MINCE: Shrinking LLM Evaluation Datasets via Few-Model Monte Carlo Calibration
Pith reviewed 2026-06-26 08:50 UTC · model grok-4.3
The pith
MINCE uses Monte Carlo simulation on few calibration models to shrink LLM evaluation datasets by 54-89% while bounding accuracy drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
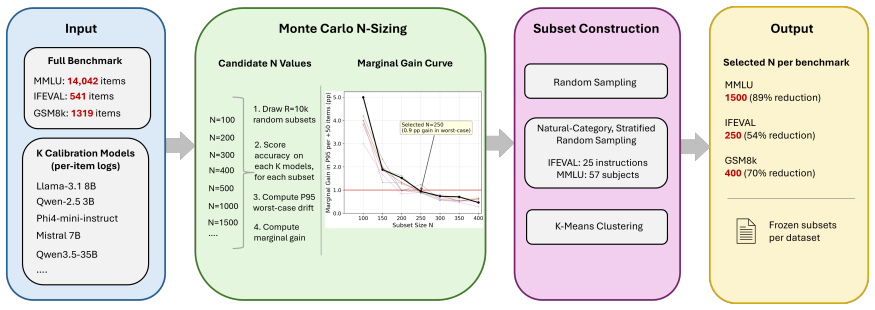
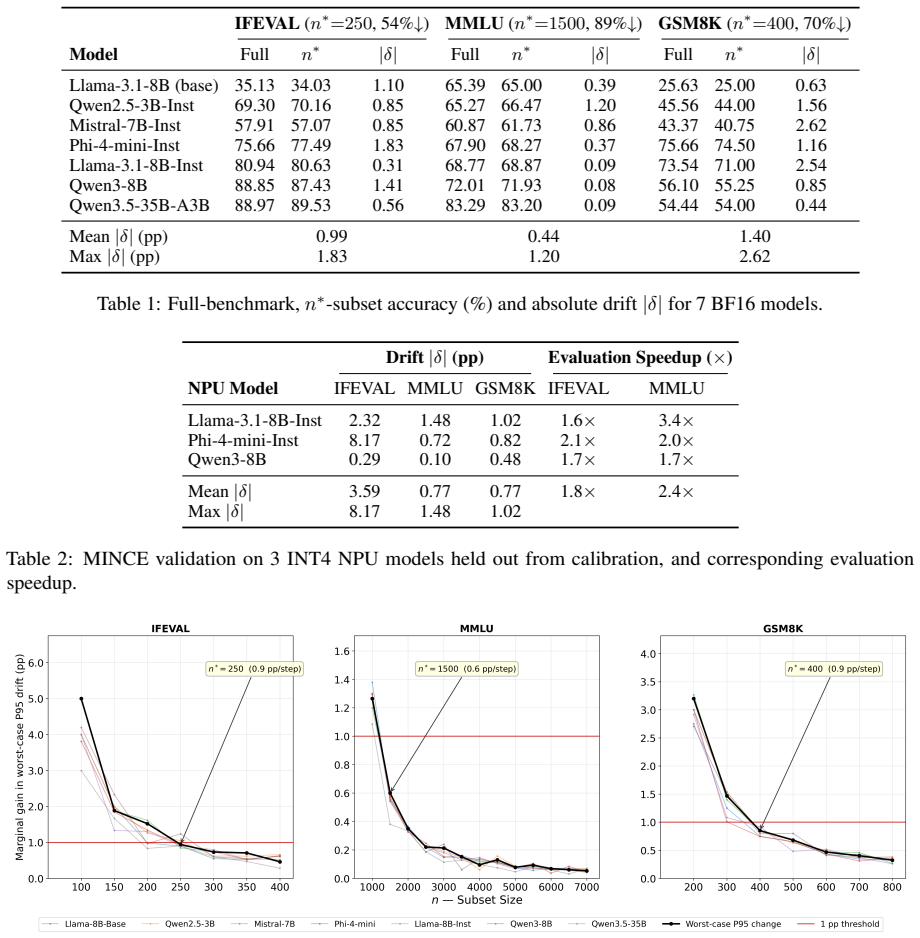
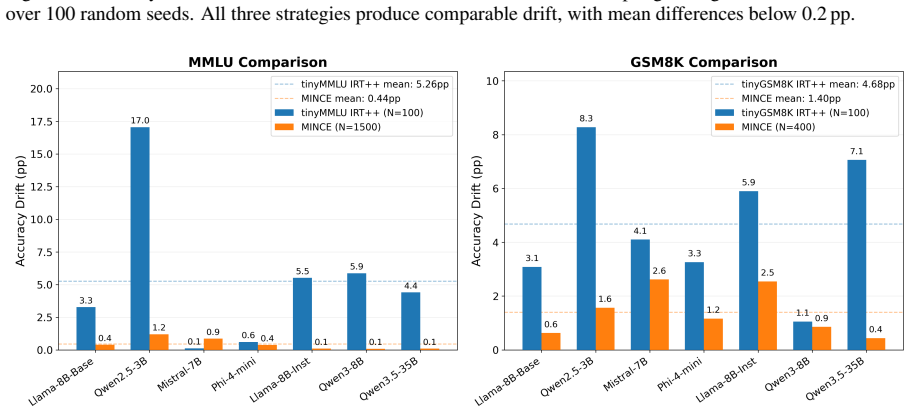
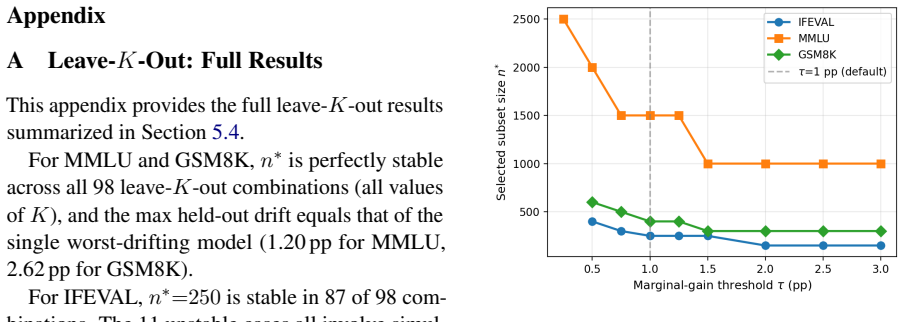
MINCE determines the minimum subset size via Monte Carlo simulation on per-item logs from a small calibration pool to guarantee bounded accuracy drift, then uses a fixed random sample of that size for evaluation, achieving reductions of 54% on IFEVAL, 89% on MMLU, and 70% on GSM8K with maximum drift of 2.62 percentage points on BF16 models and mean drifts of 0.77-3.59 on NPU models, along with speedups of 2.7-8.1x on GPU and 1.7-2.0x on NPU, while being robust to pool size and using far fewer calibration models than alternatives.
What carries the argument
Monte Carlo simulation over per-item correctness logs from a small set of calibration models to compute the minimum subset size bounding accuracy drift.
If this is right
- Evaluation time for model variants drops by factors of 2-8x on both GPU and NPU hardware.
- Accuracy drift stays at or below 2.62 pp on the tested model classes when the computed size is used.
- The same subset works across quantization levels and fine-tunes once the size is fixed.
- Drift remains lower than tinyBenchmarks even though 57x fewer calibration models are needed.
- Performance is stable across different sizes of the calibration pool.
Where Pith is reading between the lines
- The same Monte Carlo sizing step could be applied to other instruction-following or reasoning benchmarks not examined here.
- Running the calibration step once per hardware class might let teams maintain separate compact subsets for CPU, GPU, and NPU deployments.
- If the representativeness assumption weakens for very different model families, the method could be extended with a small per-family recalibration step.
