Antimodes and Graphical Anomaly Exploration via Adaptive Depth Quantile Functions
Pith reviewed 2026-05-24 13:05 UTC · model grok-4.3
The pith
Adaptive depth quantile functions detect anomalies by adapting to antimodes in the data generating distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By connecting anomalies to antimodes and deriving how depth quantile functions behave in their presence, the adaptive version of the functions produces scores and plots that identify outlying points more reliably than the non-adaptive baseline.
What carries the argument
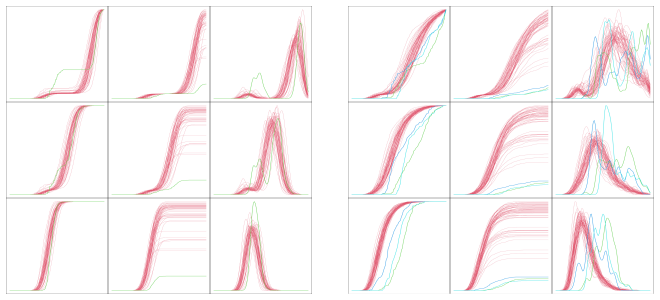
Adaptive depth quantile functions (aDQF), which modify the shape of the single-variable functions attached to each observation so that antimodes in the distribution increase the separation between normal and anomalous points.
If this is right
- Anomaly detection becomes feasible for data lying in any Hilbert space without requiring a Euclidean structure.
- Plots of the per-observation functions supply an immediate graphical way to explore which points deviate from the main mass.
- The same functions can be used for both scoring and visual inspection on the same data set.
- Performance remains competitive with existing detectors across Euclidean and non-Euclidean examples.
Where Pith is reading between the lines
- If the antimode-anomaly link holds only for certain types of contamination, the method could be combined with other depth measures that target different departures.
- The single-variable encoding might allow direct comparison of anomaly patterns across data sets of different dimensions.
- In settings where the data arrive sequentially, the adaptive adjustment could be updated online by tracking changes in the estimated antimode locations.
Load-bearing premise
Anomalies appear in data precisely because the data-generating distribution contains antimodes.
What would settle it
A collection of point clouds in which anomalies have been injected but the underlying distribution has no antimodes, followed by a direct comparison showing that aDQF scores no longer separate the anomalies from the bulk.
Figures












read the original abstract
This work proposes and investigates a novel method for anomaly detection and shows it to be competitive in a variety of Euclidean and non-Euclidean situations. It is based on an extension of the depth quantile functions (DQF) approach. The DQF approach encodes geometric information about a point cloud via functions of a single variable, whereas each observation in a data set is associated with a single such function. Plotting these functions provides a very beneficial visualization aspect. This technique can be applied to any data lying in a Hilbert space. The proposed anomaly detection approach is motivated by the geometric insight of the presence of anomalies in data being tied to the existence of antimodes in the data generating distribution. Coupling this insight with novel theoretical understanding into the shape of the DQFs gives rise to the proposed adaptive DQF (aDQF) methodology. Applications to various data sets illustrate the DQF and aDQF's strong anomaly detection performance, and the benefits of its visualization aspects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the adaptive depth quantile function (aDQF) methodology for anomaly detection and graphical exploration in Hilbert spaces. It extends the depth quantile function (DQF) approach by adapting to antimodes in the data-generating distribution, motivated by the geometric insight that anomalies correspond to antimodes, together with new theoretical results on DQF shapes. The method is claimed to deliver competitive anomaly detection performance across Euclidean and non-Euclidean data sets while providing useful visualization of individual observations via single-variable functions.
