Towards Load-Aware Prefill Deflection for Disaggregated LLM Serving
Pith reviewed 2026-07-03 06:02 UTC · model grok-4.3
The pith
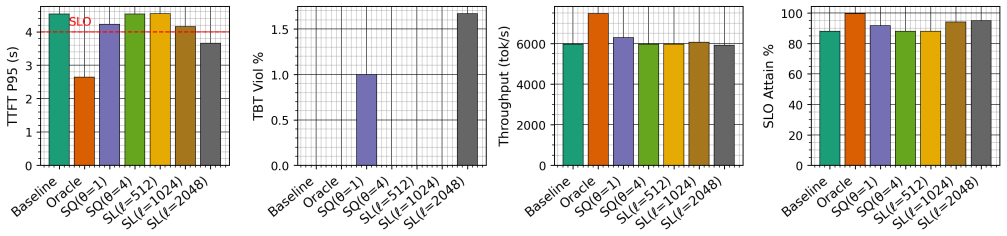
A load-aware scheduler deflects prefill chunks to decode nodes to cut P95 TTFT by up to 81% while eliminating KV transfers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
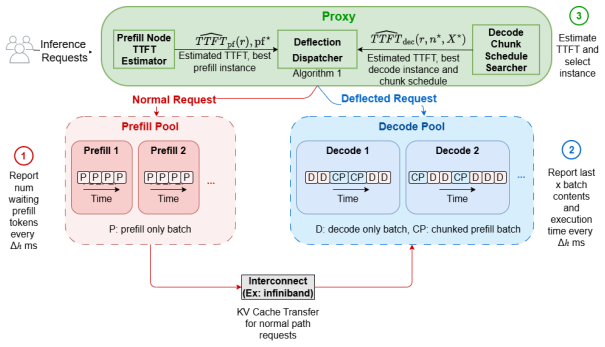
For each queued request the scheduler estimates the TTFT it would see on the prefill node; on every decode node it searches for the largest chunk schedule that keeps in-flight decodes inside their TBT SLO and deflects when the decode path yields lower tail latency. Because the prefill phase then executes in place on the decode node, the inter-node KV-cache transfer is eliminated entirely.
What carries the argument
The proactive prefill-deflecting scheduler that estimates TTFT on prefill nodes and searches largest feasible chunk schedules on decode nodes to decide deflection.
If this is right
- KV-cache transfers between prefill and decode nodes are removed for every deflected request.
- Prefill execution time shrinks from the dominant fraction of tail TTFT to a small fraction under bursty loads.
- Decode nodes absorb prefill work while still meeting TBT SLOs for their existing decode batches.
- The approach delivers its gains on real production-style traces with models such as DeepSeek-V2-Lite.
- Per-request routing decisions remain under one millisecond.
Where Pith is reading between the lines
- Hardware provisioning could shift toward fewer prefill nodes if deflection reliably balances load.
- The interleaving technique may combine with dynamic batch sizing or other decode-side optimizations.
- In very large clusters the per-request search over decode nodes may need approximation to stay sub-millisecond.
- Strict phase separation may be less necessary than assumed once deflection is available.
Load-bearing premise
The TTFT estimates and chunk-schedule searches on decode nodes accurately predict whether deflection will keep in-flight decodes inside their TBT SLO.
What would settle it
A production trace run in which deflection decisions cause measured TBT to exceed the SLO for decode requests, or in which P95 TTFT shows no improvement over the non-deflecting baseline.
