A Comparative Study of High-Recall Real-Time Semantic Segmentation Based on Swift Factorized Network
Pith reviewed 2026-05-24 16:04 UTC · model grok-4.3
The pith
A Swift Factorized Network with enlarged receptive-field blocks and three targeted recall methods improves detection of traffic objects over its baseline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Swift Factorized Network, which incorporates enlarged receptive-field blocks and applies three recall-enhancement methods through the loss function, the classifier, and decision rules, reaches excellent performance and significantly improves recall rates compared with the baseline network on the CamVid and Cityscapes datasets.
What carries the argument
Swift Factorized Network (SFN), a U-shaped real-time segmentation architecture with lateral connections plus enlarged receptive-field blocks and recall adjustments applied at loss, classifier, and decision stages.
If this is right
- Fewer traffic objects are missed during real-time operation.
- The model remains fast enough for vehicle deployment while recall rises.
- The three recall methods can be compared directly for their individual contributions.
- The same blocks and adjustments can be inserted into other U-shaped segmentation networks.
Where Pith is reading between the lines
- The recall adjustments may transfer to segmentation models that were not originally factorized.
- Safety validation for new environments would still require fresh recall measurements rather than relying on the original datasets alone.
- Designers of other real-time vision systems for hazard detection could adopt similar loss or decision changes without enlarging the network.
Load-bearing premise
Performance gains measured on CamVid and Cityscapes will continue when the same trained model faces new cameras, weather, or road layouts.
What would settle it
Measuring recall on a held-out collection of driving images recorded under different lighting or camera conditions and finding that the enhanced model no longer exceeds the baseline.
Figures










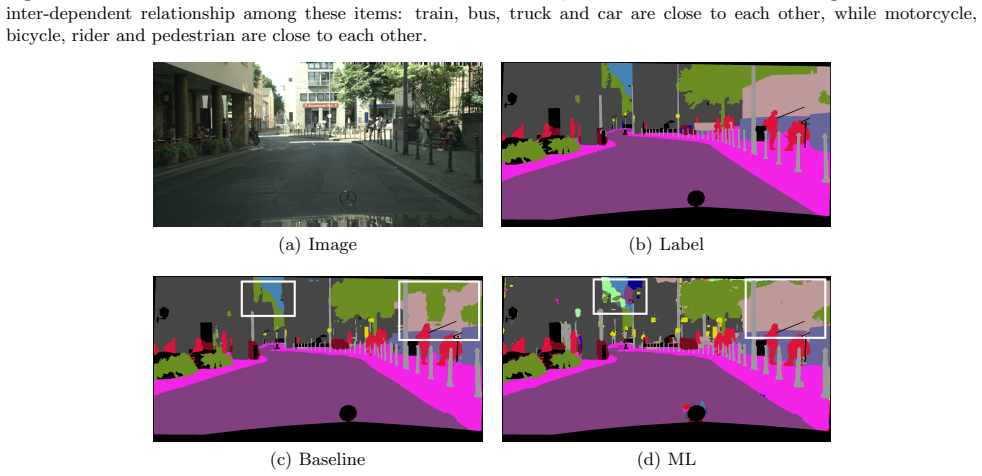
read the original abstract
Semantic Segmentation (SS) is the task to assign a semantic label to each pixel of the observed images, which is of crucial significance for autonomous vehicles, navigation assistance systems for the visually impaired, and augmented reality devices. However, there is still a long way for SS to be put into practice as there are two essential challenges that need to be addressed: efficiency and evaluation criterions for practical application. For specific application scenarios, different criterions need to be adopted. Recall rate is an important criterion for many tasks like autonomous vehicles. For autonomous vehicles, we need to focus on the detection of the traffic objects like cars, buses, and pedestrians, which should be detected with high recall rates. In other words, it is preferable to detect it wrongly than miss it, because the other traffic objects will be dangerous if the algorithm miss them and segment them as safe roadways. In this paper, our main goal is to explore possible methods to attain high recall rate. Firstly, we propose a real-time SS network named Swift Factorized Network (SFN). The proposed network is adapted from SwiftNet, whose structure is a typical U-shape structure with lateral connections. Inspired by ERFNet and Global convolution Networks (GCNet), we propose two different blocks to enlarge valid receptive field. They do not take up too much calculation resources, but significantly enhance the performance compared with the baseline network. Secondly, we explore three ways to achieve higher recall rate, i.e. loss function, classifier and decision rules. We perform a comprehensive set of experiments on state-of-the-art datasets including CamVid and Cityscapes. We demonstrate that our SS convolutional neural networks reach excellent performance. Furthermore, we make a detailed analysis and comparison of the three proposed methods on the promotion of recall rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Swift Factorized Network (SFN), adapted from SwiftNet with two enlarged receptive-field blocks inspired by ERFNet and GCNet. It further explores three recall-enhancement techniques (loss function, classifier, and decision rules) and evaluates the resulting models on the CamVid and Cityscapes benchmarks, claiming significantly higher recall than the SwiftNet baseline while preserving real-time inference speed.