Significance. If the central modeling assumption holds and the adaptation produces a measurable advantage, the work supplies a geometrically motivated functional representation for anomaly exploration that is applicable beyond Euclidean spaces and emphasizes visualization. The reported applications to multiple data sets would then constitute concrete evidence of practical utility.
major comments (2)
- [§1 and §3] §1 (Introduction) and §3 (Methodology): The central claim that aDQF yields competitive performance because of the stated geometric insight requires that the presence of anomalies is tied to antimodes with sufficient strength that adaptation around them produces a detectable advantage. No formal statement of the required distributional condition, derivation of the advantage, or counter-example analysis appears; without this the performance gains remain empirical observations rather than consequences of the motivating insight.
- [§4] §4 (Theoretical results): The 'novel theoretical understanding into the shape of the DQFs' is invoked to justify the adaptive construction, yet the manuscript supplies no explicit theorem, proposition, or lemma that quantifies how antimode adaptation alters the DQF shape in a manner that improves anomaly separation. This leaves the adaptation rule without a load-bearing theoretical anchor.
minor comments (2)
- [Abstract and §1] The abstract and introduction repeatedly use 'various data sets' without specifying the collection of benchmarks or contamination models employed; a table listing the data sets, dimensions, and contamination fractions would improve reproducibility.
- [§3] Notation for the adaptive parameter (e.g., the bandwidth or antimode threshold) is introduced without an explicit equation number; cross-referencing would clarify how the adaptation is implemented.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [§1 and §3] §1 (Introduction) and §3 (Methodology): The central claim that aDQF yields competitive performance because of the stated geometric insight requires that the presence of anomalies is tied to antimodes with sufficient strength that adaptation around them produces a detectable advantage. No formal statement of the required distributional condition, derivation of the advantage, or counter-example analysis appears; without this the performance gains remain empirical observations rather than consequences of the motivating insight.
Authors: The geometric insight that anomalies correspond to antimodes in the data-generating distribution is presented as motivation for developing the adaptive construction, not as a formal assumption from which performance guarantees are derived. The manuscript establishes competitive performance through empirical evaluation on multiple data sets. We will add a clarifying paragraph in §1 to make this distinction explicit. revision: partial
-
Referee: [§4] §4 (Theoretical results): The 'novel theoretical understanding into the shape of the DQFs' is invoked to justify the adaptive construction, yet the manuscript supplies no explicit theorem, proposition, or lemma that quantifies how antimode adaptation alters the DQF shape in a manner that improves anomaly separation. This leaves the adaptation rule without a load-bearing theoretical anchor.
Authors: Section 4 supplies new results characterizing DQF shapes under various distributional features; these results inform the definition of the adaptation rule. We agree that no dedicated proposition directly quantifies the separation gain attributable to antimode adaptation. We will insert a short remark in §4 that links the shape results more explicitly to the adaptation step. revision: partial
Circularity Check
No circularity; method motivated by external geometric assumption with empirical validation
full rationale
The provided abstract and description present the aDQF approach as motivated by a stated geometric insight (anomalies tied to antimodes) coupled with theoretical understanding of DQFs, then validated through applications to data sets. No equations, fitted parameters renamed as predictions, self-citations, or derivation steps are exhibited that reduce any claimed result back to its own inputs by construction. The central performance claims rest on empirical illustration rather than a closed loop, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The proposed anomaly detection approach is motivated by the geometric insight of the presence of anomalies in data being tied to the existence of antimodes in the data generating distribution.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 2.1 (median property and zero interval)... qx(δ)=0 for 0≤δ≤lx
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Antimodes and Graphical Anomaly Exploration via Adaptive Depth Quantile Functions
Antimodes and Graphical Anomaly Exploration via Adaptive Depth Quantile Functions Gabriel Chandler Department of Mathematics and Statistics Pomona College, Claremont, CA 91711 and Wolfgang Polonik∗ Department of Statistics University of California, Davis, CA 95616 E-mail: gabriel.chandler@pomona.edu and wpolonik@ucdavis.edu July 19, 2023 Abstract This wor...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
locally” around the anomalous point or anomalous “micro-cluster
define them as observations lying far from the bulk of the data. Considering these different points of view on outliers or anomalies, one sees that rare (anoma- lous) events obviously correspond to low density. Furthermore, the idea of an alternative mech- anism Q generating these observations relates to mixture distributions in the sense of Huber’s (1964...
