Learning to Detect and Segment for Open Vocabulary Object Detection
Pith reviewed 2026-05-24 10:22 UTC · model grok-4.3
The pith
CondHead conditions box and mask prediction heads on semantic embeddings to generalize detection and segmentation to novel object categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CondHead is a conditional parameterization of the detection heads in which network parameters for box regression and mask segmentation are generated or aggregated from the semantic embedding supplied by a pretrained vision-language model. It consists of a dynamically aggregated head that combines multiple static expert heads and a dynamically generated head whose weights are produced on the fly from the class embedding. This bridges the semantic space directly to the spatial prediction tasks, allowing class-specific guidance for novel categories without retraining the backbone or heads on those categories.
What carries the argument
CondHead, a two-stream dynamic head architecture whose parameters are conditioned on semantic embeddings to produce class-specific box regression and mask segmentation.
If this is right
- The method raises novel-category detection AP by 3.0 points over a RegionClip baseline.
- The added computation is limited to 1.1 percent.
- Both box regression and mask segmentation benefit from the same conditional parameterization.
- The design applies on top of existing open-vocabulary detectors with only head-level changes.
Where Pith is reading between the lines
- The same conditioning principle could be tested on other spatial tasks such as keypoint estimation or depth prediction for open-vocabulary inputs.
- If the dynamic heads learn reusable expert behaviors, freezing the backbone and retraining only CondHead might suffice for new vocabularies.
- Performance gains may shrink when the vision-language model and the detection dataset have large domain mismatch.
Load-bearing premise
Semantic embeddings from the pretrained vision-language model carry enough class-specific visual detail to meaningfully improve bounding-box and mask predictions for categories absent from the detection training set.
What would settle it
On a held-out set of novel categories, replacing the CondHead with a standard class-agnostic head produces equal or higher AP while using the same embeddings and backbone.
Figures







read the original abstract
Open vocabulary object detection has been greatly advanced by the recent development of vision-language pretrained model, which helps recognize novel objects with only semantic categories. The prior works mainly focus on knowledge transferring to the object proposal classification and employ class-agnostic box and mask prediction. In this work, we propose CondHead, a principled dynamic network design to better generalize the box regression and mask segmentation for open vocabulary setting. The core idea is to conditionally parameterize the network heads on semantic embedding and thus the model is guided with class-specific knowledge to better detect novel categories. Specifically, CondHead is composed of two streams of network heads, the dynamically aggregated head and the dynamically generated head. The former is instantiated with a set of static heads that are conditionally aggregated, these heads are optimized as experts and are expected to learn sophisticated prediction. The latter is instantiated with dynamically generated parameters and encodes general class-specific information. With such a conditional design, the detection model is bridged by the semantic embedding to offer strongly generalizable class-wise box and mask prediction. Our method brings significant improvement to the state-of-the-art open vocabulary object detection methods with very minor overhead, e.g., it surpasses a RegionClip model by 3.0 detection AP on novel categories, with only 1.1% more computation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CondHead, a dynamic network architecture for open-vocabulary object detection consisting of a dynamically aggregated head and a dynamically generated head, both conditioned on semantic embeddings from pretrained vision-language models. This design aims to provide class-specific guidance for box regression and mask segmentation, enabling better generalization to novel categories. The authors report that their method surpasses RegionClip by 3.0 detection AP on novel categories with only 1.1% more computation.
