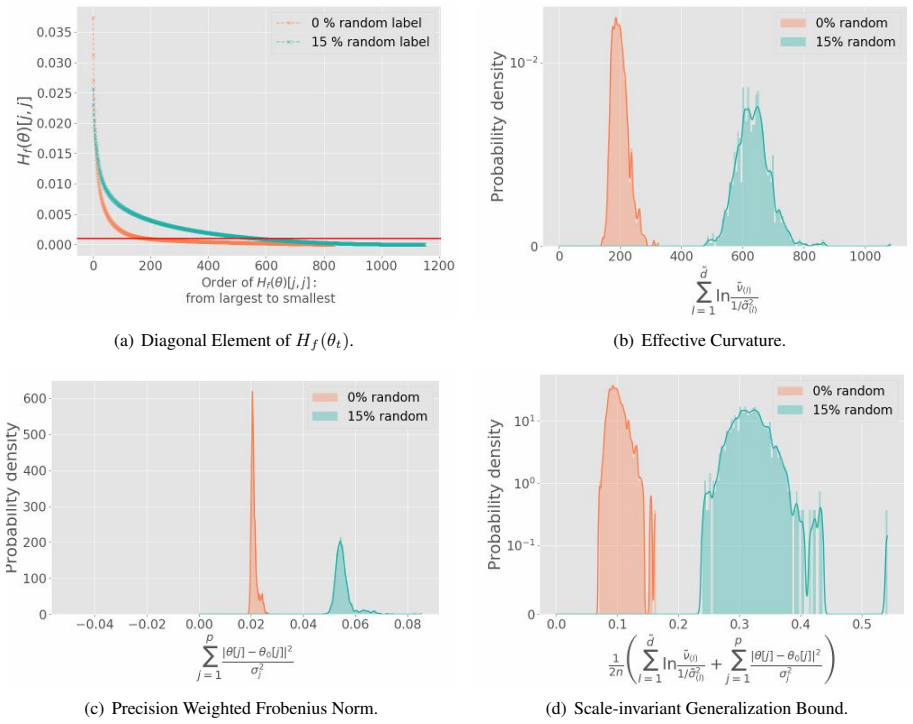
read the original abstract
While stochastic gradient descent (SGD) and variants have been surprisingly successful for training deep nets, several aspects of the optimization dynamics and generalization are still not well understood. In this paper, we present new empirical observations and theoretical results on both the optimization dynamics and generalization behavior of SGD for deep nets based on the Hessian of the training loss and associated quantities. We consider three specific research questions: (1) what is the relationship between the Hessian of the loss and the second moment of stochastic gradients (SGs)? (2) how can we characterize the stochastic optimization dynamics of SGD with fixed and adaptive step sizes and diagonal pre-conditioning based on the first and second moments of SGs? and (3) how can we characterize a scale-invariant generalization bound of deep nets based on the Hessian of the loss, which by itself is not scale invariant? We shed light on these three questions using theoretical results supported by extensive empirical observations, with experiments on synthetic data, MNIST, and CIFAR-10, with different batch sizes, and with different difficulty levels by synthetically adding random labels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to characterize (1) the relationship between the Hessian of the training loss and the second moment of stochastic gradients, (2) the stochastic dynamics of SGD (fixed and adaptive step sizes, diagonal preconditioning) in terms of first and second moments of stochastic gradients, and (3) a scale-invariant generalization bound for deep nets derived from the Hessian (which itself is not scale-invariant), supported by theory and experiments on synthetic data, MNIST, and CIFAR-10 with varying batch sizes and label noise.
Significance. If the derivations hold without hidden assumptions on loss homogeneity or gradient covariance, the work would supply concrete links between Hessian quantities and both optimization trajectories and generalization, with the scale-invariant bound being a potentially useful contribution; the experiments across difficulty levels provide some empirical grounding.
major comments (2)
- [Generalization bound section (near Eq. for the bound)] The scale-invariant generalization bound (research question 3) is presented as based on the Hessian, yet the construction appears to require the loss to be approximately homogeneous of degree 2 or explicit per-layer normalization; neither holds in general for ReLU networks with batch-norm and cross-entropy. This assumption is load-bearing for the central claim and must be stated explicitly with a concrete test (e.g., homogeneity check on the trained models).
