Subspace-Guided Feature Reconstruction for Unsupervised Anomaly Localization
Pith reviewed 2026-05-24 06:43 UTC · model grok-4.3
The pith
Subspace-guided feature reconstruction using self-expressive linear combinations of subspace basis vectors allows adaptive approximation of target features for anomaly localization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
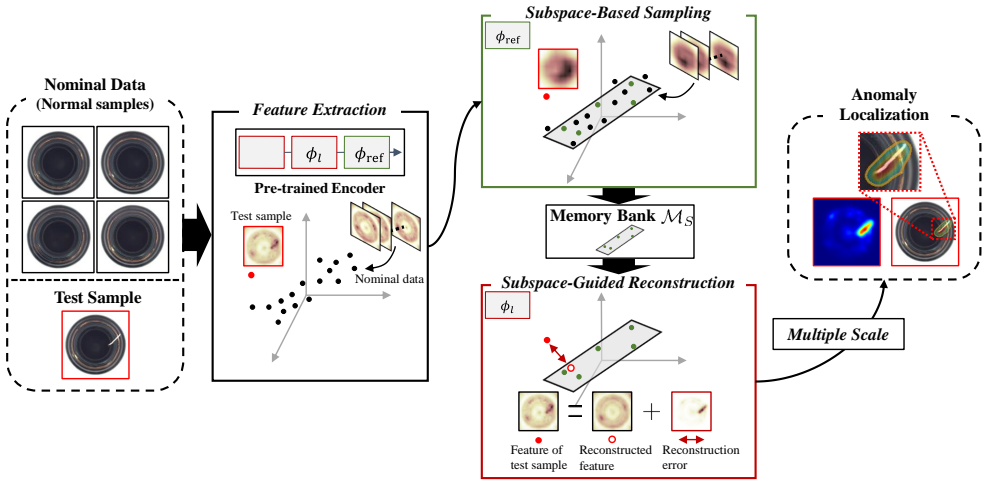
Despite the limited resources in the memory bank, out-of-bank features can be alternatively mimicked to adaptively model the target by learning to construct low-dimensional subspaces from the given nominal samples, and then reconstructing the given deep target embedding by linearly combining the subspace basis vectors using the self-expressive model.
What carries the argument
Self-expressive model for linearly combining subspace basis vectors learned from nominal samples to reconstruct target embeddings.
If this is right
- Achieves state-of-the-art anomaly localization performance on three benchmark datasets.
- Allows adaptive modeling of out-of-bank features for robustness to unseen targets.
- Enables feature reconstruction depending only on a small resource subset via sparsity sampling, reducing memory overhead.
Where Pith is reading between the lines
- The linear nature of the reconstruction might limit performance on highly nonlinear anomaly patterns not captured by subspaces.
- This framework could be tested in other memory-constrained settings like edge device anomaly detection.
- Extending the subspace learning to incorporate nonlinear bases could be a natural next step if linear combinations prove insufficient.
Load-bearing premise
Low-dimensional subspaces from a finite set of nominal samples can reliably approximate unseen target embeddings through linear self-expressive combinations, even when memory bank resources are limited.
What would settle it
Observing significantly worse performance than competing methods on a benchmark dataset featuring anomalies that require nonlinear feature relationships beyond linear subspace combinations.
Figures



read the original abstract
Unsupervised anomaly localization aims to identify anomalous regions that deviate from normal sample patterns. Most recent methods perform feature matching or reconstruction for the target sample with pre-trained deep neural networks. However, they still struggle to address challenging anomalies because the deep embeddings stored in the memory bank can be less powerful and informative. Specifically, prior methods often overly rely on the finite resources stored in the memory bank, which leads to low robustness to unseen targets. In this paper, we propose a novel subspace-guided feature reconstruction framework to pursue adaptive feature approximation for anomaly localization. It first learns to construct low-dimensional subspaces from the given nominal samples, and then learns to reconstruct the given deep target embedding by linearly combining the subspace basis vectors using the self-expressive model. Our core is that, despite the limited resources in the memory bank, the out-of-bank features can be alternatively ``mimicked'' to adaptively model the target. Moreover, we propose a sampling method that leverages the sparsity of subspaces and allows the feature reconstruction to depend only on a small resource subset, contributing to less memory overhead. Extensive experiments on three benchmark datasets demonstrate that our approach generally achieves state-of-the-art anomaly localization performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a subspace-guided feature reconstruction framework for unsupervised anomaly localization in images. It learns low-dimensional subspaces from nominal deep features extracted by a pre-trained CNN, then reconstructs target embeddings via self-expressive linear combinations of subspace basis vectors. This is intended to adaptively model out-of-bank normal features despite limited memory-bank resources. A sparsity-aware sampling method is introduced to reduce memory overhead. Experiments on three standard benchmarks (MVTec AD, BTAD, and one additional) report state-of-the-art or competitive pixel- and image-level AUROC and PRO scores compared to prior memory-bank and reconstruction baselines.