Significance. If the empirical results hold, this work would be significant as it extends knowledge transfer in open-vocabulary detection from classification to the more challenging tasks of localization and segmentation. The conditional parameterization approach offers a principled way to incorporate class-specific information into the prediction heads, which could influence future designs in vision-language models for detection tasks.
major comments (1)
- [Abstract] Abstract: The central claim that CondHead improves box regression and mask segmentation for novel categories depends on semantic embeddings supplying sufficient geometric and spatial information. Since VL embeddings are optimized for semantic similarity rather than localization precision, the manuscript should provide evidence (such as separate ablation on regression and segmentation metrics for novel classes) to confirm that the dynamic heads deliver gains beyond classification transfer.
minor comments (1)
- The abstract mentions 'very minor overhead' and specific numbers like 3.0 AP and 1.1% computation; these should be supported with exact experimental setup details in the main text for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback on our manuscript. The suggestion to provide more targeted evidence for localization and segmentation gains is constructive, and we address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that CondHead improves box regression and mask segmentation for novel categories depends on semantic embeddings supplying sufficient geometric and spatial information. Since VL embeddings are optimized for semantic similarity rather than localization precision, the manuscript should provide evidence (such as separate ablation on regression and segmentation metrics for novel classes) to confirm that the dynamic heads deliver gains beyond classification transfer.
Authors: We agree that isolating the localization and segmentation contributions would strengthen the presentation. While the reported novel-category detection AP already incorporates localization quality (true positives require IoU thresholds), we will add explicit ablations in the revision: (1) box AP at stricter IoU thresholds (e.g., AP75) on novel classes, and (2) mask AP on novel classes when available in the benchmark. These will be compared against the class-agnostic baseline to quantify gains attributable to the conditional heads beyond classification transfer. The dynamic aggregation and generation streams are designed precisely to map semantic embeddings into class-specific geometric parameters; the new tables will make this mapping visible. revision: yes
Circularity Check
Empirical architecture proposal with no self-referential derivation
full rationale
The paper introduces CondHead as a dynamic network architecture that conditions box regression and mask segmentation heads on semantic embeddings from pretrained vision-language models. Its central claim is an empirical result: improved AP on novel categories with minor overhead compared to baselines such as RegionCLIP. No equations, uniqueness theorems, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce the claimed generalization to a definitional or statistical tautology. The method is presented as a design choice evaluated on external benchmarks, making the derivation chain self-contained and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ankan Bansal, Karan Sikka, Gaurav Sharma, Rama Chel- lappa, and Ajay Divakaran. Zero-shot object detection. In Proceedings of the European Conference on Computer Vi- sion (ECCV), pages 384–400, 2018. 1
work page 2018
-
[2]
