AI-based Prediction of Independent Construction Safety Outcomes from Universal Attributes
Pith reviewed 2026-05-24 16:13 UTC · model grok-4.3
The pith
NLP-extracted attributes from incident reports predict four independently human-annotated construction safety outcomes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Attributes extracted via natural language processing from raw incident reports remain highly predictive of safety outcomes when those outcomes are supplied by independent human annotations rather than by the same extraction process, and this holds on a dataset of more than 90,000 reports for injury severity, injury type, body part impacted, and incident type.
What carries the argument
NLP extraction of universal attributes from text reports used as input features for machine learning models that predict separate human-annotated safety outcomes.
If this is right
- The approach is validated without risk of spurious correlation created by shared extraction methods.
- Injury severity reaches reliable prediction levels on the large dataset.
- Model stacking and the addition of XGBoost and linear SVM improve performance over prior setups.
- Attribute importance can be examined separately for each outcome category.
Where Pith is reading between the lines
- Real-time screening tools could flag reports likely to involve severe injuries directly from free-text descriptions.
- The same attribute set might be tested for predictive power in non-construction incident corpora such as manufacturing or transportation logs.
- If the attributes capture stable risk signals, retraining on domain-specific reports could transfer the method with minimal new labeling.
Load-bearing premise
The human annotations of the four safety outcomes are truly independent of the NLP attribute extraction process and contain no systematic bias aligned with the extracted attributes.
What would settle it
Collect a fresh set of human annotations on a held-out collection of reports while keeping annotators blind to the NLP attribute values, then test whether the trained models still exceed chance-level accuracy on those new labels.
Figures


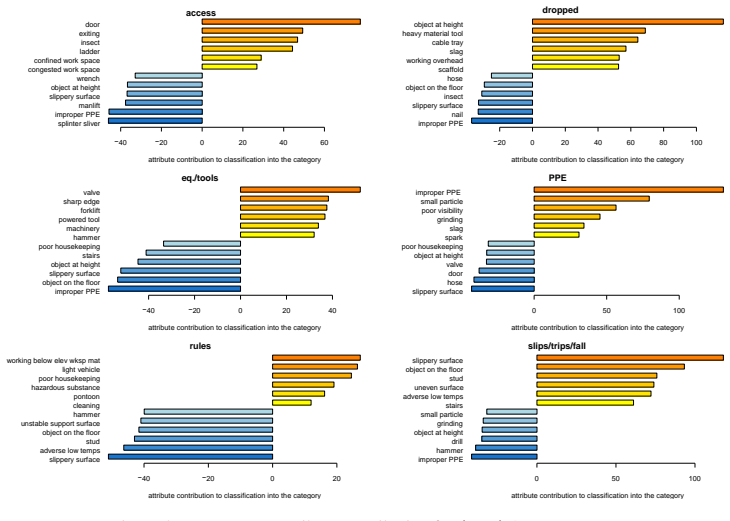
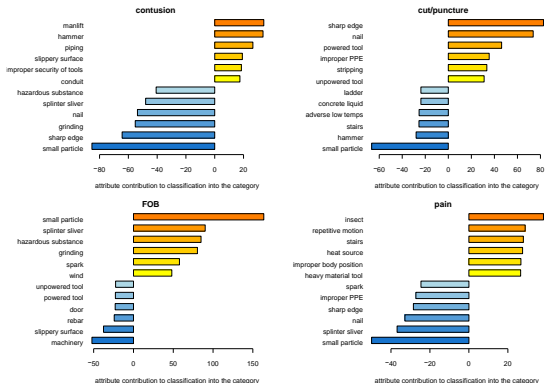

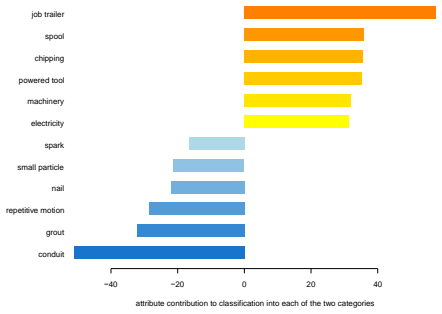
read the original abstract
This paper significantly improves on, and finishes to validate, an approach proposed in previous research in which safety outcomes were predicted from attributes with machine learning. Like in the original study, we use Natural Language Processing (NLP) to extract fundamental attributes from raw incident reports and machine learning models are trained to predict safety outcomes. The outcomes predicted here are injury severity, injury type, body part impacted, and incident type. However, unlike in the original study, safety outcomes were not extracted via NLP but were provided by independent human annotations, eliminating any potential source of artificial correlation between predictors and predictands. Results show that attributes are still highly predictive, confirming the validity of the original approach. Other improvements brought by the current study include the use of (1) a much larger dataset featuring more than 90,000 reports, (2) two new models, XGBoost and linear SVM (Support Vector Machines), (3) model stacking, (4) a more straightforward experimental setup with more appropriate performance metrics, and (5) an analysis of per-category attribute importance scores. Finally, the injury severity outcome is well predicted, which was not the case in the original study. This is a significant advancement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that NLP-extracted universal attributes from over 90,000 raw construction incident reports remain highly predictive of four independently human-annotated safety outcomes (injury severity, injury type, body part impacted, incident type) when using ML models including XGBoost, linear SVM, and model stacking; this eliminates the artificial correlation present in prior work where outcomes were also NLP-derived, and succeeds in predicting injury severity where the original study did not.