Significance. If the empirical gains hold under the reported conditions, the work offers a practical way to improve robustness of memory-bank anomaly detectors without increasing bank size, by leveraging the self-expressive property of subspaces. The sampling contribution directly addresses a common deployment constraint (memory footprint). No machine-checked proofs or parameter-free derivations are present, but the method is grounded in standard linear-algebra tools and evaluated on reproducible public datasets.
major comments (3)
- [§3.2] §3.2, Eq. (4)–(6): the reconstruction objective minimizes a self-expressive loss over the learned subspace basis, yet no analysis or bound is given on the approximation error when the target embedding lies outside the span of the finite nominal samples; this directly underpins the central claim of robustness to unseen normal features.
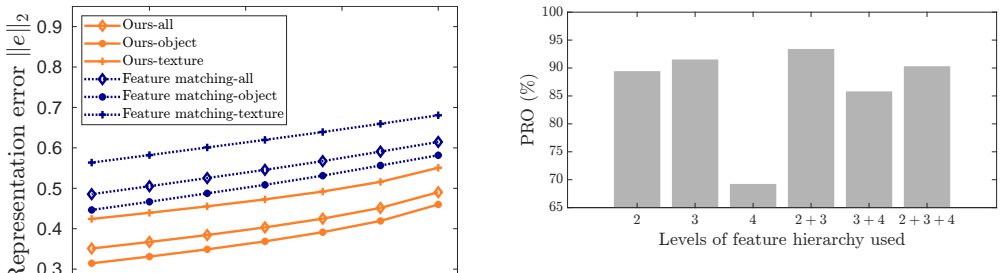
- [§4.3] §4.3, Table 3 (MVTec pixel-level results): the reported gains over PatchCore and similar memory-bank baselines are shown without standard deviations across multiple runs or seeds, and without an ablation isolating the contribution of the subspace dimension k versus the sampling ratio; this weakens the claim that the subspace mechanism itself drives the improvement.
- [§3.3] §3.3: the sparsity-based sampling selects a subset of basis vectors according to the coefficient sparsity pattern, but the paper provides no guarantee or empirical check that the selected subset still spans a subspace sufficient to reconstruct held-out normal samples from the same distribution.
minor comments (3)
- [§3.1] The notation for the memory bank and subspace matrix is introduced inconsistently between §3.1 and the algorithm box; a single consistent symbol table would improve readability.