- [Dynamics characterization (Eqs. relating moments to Hessian)] The dynamics characterization (research question 2) replaces the stochastic gradient covariance with the Hessian; the paper must quantify the remainder term and show it does not grow with depth or batch size, as this replacement is central to both the fixed-step and adaptive-step analyses.
minor comments (2)
- Clarify the precise definition of 'diagonal pre-conditioning' and how the first and second moments are estimated in the adaptive case.
- [Experimental section] The experiments on synthetic data should include a direct comparison of the proposed bound against existing scale-invariant bounds (e.g., those based on weight norms) to demonstrate improvement.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. Below we respond point-by-point to the two major comments, indicating the revisions we will make.
read point-by-point responses
-
Referee: [Generalization bound section (near Eq. for the bound)] The scale-invariant generalization bound (research question 3) is presented as based on the Hessian, yet the construction appears to require the loss to be approximately homogeneous of degree 2 or explicit per-layer normalization; neither holds in general for ReLU networks with batch-norm and cross-entropy. This assumption is load-bearing for the central claim and must be stated explicitly with a concrete test (e.g., homogeneity check on the trained models).
Authors: We agree that the scale-invariant bound derivation relies on the training loss behaving approximately homogeneously of degree 2, which arises from the combination of batch normalization (which normalizes scale per layer) and the positive homogeneity of ReLU activations. This property does not hold for arbitrary networks but is a reasonable approximation for the standard architectures and training regimes examined in the paper. In the revision we will (i) explicitly state the homogeneity assumption in the generalization section and (ii) add a concrete numerical verification: for each trained model we will report the empirical degree by evaluating L(c·θ) / L(θ) for several scalars c near 1 and confirm that the ratio is close to c². These checks will be performed on the MNIST and CIFAR-10 models already present in the experiments. revision: yes
-
Referee: [Dynamics characterization (Eqs. relating moments to Hessian)] The dynamics characterization (research question 2) replaces the stochastic gradient covariance with the Hessian; the paper must quantify the remainder term and show it does not grow with depth or batch size, as this replacement is central to both the fixed-step and adaptive-step analyses.
Authors: The substitution of the stochastic-gradient second-moment matrix by the Hessian follows from the standard Gauss-Newton / Fisher approximation that becomes exact when the model predictions match the labels (or in the large-batch limit). We acknowledge that a rigorous bound on the remainder is desirable. In the revised manuscript we will add (i) an explicit expression for the remainder term involving third- and fourth-order derivatives and (ii) both theoretical scaling arguments and empirical measurements (on the same synthetic, MNIST, and CIFAR-10 networks) demonstrating that the relative size of the remainder stays bounded and does not increase materially with depth or batch size within the regimes studied. These additions will be placed immediately after the dynamics equations. revision: yes
Circularity Check
No significant circularity in derivation chain.
full rationale
The paper's abstract and described claims present three research questions on relationships between Hessian and stochastic gradient moments, SGD dynamics characterization, and a scale-invariant generalization bound. These are addressed via theoretical results supported by empirical observations on synthetic data, MNIST, and CIFAR-10. No quoted equations or steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the characterizations are framed as independent derivations from first/second moments and Hessian quantities, with no load-bearing self-citations or ansatzes smuggled in. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On the Convergence Rate of Training Recurrent Neural Networks
Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. On the convergence rate of training recurrent neural networks. arXiv:1810.12065, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Methods of Information Geometry, volume 191
Shun-ichi Amari and Hiroshi Nagaoka. Methods of Information Geometry, volume 191. 01 2000
work page 2000
-
[3]
A convergence analysis of gradient descent for deep linear neural networks