Significance. If the independence of the human annotations holds and performance is quantitatively validated, the result would strengthen the case that the extracted attributes capture genuine, generalizable safety signals rather than labeling artifacts, supported by the large dataset size, addition of XGBoost/SVM/stacking, and per-category importance analysis; this advances practical predictive safety tools in construction.
major comments (2)
- [Abstract] Abstract: the central claim that 'safety outcomes were not extracted via NLP but were provided by independent human annotations, eliminating any potential source of artificial correlation' is load-bearing, yet the manuscript provides no protocol details on blinding, annotator separation, access to raw text, or inter-annotator agreement metrics to confirm that human labels introduce no systematic bias correlated with the NLP attributes.
- [Abstract] Abstract and results description: the statements that 'attributes are still highly predictive' and 'the injury severity outcome is well predicted' are presented without any quantitative performance numbers (accuracy, F1, AUC), error bars, cross-validation details, or validation of post-hoc choices such as model stacking and attribute importance scoring.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'safety outcomes were not extracted via NLP but were provided by independent human annotations, eliminating any potential source of artificial correlation' is load-bearing, yet the manuscript provides no protocol details on blinding, annotator separation, access to raw text, or inter-annotator agreement metrics to confirm that human labels introduce no systematic bias correlated with the NLP attributes.
Authors: We agree that the independence of the human annotations is central and that additional protocol details would strengthen the claim. The manuscript states that outcomes were independently human-annotated but does not provide the requested specifics on blinding, annotator separation, access to raw text, or inter-annotator agreement. In revision we will add a new subsection to the Methods section describing the annotation process in as much detail as available from the data source; where formal blinding or agreement metrics were not recorded we will state this explicitly as a limitation rather than over-claim. revision: yes
-
Referee: [Abstract] Abstract and results description: the statements that 'attributes are still highly predictive' and 'the injury severity outcome is well predicted' are presented without any quantitative performance numbers (accuracy, F1, AUC), error bars, cross-validation details, or validation of post-hoc choices such as model stacking and attribute importance scoring.
Authors: Quantitative results (accuracy, F1, AUC where computed), cross-validation procedure, model-stacking validation, and per-category attribute importance are reported in the Results section and tables. We concur that the abstract and high-level results description would benefit from explicit numbers. We will revise the abstract to include key performance figures for the four outcomes (with emphasis on injury severity) and will add a short paragraph in the results description summarizing cross-validation, error estimation, and validation of the stacking and importance analyses. revision: yes
Circularity Check
Minor self-citation to prior work; central claim uses independent human labels with no reduction by construction
full rationale
The paper builds on a prior approach but explicitly replaces NLP-derived outcomes with independent human annotations on a new dataset of >90k reports, training ML models (XGBoost, linear SVM, stacking) on NLP attributes to predict these separate labels. No equations, fitted parameters, or predictions reduce to the inputs by construction, and the self-citation is not load-bearing for the validation claim. The setup directly addresses the most obvious circularity risk from the original study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption NLP-extracted attributes from incident text are universal and carry predictive signal independent of how the outcome labels are generated.