Cascade r-cnn: Delv- ing into high quality object detection
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delv- ing into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 6154–6162, 2018. 2
work page 2018
-
[3]
End- to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End- to-end object detection with transformers. arXiv preprint arXiv:2005.12872, 2020. 2, 3
-
[4]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedan- tam, Saurabh Gupta, Piotr Doll ´ar, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015. 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Dynamic convolution: Attention over convolution kernels
Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: Attention over convolution kernels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11030–11039, 2020. 2, 3, 5
work page 2020
-
[6]
Deformable convolutional networks
Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei. Deformable convolutional networks. In Proceedings of the IEEE international confer- ence on computer vision, pages 764–773, 2017. 2, 3
work page 2017
-
[7]
Learning to prompt for open-vocabulary ob- ject detection with vision-language model
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open-vocabulary ob- ject detection with vision-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14084–14093, 2022. 1, 2, 3
work page 2022
-
[8]
The pascal visual object classes (voc) challenge
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010. 5
work page 2010
-
[9]
Open vocabulary object detection with pseudo bounding-box labels
Mingfei Gao, Chen Xing, Juan Carlos Niebles, Junnan Li, Ran Xu, Wenhao Liu, and Caiming Xiong. Open vocabulary object detection with pseudo bounding-box labels. 1, 3
-
[10]
Ross Girshick. Fast r-cnn. In Proceedings of the IEEE inter- national conference on computer vision , pages 1440–1448,
-
[11]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. arXiv preprint arXiv:2104.13921 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
LVIS: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A dataset for large vocabulary instance segmentation. InCVPR,
-
[13]
Learning to segment every thing
Ronghang Hu, Piotr Doll ´ar, Kaiming He, Trevor Darrell, and Ross Girshick. Learning to segment every thing. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4233–4241, 2018. 5, 10
work page 2018
-
[14]
Open-vocabulary instance segmentation via ro- bust cross-modal pseudo-labeling
Dat Huynh, Jason Kuen, Zhe Lin, Jiuxiang Gu, and Ehsan Elhamifar. Open-vocabulary instance segmentation via ro- bust cross-modal pseudo-labeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7031, 2022. 1, 3
work page 2022
-
[15]
Max Jaderberg, Karen Simonyan, Andrew Zisserman, et al. Spatial transformer networks. Advances in neural informa- tion processing systems, 28, 2015. 2, 3
work page 2015
-
[16]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. In International Conference on Machine Learning, pages 4904–4916. PMLR,
-
[17]
Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc V Gool. Dynamic filter networks. Advances in neural informa- tion processing systems, 29, 2016. 2, 3
work page 2016
-
[18]
Shapemask: Learning to segment novel objects by refining shape priors
Weicheng Kuo, Anelia Angelova, Jitendra Malik, and Tsung-Yi Lin. Shapemask: Learning to segment novel objects by refining shape priors. In Proceedings of the IEEE/CVF international conference on computer vision , pages 9207–9216, 2019. 5, 8, 10
work page 2019
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision , pages 740–755. Springer, 2014. 2, 5
work page 2014
-
[20]
Ssd: Single shot multibox detector
