REMOD: Relation Extraction for Modeling Online Discourse
Pith reviewed 2026-05-24 14:10 UTC · model grok-4.3
The pith
A new supervised method extracts semantic relations by traversing paths in dependency graphs between entities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our novel supervised learning method combines graph embedding techniques with path traversal on semantic dependency graphs. Knowledge of the entities along the path between the subject and object of a triple provides useful information that can be leveraged for extracting its semantic relation. As an example of a potential application, we show that our method can be integrated into a pipeline to reason about potential misinformation claims.
What carries the argument
Graph embedding combined with path traversal on semantic dependency graphs, which supplies the sequence of intermediate entities as additional features for classifying the relation between a subject and object.
If this is right
- More accurate extraction of relations such as capitalOf or locatedIn from unstructured claim text.
- Improved modeling of how political elites amplify specific claims through repeated entity-relation patterns.
- Automated pipelines that can aggregate and compare fact-checks across many sources without requiring fully structured input.
- Better quantification of the volume and reach of inaccurate claims in the online information ecosystem.
Where Pith is reading between the lines
- The same path-traversal signal could be tested on relation extraction tasks outside fact-checking, such as scientific literature or legal documents.
- If path information proves robust, future systems might reduce the need for large manually annotated relation datasets by leveraging the graph structure already present in parsed text.
- Extending the method to multi-hop paths or incorporating temporal information along the path could address claims that evolve over time.
Load-bearing premise
That the entities appearing on the dependency path between two named entities carry information that improves the accuracy of predicting the semantic relation holding between them in online claims.
What would settle it
A held-out evaluation on annotated ClaimReview triples in which the path-augmented model shows no statistically significant gain in F1 score over a graph-embedding baseline that ignores path information.
Figures




read the original abstract
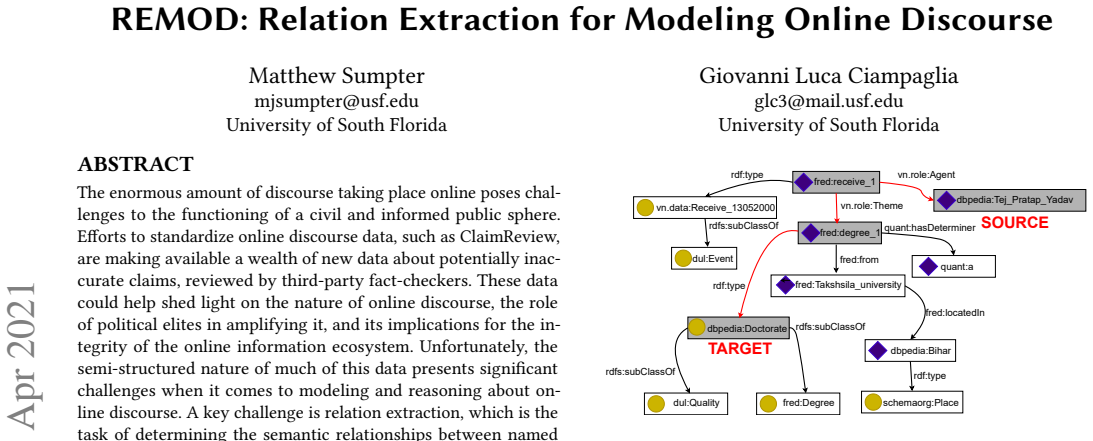
The enormous amount of discourse taking place online poses challenges to the functioning of a civil and informed public sphere. Efforts to standardize online discourse data, such as ClaimReview, are making available a wealth of new data about potentially inaccurate claims, reviewed by third-party fact-checkers. These data could help shed light on the nature of online discourse, the role of political elites in amplifying it, and its implications for the integrity of the online information ecosystem. Unfortunately, the semi-structured nature of much of this data presents significant challenges when it comes to modeling and reasoning about online discourse. A key challenge is relation extraction, which is the task of determining the semantic relationships between named entities in a claim. Here we develop a novel supervised learning method for relation extraction that combines graph embedding techniques with path traversal on semantic dependency graphs. Our approach is based on the intuitive observation that knowledge of the entities along the path between the subject and object of a triple (e.g. Washington,_D.C.}, and United_States_of_America) provides useful information that can be leveraged for extracting its semantic relation (i.e. capitalOf). As an example of a potential application of this technique for modeling online discourse, we show that our method can be integrated into a pipeline to reason about potential misinformation claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces REMOD, a supervised relation extraction method that combines graph embedding techniques with path traversal on semantic dependency graphs. It is motivated by the observation that entities along the path between subject and object in a triple supply useful signal for classifying the semantic relation (e.g., capitalOf), and illustrates integration of the extractor into a pipeline for reasoning about potential misinformation in ClaimReview-style claims.