Figures

read the original abstract
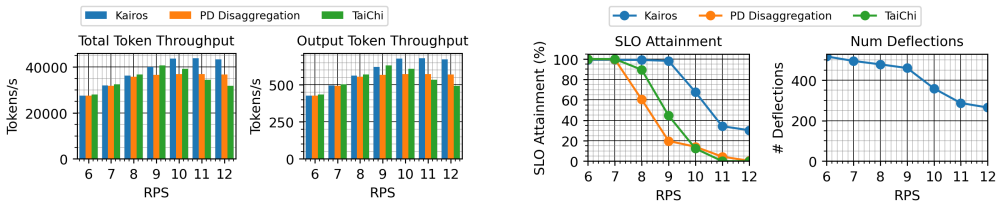
Disaggregated LLM serving runs prefill and decode on separate GPU pools to keep the two phases from interfering. In practice, this creates a new asymmetry: under bursty, heavy-tailed workloads prefill nodes saturate while decode nodes have compute underutilized, and on a production-style A100 cluster with 2 prefill and 2 decode nodes (2P2D), we find that prefill execution accounts for only 2-23% of P95 Time-to-First-Token (TTFT). Queuing and inter-node GPU-GPU KV-cache transfer account for the rest. We present a proactive prefill-deflecting scheduler that lets decode nodes serve prefill phase of requests as chunked-prefill steps interleaved with their in-flight decode batches. For each queued request, we estimate the TTFT it would see on the prefill node, and on every decode node, search for the largest chunk schedule that keeps in-flight decodes within their Time-Between-Tokens (TBT) SLO and deflect when the decode path helps tail latency. Because the prefill phase of deflected requests runs in place on the decode node, the inter-node KV transfer is eliminated. Implemented on vLLM and evaluated on production-style traces with DeepSeek-V2-Lite, our approach reduces P95 TTFT by upto 81% and raises SLO attainment by upto 79% over state-of-the-art disaggregated schedulers, at sub-millisecond per-request routing cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a load-aware prefill deflection scheduler for disaggregated LLM serving. Decode nodes perform chunked prefill interleaved with in-flight decodes for selected requests; TTFT is estimated per queued request on the prefill node and a largest-chunk search is performed on each decode node to keep TBT within SLO. Deflection eliminates inter-node KV transfer. Implemented in vLLM and evaluated on production-style traces with DeepSeek-V2-Lite on a 2P2D A100 cluster, the approach reports up to 81% reduction in P95 TTFT and up to 79% improvement in SLO attainment at sub-millisecond routing cost.
Significance. If the TTFT estimator and chunk-search procedure are shown to accurately predict TBT compliance on the evaluated traces without post-hoc tuning, the work would demonstrate a practical way to exploit decode-node underutilization under bursty workloads while removing KV-transfer overhead, which is a concrete contribution to disaggregated serving systems.
major comments (2)
- [Abstract / method description] Abstract and method description: the TTFT estimator for queued requests and the procedure for searching the largest chunk schedule on decode nodes are not described (analytic model, learned predictor, or otherwise), nor is any validation provided that the predictions match observed TBT outcomes on the production traces. This is load-bearing for the central claim, because the reported 81% P95 TTFT reduction and 79% SLO gain are attributed to proactive deflection that keeps in-flight decodes inside their TBT SLO.
- [Evaluation] Evaluation section: the abstract reports large gains but supplies no information on error bars, number of runs, data exclusion criteria, or how the production-style traces were selected or pre-processed. Without these, it is impossible to assess whether the improvements are robust or trace-specific.