Load-bearing premise
Per-item correctness logs from a small calibration set of models are sufficiently representative that Monte Carlo simulation can reliably set a subset size guaranteeing low drift for arbitrary new models and hardware.
What would settle it
A held-out model whose accuracy on the MINCE-chosen subset drifts more than the bound computed from the calibration logs.
Figures
read the original abstract
Evaluating LLMs across many model variants -- quantized, fine-tuned, or deployment-specific -- requires running large benchmarks repeatedly, a process that can take tens of hours per model on edge hardware such as NPUs. Existing subset selection methods reduce this cost but depend on large calibration pools or learned prediction layers. We introduce MINCE (Monte Carlo Informed N-sizing for Compact Evaluation), which uses Monte Carlo simulation over per-item logs from a small set of calibration models to find the minimum subset size that bounds accuracy drift and then fixes a randomly sampled subset at that size, with no prediction layer needed. MINCE reduces IFEVAL by 54\%, MMLU by 89\%, and GSM8K by 70\% with maximum drift $\leq$2.62\,pp on BF16 models and mean drift of 0.77--3.59\,pp on held-out NPU models, while delivering median GPU evaluation speedups of 2.7--8.1$\times$ and NPU evaluation speedups of 1.7--2.0$\times$. The method is robust to calibration pool size and achieves lower drift than tinyBenchmarks (12$\times$ lower on MMLU, 3.3$\times$ on GSM8K) while using 57$\times$ fewer calibration models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MINCE, which performs Monte Carlo simulation on per-item correctness logs collected from a small calibration pool of models to determine the smallest fixed subset size that bounds accuracy drift on benchmarks (IFEVAL, MMLU, GSM8K), then draws one such subset without any learned predictor. It reports concrete reductions (54% IFEVAL, 89% MMLU, 70% GSM8K) together with maximum drift ≤2.62 pp on BF16 models and mean drift 0.77–3.59 pp on held-out NPU models, plus median speedups of 2.7–8.1 imes (GPU) and 1.7–2.0 imes (NPU), while claiming robustness to pool size and superiority to tinyBenchmarks with 57 imes fewer calibration models.
Significance. If the Monte Carlo calibration procedure and its generalization claims are shown to be statistically sound, the work would provide a lightweight, prediction-layer-free route to compact evaluation sets that could materially reduce repeated benchmarking costs on edge hardware; the reported factor-of-57 reduction in calibration models relative to prior subset methods would be a notable practical advantage.
major comments (3)
- [Abstract] Abstract and method description: the concrete drift bounds (≤2.62 pp max, 0.77–3.59 pp mean) and subset-size claims are stated without any description of the Monte Carlo procedure itself (number of draws, how tail probabilities are estimated, or the precise stopping rule that converts simulated drift into a size guarantee), rendering the numerical results unverifiable from the given information.
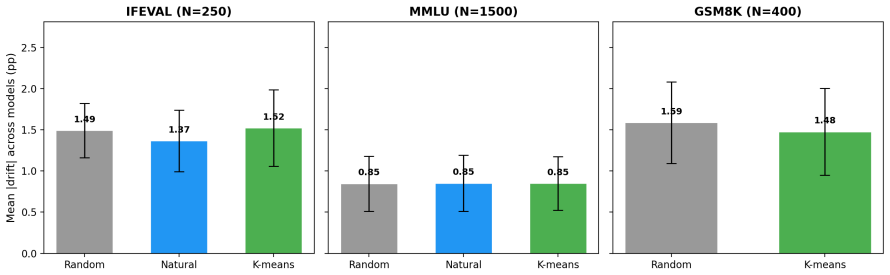
- [Method / Calibration pool] § on calibration and held-out evaluation: the central assumption that per-item correctness logs from the small calibration pool are representative of arbitrary future models is asserted but not supported by any diversity argument, coverage test, or worst-case analysis; if a held-out model exhibits different item-wise error correlations (different architecture, quantization, or fine-tuning), the simulated size may fail to bound empirical drift.