Significance. If the path-traversal component demonstrably improves relation extraction over standard baselines and the pipeline yields measurable gains on misinformation-related triples, the work could contribute a targeted technique for handling semi-structured online discourse data. The absence of any quantitative results, however, prevents assessment of whether these conditions hold or whether the approach offers advantages over existing shortest-path or graph-feature RE models.
major comments (2)
- [Abstract] Abstract: the manuscript states the intuitive observation and describes the method but supplies no experimental results, baselines, ablation studies isolating the path component, or end-to-end metrics on ClaimReview-style triples, leaving both required conditions of the central claim untested.
- [Abstract] Abstract: no comparison is reported against standard supervised RE models that already incorporate shortest-path or dependency-graph features, so it is impossible to determine whether the proposed combination of graph embeddings and path traversal supplies additive signal.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We agree that the current version of the manuscript is primarily descriptive and does not contain the quantitative experiments needed to substantiate the central claims. We will revise the paper to include a full experimental evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript states the intuitive observation and describes the method but supplies no experimental results, baselines, ablation studies isolating the path component, or end-to-end metrics on ClaimReview-style triples, leaving both required conditions of the central claim untested.
Authors: We acknowledge this limitation. The current manuscript presents the method and an illustrative pipeline but does not report quantitative results. In the revised version we will add an Experiments section containing: (1) performance on standard relation extraction benchmarks, (2) ablation studies that isolate the contribution of the path-traversal component, and (3) end-to-end metrics on a ClaimReview-derived dataset for the misinformation-reasoning task. revision: yes
-
Referee: [Abstract] Abstract: no comparison is reported against standard supervised RE models that already incorporate shortest-path or dependency-graph features, so it is impossible to determine whether the proposed combination of graph embeddings and path traversal supplies additive signal.
Authors: We agree that direct comparisons to existing shortest-path and graph-feature baselines are required. The revised manuscript will include these comparisons (e.g., against models that use dependency-path features or graph kernels) and will report whether the combination of graph embeddings and explicit path traversal yields measurable gains. revision: yes
Circularity Check
No significant circularity; method is a standard novel proposal grounded in observation
full rationale
The paper proposes a supervised relation extraction technique that combines graph embeddings with path traversal on dependency graphs, justified by the intuitive observation that entities along paths between subject and object supply useful signal for semantic relations. No equations, derivations, or self-referential definitions appear in the abstract or description that would reduce the claimed method to its inputs by construction. No fitted parameters are renamed as predictions, no uniqueness theorems are imported from self-citations, and no ansatzes are smuggled via prior work. The central claim remains an independent modeling choice rather than a tautology, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge of the entities along the path between the subject and object of a triple provides useful information that can be leveraged for extracting its semantic relation.
