Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking
Pith reviewed 2026-05-24 16:42 UTC · model grok-4.3
The pith
Self-supervised adaptation lets high-fidelity face models track performance from cellphone videos without any new labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
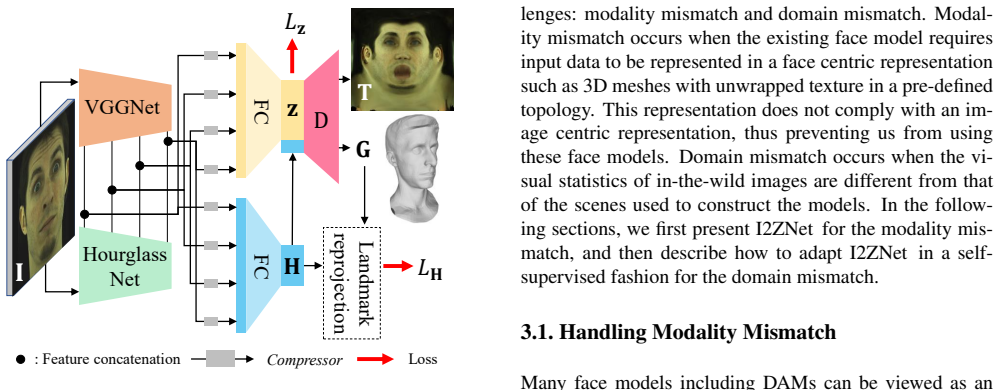
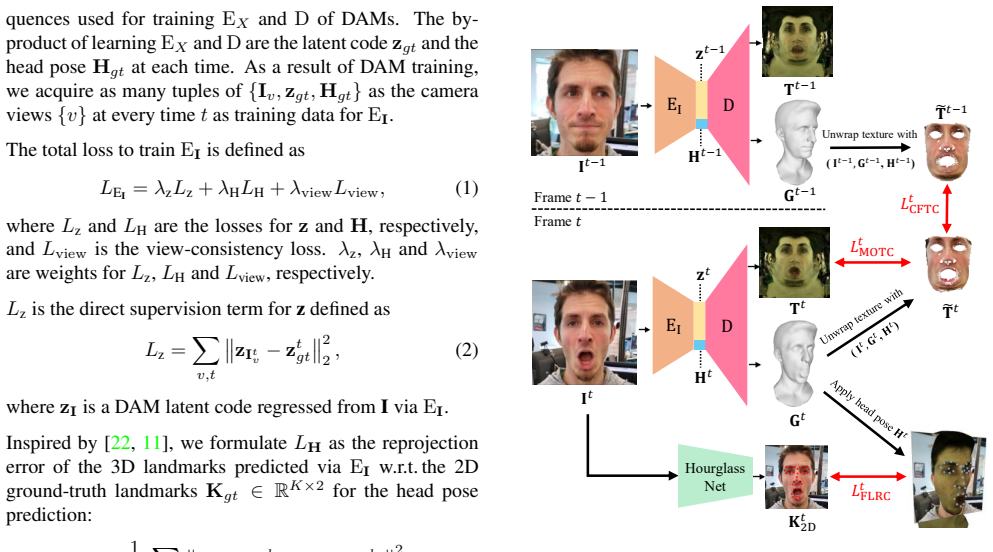
The central claim is that a network can be trained to drive a high-fidelity face model from single 2D images, after which self-supervised domain adaptation via consecutive frame texture consistency transfers the model to uncontrolled environments without labeled data from the new domain.
What carries the argument
Consecutive frame texture consistency, a self-supervised constraint that assumes constant face appearance across adjacent frames and uses that to adapt the driving network.
If this is right
- High-fidelity models become usable with standard 2D image input instead of meshes or unwrapped textures.
- No explicit modeling of the target environment is required for domain transfer.
- Complex facial motions can be captured from commodity cameras without domain-specific labels.
- The adaptation step works on unlabeled video sequences from the new setting.
Where Pith is reading between the lines
- The same consistency signal could support adaptation for other time-varying tracking problems where appearance is stable over short intervals.
- Mobile real-time performance capture becomes practical once the network is adapted.