Sanjeev Arora, Nadav Cohen, Noah Golowich, and Wei Hu. A convergence analysis of gradient descent for deep linear neural networks. In ICLR, 2019
work page 2019
-
[4]
On the Optimization of Deep Networks: Implicit Acceleration by Overparameterization
Sanjeev Arora, Nadav Cohen, and Elad Hazan. On the optimization of deep networks: Implicit acceleration by overparameterization. arXiv:1802.06509, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Spectrally-normalized margin bounds for neural networks
Peter L Bartlett, Dylan J Foster, and Matus J Telgarsky. Spectrally-normalized margin bounds for neural networks. In NIPS, 2017
work page 2017
- [6]
-
[7]
Concentration inequalities: A nonasymptotic theory of independence
St´ephane Boucheron, G´abor Lugosi, and Pascal Massart. Concentration inequalities: A nonasymptotic theory of independence. Oxford university press, 2013
work page 2013
-
[8]
SGD learns over- parameterized networks that provably generalize on linearly separable data
Alon Brutzkus, Amir Globerson, Eran Malach, and Shai Shalev-Shwartz. SGD learns over- parameterized networks that provably generalize on linearly separable data. In ICLR, 2018
work page 2018
-
[9]
G. Casella and R.L. Berger. Statistical Inference. Duxbury advanced series. Brooks/Cole Publishing Company, 1990
work page 1990
-
[10]
Entropy-SGD: Biasing Gradient Descent Into Wide Valleys
Pratik Chaudhari, Anna Choromanska, Stefano Soatto, Yann LeCun, Carlo Baldassi, Christian Borgs, Jennifer Chayes, Levent Sagun, and Riccardo Zecchina. Entropy-sgd: Biasing gradient descent into wide valleys. arXiv:1611.01838, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Pratik Chaudhari and Stefano Soatto. Stochastic gradient descent performs variational inference, converges to limit cycles for deep networks. In ICLR, 2018
work page 2018
-
[12]
Thomas M. Cover and Joy A. Thomas. Elements of Information Theory (Wiley Series in Telecommuni- cations and Signal Processing). Wiley-Interscience, New York, NY , USA, 2006
work page 2006
-
[13]
C. Davis and W. Kahan. The rotation of eigenvectors by a perturbation. iii. SIAM Journal on Numerical Analysis, 7(1):1–46, 1970
work page 1970
-
[14]
Sharp Minima Can Generalize For Deep Nets
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp minima can generalize for deep nets. arXiv:1703.04933, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
Gradient descent finds global minima of deep neural networks
Simon S Du, Jason D Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In ICML, 2019. 27
work page 2019
-
[16]
Simon S. Du, Jason D. Lee, Yuandong Tian, Barnab´as P´oczos, and Aarti Singh. Gradient descent learns one-hidden-layer CNN: Don’t be afraid of spurious local minima. In ICML, pages 1339–1348. PMLR, 10–15 Jul 2018
work page 2018
-
[17]
Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh
Simon S. Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. In ICLR, 2019
work page 2019
-
[18]
An overview on the evolution and adoption of deep learning applications used in the industry
Sourav Dutta. An overview on the evolution and adoption of deep learning applications used in the industry. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 8(4):e1257, 2018
work page 2018
-
[19]
S. Ghadimi and G. Lan. Stochastic first- and zeroth-order methods for nonconvex stochastic program- ming. SIAM Journal on Optimization, 23(4):2341–2368, 2013
work page 2013
-
[20]
An Investigation into Neural Net Optimization via Hessian Eigenvalue Density
Behrooz Ghorbani, Shankar Krishnan, and Ying Xiao. An investigation into neural net optimization via hessian eigenvalue density. arXiv preprint arXiv:1901.10159, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[21]
Gene H. Golub and Charles F. van Loan. Matrix Computations. JHU Press, fourth edition, 2013
work page 2013
-
[22]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http: //www.deeplearningbook.org
work page 2016
-
[23]
Gradient Descent Happens in a Tiny Subspace
Guy Gur-Ari, Daniel A Roberts, and Ethan Dyer. Gradient descent happens in a tiny subspace. arXiv preprint arXiv:1812.04754, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [24]
-
[25]
Sepp Hochreiter and J ¨urgen Schmidhuber. Flat minima. Neural Computation, 9(1):1–42, 1997
work page 1997
-
[26]
A tail inequality for quadratic forms of subgaussian random vectors
Daniel Hsu, Sham Kakade, and Tong Zhang. A tail inequality for quadratic forms of subgaussian random vectors. Electronic Communications in Probability, 17:6 pp., 2012
work page 2012
-
[27]
Jean Jacod and Philip Protter. Probability essentials. Springer Science & Business Media, 2012
work page 2012
-
[28]
Stanislaw Jastrzebski, Zachary Kenton, Devansh Arpit, Nicolas Ballas, Asja Fischer, Yoshua Bengio, and Amos J. Storkey. Three factors influencing minima in SGD. In ICANN, 2018
