Inferring Latent Temporal Sparse Coordination Graph for Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-24 03:22 UTC · model grok-4.3
The pith
A sparse coordination graph sampled from an agent-pair probability matrix derived from historical observations enables effective knowledge exchange in multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
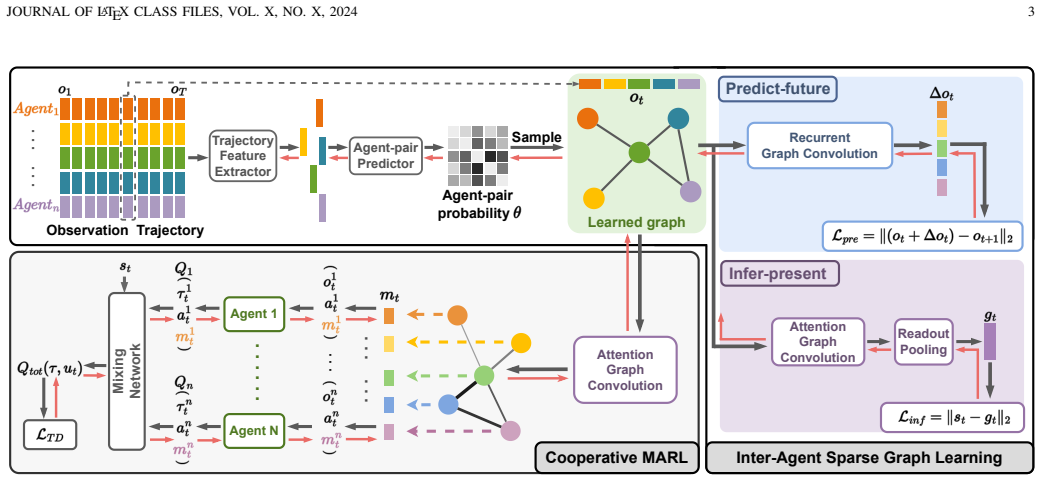
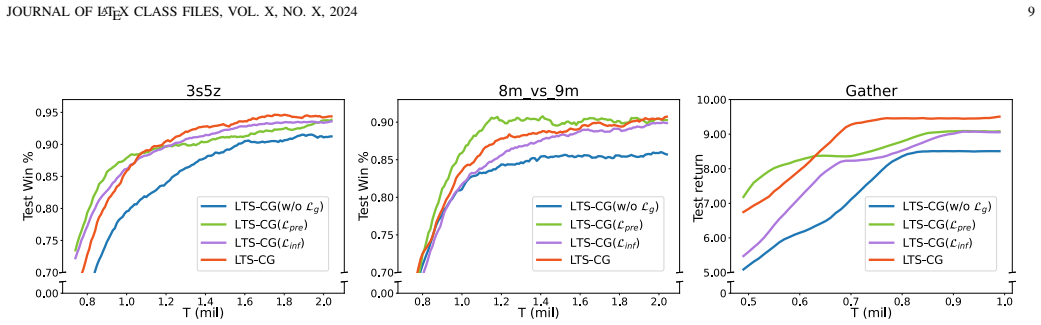
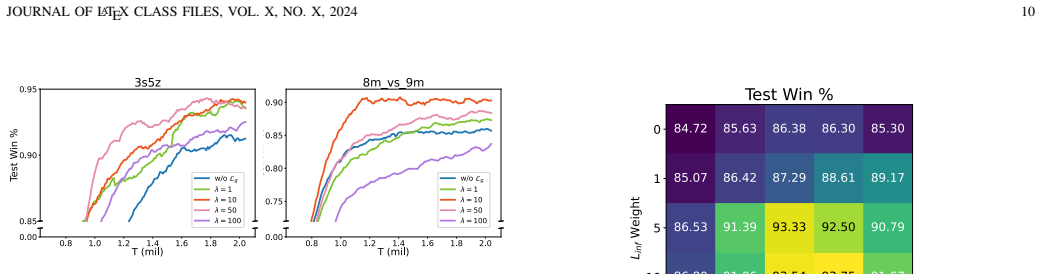
By leveraging agents' historical observations to form a probability matrix, sampling a sparse graph, and exchanging knowledge along its edges, the LTS-CG captures temporal dependencies and uncertainty in relations; the addition of Predict-Future and Infer-Present augments this with foresight and contextual inference, all at a cost dependent only on agent count, in an end-to-end trainable framework.