Reference graph
Works this paper leans on
-
[1]
Hunt Allcott and Matthew Gentzkow. 2017. Social media and fake news in the 2016 election. Journal of economic perspectives 31, 2 (2017), 211–36. REMOD KnOD’21 Workshop, April 14, 2021, Virtual Event
work page 2017
-
[2]
Gabor Angeli and Christopher D. Manning. 2014. NaturalLI: Natural Logic Inference for Common Sense Reasoning. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) . Association for Computational Linguistics, Doha, Qatar, 534–545. https://doi.org/10.3115/v1/ D14-1059
work page doi:10.3115/v1/ 2014
-
[3]
Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, and Tom Kwiatkowski
-
[4]
In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Matching the Blanks: Distributional Similarity for Relation Learning. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy, 2895–2905. https://doi.org/10.18653/v1/P19-1279
- [5]
-
[6]
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Ok- sana Yakhnenko. 2013. Translating Embeddings for Modeling Multi-relational Data. In Advances in Neural Information Processing Systems 26 , C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (Eds.). Curran Associates, Inc., Red Hook, NY, United States, 2787–2795
work page 2013
-
[7]
B. Borel. 2016. The Chicago Guide to Fact-Checking . University of Chicago Press, Chicago, IL, USA
work page 2016
-
[8]
Alexandre Bovet and Hernán A. Makse. 2019. Influence of fake news in Twitter during the 2016 US presidential election. Nature Communications 10, 1 (Jan. 2019),
work page 2019
-
[9]
https://doi.org/10.1038/s41467-018-07761-2
-
[10]
Lorenz Bühmann and Jens Lehmann. 2013. Pattern Based Knowledge Base Enrichment. In The Semantic Web – ISWC 2013, Harith Alani, Lalana Kagal, Achille Fokoue, Paul Groth, Chris Biemann, Josiane Xavier Parreira, Lora Aroyo, Natasha Noy, Chris Welty, and Krzysztof Janowicz (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 33–48
work page 2013
-
[11]
Razvan C. Bunescu and Raymond J. Mooney. 2005. A Shortest Path Depen- dency Kernel for Relation Extraction. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (Vancouver, British Columbia, Canada) (HLT ’05). Association for Computational Linguistics, USA, 724–731. https://doi.org/10.3115/1220...
-
[12]
Giovanni Luca Ciampaglia. 2018. Fighting fake news: a role for computational social science in the fight against digital misinformation.Journal of Computational Social Science 1, 1 (29 Jan. 2018), 147–153. https://doi.org/10.1007/s42001-017- 0005-6
-
[13]
Rocha, Johan Bollen, Filippo Menczer, and Alessandro Flammini
Giovanni Luca Ciampaglia, Prashant Shiralkar, Luis M. Rocha, Johan Bollen, Filippo Menczer, and Alessandro Flammini. 2015. Computational Fact Checking from Knowledge Networks. PLOS ONE 10, 6 (06 2015), 1–13. https://doi.org/10. 1371/journal.pone.0128193
work page 2015
-
[14]
Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Mur- phy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining . Association for Computing Machinery, New York, New Y...
-
[15]
Xin Luna Dong, Evgeniy Gabrilovich, Kevin Murphy, Van Dang, Wilko Horn, Camillo Lugaresi, Shaohua Sun, and Wei Zhang. 2015. Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources. Proc. VLDB Endow. 8, 9 (May 2015), 938–949. https://doi.org/10.14778/2777598.2777603
-
[16]
C. Fellbaum and G.A. Miller. 1998. WordNet: An Electronic Lexical Database. MIT Press, Cambridge, MA, USA
work page 1998
-
[17]
Kenney, and Amanda Wintersieck
Kim Fridkin, Patrick J. Kenney, and Amanda Wintersieck. 2015. Liar, Liar, Pants on Fire: How Fact-Checking Influences Citizens’ Reactions to Nega- tive Advertising. Political Communication 32, 1 (Jan 2015), 127–151. https: //doi.org/10.1080/10584609.2014.914613
-
[18]
Luis Antonio Galárraga, Christina Teflioudi, Katja Hose, and Fabian Suchanek
-
[19]