minor comments (1)
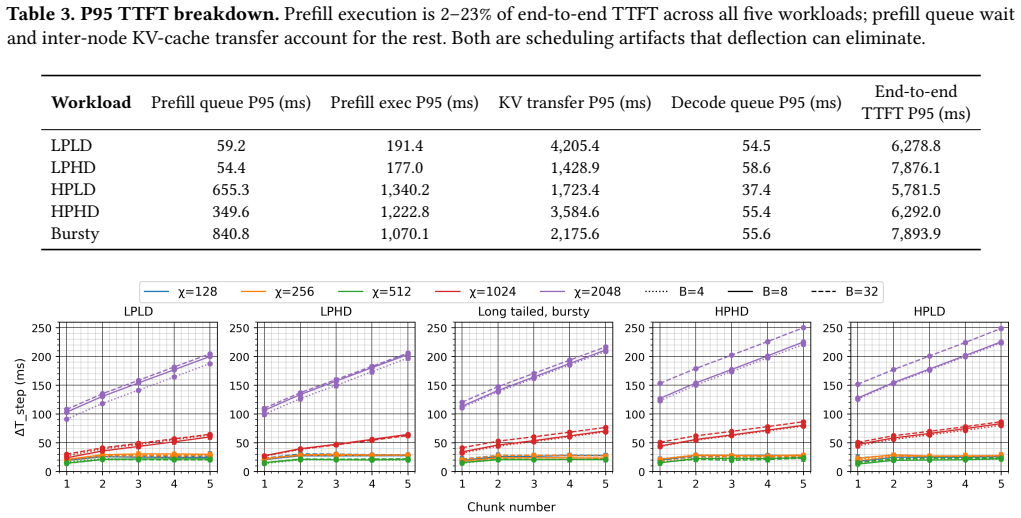
- [Abstract] The claim that prefill execution accounts for only 2-23% of P95 TTFT should be supported by a specific figure or table showing the breakdown across the evaluated traces.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater clarity on the TTFT estimator, chunk-search procedure, and evaluation methodology. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / method description] Abstract and method description: the TTFT estimator for queued requests and the procedure for searching the largest chunk schedule on decode nodes are not described (analytic model, learned predictor, or otherwise), nor is any validation provided that the predictions match observed TBT outcomes on the production traces. This is load-bearing for the central claim, because the reported 81% P95 TTFT reduction and 79% SLO gain are attributed to proactive deflection that keeps in-flight decodes inside their TBT SLO.
Authors: We agree that the abstract and high-level method overview do not provide sufficient detail on these components. The full paper describes the TTFT estimator as an analytic model that combines estimated prefill execution time (based on token count and model parameters) with current queue wait time on the prefill node, and the chunk search as an iterative greedy procedure that tests decreasing chunk sizes until the predicted TBT for in-flight decodes remains under the SLO. However, these elements require expansion for clarity. In the revised manuscript we will add pseudocode for the search algorithm in the method section, a dedicated subsection on the analytic model, and empirical validation results (e.g., prediction error distribution and correlation with measured TBT) on the production traces to confirm the estimator's accuracy without post-hoc tuning. revision: yes
-
Referee: [Evaluation] Evaluation section: the abstract reports large gains but supplies no information on error bars, number of runs, data exclusion criteria, or how the production-style traces were selected or pre-processed. Without these, it is impossible to assess whether the improvements are robust or trace-specific.
Authors: We concur that the evaluation section lacks these reproducibility details. The experiments were run on five independent repetitions of each trace with results reported as means; traces were selected from internal production logs exhibiting bursty, heavy-tailed request patterns and pre-processed only by rate normalization to match the target load; no data points were excluded. In the revised manuscript we will add a dedicated experimental setup subsection that explicitly states the number of runs, reports error bars as standard deviation, describes trace selection criteria and pre-processing steps, and confirms the absence of exclusion criteria. This will allow readers to assess robustness across the evaluated workloads. revision: yes
Circularity Check
No significant circularity; evaluation relies on external traces and prior schedulers
full rationale
The paper presents a proactive prefill-deflecting scheduler whose core mechanism (TTFT estimation per queued request plus per-decode-node chunk search) is described at a high level in the abstract and full text but is never reduced to an equation, fitted parameter, or self-citation chain that would make the reported gains tautological. No derivation steps, uniqueness theorems, or ansatzes appear; the 81 % P95 TTFT and 79 % SLO claims are obtained by direct comparison against external production-style traces and state-of-the-art baselines on vLLM with DeepSeek-V2-Lite, rendering the result independent of any self-defined quantities.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Bursty heavy-tailed workloads cause prefill nodes to saturate while decode nodes remain underutilized
- domain assumption Inter-node GPU-GPU KV-cache transfer and queuing dominate TTFT beyond the prefill execution itself