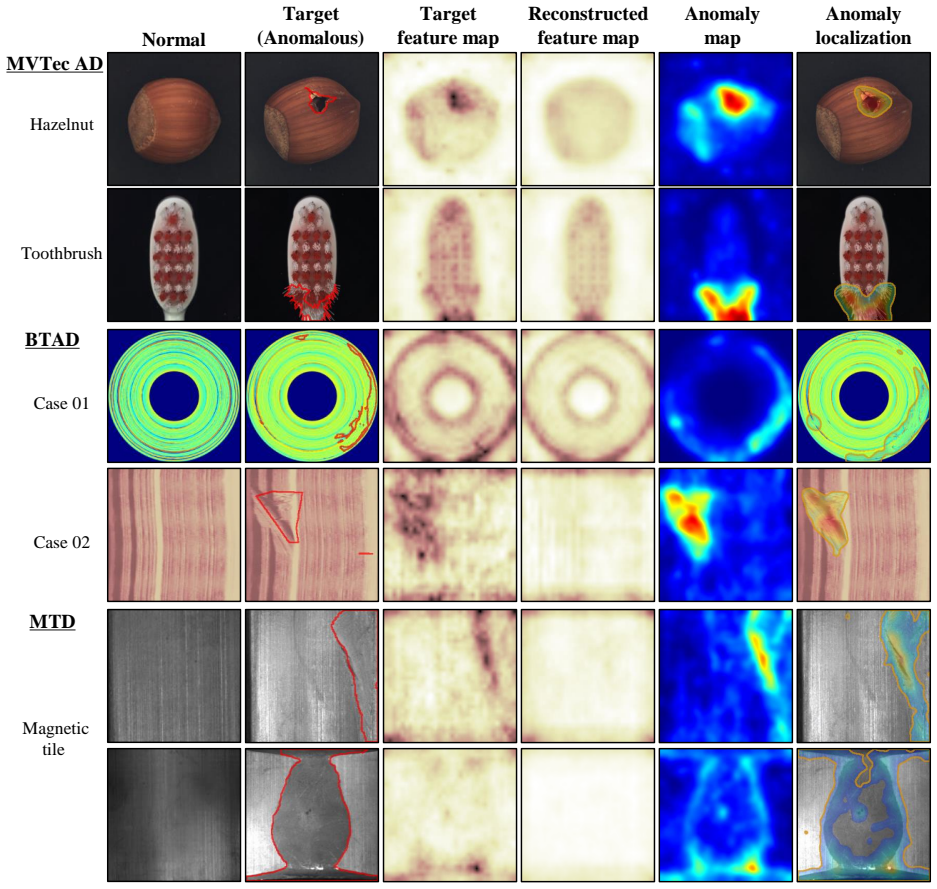
- [Figure 4] Figure 4 (qualitative results) lacks a failure-case example where the subspace reconstruction produces a false positive; including one would help readers assess the method’s limitations.
- [Abstract] The abstract states “generally achieves state-of-the-art,” yet the tables show occasional second-place results; the text should qualify this phrasing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below with specific plans for the revised manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (4)–(6): the reconstruction objective minimizes a self-expressive loss over the learned subspace basis, yet no analysis or bound is given on the approximation error when the target embedding lies outside the span of the finite nominal samples; this directly underpins the central claim of robustness to unseen normal features.
Authors: We agree that no theoretical bound on approximation error for embeddings outside the learned subspace span is provided. The approach builds on the established property that deep features from nominal samples admit low-dimensional subspace approximations (as in subspace clustering literature), enabling self-expressive reconstruction of similar unseen normals. In revision we will add an empirical section quantifying reconstruction error on held-out normal samples from the same distribution, showing low error consistent with the robustness claim. A rigorous bound would require distributional assumptions outside the paper's scope. revision: partial
-
Referee: [§4.3] §4.3, Table 3 (MVTec pixel-level results): the reported gains over PatchCore and similar memory-bank baselines are shown without standard deviations across multiple runs or seeds, and without an ablation isolating the contribution of the subspace dimension k versus the sampling ratio; this weakens the claim that the subspace mechanism itself drives the improvement.
Authors: We accept this point. The revised manuscript will include standard deviations computed over multiple random seeds for all reported AUROC/PRO scores in Table 3. We will also add a dedicated ablation table that varies subspace dimension k and sampling ratio independently while holding other factors fixed, to isolate the subspace contribution. revision: yes
-
Referee: [§3.3] §3.3: the sparsity-based sampling selects a subset of basis vectors according to the coefficient sparsity pattern, but the paper provides no guarantee or empirical check that the selected subset still spans a subspace sufficient to reconstruct held-out normal samples from the same distribution.