- The method may extend to objects other than faces if a comparable temporal consistency cue exists.
Load-bearing premise
The face's appearance stays consistent from one frame to the next even when the camera, lighting, or background changes.
What would settle it
A video sequence in which face texture visibly changes between consecutive frames due to lighting variation or motion would produce tracking errors after adaptation.
Figures



read the original abstract
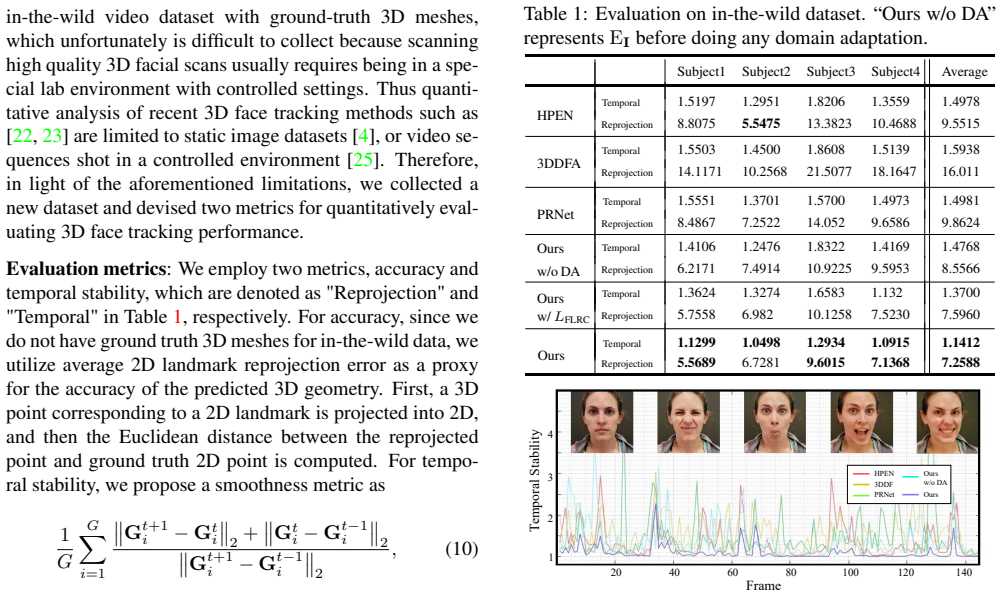
Improvements in data-capture and face modeling techniques have enabled us to create high-fidelity realistic face models. However, driving these realistic face models requires special input data, e.g. 3D meshes and unwrapped textures. Also, these face models expect clean input data taken under controlled lab environments, which is very different from data collected in the wild. All these constraints make it challenging to use the high-fidelity models in tracking for commodity cameras. In this paper, we propose a self-supervised domain adaptation approach to enable the animation of high-fidelity face models from a commodity camera. Our approach first circumvents the requirement for special input data by training a new network that can directly drive a face model just from a single 2D image. Then, we overcome the domain mismatch between lab and uncontrolled environments by performing self-supervised domain adaptation based on "consecutive frame texture consistency" based on the assumption that the appearance of the face is consistent over consecutive frames, avoiding the necessity of modeling the new environment such as lighting or background. Experiments show that we are able to drive a high-fidelity face model to perform complex facial motion from a cellphone camera without requiring any labeled data from the new domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a self-supervised domain adaptation method that first trains a network to drive a high-fidelity face model directly from a single 2D image (bypassing the need for 3D meshes or unwrapped textures) and then adapts the model to uncontrolled cellphone video by enforcing a texture-consistency loss between consecutive frames. The adaptation rests on the assumption that face appearance remains stationary across frames, thereby avoiding explicit modeling of lighting, background, or other environmental factors. Experiments are said to show successful driving of complex facial motion from commodity cameras without any labeled target-domain data.
Significance. If the central claim is substantiated, the work would enable practical deployment of lab-captured high-fidelity face models in everyday monocular settings, which is a meaningful step for performance capture and animation pipelines. The self-supervised formulation that sidesteps new labeled data collection is a clear methodological strength.
major comments (2)
- [Method (domain adaptation subsection)] The domain-adaptation stage (described after the initial network training) defines the self-supervised loss exclusively via consecutive-frame texture consistency. No ablation or sensitivity analysis is provided that tests the loss under the illumination shifts, auto-exposure changes, or small viewpoint variations that routinely occur in cellphone video; because the adaptation step depends directly on this unverified premise, the absence of such validation is load-bearing for the central claim.