work page 2018
- [29]
-
[30]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. In ICLR, 2017
work page 2017
-
[31]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015
work page 2015
-
[32]
Information theory and dynamical system predictability
Richard Kleeman. Information theory and dynamical system predictability. Entropy, 13(3):612–649, 2011
work page 2011
-
[33]
Learning Multiple Layers of Features from Tiny Images
Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images. Technical Report V ol. 1. No. 4., University of Toronto, 2009
work page 2009
-
[34]
Cornelius Lanczos. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. J. Res. Natl. Bur. Stand. B, 45:255–282, 1950. 28
work page 1950
-
[35]
John Langford and John Shawe-Taylor. Pac-bayes & margins. In NIPS, 2003
work page 2003
-
[36]
Brownian Motion, Martingales, and Stochastic Calculus, volume 274
Jean-Francois Le Gall. Brownian Motion, Martingales, and Stochastic Calculus, volume 274. Springer, 01 2016
work page 2016
-
[37]
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521:436 EP –, 05 2015
work page 2015
-
[38]
Gradient-based learning applied to document recognition
Yann LeCun, L´eon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324, 1998
work page 1998
-
[39]
Probability in Banach Spaces: isoperimetry and processes
Michel Ledoux and Michel Talagrand. Probability in Banach Spaces: isoperimetry and processes . Springer, Berlin, May 1991
work page 1991
-
[40]
E.L. Lehmann and G. Casella. Theory of Point Estimation. Springer Verlag, 1998
work page 1998
-
[41]
Learning overparameterized neural networks via stochastic gradient descent on structured data
Yuanzhi Li and Yingyu Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. In NIPS, 2018
work page 2018
-
[42]
Siyuan Ma, Raef Bassily, and Mikhail Belkin. The power of interpolation: Understanding the effective- ness of sgd in modern over-parametrized learning. arXiv:1712.06559, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Dougal Maclaurin, David Duvenaud, and Ryan P. Adams. Autograd: Effortless gradients in numpy. In ICML AutoML Workshop, 2015
work page 2015
-
[44]
Stephan Mandt, Matthew D. Hoffman, and David M. Blei. Stochastic gradient descent as approximate bayesian inference. JMLR, 18(1):4873–4907, January 2017
work page 2017
-
[45]
New insights and perspectives on the natural gradient method
James Martens. New insights and perspectives on the natural gradient method. arXiv:1412.1193, Dec 2014
-
[46]
David A McAllester. Pac-bayesian model averaging. In COLT. ACM, 1999
work page 1999
-
[47]
Estimating structured vector autoregressive models
Igor Melnyk and Arindam Banerjee. Estimating structured vector autoregressive models. In Interna- tional Conference on Machine Learning, pages 830–839, 2016
work page 2016
-
[48]
Recent Advances in Deep Learning: An Overview
Matiur Rahman Minar and Jibon Naher. Recent advances in deep learning: An overview. arXiv:1807.08169, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[49]
Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience
Vaishnavh Nagarajan and Zico Kolter. Deterministic PAC-bayesian generalization bounds for deep networks via generalizing noise-resilience. In ICLR, 2019
work page 2019
-
[50]
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro. Robust stochastic approximation approach to stochastic programming. SIAM Journal on Optimization, 19(4):1574–1609, 2009
work page 2009
-
[51]
A PAC-Bayesian Approach to Spectrally-Normalized Margin Bounds for Neural Networks
Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nathan Srebro. A pac-bayesian approach to spectrally-normalized margin bounds for neural networks. arXiv:1707.09564, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
Exploring generalization in deep learning
Behnam Neyshabur, Srinadh Bhojanapalli, David Mcallester, and Nati Srebro. Exploring generalization in deep learning. In NIPS, 2017
work page 2017
-
[53]
The Full Spectrum of Deepnet Hessians at Scale: Dynamics with SGD Training and Sample Size
Vardan Papyan. The full spectrum of deep net hessians at scale: Dynamics with sample size. arXiv preprint arXiv:1811.07062, 2018. 29
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[54]
Vardan Papyan. Measurements of three-level hierarchical structure in the outliers in the spectrum of deepnet hessians. arXiv preprint arXiv:1901.08244, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[55]
Barak A. Pearlmutter. Fast exact multiplication by the hessian. Neural Comput., 6(1):147–160, January 1994
work page 1994
-
[56]
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duches- nay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[57]
A Scale Invariant Flatness Measure for Deep Network Minima
