Bayesian Optimistic Optimisation with Exponentially Decaying Regret
Pith reviewed 2026-05-24 12:38 UTC · model grok-4.3
The pith
The BOO algorithm achieves a regret bound of order O(N^{-√N}) for Bayesian optimization of black-box functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BOO is the first practical approach that can achieve an exponential regret bound with order O(N^{-√N}) in the noiseless setting for functions sampled from a Gaussian process with Matérn kernel where the smoothness parameter ν exceeds 4 plus D over 2.
What carries the argument
The BOO algorithm, which intertwines Bayesian optimization concepts with tree-based optimistic optimization based on partitioning the search space.
If this is right
- The regret decreases exponentially faster than previous bounds ranging from O(log N / sqrt(N)) to O(e^{-sqrt(N)}).
- It enables more efficient optimization with fewer function evaluations in the noiseless case.
- It outperforms standard BO methods in practice on synthetic functions and hyperparameter tuning tasks.
Where Pith is reading between the lines
- Hybrid algorithms merging probabilistic and deterministic optimization ideas may yield stronger theoretical guarantees in related search problems.
- This approach could be tested for extensions to noisy observations or other kernel families beyond Matérn.
- Practitioners might achieve better results in hyperparameter tuning by adopting this method when functions meet the smoothness condition.
Load-bearing premise
The objective function is sampled from a Gaussian process with a Matérn kernel having smoothness parameter ν greater than 4 plus half the number of dimensions.
What would settle it
A numerical simulation or theoretical construction showing that the regret under BOO exceeds O(N^{-√N}) for some function satisfying the Gaussian process and Matérn kernel conditions.
Figures


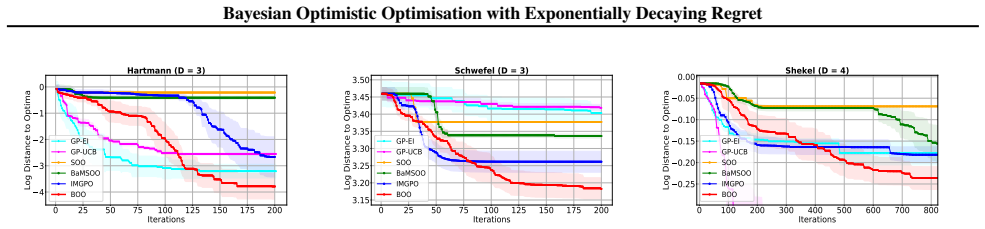

read the original abstract
Bayesian optimisation (BO) is a well-known efficient algorithm for finding the global optimum of expensive, black-box functions. The current practical BO algorithms have regret bounds ranging from $\mathcal{O}(\frac{logN}{\sqrt{N}})$ to $\mathcal O(e^{-\sqrt{N}})$, where $N$ is the number of evaluations. This paper explores the possibility of improving the regret bound in the noiseless setting by intertwining concepts from BO and tree-based optimistic optimisation which are based on partitioning the search space. We propose the BOO algorithm, a first practical approach which can achieve an exponential regret bound with order $\mathcal O(N^{-\sqrt{N}})$ under the assumption that the objective function is sampled from a Gaussian process with a Mat\'ern kernel with smoothness parameter $\nu > 4 +\frac{D}{2}$, where $D$ is the number of dimensions. We perform experiments on optimisation of various synthetic functions and machine learning hyperparameter tuning tasks and show that our algorithm outperforms baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the BOO algorithm, which combines Bayesian optimisation with tree-based optimistic optimisation via space partitioning. It claims to be the first practical method achieving an exponentially decaying regret bound of order O(N^{-√N}) in the noiseless setting, under the assumption that the objective function is sampled from a Gaussian process with Matérn kernel of smoothness ν > 4 + D/2. Experiments on synthetic functions and machine learning hyperparameter tuning tasks are reported to show outperformance over baselines.
Significance. If the claimed regret bound holds under the stated assumptions, the result would represent a meaningful theoretical advance for Bayesian optimisation by delivering a substantially faster rate than the O(log N / √N) to O(e^{-√N}) bounds of existing practical algorithms. The explicit conditioning on a high-smoothness GP prior is clearly stated, and the experimental component provides initial empirical grounding for the approach.
major comments (1)
- [Abstract] Abstract: the O(N^{-√N}) regret claim is load-bearing on the premise that the objective is drawn from a GP with Matérn kernel satisfying ν > 4 + D/2; the manuscript must explicitly verify that this smoothness threshold is both necessary for the derivation and sufficient to guarantee the stated rate without additional hidden regularity conditions.
minor comments (1)
- The abstract refers to 'various synthetic functions' without naming them or describing the experimental protocol (e.g., number of runs, noise model, or comparison metrics), which hinders reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and positive assessment of the significance. We address the single major comment below regarding the abstract and the smoothness threshold.
read point-by-point responses
-
Referee: [Abstract] Abstract: the O(N^{-√N}) regret claim is load-bearing on the premise that the objective is drawn from a GP with Matérn kernel satisfying ν > 4 + D/2; the manuscript must explicitly verify that this smoothness threshold is both necessary for the derivation and sufficient to guarantee the stated rate without additional hidden regularity conditions.