AMIE: association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd international conference on World Wide Web - WWW ’13. ACM Press, New York, New York, USA, 413–422. https: //doi.org/10.1145/2488388.2488425
-
[20]
Aldo Gangemi, Valentina Presutti, Diego Reforgiato Recupero, Andrea Giovanni Nuzzolese, Francesco Draicchio, and Misael Mongiovì. 2017. Semantic Web Machine Reading with FRED. Semantic Web 8, 6 (2017), 873–893. https://doi. org/10.3233/SW-160240
-
[21]
Matt Gardner and Tom Mitchell. 2015. Efficient and Expressive Knowledge Base Completion Using Subgraph Feature Extraction. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics, Lisbon, Portugal, 1488–1498. https://doi.org/10. 18653/v1/D15-1173
work page 2015
-
[22]
Nir Grinberg, Kenneth Joseph, Lisa Friedland, Briony Swire-Thompson, and David Lazer. 2019. Fake news on Twitter during the 2016 US presidential election. Science 363, 6425 (2019), 374–378
work page 2019
- [23]
-
[24]
Andrew M Guess, Brendan Nyhan, and Jason Reifler. 2020. Exposure to untrust- worthy websites in the 2016 US election. Nature human behaviour 4, 5 (2020), 472–480
work page 2020
-
[25]
R. V. Guha, Dan Brickley, and Steve Macbeth. 2016. Schema.Org: Evolution of Structured Data on the Web. Commun. ACM 59, 2 (Jan. 2016), 44–51. https: //doi.org/10.1145/2844544
-
[26]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems (Long Beach, California, USA) (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 1025–1035
work page 2017
-
[27]
Naeemul Hassan, Gensheng Zhang, Fatma Arslan, Josue Caraballo, Damian Jimenez, Siddhant Gawsane, Shohedul Hasan, Minumol Joseph, Aaditya Kulkarni, Anil Kumar Nayak, Vikas Sable, Chengkai Li, and Mark Tremayne. 2017. Claim buster: The firstever endtoend factchecking system. Proceedings of the VLDB Endowment 10, 12 (2017), 1945–1948. https://doi.org/10.1477...
-
[28]
Viet Phi Huynh and Paolo Papotti. 2019. A benchmark for fact checking algo- rithms built on knowledge bases. In International Conference on Information and Knowledge Management, Proceedings, Vol. 10. Association for Computing Machin- ery, New York, NY, USA, 689–698. https://doi.org/10.1145/3357384.3358036
-
[29]
Krutika Kale. 2018. No, Tej Pratap Yadav Did Not Receive A Doctorate From Takshashila University. Online at https://www.boomlive.in/no-lalus-son-tej- pratap-did-not-receive-a-doctorate-from-takshashila-university/. Last accessed 2021-02-21
work page 2018
-
[30]
Sunny Lai, Kwong Sak Leung, and Yee Leung. 2018. SUNNYNLP at SemEval-2018 Task 10: A Support-Vector-Machine-Based Method for Detecting Semantic Differ- ence using Taxonomy and Word Embedding Features. In Proceedings of The 12th International Workshop on Semantic Evaluation. Association for Computational Linguistics, New Orleans, Louisiana, 741–746. https:...
-
[31]
Ni Lao and William W. Cohen. 2010. Relational retrieval using a combination of path-constrained random walks. Machine Learning 81, 1 (2010), 53–67. https: //doi.org/10.1007/s10994-010-5205-8
-
[32]
Ni Lao, Tom Mitchell, and William W. Cohen. 2011. Random Walk Inference and Learning in A Large Scale Knowledge Base. In Proceedings of the 2011 Con- ference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics, Edinburgh, Scotland, UK., 529–539
work page 2011
-
[33]
David MJ Lazer, Matthew A Baum, Yochai Benkler, Adam J Berinsky, Kelly M Greenhill, Filippo Menczer, Miriam J Metzger, Brendan Nyhan, Gordon Penny- cook, David Rothschild, et al. 2018. The science of fake news. Science 359, 6380 (2018), 1094–1096
work page 2018
-
[34]
Quoc Le and Tomas Mikolov. 2014. Distributed Representations of Sentences and Documents. In Proceedings of the 31st International Conference on International Conference on Machine Learning - Volume 32 (ICML’14). JMLR.org, Beijing, China, II–1188–II–1196
work page 2014
-
[35]