Reference graph
Works this paper leans on
-
[1]
A. J.-P. Tixier, M. R. Hallowell, B. Rajagopalan, D. Bowman, Application of machine learning to construction injury prediction, Automation in Construction 69 (2016) 102–114. doi:10.1016/j.autcon.2016.05.016
-
[2]
W. J. Wiatrowski, J. A. Janocha, Comparing fatal work injuries in the United States and the European Union, Tech. rep., Accessed 21st January 2020 (June 2014). URL https://www.bls.gov/opub/mlr/2014/article/ comparing-fatal-work-injuries-us-eu.htm
work page 2020
-
[3]
A. J.-P. Tixier, M. R. Hallowell, B. Rajagopalan, D. Bowman, Automated content analysis for construction safety: A natural language processing system to extract pre- cursors and outcomes from unstructured injury reports, Automation in Construction 62 (2016) 45–56. doi:10.1016/j.autcon.2015.11.001
-
[4]
T. Hastie, R. Tibshirani, J. Friedman, J. Franklin, The elements of statistical learning: data mining, inference and prediction, The Mathematical Intelligencer 27 (2) (2005) 83–85. doi:10.1007/BF02985802
-
[5]
C. M. Bishop, Pattern recognition and machine learning, Springer, 2006
work page 2006
-
[6]
O. Moselhi, T. Hegazy, P. Fazio, Neural networks as tools in construction, Journal of Construction Engineering and Management 117 (4) (1991) 606–625. doi:10. 1061/(ASCE)0733-9364(1991)117:4(606). 25
work page 1991
-
[7]
M. Skibniewski, T. Arciszewski, K. Lueprasert, Constructability analysis: machine learning approach, Journal of Computing in Civil Engineering 11 (1) (1997) 8–16. doi:10.1061/(ASCE)0887-3801(1997)11:1(8)
-
[8]
L. Soibelman, H. Kim, Data preparation process for construction knowledge genera- tion through knowledge discovery in databases, Journal of Computing in Civil Engi- neering 16 (1) (2002) 39–48. doi:10.1061/(ASCE)0887-3801(2002)16: 1(39)
-
[9]
K. C. Lam, E. Palaneeswaran, C.-y. Yu, A support vector machine model for con- tractor prequalification, Automation in Construction 18 (3) (2009) 321–329. doi: 10.1016/j.autcon.2008.09.007
-
[10]
M.-Y . Cheng, H.-S. Peng, Y .-W. Wu, T.-L. Chen, Estimate at completion for construc- tion projects using evolutionary support vector machine inference model, Automation in Construction 19 (5) (2010) 619–629. doi:10.1016/j.autcon.2010.02. 008
-
[11]
H. Son, C. Kim, C. Kim, Automated color model–based concrete detection in construction-site images by using machine learning algorithms, Journal of Com- puting in Civil Engineering 26 (3) (2011) 421–433. doi:10.1061/(ASCE)CP. 1943-5487.0000141
-
[12]
Air traffic con- troller workload level prediction using conformalized dynamical graph learning
R. Akhavian, A. H. Behzadan, Construction equipment activity recognition for sim- ulation input modeling using mobile sensors and machine learning classifiers, Ad- vanced Engineering Informatics 29 (4) (2015) 867–877. doi:10.1016/j.aei. 2015.03.001
-
[13]
N. Nath, A. H. Behzadan, Construction productivity and ergonomic assessment using mobile sensors and machine learning, in: Proceedings of the ASCE International Workshop on Computing in Civil Engineering 2017: Smart Safety, Sustainability and Resilience, Seattle, W A, 2017, pp. 434–441. doi:10.1061/9780784480847. 054
-
[14]
Z. Zhou, Y . M. Goh, Q. Li, Overview and analysis of safety management studies in the construction industry, Safety Science 72 (2015) 337–350. doi:10.1016/j. ssci.2014.10.006
work page doi:10.1016/j 2015
-
[15]
R. Hubbard, J. Neil, Major and minor accidents at the thames barrier construction site, Journal of Occupational Accidents 7 (3) (1985) 147–164. doi:10.1016/ 0376-6349(85)90001-X
work page 1985
-
[16]
S. Salminen, Serious occupational accidents in the construction industry, Con- struction Management and Economics 13 (4) (1995) 299–306. doi:10.1080/ 01446199500000035
work page 1995
- [17]
- [18]
-
[19]
B. Esmaeili, M. R. Hallowell, B. Rajagopalan, Attribute-based safety risk assess- ment. ii: predicting safety outcomes using generalized linear models, Journal of Con- struction Engineering and Management 141 (8) (2015) 04015022. doi:10.1061/ (ASCE)CO.1943-7862.0000981
-
[20]
K. Kang, H. Ryu, Predicting types of occupational accidents at construction sites in Korea using random forest model, Safety Science 120 (2019) 226–236. doi: 10.1016/j.ssci.2019.06.034
-
[21]