- [Experiments] The experiments section asserts that the adapted model successfully drives complex facial motion from cellphone footage, yet reports no quantitative tracking or reconstruction error metrics, no comparison against supervised or lighting-aware baselines, and no failure-case analysis on sequences where the consistency assumption is violated. This leaves the empirical support for the “without requiring any labeled data” claim difficult to evaluate.
minor comments (1)
- [Abstract] The abstract would be strengthened by inclusion of at least one quantitative result (e.g., a tracking error number or comparison) rather than a purely qualitative statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (domain adaptation subsection)] The domain-adaptation stage (described after the initial network training) defines the self-supervised loss exclusively via consecutive-frame texture consistency. No ablation or sensitivity analysis is provided that tests the loss under the illumination shifts, auto-exposure changes, or small viewpoint variations that routinely occur in cellphone video; because the adaptation step depends directly on this unverified premise, the absence of such validation is load-bearing for the central claim.
Authors: We agree that validating the texture consistency assumption under realistic variations strengthens the central claim. In the revised manuscript we will add an ablation study that applies controlled illumination shifts, auto-exposure simulation, and small viewpoint perturbations to consecutive-frame pairs and reports the resulting adaptation quality. This directly tests the load-bearing premise. revision: yes
-
Referee: [Experiments] The experiments section asserts that the adapted model successfully drives complex facial motion from cellphone footage, yet reports no quantitative tracking or reconstruction error metrics, no comparison against supervised or lighting-aware baselines, and no failure-case analysis on sequences where the consistency assumption is violated. This leaves the empirical support for the “without requiring any labeled data” claim difficult to evaluate.
Authors: We acknowledge the lack of quantitative metrics and comparisons. Because the method is deliberately self-supervised, direct reconstruction error on target labels is unavailable by design; however, we will add proxy quantitative evaluations (e.g., landmark reprojection error on held-out frames) together with comparisons against a supervised baseline trained on limited synthetic data and a lighting-augmented variant. We will also include a dedicated failure-case analysis for sequences that violate the consistency assumption (rapid lighting changes, large head motion). These additions will be incorporated in the revision. revision: yes