work page 1964
-
[3]
Therefore we present this case which, in turn, establishes a perhaps unexpected connection to the concept of modal intervals put forward by Lientz (1974), and the related shorth plot (Sawitzki, 1994, Einmahl et al., 2010a,b). The literature on tools for detecting anomalous observations is extensive, and it is impossible to provide a comprehensive overview...
work page 1974
-
[4]
applied to one-dimensional projections, where for a one-dimensional distribution function F , Tukey depth of x ∈ R is defined as T D(x, F) = min{F (x), 1 − F (x)}. The essence of choosing a random subset (spherical cone) and only considering points captured inside this cone is related to the concept of masking that Tukey introduced with PRIM-9 (see Fisher...
work page 1974
-
[5]
, for F (x) ≥ 1 2 . (4) Then, for 0 ≤ δ < δ ∗ x, there exists an interval Ix,δ = [ax,δ, bx,δ] ⊂ [0, 1] of G-measure δ with qx(δ) = 1 2 F (Ix,δ) = F ([ax,δ, x]) = F ([x, bx,δ]). (5) Moreover, qx(δ) = ( 0 for 0 ≤ δ ≤ lx T D(x, F) for δ∗ x ≤ δ ≤ 1 , (6) where lx = sup{G(b) − G(a) : x ∈ [a, b], F ([a, b]) = 0}. The zero interval property expressed in (6) also...
work page 2021
-
[6]
2.2 The case d > 1 As localization is an important aspect of the DQF for small values of δ, one finds that half-spaces as our random subsets will not suffice. Rather, we consider subsets of the data space formed by 6 spherically symmetric cones with opening angle α strictly less than π/4 (the angle between a point on the surface of the cone and the axis o...
work page 2021
-
[7]
Note that the two cones point in opposite directions, and by definition of t+ x,y and t− x,y, they are chosen such that they give the largest spherically symmetric cones under consideration that do not intersect with the support of F. Also note that the two cones belong to the same anchor point that is lying between the bases of these two cones. Figure 5:...
work page 2021
-
[8]
2.2.2 Other (nearly) flat parts Similar to the (near) zero intervals, the DQFs can also display other (nearly) flat portions, where the increase of the DQFs is almost zero over a range of δ values not close to zero. On a heuristic level, this again indicates the presence of ‘empty regions’ that are visible when looking in the ‘right’ direction. Note, howe...
work page 2021
-
[9]
We look at the case where anomalous observations exist in particular types of antimodes, which we call “holes”, characterized by a low density region surrounded closely by much higher density regions. Such observations are occasionally referred to as “inliers” in the literature (for example, Talagala et al., 2021). As we relate distance based outliers to ...
work page 2021
-
[10]
Einmahl et al. (2010a) motivated the shorth plot in part by demonstrating the shortcomings of standard techniques like the histogram or kernel density estimation in distinguishing this density (and its antimode) from a standard normal density based on a random sample. Just as the DQF qx(δ) is related to the probability measure of an interval of size δ for...
work page 1974
-
[11]
This means that for small parameter values, both functions (in x) might be considered as some type of density estimator. However, neither of these approaches is to be understood as such. Indeed, particularly in high dimensions when the curse of dimensionality kicks in, we are aiming at extracting more structural information in the sense of feature extract...
work page 1963
-
[12]
that posits that the data often lives (at least approximately) on a manifold of much lower dimension than the d-dimensional ambient space. This fact is often exploited by dimension reduction algorithms, either linear (for instance, principal component analysis) or non-linear (for instance, Isomap by Tenenbaum, et al. 2000). Certainly an observation far in...
work page 2000
-
[13]
Considering the zero interval of the (a)DQFs means to look for “large distance gaps,” measured by δx,y (see Lemma 2.2). Of course, Lemma 2.1 also makes clear that δ small is related to the underlying density, resulting in somewhat of a unification of the two standard types of out- liers, those far from the bulk of the data and those lying in low-density r...
