Convergence of Policy Iteration for Entropy-Regularized Stochastic Control Problems
Pith reviewed 2026-05-24 11:23 UTC · model grok-4.3
The pith
A policy iteration algorithm converges to an optimal relaxed control for entropy-regularized stochastic control on infinite horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For a general entropy-regularized stochastic control problem on an infinite horizon, the policy iteration algorithm converges to an optimal relaxed control. This is achieved by moving between Hölder and Sobolev spaces to obtain a uniform Hölder bound on the generated value functions, using new Sobolev estimates designed for policy iteration and a method to contain entropy growth, even though standard Hölder estimates are insufficient.
What carries the argument
The policy iteration algorithm (PIA), whose convergence is secured by new Sobolev estimates tailored to the iteration and a technique that controls entropy growth to produce a uniform Hölder bound on value functions.
If this is right
- The value functions produced by the policy iteration algorithm remain uniformly bounded in the Hölder norm.
- Convergence holds to an optimal relaxed control for the entropy-regularized problem.
- The optimal value function is characterized as the unique solution to the exploratory Hamilton-Jacobi-Bellman equation.
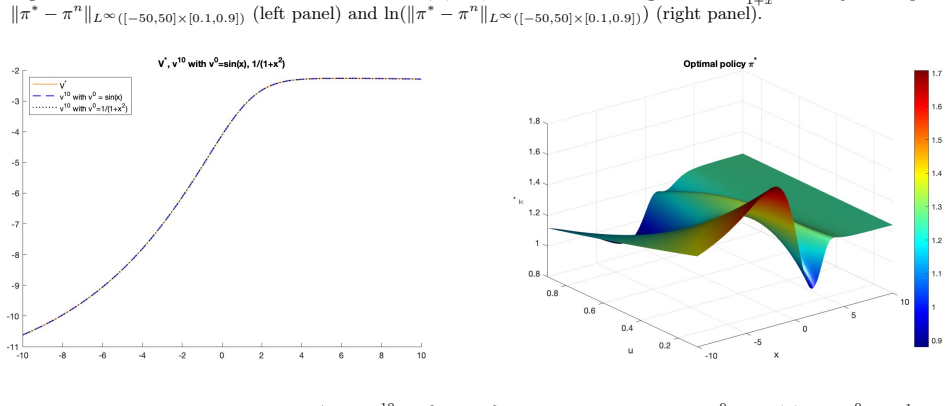
- The algorithm can be implemented numerically on concrete problems such as optimal consumption.
Where Pith is reading between the lines
- The same Sobolev estimates and entropy-control technique could be tested on finite-horizon versions of the problem.
- The method supplies a route to prove convergence for other regularized control problems where classical estimates break.
- Numerical stability of the policy iteration may improve in practice once the uniform Hölder bound is available.
Load-bearing premise
New Sobolev estimates designed for policy iteration, combined with a technique to contain entropy growth, produce a uniform Hölder bound on the sequence of value functions where classical estimates fail.
What would settle it