Significance. If the internal comparisons hold, the work supplies concrete, reproducible techniques for improving recall in real-time semantic segmentation without sacrificing efficiency. The use of standard public benchmarks, ablation tables, and quantitative results on two datasets provides a verifiable empirical contribution to practical applications such as autonomous driving.
minor comments (2)
- [Abstract] Abstract: the summary asserts performance gains and 'excellent performance' but supplies no numerical metrics, error bars, or specific recall/accuracy figures; adding the key quantitative results would make the abstract self-contained.
- The manuscript would benefit from an explicit statement of the real-time FPS achieved by the final SFN variants on the target hardware, to directly support the efficiency claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments appear in the provided report, so we offer no point-by-point responses below.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical study that proposes the SFN architecture (adapted from SwiftNet with receptive-field blocks) and three recall-enhancement techniques, then reports measured performance on the independent public benchmarks CamVid and Cityscapes. No mathematical derivation, first-principles prediction, or fitted parameter is presented as a result; all claims rest on direct experimental tables and ablations. No self-citation is load-bearing for any uniqueness claim, and no step reduces by construction to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Unifying terrain awareness for the visually impaired through real-time semantic segmentation,
Yang, K., Wang, K., Bergasa, L., Romera, E., Hu, W., Sun, D., Sun, J., Cheng, R., Chen, T., and L´ opez, E., “Unifying terrain awareness for the visually impaired through real-time semantic segmentation,” Sensors 18(5), 1506 (2018)
work page 2018
-
[2]
Xiang, K., Wang, K., and Yang, K., “Importance-aware semantic segmentation with efficient pyramidal context network for navigational assistant systems,” in [2019 IEEE Intelligent Transportation Systems Con- ference (ITSC) ], 1–7, IEEE (2019)
work page 2019
-
[3]
Fully convolutional networks for semantic segmentation,
Long, J., Shelhamer, E., and Darrell, T., “Fully convolutional networks for semantic segmentation,” in [2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) ], 3431–3440, IEEE (2015)
work page 2015
-
[4]
Deep residual learning for image recognition,
He, K., Zhang, X., Ren, S., and Sun, J., “Deep residual learning for image recognition,” in [ 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) ], 770–778, IEEE (2016)
work page 2016
-
[5]
Orsic, M., Kreso, I., Bevandic, P., and Segvic, S., “In defense of pre-trained imagenet architectures for real- time semantic segmentation of road-driving images,” in [ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ], 12607–12616 (2019)
work page 2019
-
[6]
Erfnet: Efficient residual factorized convnet for real-time semantic segmentation,
Romera, E., Alvarez, J. M., Bergasa, L. M., and Arroyo, R., “Erfnet: Efficient residual factorized convnet for real-time semantic segmentation,” IEEE Transactions on Intelligent Transportation Systems 19(1), 263–272 (2018)
work page 2018
-
[7]
Bridging the day and night domain gap for semantic segmentation,
Romera, E., Bergasa, L. M., Yang, K., Alvarez, J. M., and Barea, R., “Bridging the day and night domain gap for semantic segmentation,” in [ 2019 IEEE Intelligent Vehicles Symposium (IV) ], 1184–1190, IEEE (2019)
work page 2019
-
[8]
Large kernel matters improve semantic segmentation by global convolutional network,
Peng, C., Zhang, X., Yu, G., Luo, G., and Sun, J., “Large kernel matters improve semantic segmentation by global convolutional network,” in [ 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)], 1743–1751, IEEE (2017)