- [Experiments / Comparison] Results tables comparing to tinyBenchmarks: the reported 12 imes and 3.3 imes lower drift figures are presented without the exact calibration-pool sizes, number of Monte Carlo trials, or variance estimates used for the comparison, so it is impossible to assess whether the superiority claim is load-bearing or sensitive to those choices.
minor comments (2)
- [Notation] Notation for percentage-point drift and speedup factors is used inconsistently between abstract and later sections; a single definition table would improve clarity.
- [Experimental setup] The manuscript does not state the exact number of calibration models or the identity of the held-out NPU models, which are needed to reproduce the robustness-to-pool-size experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies important areas for improving clarity and supporting claims. We address each major comment below, proposing specific revisions to the manuscript where details are missing or assumptions require further elaboration.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the concrete drift bounds (≤2.62 pp max, 0.77–3.59 pp mean) and subset-size claims are stated without any description of the Monte Carlo procedure itself (number of draws, how tail probabilities are estimated, or the precise stopping rule that converts simulated drift into a size guarantee), rendering the numerical results unverifiable from the given information.
Authors: We agree that the Monte Carlo procedure requires explicit description to ensure verifiability. In the revised manuscript we will expand the Method section to specify: 10,000 Monte Carlo draws per size trial, empirical quantile estimation for tail probabilities, and the stopping rule that selects the smallest size guaranteeing the target drift bound holds in at least 95% of simulated trials. Corresponding details will also be added to the abstract for completeness. revision: yes
-
Referee: [Method / Calibration pool] § on calibration and held-out evaluation: the central assumption that per-item correctness logs from the small calibration pool are representative of arbitrary future models is asserted but not supported by any diversity argument, coverage test, or worst-case analysis; if a held-out model exhibits different item-wise error correlations (different architecture, quantization, or fine-tuning), the simulated size may fail to bound empirical drift.
Authors: The assumption receives empirical support from the held-out NPU evaluations showing low drift. We will add a subsection describing the calibration pool's composition (models spanning multiple families, bit-widths, and fine-tuning regimes) together with a simple coverage check on error-pattern diversity. A formal worst-case analysis lies outside the paper's scope; we will instead note this as a limitation and emphasize that the method's practical utility is demonstrated by the reported held-out results rather than claimed as universally guaranteed. revision: partial
-
Referee: [Experiments / Comparison] Results tables comparing to tinyBenchmarks: the reported 12× and 3.3× lower drift figures are presented without the exact calibration-pool sizes, number of Monte Carlo trials, or variance estimates used for the comparison, so it is impossible to assess whether the superiority claim is load-bearing or sensitive to those choices.