Authors: We will incorporate an empirical check in the revision. Using the same held-out normal validation split, we will report reconstruction error and downstream anomaly localization metrics when using the sparsity-selected subset versus the full basis, demonstrating that the selected subset preserves sufficient span for in-distribution reconstruction with negligible degradation. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper applies standard subspace learning and self-expressive linear reconstruction to pre-trained CNN embeddings for anomaly localization. The core steps—constructing low-dimensional subspaces from nominal samples then approximating targets via linear combinations—are direct applications of known linear algebra (self-expressive models) without reducing any claimed result to a fitted input renamed as prediction, a self-citation chain, or a definitional tautology. Performance claims rest on external benchmark comparisons rather than internal construction. No load-bearing self-citations or smuggled ansatzes appear in the abstract or described method.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Low-dimensional subspaces can be constructed from nominal samples to capture normal patterns
- domain assumption Target embeddings can be reconstructed as linear combinations of subspace basis vectors
Reference graph
Works this paper leans on
-
[1]
Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection,
P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Mvtec ad–a comprehensive real-world dataset for unsupervised anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9592–9600
work page 2019
-
[2]
P. Bergmann, K. Batzner, M. Fauser, D. Sattlegger, and C. Steger, “Be- yond dents and scratches: Logical constraints in unsupervised anomaly detection and localization,” International Journal of Computer Vision , vol. 130, no. 4, pp. 947–969, 2022
work page 2022
-
[3]
Spot-the- difference self-supervised pre-training for anomaly detection and seg- mentation,
Y . Zou, J. Jeong, L. Pemula, D. Zhang, and O. Dabeer, “Spot-the- difference self-supervised pre-training for anomaly detection and seg- mentation,” in European Conference on Computer Vision . Springer, 2022, pp. 392–408
work page 2022
-
[4]
Anomaly detection and localization in crowded scenes,
W. Li, V . Mahadevan, and N. Vasconcelos, “Anomaly detection and localization in crowded scenes,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 36, no. 1, pp. 18–32, 2013
work page 2013
-
[5]
Future frame prediction for anomaly detection–a new baseline,
W. Liu, W. Luo, D. Lian, and S. Gao, “Future frame prediction for anomaly detection–a new baseline,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2018, pp. 6536–6545
work page 2018
-
[6]
Unsupervised anomaly detection in images using attentional normalizing flows,
X. Wu, G. Mao, and S. Xing, “Unsupervised anomaly detection in images using attentional normalizing flows,” Engineering Applications of Artificial Intelligence , vol. 127, p. 107369, 2024
work page 2024
-
[7]
Anomaly detection via reverse distillation from one-class embedding,
H. Deng and X. Li, “Anomaly detection via reverse distillation from one-class embedding,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2022, pp. 9737–9746
work page 2022
-
[8]
Simplenet: A simple network for image anomaly detection and localization,
Z. Liu, Y . Zhou, Y . Xu, and Z. Wang, “Simplenet: A simple network for image anomaly detection and localization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2023, pp. 20 402–20 411
work page 2023
-
[9]
Ima- genet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Ima- genet: A large-scale hierarchical image database,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2009, pp. 248–255
work page 2009
-
[10]
Sub-image anomaly detection with deep pyramid correspondences,
N. Cohen and Y . Hoshen, “Sub-image anomaly detection with deep pyramid correspondences,” CoRR, vol. abs/2005.02357, 2020
-
[11]
Towards total recall in industrial anomaly detection,
K. Roth, L. Pemula, J. Zepeda, B. Sch ¨olkopf, T. Brox, and P. Gehler, “Towards total recall in industrial anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 318–14 328
work page 2022
-
[12]
Mbmf: Constructing memory banks of multi-scale features for anomaly detection,