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In European con- ference on computer vision, pages 21–37. Springer, 2016. 2
work page 2016
-
[21]
Simple open-vocabulary object detection with vision transformers
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, et al. Simple open-vocabulary object detection with vision transformers. arXiv preprint arXiv:2205.06230, 2022. 1, 3
-
[22]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. In International Conference on Machine Learning , pages 8748–8763. PMLR, 2021. 1, 3, 5
work page 2021
-
[23]
Improved visual-semantic alignment for zero-shot object detection
Shafin Rahman, Salman Khan, and Nick Barnes. Improved visual-semantic alignment for zero-shot object detection. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 34, pages 11932–11939, 2020. 1, 6
work page 2020
-
[24]
You only look once: Unified, real-time object de- tection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object de- tection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016. 2
work page 2016
-
[25]
Yolo9000: better, faster, stronger
Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. arXiv preprint, 2017. 2
work page 2017
-
[26]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information pro- cessing systems, pages 91–99, 2015. 2, 3
work page 2015
-
[27]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. In Pro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 8430–8439, 2019. 5 9
work page 2019
-
[28]
Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning
Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, im- age alt-text dataset for automatic image captioning. In Pro- ceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 2556–2565, 2018. 3
work page 2018
-
[29]
Condconv: Conditionally parameterized convolu- tions for efficient inference
Brandon Yang, Gabriel Bender, Quoc V Le, and Jiquan Ngiam. Condconv: Conditionally parameterized convolu- tions for efficient inference. Advances in Neural Information Processing Systems, 32, 2019. 2, 3, 5
work page 2019
-
[30]
Open-vocabulary detr with conditional matching
Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Open-vocabulary detr with conditional matching. arXiv preprint arXiv:2203.11876, 2022. 1, 3
-
[31]
Open-vocabulary object detection using captions
Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih- Fu Chang. Open-vocabulary object detection using captions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14393–14402, 2021. 1, 2, 3, 5, 6
work page 2021
-
[32]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16793–16803, 2022. 1, 2, 3, 5, 6
work page 2022
-
[33]
Learning to prompt for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models. In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[34]
Don’t even look once: Synthesizing features for zero-shot detection
Pengkai Zhu, Hanxiao Wang, and Venkatesh Saligrama. Don’t even look once: Synthesizing features for zero-shot detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 11693– 11702, 2020. 6
work page 2020
-
[35]
De- formable convnets v2: More deformable, better results
Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. De- formable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 9308–9316, 2019. 3
work page 2019
-
[36]
Deformable detr: Deformable transformers for end-to-end object detection
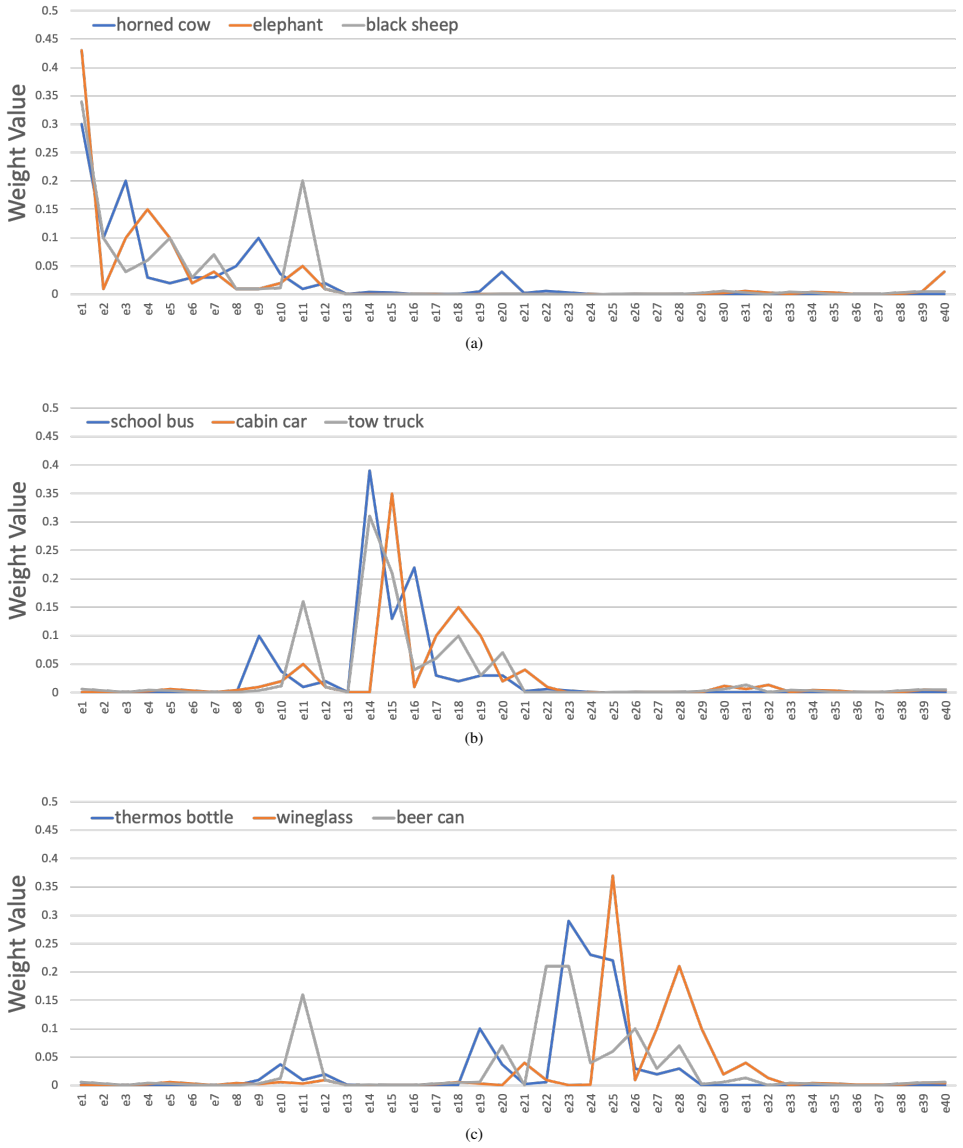
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. The International Confer- ence on Learning Representations, 2020. 2 Example Aggregation Weights To analyze how CondHead learns to consolidate the class-wise knowledge into the expert prediction heads, we plot th...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.