Circularity Check
No circularity: adaptation uses explicit consistency assumption without reducing to self-definition or fitted inputs.
full rationale
The paper's core method trains a network to drive a face model from single 2D images, then applies self-supervised domain adaptation via a loss enforcing consecutive-frame texture consistency under the stated assumption that face appearance remains stationary across frames. This assumption is declared upfront and is not derived from or equivalent to the method's outputs; the adaptation step is a direct application of the loss rather than a prediction that collapses to fitted parameters or prior self-citations. No equations or steps in the provided text reduce the claimed result to its inputs by construction, and the approach remains falsifiable against external video data where the assumption may fail.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption the appearance of the face is consistent over consecutive frames
Reference graph
Works this paper leans on
-
[1]
A morphable model for the synthesis of 3D faces
V olker Blanz and Thomas Vetter. A morphable model for the synthesis of 3D faces. In Proc. ACM SIG- GRAPH, pages 187–194, 1999. 1, 2
work page 1999
-
[2]
James Booth, Epameinondas Antonakos, Stylianos Ploumpis, George Trigeorgis, and Yannis Panagakis andStefanos Zafeiriou. 3D face morphable models “in-the-wild”. In Proc. CVPR, 2017. 2
work page 2017
-
[3]
Large scale 3D morphable models
James Booth, Anastasios Roussos, Allan Ponniah, David Dunaway, and Stefanos Zafeiriou. Large scale 3D morphable models. IJCV, 126(2-4):233–254,
-
[4]
FaceWarehouse: A 3D facial ex- pression database for visual computing
Chen Cao, Yanlin Weng, Shun Zhou, Yiying Tong, and Kun Zhou. FaceWarehouse: A 3D facial ex- pression database for visual computing. IEEE TVCG, 20(3):413–425, 2014. 2, 6
work page 2014
-
[5]
Timothy F Cootes, Gareth J Edwards, and Christo- pher J Taylor. Active appearance models. IEEE TPAMI, (6):681–685, 2001. 1, 2
work page 2001
-
[6]
Active shape models-their training and application
Timothy F Cootes, Christopher J Taylor, David H Cooper, and Jim Graham. Active shape models-their training and application. CVIU, 61(1):38–59, 1995. 1, 2
work page 1995
-
[7]
ImageNet: A large-scale hierarchi- cal image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchi- cal image database. In Proc. CVPR, 2009. 12
work page 2009
-
[8]