Y . Sun, H. Wang, Y . Hu, H. Jiang, and B. Yin, “Mbmf: Constructing memory banks of multi-scale features for anomaly detection,” IET Computer Vision, 2023
work page 2023
-
[13]
Cfa: Coupled-hypersphere-based fea- ture adaptation for target-oriented anomaly localization,
S. Lee, S. Lee, and B. C. Song, “Cfa: Coupled-hypersphere-based fea- ture adaptation for target-oriented anomaly localization,” IEEE Access, vol. 10, pp. 78 446–78 454, 2022
work page 2022
-
[14]
A geometric framework for unsupervised anomaly detection: Detecting intrusions in unlabeled data,
E. Eskin, A. Arnold, M. Prerau, L. Portnoy, and S. Stolfo, “A geometric framework for unsupervised anomaly detection: Detecting intrusions in unlabeled data,” Applications of Data Mining in Computer Security , pp. 77–101, 2002
work page 2002
-
[15]
Geometric ap- proximation via coresets,
P. K. Agarwal, S. Har-Peled, K. R. Varadarajan et al. , “Geometric ap- proximation via coresets,” Combinatorial and Computational Geometry, vol. 52, no. 1, pp. 1–30, 2005
work page 2005
-
[16]
Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
P. Bergmann, S. L ¨owe, M. Fauser, D. Sattlegger, and C. Steger, “Improv- ing unsupervised defect segmentation by applying structural similarity to autoencoders,” CoRR, vol. abs/1807.02011, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
Dfr: Deep feature reconstruction for unsupervised anomaly segmentation,
J. Yang, Y . Shi, and Z. Qi, “Dfr: Deep feature reconstruction for unsupervised anomaly segmentation,” CoRR, vol. abs/2012.07122, 2020
-
[18]
Component-based nearest neighbour subspace clustering,
K. Hotta, H. Xie, and C. Zhang, “Component-based nearest neighbour subspace clustering,” IET Image Processing, vol. 16, no. 10, pp. 2697– 2708, 2022
work page 2022
-
[19]
Pmssc: Parallelizable multi-subset based self-expressive model for subspace clustering,
K. Hotta, T. Akashi, S. Tokai, and C. Zhang, “Pmssc: Parallelizable multi-subset based self-expressive model for subspace clustering,” Com- putational Visual Media , vol. 9, no. 3, pp. 479–494, 2023
work page 2023
-
[20]
Sparse subspace clustering: Algorithm, theory, and applications,
E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory, and applications,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 11, pp. 2765–2781, 2013
work page 2013
-
[21]
D. L. Donoho, “For most large underdetermined systems of linear equations the minimal ℓ1-norm solution is also the sparsest solution,” Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , vol. 59, no. 6, pp. 797–829, 2006
work page 2006
-
[22]
R. de Paula Monteiro, M. C. Lozada, D. R. C. Mendieta, R. V . S. Loja, and C. J. A. Bastos Filho, “A hybrid prototype selection-based deep learning approach for anomaly detection in industrial machines,” Expert Systems with Applications , vol. 204, p. 117528, 2022
work page 2022
-
[23]
Deep nearest neighbor anomaly detection,
L. Bergman, N. Cohen, and Y . Hoshen, “Deep nearest neighbor anomaly detection,” CoRR, vol. abs/2002.10445, 2020
-
[24]
Fully convo- lutional cross-scale-flows for image-based defect detection,
M. Rudolph, T. Wehrbein, B. Rosenhahn, and B. Wandt, “Fully convo- lutional cross-scale-flows for image-based defect detection,” in Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2022, pp. 1088–1097
work page 2022
-
[25]
Ganomaly: Semi- supervised anomaly detection via adversarial training,
S. Akcay, A. Atapour-Abarghouei, and T. P. Breckon, “Ganomaly: Semi- supervised anomaly detection via adversarial training,” in Proceedings of the Asian Conference on Computer Vision . Springer, 2019, pp. 622– 637
work page 2019
-
[26]
Skip-ganomaly: Skip connected and adversarially trained encoder-decoder anomaly de- tection,
S. Akc ¸ay, A. Atapour-Abarghouei, and T. P. Breckon, “Skip-ganomaly: Skip connected and adversarially trained encoder-decoder anomaly de- tection,” in 2019 International Joint Conference on Neural Networks (IJCNN). IEEE, 2019, pp. 1–8
work page 2019
-
[27]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” in Proceedings of the International Conference on Learning Representa- tions, 2014
work page 2014
-
[28]
Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings,
P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Uninformed students: Student-teacher anomaly detection with discriminative latent embeddings,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2020, pp. 4183–4192