Authors: We acknowledge that these experimental details are necessary for assessing the comparison. The revised version will report the precise calibration-pool sizes (5 models for MINCE), the number of Monte Carlo trials (10,000), and standard-error estimates or confidence intervals on the drift values. These additions will allow readers to evaluate sensitivity and the robustness of the superiority claim. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives subset sizes and drift bounds via Monte Carlo simulation performed exclusively on per-item correctness logs from a separate calibration pool of models. These logs are distinct from the held-out BF16 and NPU models used to report empirical drift (≤2.62 pp max, 0.77–3.59 pp mean). The final subset is fixed by random sampling at the simulated size; no parameters are fitted to the held-out results, and no self-citation, uniqueness theorem, or ansatz is invoked to justify the bounds. The comparison to tinyBenchmarks is an external empirical benchmark. The derivation chain is therefore self-contained and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Balinski and H
Michel L. Balinski and H. Peyton Young. 2010. Fair Representation: Meeting the Ideal of One Man, One Vote, 2nd edition. Brookings Institution Press
2010
-
[3]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O'Brien, and 1 others. 2024. https://doi.org/10.5281/zenodo.10256836 A framework for few-shot language model evaluation
-
[5]
William G. Cochran. 1977. Sampling Techniques, 3rd edition. John Wiley & Sons
1977
-
[6]
Cl\' e mentine Fourrier, Nathan Habib, Thomas Wolf, and Lewis Tunstall. 2024. Open LLM leaderboard. Hugging Face
2024
-
[7]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, and 1 others. 2024. The L lama 3 herd of models. arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[8]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. In Proceedings of the International Conference on Learning Representations
2021
-
[9]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, and 1 others. 2023. Mistral 7 B . arXiv preprint arXiv:2310.06825
Pith/arXiv arXiv 2023
-
[10]
Schulze Buschoff, and 1 others
Alex Kipnis, Konstantinos Voudouris, Luca M. Schulze Buschoff, and 1 others. 2025. metabench -- a sparse benchmark of reasoning and knowledge in large language models. In Proceedings of the 13th International Conference on Learning Representations
2025
-
[11]
Yotam Perlitz, Elron Bandel, Ariel Gera, Ofir Arviv, Michal Shlain, Michal Shmueli-Scheuer, Leshem Choshen, Noam Slonim, and Dafna Sheinwald. 2024. Efficient benchmarking (of language models). In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics
2024
-
[12]
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. 2024. tiny B enchmarks: evaluating LLM s with fewer examples. In Proceedings of the 41st International Conference on Machine Learning
2024
-
[13]
Vijay Janapa Reddi, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, Maximilien Breeskin, Mark Bughici, Ciro Cebo, and 1 others. 2020. MLPerf inference benchmark. Proceedings of the ACM/IEEE International Symposium on Computer Architecture (ISCA)
2020
-
[14]
Rubinstein and Dirk P
Reuven Y. Rubinstein and Dirk P. Kroese. 2008. Simulation and the M onte C arlo Method , 2nd edition. John Wiley & Sons
2008
-
[15]
Shaobo Wang, Cong Wang, Wenjie Fu, Yue Min, Mingquan Feng, Isabel Guan, Xuming Hu, Conghui He, Cunxiang Wang, Kexin Yang, Xingzhang Ren, Fei Huang, Dayiheng Liu, and Linfeng Zhang. 2026. Rethinking LLM evaluation: Can we evaluate LLM s with 200 less data? In Proceedings of the 14th International Conference on Learning Representations
2026
-
[17]
Peiwen Yuan, Yueqi Zhang, Shaoxiong Feng, Yiwei Li, Xinglin Wang, Jiayi Shi, Chuyi Tan, Boyuan Pan, Yao Hu, and Kan Li. 2025. Beyond one-size-fits-all: Tailored benchmarks for efficient evaluation. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics
2025
-
[18]
Taolin Zhang, Hang Guo, Wang Lu, Tao Dai, Shu-Tao Xia, and Jindong Wang. 2026. Sparse E val: Efficient evaluation of large language models by sparse optimization. In Proceedings of the 14th International Conference on Learning Representations
2026
-
[20]
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. 2024. Instruction-following evaluation for large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
2024
-
[21]
Polo, Felipe Maia and Weber, Lucas and Choshen, Leshem and Sun, Yuekai and Xu, Gongjun and Yurochkin, Mikhail , booktitle=. tiny
-
[22]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics , year=
