Multitask Learning for Grapheme-to-Phoneme Conversion of Anglicisms in German Speech Recognition
Pith reviewed 2026-05-24 13:09 UTC · model grok-4.3
The pith
A multitask sequence-to-sequence model with an added classifier for Anglicisms produces more accurate phoneme sequences for English loanwords in German and lowers error rates when the outputs are used in speech recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
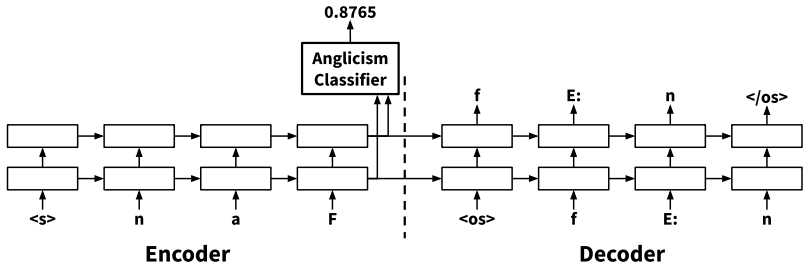
Extending a grapheme-to-phoneme model with a joint classifier that distinguishes Anglicisms from native German words enables the model to generate pronunciations differently depending on the classification result; the resulting supplementary dictionaries, when added to a baseline German speech recognizer, reduce word error rate by 1 percent and Anglicism error rate by 3 percent on a dedicated evaluation set.
What carries the argument
A multitask sequence-to-sequence architecture that jointly performs grapheme-to-phoneme conversion and binary classification of input words as Anglicisms versus native German words.
If this is right
- Supplementary pronunciation dictionaries generated by the model can be merged directly into existing German ASR systems.
- The same multitask structure can be used to produce pronunciation lexicons for other classes of words that deviate from standard German phonotactics.
- The joint training objective encourages the encoder to extract features useful for both classification and phoneme prediction.
- Improvements are measured on a dedicated Anglicism evaluation set rather than only on general German test data.
Where Pith is reading between the lines
- The method could be extended to other languages that import many words with foreign phonology, such as French or Japanese loanword handling.
- If the classifier output were made available at inference time, downstream systems could route words to different pronunciation models without retraining the entire recognizer.
- The approach assumes that the binary distinction is sufficient; finer-grained labels for word origin might yield further gains but are not tested here.
Load-bearing premise
The auxiliary classifier must separate Anglicisms from native words reliably enough that conditioning phoneme generation on the binary label improves accuracy on loanwords without degrading performance on native German words.
What would settle it
An experiment in which the classifier is replaced by random labels or by a low-accuracy classifier and the joint model then shows no reduction in Anglicism error rate on the dedicated test set.
Figures
read the original abstract
Anglicisms are a challenge in German speech recognition. Due to their irregular pronunciation compared to native German words, automatically generated pronunciation dictionaries often include faulty phoneme sequences for Anglicisms. In this work, we propose a multitask sequence-to-sequence approach for grapheme-to-phoneme conversion to improve the phonetization of Anglicisms. We extended a grapheme-to-phoneme model with a classifier to distinguish Anglicisms from native German words. With this approach, the model learns to generate pronunciations differently depending on the classification result. We used our model to create supplementary Anglicism pronunciation dictionaries that are added to an existing German speech recognition model. Tested on a dedicated Anglicism evaluation set, we improved the recognition of Anglicisms compared to a baseline model, reducing the word error rate by 1 % and the Anglicism error rate by 3 %. We show that multitask learning can help solving the challenge of Anglicisms in German speech recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a multitask seq2seq G2P model for German that adds an auxiliary classifier to distinguish Anglicisms from native words, allowing pronunciation generation to be conditioned on the classification output. The resulting model is used to generate supplementary pronunciation dictionaries that are added to an existing ASR system; on a dedicated Anglicism evaluation set this yields a 1% absolute WER reduction and a 3% reduction in Anglicism error rate relative to a baseline.