Xuanyi Dong, Shoou-I Yu, Xinshuo Weng, Shih-En Wei, Yi Yang, and Yaser Sheikh. Supervision-by- registration: An unsupervised approach to improve the precision of facial landmark detectors. InProc. CVPR,
-
[9]
Joint 3D face reconstruction and dense align- ment with position map regression network
Yao Feng, Fan Wu, Xiaohu Shao, Yanfeng Wang, and Xi Zhou. Joint 3D face reconstruction and dense align- ment with position map regression network. In Proc. ECCV, 2018. 3, 6
work page 2018
-
[10]
Dense 3D face alignment from 2D video for real-time use
László A Jeni, Jeffrey F Cohn, and Takeo Kanade. Dense 3D face alignment from 2D video for real-time use. Image Vision Comput., 58(C):13–24, 2017. 3
work page 2017
-
[11]
Angjoo Kanazawa, Michael J. Black, David W. Ja- cobs, and Jitendra Malik. End-to-end recovery of hu- man shape and pose. In Proc. CVPR, 2018. 4
work page 2018
-
[12]
Diederik P. Kingma and Max Welling. Auto-encoding variational Bayes. In Proc. ICLR, 2014. 2
work page 2014
-
[13]
Deep appearance models for face ren- dering
Stephen Lombardi, Tomas Simon, Jason Saragih, and Yaser Sheikh. Deep appearance models for face ren- dering. ACM TOG, 37(4), 2018. 1, 2, 3, 6, 12
work page 2018
-
[14]
Stacked hourglass networks for human pose estimation
Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In Proc. ECCV, 2016. 3, 11
work page 2016
-
[15]
3D face reconstruction by learning from synthetic data
Elad Richardson, Matan Sela, and Ron Kimmel. 3D face reconstruction by learning from synthetic data. In Proc. 3DV, 2016. 3
work page 2016
-
[16]
Learning detailed face reconstruction from a single image
Elad Richardson, Matan Sela, Roy Or-El, and Ron Kimmel. Learning detailed face reconstruction from a single image. In Proc. CVPR, 2017. 3
work page 2017
-
[17]
Sami Romdhani and Thomas Vetter. Estimating 3D shape and texture using pixel intensity, edges, specular highlights, texture constraints and a prior. In Proc. CVPR, 2005. 2
work page 2005
-
[18]
Adap- tive 3D face reconstruction from unconstrained photo collections
Joseph Roth, Yiying Tong, and Xiaoming Liu. Adap- tive 3D face reconstruction from unconstrained photo collections. In Proc. CVPR, 2016. 2
work page 2016
-
[19]
300 faces in-the-wild challenge: Database and results
Christos Sagonas, Epameinondas Antonakos, Geor- gios Tzimiropoulos, Stefanos Zafeiriou, and Maja Pantic. 300 faces in-the-wild challenge: Database and results. Image Vision Comput., 47:3–18, 2016. 12
work page 2016
-
[20]
Very deep convolutional networks for large-scale image recogni- tion
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recogni- tion. In Proc. ICLR, 2015. 3, 11
work page 2015
-
[21]