work page 2020
-
[29]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” CoRR, vol. abs/1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[30]
Student-teacher feature pyramid matching for anomaly detection,
G. Wang, S. Han, E. Ding, and D. Huang, “Student-teacher feature pyramid matching for anomaly detection,” in Proceedings of the British Machine Vision Conference, 2021
work page 2021
-
[31]
Dsr–a dual subspace re- projection network for surface anomaly detection,
V . Zavrtanik, M. Kristan, and D. Sko ˇcaj, “Dsr–a dual subspace re- projection network for surface anomaly detection,” in European Con- ference on Computer Vision . Springer, 2022, pp. 539–554
work page 2022
-
[32]
Padim: a patch dis- tribution modeling framework for anomaly detection and localization,
T. Defard, A. Setkov, A. Loesch, and R. Audigier, “Padim: a patch dis- tribution modeling framework for anomaly detection and localization,” in International Conference on Pattern Recognition . Springer, 2021, pp. 475–489
work page 2021
-
[33]
On the generalized distance in statistics,
P. C. Mahalanobis, “On the generalized distance in statistics,” Sankhy¯a: The Indian Journal of Statistics, Series A (2008-) , vol. 80, pp. S1–S7, 2018
work page 2008
-
[34]
R. Vidal, “Subspace clustering,” IEEE Signal Processing Magazine , vol. 28, no. 2, pp. 52–68, 2011
work page 2011
-
[35]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2016, pp. 770–778
work page 2016
-
[36]
Geometric conditions for subspace-sparse re- covery,
C. You and R. Vidal, “Geometric conditions for subspace-sparse re- covery,” in International Conference on Machine Learning , 2015, pp. 1585–1593
work page 2015
-
[37]
Scalable sparse subspace clustering by orthogonal matching pursuit,
C. You, D. Robinson, and R. Vidal, “Scalable sparse subspace clustering by orthogonal matching pursuit,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2016, pp. 3918–3927
work page 2016
-
[38]
Y . C. Pati, R. Rezaiifar, and P. S. Krishnaprasad, “Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition,” in Proceedings of Asilomar Conference on Signals, Systems and Computers , 1993, pp. 40–44
work page 1993
-
[39]
Greed is good: Algorithmic results for sparse approxima- tion,
J. A. Tropp, “Greed is good: Algorithmic results for sparse approxima- tion,” IEEE Transactions on Information Theory , vol. 50, no. 10, pp. 2231–2242, 2004
work page 2004
-
[40]
Analysis of orthogonal matching pursuit using the restricted isometry property,
M. A. Davenport and M. B. Wakin, “Analysis of orthogonal matching pursuit using the restricted isometry property,” IEEE Transactions on Information Theory, vol. 56, no. 9, pp. 4395–4401, 2010
work page 2010
-
[41]
Reconstruction by inpainting for visual anomaly detection,
V . Zavrtanik, M. Kristan, and D. Sko ˇcaj, “Reconstruction by inpainting for visual anomaly detection,” Pattern Recognition, vol. 112, p. 107706, 2021
work page 2021
-
[42]
Vt- adl: A vision transformer network for image anomaly detection and localization,
P. Mishra, R. Verk, D. Fornasier, C. Piciarelli, and G. L. Foresti, “Vt- adl: A vision transformer network for image anomaly detection and localization,” in Proceedings of the IEEE 30th International Symposium on Industrial Electronics (ISIE) . IEEE, 2021, pp. 01–06. 10
work page 2021
-
[43]
Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows,
J. Yu, Y . Zheng, X. Wang, W. Li, Y . Wu, R. Zhao, and L. Wu, “Fastflow: Unsupervised anomaly detection and localization via 2d normalizing flows,” CoRR, vol. abs/2111.07677, 2021
-
[44]
Surface defect saliency of magnetic tile,
Y . Huang, C. Qiu, and K. Yuan, “Surface defect saliency of magnetic tile,” The Visual Computer , vol. 36, pp. 85–96, 2020
work page 2020
-
[45]
S. Zagoruyko and N. Komodakis, “Wide residual networks,” in Proceed- ings of the British Machine Vision Conference , 2016, pp. 87.1–87.12
work page 2016
-
[46]
Same same but differnet: Semi-supervised defect detection with normalizing flows,
M. Rudolph, B. Wandt, and B. Rosenhahn, “Same same but differnet: Semi-supervised defect detection with normalizing flows,” in Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1907–1916. 11
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.