S. Sarkar, S. Vinay, R. Raj, J. Maiti, P. Mitra, Application of optimized machine learning techniques for prediction of occupational accidents, Computers & Opera- tions Research 106 (2019) 210–224. doi:10.1016/j.cor.2018.02.021
-
[22]
S. Sarkar, R. Raj, S. Vinay, J. Maiti, D. K. Pratihar, An optimization-based deci- sion tree approach for predicting slip-trip-fall accidents at work, Safety Science 118 (2019) 57–69. doi:10.1016/j.ssci.2019.05.009
-
[23]
C. Q. Poh, C. U. Ubeynarayana, Y . M. Goh, Safety leading indicators for construction sites: a machine learning approach, Automation in Construction 93 (2018) 375–386. doi:10.1016/j.autcon.2018.03.022
-
[24]
M. Desvignes, Requisite empirical risk data for integration of safety with advanced technologies and intelligent systems, Ph.D. thesis, University of Colorado at Boulder (2014). URL https://scholar.colorado.edu/downloads/0r967398g
work page 2014
-
[25]
M. P. Villanova, Attribute-based risk model for assessing risk to industrial construc- tion tasks, Ph.D. thesis, University of Colorado at Boulder (2014). URL https://scholar.colorado.edu/downloads/jd472w76t
work page 2014
-
[26]
A. J.-P. Tixier, M. R. Hallowell, B. Rajagopalan, D. Bowman, Construction safety clash detection: identifying safety incompatibilities among fundamental attributes using data mining, Automation in Construction 74 (2017) 39–54. doi:10.1016/ j.autcon.2016.11.001
work page 2017
-
[27]
A. J.-P. Tixier, Notes on deep learning for nlp, arXiv preprint, arXiv:1808.09772
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Automatically Learning Construction Injury Precursors from Text
H. Baker, M. R. Hallowell, A. J.-P. Tixier, Automatically learning construction injury precursors from text, arXiv preprint, arXiv:1907.11769
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[29]
Breiman, Random forests, Machine Learning 45 (1) (2001) 5–32
L. Breiman, Random forests, Machine Learning 45 (1) (2001) 5–32. doi:10. 1023/A:1010933404324. 27
work page 2001
-
[30]
T. Chen, C. Guestrin, Xgboost: A scalable tree boosting system, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM, 2016, pp. 785–794. doi:10.1145/2939672.2939785
-
[31]
B. E. Boser, I. M. Guyon, V . N. Vapnik, A training algorithm for optimal margin classifiers, in: ACM Proceedings of the Fifth Annual Workshop on Computational learning theory, 1992, pp. 144–152. doi:10.1145/130385.130401
-
[32]
L. Breiman, J. Friedman, C. J. Stone, R. Olshen, Classification and Regression Trees, CRC Press, 1984
work page 1984
-
[33]
Breiman, Bagging predictors, Machine Learning 24 (2) (1996) 123–140
L. Breiman, Bagging predictors, Machine Learning 24 (2) (1996) 123–140. doi: 10.1023/A:1018054314350
-
[34]
Breiman, Out-of-bag estimation, Tech
L. Breiman, Out-of-bag estimation, Tech. rep. (1996). URL https://www.stat.berkeley.edu/˜breiman/ OOBestimation.pdf
work page 1996
-
[35]
Y . Freund, R. E. Schapire, A decision-theoretic generalization of on-line learning and an application to boosting, Journal of Computer and System Sciences 55 (1) (1997) 119–139. doi:10.1006/jcss.1997.1504
-
[36]
L. Bottou, C.-J. Lin, Support vector machine solvers, Large Scale Kernel Machines 3 (1) (2007) 301–320
work page 2007
-
[37]
R.-E. Fan, K.-W. Chang, C.-J. Hsieh, X.-R. Wang, C.-J. Lin, Liblinear: a library for large linear classification, Journal of Machine Learning Research 9 (Aug) (2008) 1871–1874. doi:10.5555/1390681.1442794
-
[38]
ACM Transactions on Intelligent Systems and Technology2(3), 27:1–27:27 (2011)
C.-C. Chang, C.-J. Lin, Libsvm: a library for support vector machines, ACM Trans- actions on Intelligent Systems and Technology (TIST) 2 (3) (2011) 27. doi: 10.1145/1961189.1961199
-
[39]
T.-F. Wu, C.-J. Lin, R. C. Weng, Probability estimates for multi-class classification by pairwise coupling, Journal of Machine Learning Research 5 (Aug) (2004) 975–1005. doi:10.5555/1005332.1016791
-
[40]
M. R. Hallowell, D. Alexander, J. A. Gambatese, Energy-based safety risk assess- ment: does magnitude and intensity of energy predict injury severity?, Construction Management and Economics 35 (1-2) (2017) 64–77. doi:10.1080/01446193. 2016.1274418
-
[41]
A. Albert, M. R. Hallowell, M. Skaggs, B. Kleiner, Empirical measurement and improvement of hazard recognition skill, Safety Science 93 (2017) 1–8. doi: 10.1016/j.ssci.2016.11.007. 28
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.