Authors: The threshold ν > 4 + D/2 is the precise condition under which the sample-path regularity of the Matérn GP (Hölder continuity of order α = ν - D/2 > 2) enables the key concentration and optimistic partitioning lemmas in our analysis (Section 4) to yield the exponential regret without further regularity assumptions. Sufficiency is established directly by the proof; the bound does not hold for lower ν under the same partitioning scheme, though we do not provide a formal necessity proof. We will revise the abstract to restate the assumption more explicitly and add a short clarifying remark after Theorem 1 explaining the origin of the threshold from the GP regularity requirements. revision: yes
Circularity Check
No significant circularity; bound is conditional on explicit GP assumption
full rationale
The central result is a regret bound O(N^{-√N}) derived for the BOO algorithm under the stated assumption that the objective is drawn from a GP with Matérn kernel (ν > 4 + D/2). This is a standard conditional theoretical guarantee; the derivation chain does not reduce any prediction or uniqueness claim to a fitted parameter, self-definition, or load-bearing self-citation. No equations or steps in the provided claims exhibit the enumerated circular patterns. The result remains falsifiable outside the paper's own fitted values and is presented as holding only under the given function-class premise.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is sampled from a Gaussian process with Matérn kernel of smoothness ν > 4 + D/2 in the noiseless setting.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
under the assumption that the objective function is sampled from a Gaussian process with a Matérn kernel with smoothness parameter ν > 4 + D/2
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical partition ... m-ary tree ... partitioning procedure P(m;a,b)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
PMLR. URL http://proceedings.mlr. press/v70/chowdhury17a.html. De Freitas, N., Smola, A. J., and Zoghi, M. Exponential regret bounds for gaussian process bandits with determin- istic observations. In Proceedings of the 29th Interna- tional Coference on International Conference on Machine Learning, ICML’12, pp. 955–962, Madison, WI, USA,
-
[2]
Bayesian Optimization with Exponential Convergence
Omnipress. ISBN 9781450312851. Floudas, C. A. Deterministic Global Optimization: Theory, Methods and (NONCONVEX OPTIMIZATION AND ITS APPLICATIONS Volume 37) (Nonconvex Optimization and Its Applications). Springer-Verlag, Berlin, Heidel- berg, 2005. ISBN 0792360141. Grill, J.-B., Valko, M., Munos, R., and Munos, R. Black-box optimization of noisy functions...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
PMLR. URL http://proceedings.mlr. press/v65/scarlett17a.html. Sen, R., Kandasamy, K., and Shakkottai, S. Multi-fidelity black-box optimization with hierarchical partitions. vol- ume 80 of Proceedings of Machine Learning Research, pp. 4538–4547, Stockholmsm¨assan, Stockholm Sweden, 10–15 Jul 2018. PMLR. Srinivas, N., Krause, A., Kakade, S. M., and Seeger, M...
-
[4]
doi: 10.1007/ 978-1-4612-1494-6
ISBN 0-387-98629-4. doi: 10.1007/ 978-1-4612-1494-6. URL http://dx.doi.org/ 10.1007/978-1-4612-1494-6 . Some theory for Kriging. Tran-The, H., Gupta, S., Rana, S., Ha, H., and Venkatesh, S. Sub-linear regret bounds for bayesian optimisation in unknown search spaces. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances i...
-
[5]
Review of SOO, BaMSOO, IMGPO algorithms In the first section of the Supplementary Material, we provide the details of SOO (Munos, 2011) and BamSOO (Wang et al., 2014). The main difference between our proposed BOO algorithm and these algorithms are in the following blue color lines. As we can see, SOO and BaMSOO select a node to be expanded at line 4 in eac...
work page 2011
-
[6]
We here generalize their proof to anym
IMGPO uses a fixedm = 3. We here generalize their proof to anym. The Table 3 shows the strict negative correlation of tree-based optimistic optimisation algorithms like SOO, BamSOO, Bayesian Optimistic Optimisation with Exponentially Decaying Regret Algorithm 3 The BaMSOO Algorithm (Wang et al., 2014) Input: Parameterm Initialisation: Setg0,0 =f(c0,0),f + ...
work page 2014
-
[7]
Given any (a,b )∈M(m) and a partitioning procedureP (m;a,b ), then
Proof of Lemma 1 Lemma 7 (Lemma 1 in the main paper). Given any (a,b )∈M(m) and a partitioning procedureP (m;a,b ), then
-
[8]
the longest side of a cell at depth h is at mosta−⌊bh D⌋, and
-
[9]
the smallest side of a cell at depth h is at leasta−⌈bh D⌉. Proof. We prove the statement by induction. At depthh = 1, we partition the search spaceX intom =ab cells using the partitioning procedureP (m;a,b ). There are two cases onb. • b =D. Then the longest side of a cell at depth h = 1 is 1/a =a−⌊ b D⌋. Also, the smallest side of a cell at depth h = 1 ...