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
2024
-
[2]
Amey Agrawal, Haoran Qiu, Junda Chen, Íñigo Goiri, Chaojie Zhang, Rayyan Shahid, Ramachandran Ramjee, Alexey Tumanov, and Esha Choukse. 2024. Medha: Efficiently serving multi-million context length LLM inference requests without approximations.arXiv preprint arXiv:2409.17264(2024)
-
[3]
Yukang Chen, Weihao Cui, Han Zhao, Ziyi Xu, Xiaoze Fan, Xusheng Chen, Yangjie Zhou, Shixuan Sun, Bingsheng He, and Quan Chen. 2026. Towards High-Goodput LLM Serving with Prefill-decode Multiplexing. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 2030–2047
2026
-
[4]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[5]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems35 (2022), 16344–16359
2022
-
[6]
DeepSeek-AI. 2024. DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model. arXiv:2405.04434 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Cunchen Hu, Heyang Huang, Liangliang Xu, Xusheng Chen, Jiang Xu, Shuang Chen, Hao Feng, Chenxi Wang, Sa Wang, Yungang Bao, et al
- [8]
-
[9]
Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ra- machandran Ramjee, and Ashish Panwar. 2025. Pod-attention: Unlock- ing full prefill-decode overlap for faster llm inference. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 897–912
2025
-
[10]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[11]
InProceedings of the 29th symposium on operating systems principles
Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[12]
Zongze Li, Jingyu Liu, Zach Xu, Yineng Zhang, Tahseen Rabbani, and Ce Zhang. 2026. Not All Prefills Are Equal: PPD Disaggregation for Multi-turn LLM Serving.arXiv preprint arXiv:2603.13358(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
2025.https://learn.microsoft.com/en-us/azure/machine- learning/how-to-create-attach-compute-cluster?view=azureml-api- 2&tabs=pythonAzure Machine Learning Compute Cluster
Microsoft. 2025.https://learn.microsoft.com/en-us/azure/machine- learning/how-to-create-attach-compute-cluster?view=azureml-api- 2&tabs=pythonAzure Machine Learning Compute Cluster
2025
-
[14]
2026.https://learn.microsoft.com/en-us/azure/virtual- network/accelerated-networking-overviewAzure Accelerated Networking
Microsoft. 2026.https://learn.microsoft.com/en-us/azure/virtual- network/accelerated-networking-overviewAzure Accelerated Networking
2026
-
[15]
2026.https://docs.dynamo.nvidia.com/dynamo/dev/user- guides/disaggregated-serving#kv-transfer-is-the-critical-pathNvidia Dynamo Documentation
NVIDIA. 2026.https://docs.dynamo.nvidia.com/dynamo/dev/user- guides/disaggregated-serving#kv-transfer-is-the-critical-pathNvidia Dynamo Documentation
2026
-
[16]
2026.https://docs.nvidia.com/dynamo/getting-started/quic kstartNvidia Dynamo Documentation
NVIDIA. 2026.https://docs.nvidia.com/dynamo/getting-started/quic kstartNvidia Dynamo Documentation
2026
-
[17]
2026.https://network.nvidia.com/pdf/whitepapers/IB_Intr o_WP_190.pdfNvidia InfiniBand
NVIDIA. 2026.https://network.nvidia.com/pdf/whitepapers/IB_Intr o_WP_190.pdfNvidia InfiniBand
2026
-
[18]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 118–132
2024
-
[19]
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Heyi Tang, Feng Ren, Teng Ma, Shangming Cai, Yineng Zhang, Mingxing Zhang, et al. 2024. Mooncake: A kvcache-centric disaggregated architecture for llm serv- ing.ACM Transactions on Storage(2024)
2024
- [20]
- [21]
-
[22]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. 2025. Flashinfer: Efficient and customizable atten- tion engine for llm inference serving.arXiv preprint arXiv:2501.01005 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. 2024. Sglang: Efficient execution of structured lan- guage model programs.Advances in neural information processing systems37 (2024), 62557–62583
2024
-
[24]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.