Stephan Lewandowsky, Ullrich K. H. Ecker, Colleen M. Seifert, Norbert Schwarz, and John Cook. 2012. Misinformation and Its Correction: Continued Influence and Successful Debiasing. Psychological Science in the Public Interest 13, 3 (2012), 106–131. https://doi.org/10.1177/1529100612451018
-
[36]
David Liben-Nowell and Jon Kleinberg. 2007. The Link-Prediction Problem for Social Networks. Journal of the American society for Information Science and Technology 58, 7 (2007), 1019–1031
work page 2007
-
[37]
Xiaomo Liu, Armineh Nourbakhsh, Quanzhi Li, Rui Fang, and Sameena Shah
-
[38]
Real-Time Rumor Debunking on Twitter. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management (Mel- bourne, Australia) (CIKM ’15). Association for Computing Machinery, New York, NY, USA, 1867–1870. https://doi.org/10.1145/2806416.2806651
-
[39]
T. Mitchell, W. Cohen, E. Hruschka, P. Talukdar, B. Yang, J. Betteridge, A. Carlson, B. Dalvi, M. Gardner, B. Kisiel, J. Krishnamurthy, N. Lao, K. Mazaitis, T. Mohamed, N. Nakashole, E. Platanios, A. Ritter, M. Samadi, B. Settles, R. Wang, D. Wijaya, A. Gupta, X. Chen, A. Saparov, M. Greaves, and J. Welling. 2018. Never-Ending Learning. Commun. ACM 61, 5 ...
work page 2018
-
[40]
Brendan Nyhan and Jason Reifler. 2015. The Effect of Fact-Checking on Elites: A Field Experiment on U.S. State Legislators. American Journal of Political Science 59, 3 (2015), 628–640. https://doi.org/10.1111/ajps.12162
-
[41]
Dave Orr. 2013. 50,000 Lessons on How to Read: a Relation Extraction Cor- pus. https://ai.googleblog.com/2013/04/50000-lessons-on-how-to-read-relation. html
work page 2013
-
[42]
Stefano Ortona, Venkata Vamsikrishna Meduri, and Paolo Papotti. 2018. Robust discovery of positive and negative rules in knowledge bases. In 2018 IEEE 34th International Conference on Data Engineering (ICDE) (Paris, France). IEEE, IEEE, Piscataway, NJ, USA, 1168–1179
work page 2018
-
[43]
Heiko Paulheim and Simone Paolo Ponzetto. 2013. Extending DBpedia with Wikipedia List Pages. In Proceedings of the 2013th International Conference on NLP & DBpedia - Volume 1064 (Sydney, Australia) (NLP-DBPEDIA’13). CEUR-WS.org, Aachen, DEU, 85–90. KnOD’21 Workshop, April 14, 2021, Virtual Event Matthew Sumpter and Giovanni Luca Ciampaglia
work page 2013
-
[44]
Hannah Rashkin, Eunsol Choi, Jin Yea Jang, Svitlana Volkova, and Yejin Choi. 2017. Truth of Varying Shades: Analyzing Language in Fake News and Political Fact- Checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Copenhagen, Denmark, 2931–2937. https://doi.org/10.18...
-
[45]
Bradley L. Richards and Raymond J. Mooney. 1992. Learning Relations by Pathfinding. In Proceedings of the Tenth National Conference on Artificial Intelli- gence (San Jose, California) (AAAI’92). AAAI Press, Palo Alto, CA, USA, 50–55
work page 1992
-
[46]
Rubin, Yimin Chen, and Nadia K
Victoria L. Rubin, Yimin Chen, and Nadia K. Conroy. 2015. Deception detection for news: Three types of fakes. Proceedings of the Association for Information Science and Technology 52, 1 (2015), 1–4. https://doi.org/10.1002/pra2.2015.145052010083
-
[47]
Victoria L. Rubin and Tatiana Vashchilko. 2012. Identification of Truth and Deception in Text: Application of Vector Space Model to Rhetorical Structure Theory. In Proceedings of the Workshop on Computational Approaches to Deception Detection. Association for Computational Linguistics, Avignon, France, 97–106
work page 2012
-
[48]
schema.org. 2020. ClaimReview schema. https://schema.org/ClaimReview
work page 2020
-
[49]
Chengcheng Shao, Giovanni Luca Ciampaglia, Alessandro Flammini, and Fil- ippo Menczer. 2016. Hoaxy: A Platform for Tracking Online Misinformation. In Proceedings of the 25 th International Conference Companion on World Wide Web (Montréal, Québec, Canada) (WWW ’16 Companion). International World Wide Web Conferences Steering Committee, Republic and Canton ...