Efficient Benchmarking (of Language Models) , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics , year=
2024
-
[23]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics , year=
Anchor Points: Benchmarking Models with Much Fewer Examples , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics , year=
-
[24]
Proceedings of the 13th International Conference on Learning Representations , year=
metabench -- A Sparse Benchmark of Reasoning and Knowledge in Large Language Models , author=. Proceedings of the 13th International Conference on Learning Representations , year=
-
[25]
Rethinking
Wang, Shaobo and Wang, Cong and Fu, Wenjie and Min, Yue and Feng, Mingquan and Guan, Isabel and Hu, Xuming and He, Conghui and Wang, Cunxiang and Yang, Kexin and Ren, Xingzhang and Huang, Fei and Liu, Dayiheng and Zhang, Linfeng , booktitle=. Rethinking
-
[26]
Zhang, Taolin and Guo, Hang and Lu, Wang and Dai, Tao and Xia, Shu-Tao and Wang, Jindong , booktitle=. Sparse
-
[27]
Active Evaluation Acquisition for Efficient
Li, Yang and others , booktitle=. Active Evaluation Acquisition for Efficient
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
Beyond One-Size-Fits-All: Tailored Benchmarks for Efficient Evaluation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics , year=
-
[29]
Zhu, Xuechen and Tang, Kaiqiang and Pan, Yifei and Du, Mengdi and Xu, Jiaze and Jiang, Zhisong and Xie, Pengtao , booktitle=. Sub
-
[30]
arXiv preprint arXiv:2502.10312 , year=
Scales++: Efficient Benchmark Evaluation at Scale through Item-Centric Assessment of Cognitive Abilities , author=. arXiv preprint arXiv:2502.10312 , year=
-
[31]
arXiv preprint arXiv:2502.07489 , year=
Less is More: A Submodular Approach for Efficient LLM Benchmark Selection , author=. arXiv preprint arXiv:2502.07489 , year=
-
[32]
Proceedings of the 42nd International Conference on Machine Learning , year=
Autoeval Done Right: Using Synthetic Data for Model Evaluation , author=. Proceedings of the 42nd International Conference on Machine Learning , year=
-
[33]
1977 , publisher=
Sampling Techniques , author=. 1977 , publisher=
1977
-
[34]
Journal of the Royal Statistical Society , volume=
On the Two Different Aspects of the Representative Method , author=. Journal of the Royal Statistical Society , volume=
-
[35]
and Kroese, Dirk P
Rubinstein, Reuven Y. and Kroese, Dirk P. , edition=. Simulation and the. 2008 , publisher=
2008
-
[36]
Proceedings of the International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations , year=
-
[37]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
Instruction-Following Evaluation for Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year=
-
[38]
arXiv preprint arXiv:2110.14168 , year=
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[39]
Wang, Yubo and Ma, Xueguang and Zhang, Ge and Ni, Yuansheng and Chandra, Abhranil and Guo, Shiguang and Ren, Weiming and Arulraj, Aaran and He, Xuan and Jiang, Ziyan and others , journal=
-
[40]
, journal=
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , journal=
-
[41]
arXiv preprint arXiv:2501.14249 , year=
Humanity's Last Exam , author=. arXiv preprint arXiv:2501.14249 , year=
-
[42]
Transactions on Machine Learning Research , year=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , year=
-
[43]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[44]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and others , journal=. The
-
[45]
arXiv preprint arXiv:2412.19437 , year=
-
[46]
and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and others , journal=
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de las Casas, Diego and others , journal=. Mistral 7
-
[47]
arXiv preprint arXiv:2412.08905 , year=
Phi-4 Technical Report , author=. arXiv preprint arXiv:2412.08905 , year=
-
[48]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[49]
2024 , publisher=
Biderman, Stella and Schoelkopf, Hailey and Anthony, Quentin Gregory and Bradley, Herbie and O'Brien, Kyle and others , title=. 2024 , publisher=
2024
-
[50]
Fourrier, Cl\'. Open. Hugging Face , year=
-
[51]
2010 , publisher=
Fair Representation: Meeting the Ideal of One Man, One Vote , author=. 2010 , publisher=
2010
-
[52]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year=
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo\". Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , year=
-
[53]
Reddi, Vijay Janapa and Cheng, Christine and Kanter, David and Mattson, Peter and Schmuelling, Guenther and Wu, Carole-Jean and Anderson, Brian and Breeskin, Maximilien and Bughici, Mark and Cebo, Ciro and others , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.