-
[10]
Proof of Lemma 4 To derive an upper bound on variance functionσp as in Lemma 4, we use a concept, called the fill distance. Given a set of pointsDp−1 , we define the fill distanceFD(Dp−1,X ) as the largest distance from any point inX to the points inDp−1, as FD(Dp−1,X ) = supx∈X infci∈Dp−1||x−ci||. The following result, which is proven by Wu & Schaback (1992...
work page 1992
-
[11]
We prove this in the following Lemma 11
Proof of Theorem 1 To prove Theorem 1, we will involve two stages: • Stage 1: we first prove that ifN is large enough, then under some assumptions, all the centers of nodes of expandable nodes will fall into the ballB(x∗,θ ) which is centered atx∗ with radiusθ as defined in Property 1. We prove this in the following Lemma 11. • Stage 2: when a set of expand...
-
[12]
We define a node (h,i ) at depth h as δ(h;a,b )-optimal ifU(ch,i)≥f(ch,i)−δ(h;a,b )
Proof of Lemma 5 Let (h∗ p + 1,i∗) be an optimal node of depth h∗ p + 1 (i.e., x∗ ∈ Ah∗p+1,i∗). We define a node (h,i ) at depth h as δ(h;a,b )-optimal ifU(ch,i)≥f(ch,i)−δ(h;a,b ). We obtains the following result. Bayesian Optimistic Optimisation with Exponentially Decaying Regret Lemma 12. Assume thatf(ch∗p+1,i∗)≤U (ch∗p+1,i∗). Then any node (h∗ p + 1,i )...
-
[13]
Proof of Lemma 6 We useAp to denote the set of all points evaluated by the algorithm and all centers of optimal nodes of the treeTp afterp evaluations. Lemma 14. Pick aη∈ (0, 1). Setβp = 2log(π2p3/3η) andLp(c) =µp(c)−β1/2 p σp(c). With probability 1−η, we have Lp(c)≤f(c)≤U p(c), for everyp≥ 1 and for everyc∈Ap. Proof. Afterp evaluations, there are at most...
work page 2012
-
[14]
Assume that there is a partitioning procedureP (m;a,b ) wherea =O(N 1/D),b =D and 2≤ m < √ N− 1
Proof of Theorem 2 Theorem 4 (Regret Bound). Assume that there is a partitioning procedureP (m;a,b ) wherea =O(N 1/D),b =D and 2≤ m < √ N− 1. Let the depth function hmax(p) =√p. We consider m2 < p≤ N, and defineh(p) as the smallest integerh such that h≥ √p−m− 1 C + 2, whereC is the constant defined by Theorem 1. Pick aη∈ (0, 1). Then for everyN≥N1, the loss...
-
[15]
We let node (h∗ p + 1,o∗) be the optimal node at depthh∗ p + 1
Thus, since the node (h,j ) has been expanded, its GP-UCB value is at least as high as that of the some node (h∗ p + 1,o ) at depthh∗ p + 1, such that • (1) node (h∗ p + 1,o ) has been evaluated at somep′-th expansion before node (h,j ) and • (2) (h∗ p + 1,o )∈ argmax(h∗p+1,i)∈LUp′(ch∗p+1,i) (see Line 4 of Algorithm 1). We let node (h∗ p + 1,o∗) be the op...
-
[16]
Proof of Corollary 1 Corollary 2. Pick aη∈ (0, 1). There exists a constantN2 > 0 such that for everyN≥N2 we have that the simple regret of the proposed BOO with the partitioning procedureP (m;a,b ) wherea =⌊( √ N 2 ) 1 D⌋,b =D, is bounded as rN≤O (N− √ N), with probability 1−η. Proof. Witha =⌊( √ N 2 ) 1 D⌋ andb = D, m = ab≤ √ N/2. These conditions satisf...
-
[17]
Ablation study between function sampling and partitioning procedure in the proposed BOO algorithm To show this point, we have performed additional experiments withm = 64 (see Figure below). The left plot shows different partitioning procedures while function sampling is fixed to our proposed scheme. We can see good improvement when b = D compared tob = 1 c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.