-
[50]
Chengcheng Shao, Giovanni Luca Ciampaglia, Onur Varol, Kai-Cheng Yang, Alessandro Flammini, and Filippo Menczer. 2018. The spread of low-credibility content by social bots. Nature communications 9, 1 (2018), 1–9
work page 2018
-
[51]
Baoxu Shi and Tim Weninger. 2016. Discriminative predicate path mining for fact checking in knowledge graphs. Knowledge-Based Systems 104 (Jul 2016), 123–133. https://doi.org/10.1016/j.knosys.2016.04.015 arXiv:1510.05911
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.knosys.2016.04.015 2016
-
[52]
Prashant Shiralkar, Alessandro Flammini, Filippo Menczer, and Giovanni Luca Ciampaglia. 2017. Finding Streams in Knowledge Graphs to Support Fact Check- ing. In 2017 IEEE International Conference on Data Mining (ICDM) (New Orleans, Louisiana, USA). IEEE, Piscataway, NJ, 859–864. https://doi.org/10.1109/ICDM. 2017.105 arXiv:1708.07239 [cs.AI] Extended Version
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/icdm 2017
-
[53]
Kai Shu, Deepak Mahudeswaran, Suhang Wang, and Huan Liu. 2020. Hierarchical propagation networks for fake news detection: Investigation and exploitation. In Proceedings of the International AAAI Conference on Web and Social Media , Vol. 14. AAAI, Palo Alto, CA, USA, 626–637
work page 2020
-
[54]
Kai Shu, Suhang Wang, and Huan Liu. 2018. Understanding User Profiles on Social Media for Fake News Detection. In IEEE 1st Conference on Multimedia Information Processing and Retrieval (MIPR 2018) . IEEE, Piscataway, NJ, USA, 430–435. https://doi.org/10.1109/MIPR.2018.00092
-
[55]
Craig Silverman (Ed.). 2014. Verification Handbook. European Journalism Center, Maastricht, the Netherlands
work page 2014
-
[56]
Sameer Singh, Sebastian Riedel, Brian Martin, Jiaping Zheng, and Andrew McCal- lum. 2013. Joint Inference of Entities, Relations, and Coreference. In Proceedings of the 2013 Workshop on Automated Knowledge Base Construction (San Francisco, California, USA) (AKBC ’13). Association for Computing Machinery, New York, NY, USA, 1–6. https://doi.org/10.1145/250...
-
[57]
Richard Socher, Danqi Chen, Christopher D Manning, and Andrew Ng
-
[58]
In Advances in Neural Information Processing Systems , C
Reasoning With Neural Tensor Networks for Knowledge Base Com- pletion. In Advances in Neural Information Processing Systems , C. J. C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Q. Weinberger (Eds.), Vol. 26. Curran Associates, Inc., 57 Morehouse Lane, Red Hook, NY, United States, 926–934. https://proceedings.neurips.cc/paper/2013/file/ b337e84d...
work page 2013
-
[59]
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal
-
[60]
FEVER: a Large-scale Dataset for Fact Extraction and VERification. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). Association for Computational Linguistics, Stroudsburg, PA, USA, 809–
work page 2018
-
[61]
https://doi.org/10.18653/v1/N18-1074
work page internal anchor Pith review doi:10.18653/v1/n18-1074
-
[62]
Sebastian Tschiatschek, Adish Singla, Manuel Gomez Rodriguez, Arpit Merchant, and Andreas Krause. 2018. Fake News Detection in Social Networks via Crowd Signals. In Companion Proceedings of the The Web Conference 2018 (Lyon, France) (WWW ’18). International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, 517–524. https:/...