work page 2021
-
[14]
Finally, improved results were observed for the aDQF using a normal base distribution Gij versus a uniform. For instance, in the 6 dimensional subspace example, a uniform Gij with support proportional to the Windsorized standard deviation identified the outlier correctly only 46% of the time. 17 4.1.2 Real Data As a real data example, we consider the mult...
work page 2021
-
[15]
5” observations and the first 10 “9
The curvature of this manifold is seemingly the reason that the visual information in the non-adaptive DQF presented here is better than the aDQF. Next, we consider a data set of size n = 210, consisting of all “5” observations and the first 10 “9” observations. Based on the visually chosen 0.42 quantile, the area under the response operator curve (ROC AU...
work page 2017
-
[16]
18 Figure 10: Functional data example, raw data (inset) and normalized aDQF ˜ qi(δ)
Figure 10 shows both the raw data and the aDQF based L2-inner product. 18 Figure 10: Functional data example, raw data (inset) and normalized aDQF ˜ qi(δ). The anomaly (green) tends to decrease while the non-anomalous observations tend to increase. The other observation identified by the aDQF corresponds to the highest function. The second example is the ...
work page 2015
-
[17]
Figure 12: Normalized aDQFs ˜qi(δ) based on a kernel defined on persistence diagrams. Red lines correspond to 99 randomly generated districting maps via ReCom, green corresponds to 2011 map (pictured, source: https://ballotpedia.org/) invalidated by the Supreme Court in 2018 for partisan gerrymandering. 20 5 Implementation The computational complexity of ...
work page 2011
-
[18]
So, we have qx(δ) = 1 2 F [ax,δu, bx,δu] = 1 2 F [ax,δℓ, bx,δℓ] = 1 2 F ([a, a + δ])
In particular, x is the median for any interval [ a, b] with [ aδu, bδu] ⊂ [a, b] ⊂ [aδℓ, bδℓ]. So, we have qx(δ) = 1 2 F [ax,δu, bx,δu] = 1 2 F [ax,δℓ, bx,δℓ] = 1 2 F ([a, a + δ]). This completes the proof of (5). To see the last assertion of the lemma, observe that lim t↘0 Dx(t) = lx. (10) In particular, this implies that for x /∈ supp(F ), Dx(t) has a ...
work page 2013
-
[19]
(2006): Additive Outlier Detection Via Extreme-Value Theory
Burridge, P., and Taylor, R. (2006): Additive Outlier Detection Via Extreme-Value Theory. J. Time Ser. Anal
work page 2006
-
[20]
685-701. Chandler, G. and Polonik, W. (2021): Multiscale geometric feature extraction for high-dimensional and non-Euclidean data with applications. Ann. Statist. 49, 988-1010. Chazal, F. and Michel, B. (2021): An introduction to topological data analysis: fundamental and practical aspects for data scientists. Front. Artif. Intell. ,
work page 2021
-
[21]
DeFord, D., Duchin, M. and Solomon, J. (2021): Recombination: A Family of Markov Chains for Redistricting. Harvard Data Sci. Rev. 3.1 Duchin, M., and Needham, T. and Weighill, T. (2021): The (homological) persistence of gerryman- dering. Found. Data Sci. 10.3934/fods.2021007. Einmahl, J. H. J., Gantner, M., and Sawitzki, G. (2010a): The Shorth Plot. J. Co...
-
[22]
(1994): Diagnostic plots for one-dimensional data
Sawitzki, G. (1994): Diagnostic plots for one-dimensional data. In: Ostermann, R., Dirschedl, P. (Eds.), Computational Statistics, 25th Conference on Statistical Computing at Schloss Reisensburg. Physica-Verlag, Springer, Heidelberg, pp. 237–258. Talagala, P.D., Hyndman, R.J. and Smith-Miles, K. (2021): Anomaly Detection in High-Dimensional Data, J. Compu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.