What carries the argument
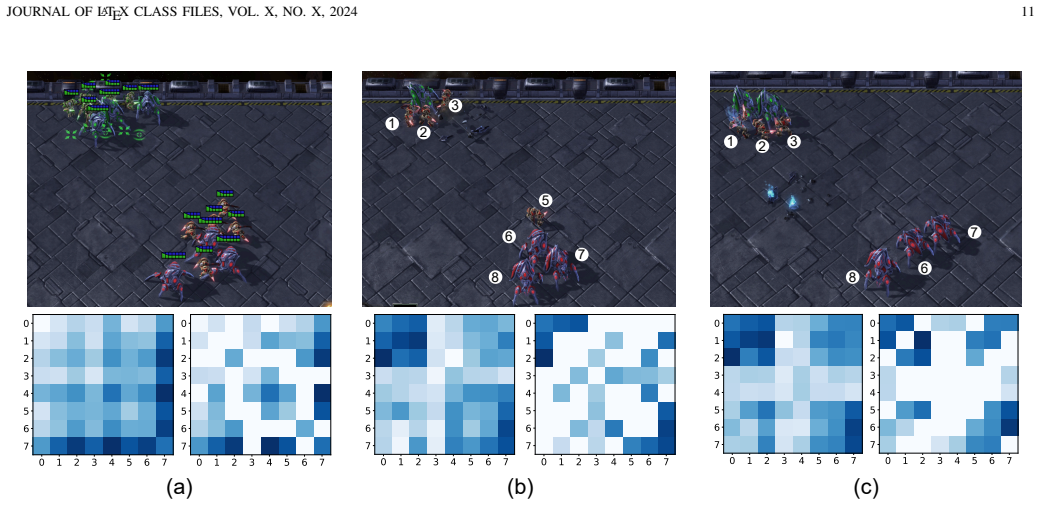
The agent-pair probability matrix computed from historical observations, used to sample a sparse graph for selective knowledge exchange.
Load-bearing premise
That a probability matrix based on historical observations reliably identifies the agent pairs whose information exchange is necessary and sufficient for successful coordination.
What would settle it
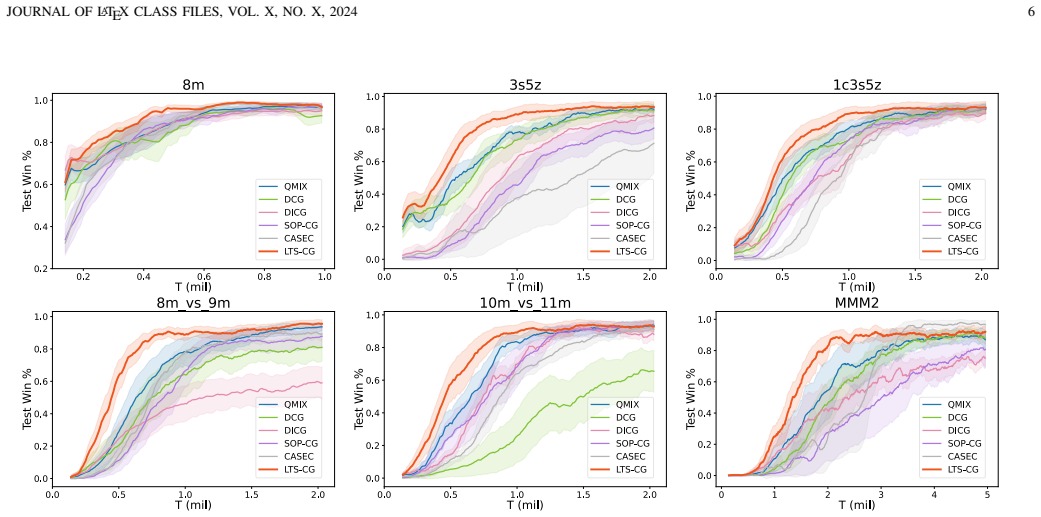
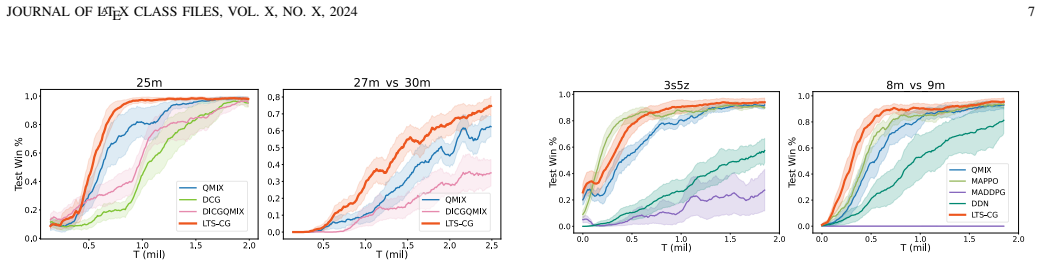
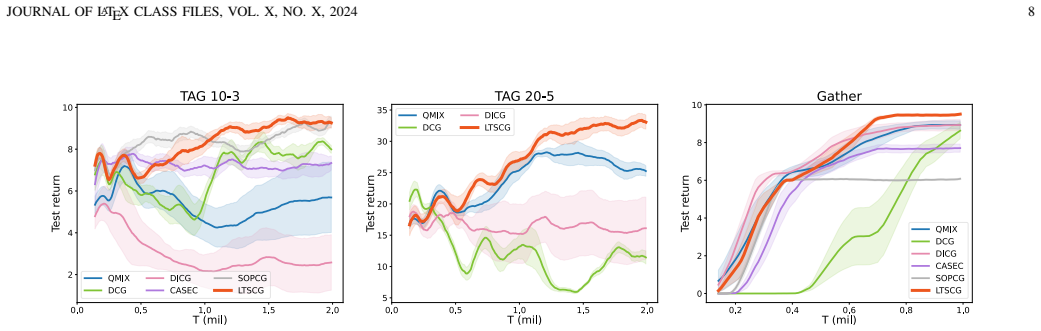
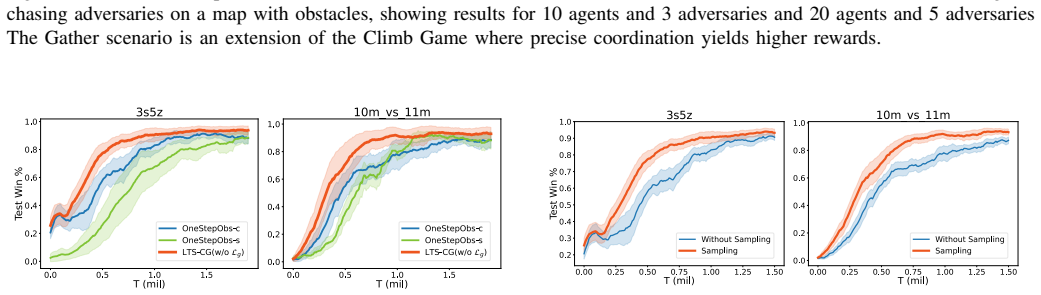
A controlled test on the StarCraft II benchmark in which the LTS-CG method produces lower win rates than a baseline using only one-step observations would indicate that incorporating historical data does not improve graph quality as claimed.
Figures

read the original abstract
Effective agent coordination is crucial in cooperative Multi-Agent Reinforcement Learning (MARL). While agent cooperation can be represented by graph structures, prevailing graph learning methods in MARL are limited. They rely solely on one-step observations, neglecting crucial historical experiences, leading to deficient graphs that foster redundant or detrimental information exchanges. Additionally, high computational demands for action-pair calculations in dense graphs impede scalability. To address these challenges, we propose inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for MARL. The LTS-CG leverages agents' historical observations to calculate an agent-pair probability matrix, where a sparse graph is sampled from and used for knowledge exchange between agents, thereby simultaneously capturing agent dependencies and relation uncertainty. The computational complexity of this procedure is only related to the number of agents. This graph learning process is further augmented by two innovative characteristics: Predict-Future, which enables agents to foresee upcoming observations, and Infer-Present, ensuring a thorough grasp of the environmental context from limited data. These features allow LTS-CG to construct temporal graphs from historical and real-time information, promoting knowledge exchange during policy learning and effective collaboration. Graph learning and