-
[63]
Andreas Vlachos and Sebastian Riedel. 2014. Fact Checking: Task definition and dataset construction. In Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science . Association for Computational Linguistics, Baltimore, MD, USA, 18–22. https://doi.org/10.3115/v1/W14-2508
-
[64]
Soroush Vosoughi, Deb Roy, and Sinan Aral. 2018. The spread of true and false news online. Science 359, 6380 (2018), 1146–1151. https://doi.org/10.1126/science. aap9559
-
[65]
Linlin Wang, Zhu Cao, Gerard de Melo, and Zhiyuan Liu. 2016. Relation Clas- sification via Multi-Level Attention CNNs. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers). Association for Computational Linguistics, Berlin, Germany, 1298–1307. https://doi.org/10.18653/v1/P16-1123
-
[66]
Claire Wardle and Hossein Derakhshan. 2017. Information disorder: Toward an interdisciplinary framework for research and policy making . Technical Report. Council of Europe Report
work page 2017
-
[67]
Jen Weedon, William Nuland, and Alex Stamos. 2017. Information Operations and Facebook. Technical Report. Facebook, Inc
work page 2017
-
[68]
Gerhard Weikum and Martin Theobald. 2010. From Information to Knowledge: Harvesting Entities and Relationships from Web Sources. In Proceedings of the Twenty-Ninth ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Data- base Systems (Indianapolis, Indiana, USA) (PODS ’10). Association for Computing Machinery, New York, NY, USA, 65–76. https://doi.org/10...
-
[69]
Shanchan Wu and Yifan He. 2019. Enriching pre-trained language model with entity information for relation classification. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management . 2361–2364
work page 2019
-
[70]
Agarwal, Chengkai Li, Jun Yang, and Cong Yu
You Wu, Pankaj K. Agarwal, Chengkai Li, Jun Yang, and Cong Yu. 2014. Toward Computational Fact-Checking. Proc. VLDB Endow. 7, 7 (March 2014), 589–600. https://doi.org/10.14778/2732286.2732295
-
[71]
Minguang Xiao and Cong Liu. 2016. Semantic Relation Classification via Hierar- chical Recurrent Neural Network with Attention. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers . The COLING 2016 Organizing Committee, Osaka, Japan, 1254–1263
work page 2016
-
[72]
Peng Xu and Denilson Barbosa. 2019. Connecting Language and Knowledge with Heterogeneous Representations for Neural Relation Extraction. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Com- putational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguis...
-
[73]
Ikuya Yamada, Hiroyuki Shindo, Hideaki Takeda, and Yoshiyasu Takefuji. 2016. Joint Learning of the Embedding of Words and Entities for Named Entity Dis- ambiguation. In Proceedings of The 20th SIGNLL Conference on Computational Natural Language Learning. Association for Computational Linguistics, 209 N. Eighth Street, Stroudsburg PA 18360, USA, 250–259
work page 2016
-
[74]
Ran Yu, Ujwal Gadiraju, Besnik Fetahu, Oliver Lehmberg, Dominique Ritze, and Stefan DIetze. 2018. KnowMore - Knowledge base augmentation with structured web markup. , 159–180 pages. https://doi.org/10.3233/SW-180304
-
[75]
Yuhao Zhang, Victor Zhong, Danqi Chen, Gabor Angeli, and Christopher D. Manning. 2017. Position-aware Attention and Supervised Data Improve Slot Filling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Copenhagen, Denmark, 35–45. https://doi.org/10.18653/v1/D17-1004
-
[76]
Zhao, Zilong, Zhao, Jichang, Sano, Yukie, Levy, Orr, Takayasu, Hideki, Takayasu, Misako, Li, Daqing, Wu, Junjie, and Havlin, Shlomo. 2020. Fake news propagates differently from real news even at early stages of spreading. EPJ Data Sci. 9, 1 (2020), 7. https://doi.org/10.1140/epjds/s13688-020-00224-z REMOD KnOD’21 Workshop, April 14, 2021, Virtual Event A ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.