A concrete counter-example in which the sequence of value functions generated by the policy iteration algorithm fails to remain uniformly Hölder continuous, or in which the algorithm does not converge to the optimal relaxed control in the optimal consumption problem.
Figures
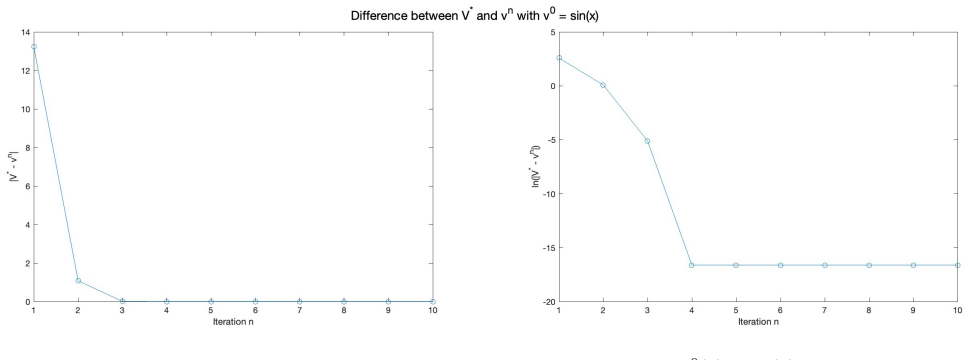
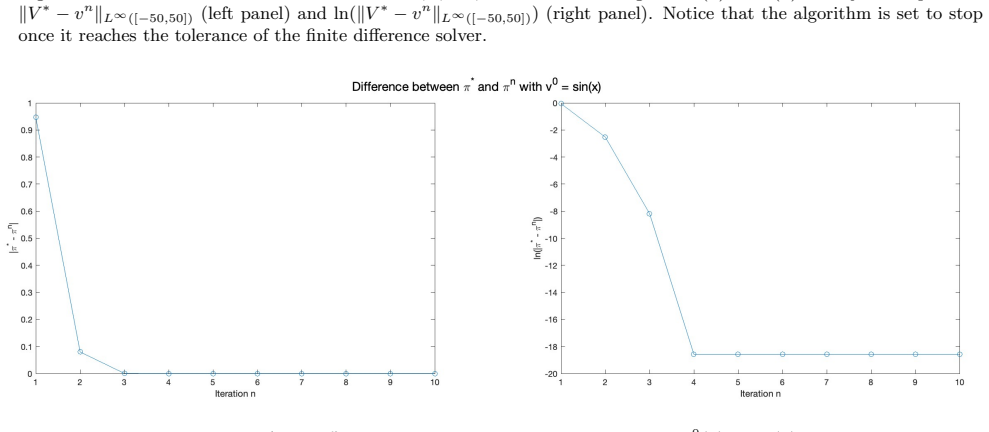
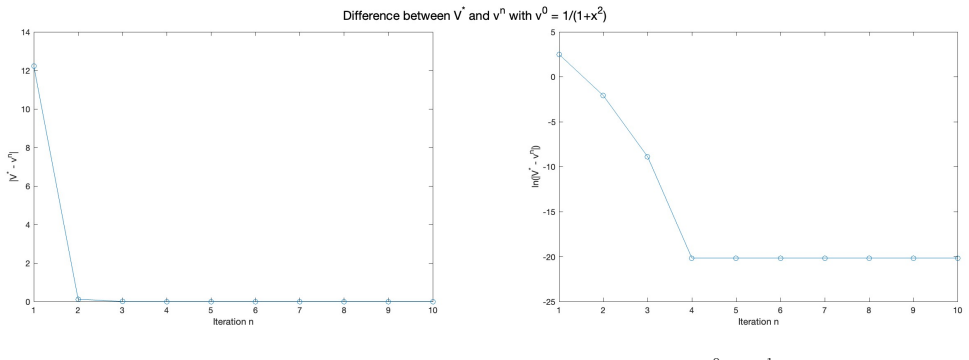
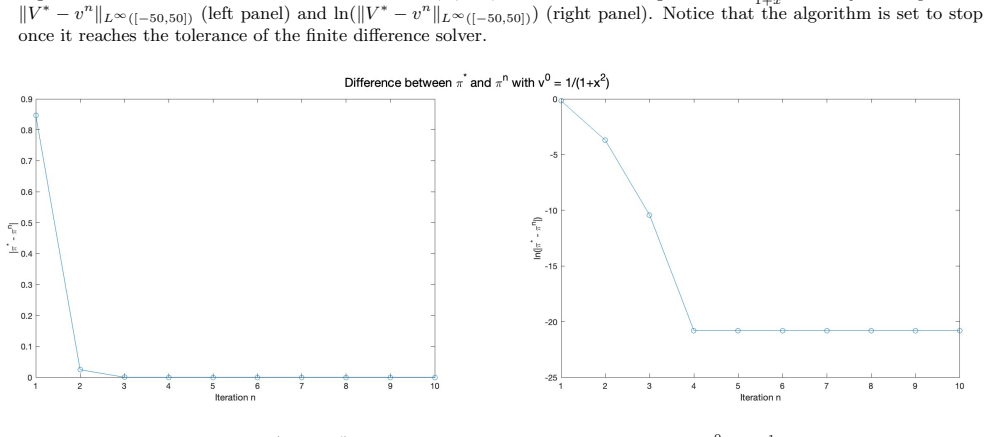
read the original abstract
For a general entropy-regularized stochastic control problem on an infinite horizon, we prove that a policy iteration algorithm (PIA) converges to an optimal relaxed control. Contrary to the standard stochastic control literature, classical H\"{o}lder estimates of value functions do not ensure the convergence of the PIA, due to the added entropy-regularizing term. To circumvent this, we carry out a delicate estimation by moving back and forth between appropriate H\"{o}lder and Sobolev spaces. This requires new Sobolev estimates designed specifically for the purpose of policy iteration and a nontrivial technique to contain the entropy growth. Ultimately, we obtain a uniform H\"{o}lder bound for the sequence of value functions generated by the PIA, thereby achieving the desired convergence result. Characterization of the optimal value function as the unique solution to an exploratory Hamilton-Jacobi-Bellman equation comes as a by-product. The PIA is numerically implemented in an example of optimal consumption.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves convergence of a policy iteration algorithm (PIA) to an optimal relaxed control for general entropy-regularized infinite-horizon stochastic control problems. Classical Hölder estimates on value functions fail due to the entropy term, so the authors derive new Sobolev estimates tailored to the PIA sequence together with an entropy-growth containment argument; these yield a uniform Hölder bound that permits extraction of a convergent subsequence whose limit is identified as optimal. As a byproduct the optimal value function is characterized as the unique solution of an exploratory Hamilton-Jacobi-Bellman equation. A numerical illustration is given for an optimal consumption problem.