agent training occur simultaneously in an end-to-end manner. Our demonstrated results on the StarCraft II benchmark underscore LTS-CG's superior performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes inferring a Latent Temporal Sparse Coordination Graph (LTS-CG) for cooperative multi-agent reinforcement learning. Agents' historical observations are used to compute an agent-pair probability matrix; a sparse graph is then sampled from this matrix for knowledge exchange. The approach incorporates Predict-Future (to anticipate future observations) and Infer-Present (to infer context from limited data) modules, claims computational complexity linear in the number of agents, trains the graph learning and policy end-to-end, and asserts superior performance on the StarCraft II benchmark.
Significance. If the empirical results and methodological details hold, the work could improve upon existing one-step graph-based MARL methods by incorporating temporal history and explicit sparsity, potentially aiding scalability in coordination tasks. The end-to-end training and complexity claim (dependent only on agent count) are positive features if substantiated.
major comments (2)
- [Abstract] Abstract: the central claim of 'superior performance' on the StarCraft II benchmark is stated without any metrics, baselines, ablation studies, error bars, or experimental protocol, so the primary empirical assertion cannot be evaluated from the manuscript.
- [Abstract] Abstract (method description): no equation, algorithm, or sampling rule (threshold, top-k, stochastic, etc.) is supplied for constructing the agent-pair probability matrix from historical observations or for drawing the sparse graph; this mechanism is load-bearing for the claim that the procedure simultaneously captures dependencies, models uncertainty, and avoids redundant/detrimental exchanges.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, clarifying the role of the abstract versus the full paper and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'superior performance' on the StarCraft II benchmark is stated without any metrics, baselines, ablation studies, error bars, or experimental protocol, so the primary empirical assertion cannot be evaluated from the manuscript.