Akshay Rangamani, Nam H Nguyen, Abhishek Kumar, Dzung Phan, Sang H Chin, and Trac D Tran. A scale invariant flatness measure for deep network minima. arXiv preprint arXiv:1902.02434, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[58]
C. Radhakrishna Rao. Information and the accuracy attainable in the estimation of statistical parameters. . Bulletin of the Calcutta Mathematical Society, pages 81–89, 1945
work page 1945
-
[59]
Reddi, Satyen Kale, and Sanjiv Kumar
Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. In ICLR, 2018
work page 2018
-
[60]
A stochastic approximation method
Herbert Robbins and Sutton Monro. A stochastic approximation method. Ann. Math. Statist., 22(3):400– 407, 09 1951
work page 1951
-
[61]
Principles of mathematical analysis
Walter Rudin. Principles of mathematical analysis. McGraw-Hill Book Co., New York, third edition,
-
[62]
International Series in Pure and Applied Mathematics
-
[63]
Spurious local minima are common in two-layer relu neural networks
Itay Safran and Ohad Shamir. Spurious local minima are common in two-layer relu neural networks. In ICML, 2018
work page 2018
-
[64]
Eigenvalues of the Hessian in Deep Learning: Singularity and Beyond
Levent Sagun, Leon Bottou, and Yann LeCun. Eigenvalues of the hessian in deep learning: Singularity and beyond. arXiv:1611.07476, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[65]
Empirical Analysis of the Hessian of Over-Parametrized Neural Networks
Levent Sagun, Utku Evci, V . Ugur G¨uney, Yann Dauphin, and L´eon Bottou. Empirical analysis of the hessian of over-parametrized neural networks. arXiv:1706.04454, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[66]
Introduction to the gamma function
Pascal Sebah and Xavier Gourdon. Introduction to the gamma function. 2002
work page 2002
-
[67]
Exponential Convergence Time of Gradient Descent for One-Dimensional Deep Linear Neural Networks
Ohad Shamir. Exponential convergence time of gradient descent for one-dimensional deep linear neural networks. arXiv:1809.08587, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[68]
Samuel L. Smith and Quoc V . Le. A bayesian perspective on generalization and stochastic gradient descent. In ICLR, 2018
work page 2018
-
[69]
Escaping saddle points with adaptive gradient methods
Matthew Staib, Sashank Reddi, Satyen Kale, Sanjiv Kumar, and Suvrit Sra. Escaping saddle points with adaptive gradient methods. In ICML, pages 5956–5965, 2019
work page 2019
-
[70]
Yusuke Tsuzuku, Issei Sato, and Masashi Sugiyama. Normalized flat minima: Exploring scale in- variant definition of flat minima for neural networks using pac-bayesian analysis. arXiv preprint arXiv:1901.04653, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[71]
Local smoothness in variance reduced optimization
Daniel Vainsencher, Han Liu, and Tong Zhang. Local smoothness in variance reduced optimization. In Advances in Neural Information Processing Systems 28, pages 2179–2187, 2015. 30
work page 2015
-
[72]
Rocio Vargas, Amir Mosavi, and Ramon Ruiz. Deep learning: A review. Advances in Intelligent Systems and Computing, 5, 08 2017
work page 2017
-
[73]
Introduction to the non-asymptotic analysis of random matrices
Roman Vershynin. Introduction to the non-asymptotic analysis of random matrices . Cambridge University Press, 2012
work page 2012
-
[74]
High-dimensional probability: An introduction with applications in data science, volume 47
Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge University Press, 2018
work page 2018
-
[75]
All of Statistics: A Concise Course in Statistical Inference
Larry Wasserman. All of Statistics: A Concise Course in Statistical Inference . Springer Publishing Company, Incorporated, 2010
work page 2010
-
[76]
David Williams. Probability with martingales. Cambridge university press, 1991
work page 1991
-
[77]
Chen Xing, Devansh Arpit, Christos Tsirigotis, and Y Bengio. A walk with sgd. arXiv:1802.08770, 02 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[78]
Positively Scale-Invariant Flatness of ReLU Neural Networks
Mingyang Yi, Qi Meng, Wei Chen, Zhi-ming Ma, and Tie-Yan Liu. Positively scale-invariant flatness of relu neural networks. arXiv preprint arXiv:1903.02237, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[79]
Y . Yu, T. Wang, and R. J. Samworth. A useful variant of the davis–kahan theorem for statisticians. Biometrika, 102(2):315–323, apr 2015
work page 2015
-
[80]
Small nonlinearities in activation functions create bad local minima in neural networks
Chulhee Yun, Suvrit Sra, and Ali Jadbabaie. Small nonlinearities in activation functions create bad local minima in neural networks. arXiv:1802.03487, February 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.