Significance. The result supplies a rigorous convergence theory for policy iteration under entropy regularization, a setting that appears in robust control and reinforcement learning. The construction of Sobolev estimates specifically adapted to the policy-iteration iterates, together with the entropy-control technique that restores uniform Hölder regularity, constitutes a technical contribution that may be reusable in other regularized control problems where standard parabolic estimates are insufficient. The argument is a direct analytic proof with no free parameters, no circular definitions, and no fitted quantities.
minor comments (3)
- [Introduction] The introduction should list the precise standing assumptions on the drift, diffusion, running cost, and entropy parameter (including any growth or boundedness conditions) before the statement of the main theorem, so that the uniformity of the Hölder bound is immediately traceable to those hypotheses.
- [Exploratory HJB section] In the statement of the exploratory HJB equation, clarify whether the entropy term appears inside or outside the supremum and whether the equation is understood in the classical or viscosity sense; this affects the uniqueness claim.
- [Numerical section] The numerical example would benefit from a brief description of the discretization scheme used for the PIA and from reporting the observed convergence rate or residual norm, even if only qualitatively.
Simulated Author's Rebuttal
We thank the referee for their careful reading and positive recommendation to accept the manuscript. The report accurately captures the main contributions, including the novel Sobolev estimates adapted to the policy-iteration sequence and the entropy-growth control argument that restores uniform Hölder regularity.
Circularity Check
No significant circularity; derivation is self-contained analytic proof
full rationale
The paper establishes convergence of policy iteration via new Sobolev estimates and an entropy-growth containment argument that produce a uniform Hölder bound on value functions. These estimates are derived directly from the problem coefficients and entropy parameter under the standing assumptions; the limit identification and exploratory HJB characterization follow from the extracted convergent subsequence. No step reduces a claimed result to a quantity defined by the result itself, no fitted parameters are relabeled as predictions, and no load-bearing uniqueness is imported via self-citation. The argument is therefore independent of its own output.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard technical assumptions on the controlled diffusion and running cost that guarantee well-posedness of the entropy-regularized problem (e.g., Lipschitz continuity, linear growth).
Reference graph
Works this paper leans on
-
[1]
Ya-Zhe Chen and Lan-Cheng Wu. Second order elliptic equations and elliptic systems, volume 174 of Trans- lations of Mathematical Monographs . American Mathematical Society, Providence, RI, 1998. Translated from the 1991 Chinese original by Bei Hu
work page 1998
-
[2]
Learning equilibrium mean-variance strategy
Min Dai, Yuchao Dong, and Yanwei Jia. Learning equilibrium mean-variance strategy. Mathematical Finance, 33(4):1166–1212, 2023
work page 2023
-
[3]
Lawrence C. Evans. Partial differential equations, volume 19 ofGraduate Studies in Mathematics. American Mathematical Society, Providence, RI, 1998
work page 1998
-
[4]
Exploratory LQG mean field games with entropy regularization
Dena Firoozi and Sebastian Jaimungal. Exploratory LQG mean field games with entropy regularization. Automatica J. IFAC, 139:Paper No. 110177, 12, 2022
work page 2022
-
[5]
Taming the noise in reinforcement learning via soft updates
Roy Fox, Ari Pakman, and Naftali Tishby. Taming the noise in reinforcement learning via soft updates. In Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence, UAI 2016, June 25-29, 2016, New York City, NY, USA
work page 2016
- [6]
-
[7]
Entropy regularization for mean field games with learning
Xin Guo, Renyuan Xu, and Thaleia Zariphopoulou. Entropy regularization for mean field games with learning. Mathematics of Operations research, 47(4):3239–3260, 2022
work page 2022
-
[8]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 , volume 70, pages 1352–1361