Ran Tao, Efstratios Gavves, and Arnold W. M. Smeul- ders. Siamese instance search for tracking. In Proc. CVPR, 2016. 12
work page 2016
-
[22]
Self-supervised multi-level face model learning for monocular reconstruction at over 250 Hz
Ayush Tewari, Michael Zollhöfer, Pablo Garrido, Flo- rian Bernard, Hyeongwoo Kim, Patrick Pérez, and Christian Theobalt. Self-supervised multi-level face model learning for monocular reconstruction at over 250 Hz. In Proc. CVPR, 2018. 2, 3, 4, 5, 6
work page 2018
-
[23]
MoFA: Model-based deep convo- lutional face autoencoder for unsupervised monocular reconstruction
Ayush Tewari, Michael Zollhöfer, Hyeongwoo Kim, Pablo Garrido, Florian Bernard, Patrick Pérez, and Christian Theobalt. MoFA: Model-based deep convo- lutional face autoencoder for unsupervised monocular reconstruction. In Proc. ICCV, 2017. 2, 6
work page 2017
-
[24]
Regressing robust and discriminative 3D morphable models with a very deep neural network
Anh Tuan Tran, Tal Hassner, Iacopo Masi, and Gérard Medioni. Regressing robust and discriminative 3D morphable models with a very deep neural network. In Proc. CVPR, 2017. 3
work page 2017
-
[25]
Lightweight binocular facial performance capture under uncon- trolled lighting
Levi Valgaerts, Chenglei Wu, Andrés Bruhn, Hans- Peter Seidel, and Christian Theobalt. Lightweight binocular facial performance capture under uncon- trolled lighting. ACM TOG, 31(6):187–1, 2012. 6
work page 2012
-
[26]
Pixel-level matching for video object segmentation using convo- lutional neural networks
Jae Shin Yoon, Francois Rameau, Junsik Kim, Seokju Lee, Seunghak Shin, and In So Kweon. Pixel-level matching for video object segmentation using convo- lutional neural networks. In Proc. ICCV, 2017. 3, 12
work page 2017
-
[27]
Xiangyu Zhu, Zhen Lei, Xiaoming Liu, Hailin Shi, and Stan Z. Li. Face alignment across large poses: A 3D solution. In Proc. CVPR, 2016. 6
work page 2016
-
[28]
Xiangyu Zhu, Zhen Lei, Junjie Yan, Dong Yi, and Stan Z. Li. High-fidelity pose and expression nor- malization for face recognition in the wild. In Proc. CVPR, 2015. 6
work page 2015
-
[29]
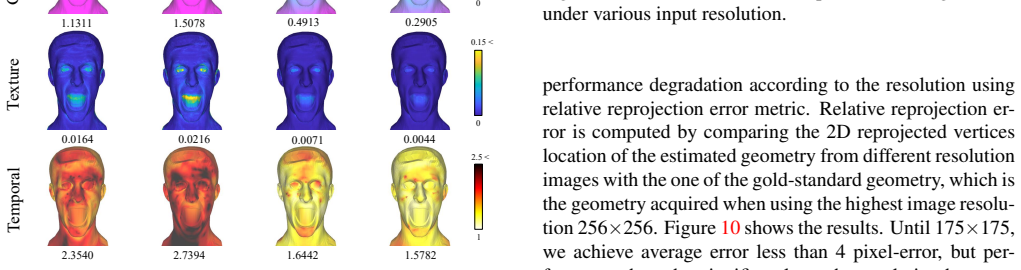
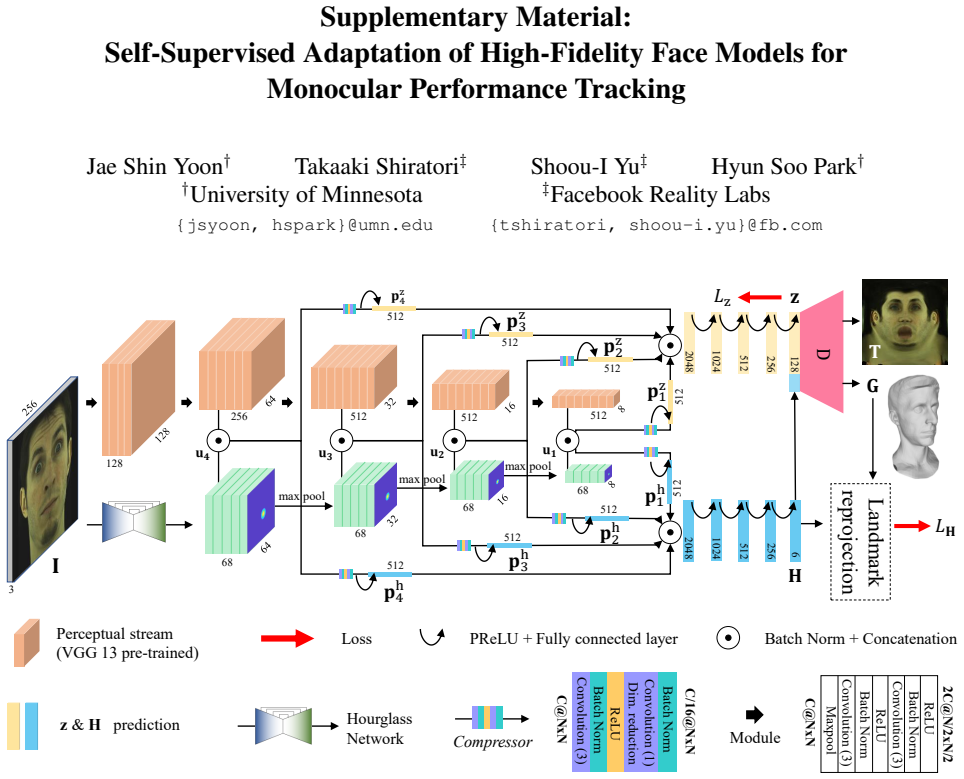
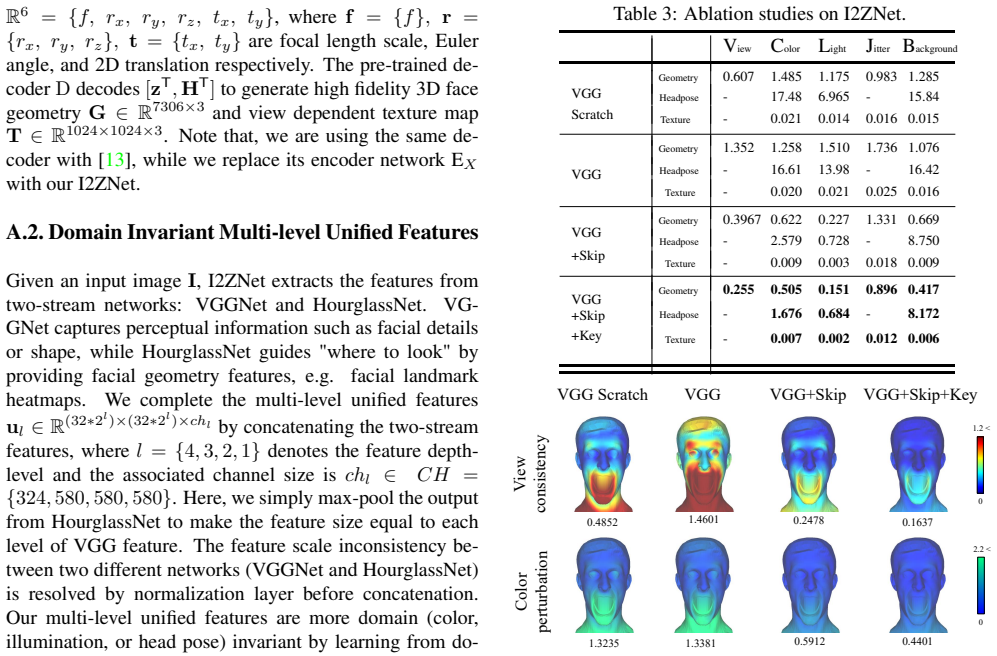
Xiangyu Zhu, Xiaoming Liu, Zhen Lei, and Stan Z. Li. Face alignment in full pose range: A 3D total so- lution. IEEE TPAMI, 2019. 3 Supplementary Material: Self-Supervised Adaptation of High-Fidelity Face Models for Monocular Performance Tracking Jae Shin Yoon† Takaaki Shiratori‡ Shoou-I Yu‡ Hyun Soo Park† †University of Minnesota ‡Facebook Reality Labs {j...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.