Significance. If the central claim holds, the work supplies a concrete, deployable technique for improving loanword handling in German ASR via multitask learning. The empirical gains are modest but directly measured on the target error type; the approach is simple enough to be reproducible and could be adopted in production dictionaries.
major comments (1)
- [Abstract / Results] Abstract and evaluation description: the reported 1% WER and 3% Anglicism-error reductions are measured only on a dedicated Anglicism test set. No numbers are supplied for overall WER on a standard German test set, for native-word subsets, or for any ablation that isolates the classifier branch. Because the central claim is that the multitask construction improves Anglicism phonetization “without side effects,” the absence of these measurements is load-bearing; degradation on native words would negate the practical value of the supplementary dictionaries.
minor comments (2)
- [Abstract] The abstract does not state the size of the Anglicism evaluation set, the baseline G2P or ASR model details, or whether any statistical significance test was performed on the 1% / 3% deltas.
- Notation for the joint loss or the way the classifier output is injected into the decoder is not described in the provided abstract; a short methods paragraph would clarify the architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern about missing baseline measurements on standard test sets is valid and directly addresses the practical utility of the proposed supplementary dictionaries. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and evaluation description: the reported 1% WER and 3% Anglicism-error reductions are measured only on a dedicated Anglicism test set. No numbers are supplied for overall WER on a standard German test set, for native-word subsets, or for any ablation that isolates the classifier branch. Because the central claim is that the multitask construction improves Anglicism phonetization “without side effects,” the absence of these measurements is load-bearing; degradation on native words would negate the practical value of the supplementary dictionaries.
Authors: We agree that the absence of these measurements weakens the claim of no side effects. The supplementary dictionaries contain only Anglicism entries generated by the multitask model, so native-word entries in the baseline lexicon remain unchanged; however, this does not fully address whether the underlying multitask G2P model itself would produce different (potentially worse) pronunciations for native words if applied to them. In the revision we will add (i) overall WER on a standard German test set (e.g., Common Voice German), (ii) separate native-word and Anglicism subsets on that set, and (iii) an ablation comparing the full multitask model against a single-task G2P baseline on both subsets. These additions will either confirm the absence of degradation or allow us to qualify the claims. revision: yes
Circularity Check
No circularity; purely empirical multitask model evaluated on external test set
full rationale
The paper proposes and trains a multitask seq2seq G2P model with an auxiliary classifier, generates pronunciation dictionaries, and measures WER/Anglicism error reductions on a dedicated held-out Anglicism evaluation set against a baseline. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described approach. All reported gains are direct empirical measurements on external data, with no load-bearing steps that reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ardila, R., Branson, M., Davis, K., Kohler, M., Meyer, J., Henretty, M., Morais, R., Saunders, L., Tyers, F., and Weber, G. (2020). Common voice: A massively-multilingual speech corpus. In Proceedings of the 12th Language Resources and Evaluation Conference , pages 4218--4222, Marseille, France, May. European Language Resources Association
work page 2020
-
[2]
Bavarian Archive for Speech Signals . (2013). Pronunciation Lexicon PHONOLEX . https://www.phonetik.uni-muenchen.de/forschung/Bas/BasPHONOLEXeng.html
work page 2013
-
[3]
Elfers, A. (2020). Der Anglizismen-Index 2020 - Deutsch statt Denglisch . https://vds-ev.de/denglisch-und-anglizismen/anglizismenindex/ag-anglizismenindex/
work page 2020
-
[4]
Stadtschnitzer, M., Schwenninger, J., Stein, D., and Koehler, J. (2014). Exploiting the large-scale G erman broadcast corpus to boost the F raunhofer IAIS S peech R ecognition S ystem. In Proceedings of the Ninth International Conference on Language Resources and Evaluation ( LREC '14) , pages 3887--3890, Reykjavik, Iceland, May. European Language Resourc...