work page 2017
-
[9]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm¨ assan, Stockholm, Sweden, July 10-15, 2018 , volume 80, pages 1856–1865
work page 2018
-
[10]
Jacka and Aleksandar Mijatovi´ c
Saul D. Jacka and Aleksandar Mijatovi´ c. On the policy improvement algorithm in continuous time.Stochas- tics, 89(1):348–359, 2017
work page 2017
-
[11]
E. T. Jaynes. Information theory and statistical mechanics. Phys. Rev. (2) , 106:620–630, 1957
work page 1957
-
[12]
E. T. Jaynes. Information theory and statistical mechanics. II. Phys. Rev. (2) , 108:171–190, 1957
work page 1957
-
[13]
Yanwei Jia and Xun Yu Zhou. q-learning in continuous time. Journal of Machine Learning Research , 24(161):1–61, 2023
work page 2023
-
[14]
Ioannis Karatzas and Steven E. Shreve. Brownian motion and stochastic calculus , volume 113 of Graduate Texts in Mathematics. Springer-Verlag, New York, second edition, 1991
work page 1991
-
[15]
B. Kerimkulov, D. ˇSiˇ ska, and L. Szpruch. A modified MSA for stochastic control problems. Appl. Math. Optim., 84(3):3417–3436, 2021. 31
work page 2021
-
[16]
Bekzhan Kerimkulov, David ˇSiˇ ska, and Lukasz Szpruch. Exponential convergence and stability of Howard’s policy improvement algorithm for controlled diffusions. SIAM J. Control Optim. , 58(3):1314–1340, 2020
work page 2020
-
[17]
Jaeyoung Lee and Richard S Sutton. Policy iterations for reinforcement learning problems in continuous time and space—fundamental theory and methods. Automatica, 126:109421, 2021
work page 2021
-
[18]
Value iteration in continuous actions, states and time
Michael Lutter, Shie Mannor, Jan Peters, Dieter Fox, and Animesh Garg. Value iteration in continuous actions, states and time. arXiv preprint arXiv:2105.04682 , 2021
-
[19]
Higher chain formula proved by combinatorics
Tsoy-Wo Ma. Higher chain formula proved by combinatorics. Electron. J. Combin., 16(1):Note 21, 7, 2009
work page 2009
-
[20]
M. L. Puterman. On the convergence of policy iteration for controlled diffusions. J. Optim. Theory Appl. , 33(1):137–144, 1981
work page 1981
-
[21]
Regularity and stability of feedback relaxed controls
Christoph Reisinger and Yufei Zhang. Regularity and stability of feedback relaxed controls. SIAM J. Control Optim., 59(5):3118–3151, 2021
work page 2021
-
[22]
C. E. Shannon. A mathematical theory of communication. Bell System Tech. J. , 27:379–423, 623–656, 1948
work page 1948
-
[23]
Policy iteration for the deterministic control problems–a viscosity approach
Wenpin Tang, Hung Vinh Tran, and Yuming Paul Zhang. Policy iteration for the deterministic control problems–a viscosity approach. arXiv preprint arXiv:2301.00419 , 2023
-
[24]
Exploratory hjb equations and their convergence
Wenpin Tang, Yuming Paul Zhang, and Xun Yu Zhou. Exploratory hjb equations and their convergence. SIAM Journal on Control and Optimization , 60(6):3191–3216, 2022
work page 2022
-
[25]
Brent A Wallace and Jennie Si. Continuous-time reinforcement learning control: A review of theoretical results, insights on performance, and needs for new designs. IEEE Transactions on Neural Networks and Learning Systems, 2023
work page 2023
-
[26]
Reinforcement learning in continuous time and space: a stochastic control approach
Haoran Wang, Thaleia Zariphopoulou, and Xun Yu Zhou. Reinforcement learning in continuous time and space: a stochastic control approach. J. Mach. Learn. Res. , 21:Paper No. 198, 34, 2020
work page 2020
-
[27]
Continuous-time mean-variance portfolio selection: a reinforcement learning framework
Haoran Wang and Xun Yu Zhou. Continuous-time mean-variance portfolio selection: a reinforcement learning framework. Math. Finance, 30(4):1273–1308, 2020
work page 2020
-
[28]
Brian D. Ziebart, J. Andrew Bagnell, and Anind K. Dey. Modeling interaction via the principle of maximum causal entropy. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), June 21-24, 2010, Haifa, Israel , pages 1255–1262
work page 2010
-
[29]
Brian D. Ziebart, Andrew L. Maas, J. Andrew Bagnell, and Anind K. Dey. Maximum entropy inverse reinforcement learning. In Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence, AAAI 2008, Chicago, Illinois, USA, July 13-17, 2008 , pages 1433–1438. 32
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.