work page 2017
-
[9]
Importance-aware semantic segmentation for autonomous vehicles,
Chen, B., Gong, C., and Yang, J., “Importance-aware semantic segmentation for autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems 20(1), 137–148 (2018)
work page 2018
-
[10]
Semantic object classes in video: A high-definition ground truth database,
Brostow, G. J., Fauqueur, J., and Cipolla, R., “Semantic object classes in video: A high-definition ground truth database,” Pattern Recognition Letters 30(2), 88–97 (2009)
work page 2009
-
[11]
The cityscapes dataset for semantic urban scene understanding,
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., and Schiele, B., “The cityscapes dataset for semantic urban scene understanding,” in [ 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) ], 3213–3223, IEEE (2016)
work page 2016
-
[12]
U-net: Convolutional networks for biomedical image seg- mentation,
Ronneberger, O., Fischer, P., and Brox, T., “U-net: Convolutional networks for biomedical image seg- mentation,” in [International Conference on Medical image computing and computer-assisted intervention ], 234–241, Springer (2015)
work page 2015
-
[13]
Pyramid scene parsing network,
Zhao, H., Shi, J., Qi, X., Wang, X., and Jia, J., “Pyramid scene parsing network,” in [2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) ], 6230–6239, IEEE (2017)
work page 2017
-
[14]
Rethinking Atrous Convolution for Semantic Image Segmentation
Chen, L.-C., Papandreou, G., Schroff, F., and Adam, H., “Rethinking atrous convolution for semantic image segmentation,” arXiv preprint arXiv:1706.05587 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[15]
ACNet: Attention Based Network to Exploit Complementary Features for RGBD Semantic Segmentation
Hu, X., Yang, K., Fei, L., and Wang, K., “Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation,” arXiv preprint arXiv:1905.10089 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[16]
ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Paszke, A., Chaurasia, A., Kim, S., and Culurciello, E., “Enet: A deep neural network architecture for real-time semantic segmentation,” arXiv preprint arXiv:1606.02147 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Unifying terrain awareness through real-time semantic segmentation,
Yang, K., Bergasa, L. M., Romera, E., Cheng, R., Chen, T., and Wang, K., “Unifying terrain awareness through real-time semantic segmentation,” in [2018 IEEE Intelligent Vehicles Symposium (IV) ], 1033–1038, IEEE (2018)
work page 2018
-
[18]
Yang, K., Hu, X., Bergasa, L. M., Romera, E., Huang, X., Sun, D., and Wang, K., “Can we pass beyond the field of view? panoramic annular semantic segmentation for real-world surrounding perception,” in [ 2019 IEEE Intelligent Vehicles Symposium (IV) ], 374–381, IEEE (2019)
work page 2019
-
[19]
Icnet for real-time semantic segmentation on high-resolution images,
Zhao, H., Qi, X., Shen, X., Shi, J., and Jia, J., “Icnet for real-time semantic segmentation on high-resolution images,” in [ Proceedings of the European Conference on Computer Vision (ECCV) ], 405–420 (2018)
work page 2018
-
[20]
Bisenet: Bilateral segmentation network for real- time semantic segmentation,
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., and Sang, N., “Bisenet: Bilateral segmentation network for real- time semantic segmentation,” in [ Proceedings of the European Conference on Computer Vision (ECCV) ], 325–341 (2018)
work page 2018
-
[21]
Shufflenet: An extremely efficient convolutional neural network for mobile devices,
Zhang, X., Zhou, X., Lin, M., and Sun, J., “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in [ 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition ], 6848– 6856, IEEE (2018)
work page 2018
-