work page 2014
-
[5]
Wiktionary. (2019). Verzeichnis:Deutsch/Anglizismen . https://de.wiktionary.org/wiki/Verzeichnis:Deutsch/Anglizismen
work page 2019
-
[6]
Wiktionary. (2020). Verzeichnis:Deutsch/Anglizismen/Schein\-angli\-zismen . https://de.wiktionary.org/wiki/Verzeichnis:Deutsch/Anglizismen/Scheinanglizismen
work page 2020
-
[7]
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
-
[8]
Baevski, A., Zhou, H., Mohamed, A., and Auli, M. (2020). wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
work page 2020
-
[9]
Bisani, M. and Ney, H. (2008). Joint-sequence models for grapheme-to-phoneme conversion . Speech Communication , 50(5):434--451
work page 2008
-
[10]
Burmasova, S. (2010). Empirische Untersuchung der Anglizismen im Deutschen am Material der Zeitung Die WELT (Jahrgänge 1994 und 2004)
work page 2010
-
[11]
Caruana, R. (1993). Multitask Learning: A Knowledge-Based Source of Inductive Bias . In Proceedings of the Tenth International Conference on Machine Learning , pages 41--48. Morgan Kaufmann
work page 1993
-
[12]
Caruana, R. (1997). Multitask Learning . Ph.D. thesis, Carnegie Mellon University
work page 1997
-
[13]
Coats, S. (2019). Lexicon geupdated: New German anglicisms in a social media corpus . European Journal of Applied Linguistics , 7:255 -- 280
work page 2019
-
[14]
Conneau, A., Baevski, A., Collobert, R., Mohamed, A., and Auli, M. (2020). Unsupervised Cross-lingual Representation Learning for Speech Recognition
work page 2020
-
[15]
Gref, M., Schmidt, C., Behnke, S., and K \" o hler, J. (2019). Two-Staged Acoustic Modeling Adaption for Robust Speech Recognition by the Example of German Oral History Interviews . In IEEE International Conference on Multimedia and Expo, ICME 2019, Shanghai, China, July 8-12, 2019 , pages 796--801. IEEE
work page 2019
-
[16]
Grosman, J. (2021). Wav2Vec2-Large-XLSR-53-German . https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-german
work page 2021
-
[17]
Hochreiter, S. and Schmidhuber, J. (1997). Long Short-Term Memory . Neural Computation , 9(8):1735--1780, November
work page 1997
-
[18]
Hunt, J. W. (2019). Anglicisms in German: tsunami or trickle? In Amei Koll-Stobbe, editor, Informalization and Hybridization of Speech Practices: Polylingual Meaning-Making across Domains, Genres, and Media , pages 25--58. Peter Lang, Bern, Schweiz
work page 2019
-
[19]
Max Planck Institute for Psycholinguistics, The Language Archive . (2020). ELAN (Version 5.9) and Simple-ELAN (Version 1.3) [Computer software] . https://archive.mpi.nl/tla/elan
work page 2020
-
[20]
Milde, B., Schmidt, C., and Köhler, J. (2017). Multitask Sequence-to-Sequence Models for Grapheme-to-Phoneme Conversion . In INTERSPEECH 2017 , pages 2536--2540
work page 2017
-
[21]
Sokolov, A., Rohlin, T., and Rastrow, A. (2019). Neural Machine Translation for Multilingual Grapheme-to-Phoneme Conversion . In Interspeech 2019 , pages 2065--2069
work page 2019
-
[22]
Sutskever, I., Vinyals, O., and Le, Q. V. (2014). Sequence to Sequence Learning with Neural Networks . In Proceedings of the 27th International Conference on Neural Information Processing Systems - Volume 2 , NIPS'14, pages 3104--–3112, Cambridge, MA, USA. MIT Press
work page 2014
-
[23]
L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. (2020). Transformers: State-of-the-Art Natural Language Processing . In Proceedings of the 2020 ...
work page 2020
-
[24]
Yao, K. and Zweig, G. (2015). Sequence-to-Sequence Neural Net Models for Grapheme-to-Phoneme Conversion . In INTERSPEECH 2015 , pages 3330--3334
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.