[22]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., and Adam, H., “Mobilenets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Focal loss for dense object detection,
Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Doll´ ar, P., “Focal loss for dense object detection,” in [ 2017 IEEE International Conference on Computer Vision (ICCV) ], 2999–3007, IEEE (2017)
work page 2017
-
[24]
Predicting polarization beyond se- mantics for wearable robotics,
Yang, K., Bergasa, L. M., Romera, E., Huang, X., and Wang, K., “Predicting polarization beyond se- mantics for wearable robotics,” in [ 2018 IEEE-RAS 18th International Conference on Humanoid Robots (Humanoids)], 96–103, IEEE (2018)
work page 2018
-
[25]
Not all pixels are equal: Difficulty-aware semantic seg- mentation via deep layer cascade,
Li, X., Liu, Z., Luo, P., Loy, C. C., and Tang, X., “Not all pixels are equal: Difficulty-aware semantic seg- mentation via deep layer cascade,” in [2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)], 6459–6468, IEEE (2017)
work page 2017
-
[26]
Sun, R., Zhu, X., Wu, C., Huang, C., Shi, J., and Ma, L., “Not all areas are equal: Transfer learning for semantic segmentation via hierarchical region selection,” in [ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ], 4360–4369 (2019)
work page 2019
-
[27]
Multi-label image recognition with graph convolutional networks,
Chen, Z.-M., Wei, X.-S., Wang, P., and Guo, Y., “Multi-label image recognition with graph convolutional networks,” in [ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition ], 5177– 5186 (2019)
work page 2019
-
[28]
3d graph neural networks for rgbd semantic segmen- tation,
Qi, X., Liao, R., Jia, J., Fidler, S., and Urtasun, R., “3d graph neural networks for rgbd semantic segmen- tation,” in [ 2017 IEEE International Conference on Computer Vision (ICCV) ], 5209–5218, IEEE (2017)
work page 2017
-
[29]
Robustifying semantic cognition of traversability across wearable rgb-depth cameras,
Yang, K., Bergasa, L. M., Romera, E., and Wang, K., “Robustifying semantic cognition of traversability across wearable rgb-depth cameras,” Applied optics 58(12), 3141–3155 (2019)
work page 2019
-
[30]
Application of Decision Rules for Handling Class Imbalance in Semantic Segmentation
Chan, R., Rottmann, M., H¨ uger, F., Schlicht, P., and Gottschalk, H., “Application of decision rules for handling class imbalance in semantic segmentation,” arXiv preprint arXiv:1901.08394 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[31]
Imagenet large scale visual recognition challenge,
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al., “Imagenet large scale visual recognition challenge,” International journal of computer vision 115(3), 211–252 (2015)
work page 2015
-
[32]
Spatial pyramid pooling in deep convolutional networks for visual recognition,
He, K., Zhang, X., Ren, S., and Sun, J., “Spatial pyramid pooling in deep convolutional networks for visual recognition,” IEEE transactions on pattern analysis and machine intelligence 37(9), 1904–1916 (2015)
work page 1904
-
[33]
Adam: A Method for Stochastic Optimization
Kingma, D. P. and Ba, J., “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[34]
Maaten, L. v. d. and Hinton, G., “Visualizing data using t-sne,” Journal of machine learning re- search 9(Nov), 2579–2605 (2008)
work page 2008
-
[35]
Lin, S., Cheng, R., Wang, K., and Yang, K., “Visual localizer: Outdoor localization based on convnet descriptor and global optimization for visually impaired pedestrians,” Sensors 18(8), 2476 (2018)
work page 2018
-
[36]
Cheng, R., Wang, K., Lin, S., Hu, W., Yang, K., Huang, X., Li, H., Sun, D., and Bai, J., “Panoramic annular localizer: Tackling the variation challenges of outdoor localization using panoramic annular images and active deep descriptors,” arXiv preprint arXiv:1905.05425 (2019)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.