Authors: The abstract is intentionally concise to summarize the contribution. The full manuscript provides the requested details in the Experiments section, including quantitative metrics on StarCraft II, comparisons to baselines, ablation studies, error bars across multiple runs, and the full experimental protocol. We agree the abstract claim would be stronger with a brief quantitative highlight and will revise it to include key performance deltas while respecting length constraints. revision: partial
-
Referee: [Abstract] Abstract (method description): no equation, algorithm, or sampling rule (threshold, top-k, stochastic, etc.) is supplied for constructing the agent-pair probability matrix from historical observations or for drawing the sparse graph; this mechanism is load-bearing for the claim that the procedure simultaneously captures dependencies, models uncertainty, and avoids redundant/detrimental exchanges.
Authors: The abstract offers a textual overview. The full manuscript supplies the precise formulation: Section 3 derives the agent-pair probability matrix from historical observations via the temporal encoder, and Section 4 details the stochastic sampling procedure (Gumbel-softmax reparameterization) used to draw the sparse graph, which explicitly models uncertainty and prunes low-probability edges. The Predict-Future and Infer-Present modules are formalized with their respective loss terms. We will augment the abstract with a short reference to the sampling mechanism to address this concern. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes LTS-CG as computing an agent-pair probability matrix from historical observations, sampling a sparse graph for knowledge exchange, and augmenting with Predict-Future and Infer-Present. No equations, derivations, or self-citations are exhibited in the provided text that reduce any claimed result or prediction to a fitted input or self-definition by construction. The central claims rest on the introduction of these mechanisms and end-to-end training, which are presented as independent of the target performance metrics on StarCraft II. This is the common case of a self-contained proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Historical observations contain sufficient information to infer future agent interactions and current context
- domain assumption Sparse sampled graphs reduce redundant or detrimental information exchange without losing necessary coordination signals
invented entities (1)
-
Latent Temporal Sparse Coordination Graph (LTS-CG)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Group-Aware Coordination Graph for Multi-Agent Reinforcement Learning
GACG infers a coordination graph capturing both pair and group dependencies for information exchange in MARL, adds a group distance loss for consistency, and reports superior performance on StarCraft II micromanagement tasks.
Reference graph
Works this paper leans on
-
[1]
Traffic signal control with reinforcement learning based on region- aware cooperative strategy,
M. Wang, L. Wu, J. Li, and L. He, “Traffic signal control with reinforcement learning based on region- aware cooperative strategy,” IEEE Trans. Intell. Transp. Syst., vol. 23, no. 7, pp. 6774–6785, 2022
work page 2022
-
[2]
Cooperative heterogeneous multi-robot systems: A survey,
Y . Rizk, M. Awad, and E. W. Tunstel, “Cooperative heterogeneous multi-robot systems: A survey,” ACM Comput. Surv., vol. 52, no. 2, pp. 29:1–29:31, 2019
work page 2019
-
[3]
Multi-agent rein- forcement learning-based resource allocation for UA V networks,
J. Cui, Y . Liu, and A. Nallanathan, “Multi-agent rein- forcement learning-based resource allocation for UA V networks,” IEEE Trans. Wirel. Commun. , vol. 19, no. 2, pp. 729–743, 2020
work page 2020
-
[4]
P. Sunehag, G. Lever, A. Gruslys, W. M. Czarnecki, V . F. Zambaldi, M. Jaderberg, M. Lanctot, N. Sonnerat, J. Z. Leibo, K. Tuyls, and T. Graepel, “Value-decomposition networks for cooperative multi-agent learning based on JOURNAL OF LATEX CLASS FILES, VOL. X, NO. X, 2024 13 team reward,” in the 17th International Conference on Autonomous Agents and MultiA...
work page 2024
-
[5]
QMIX: monotonic value function factorisation for deep multi-agent rein- forcement learning,
T. Rashid, M. Samvelyan, C. S. de Witt, G. Farquhar, J. N. Foerster, and S. Whiteson, “QMIX: monotonic value function factorisation for deep multi-agent rein- forcement learning,” inthe 35th International Conference on Machine Learning (ICML 2018), Stockholmsm ¨assan, Stockholm, Sweden, vol. 80, 2018, pp. 4292–4301
work page 2018
-
[6]
QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning,
K. Son, D. Kim, W. J. Kang, D. Hostallero, and Y . Yi, “QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning,” in the 36th International Conference on Machine Learning (ICML 2019), Long Beach, California, USA , vol. 97, 2019, pp. 5887–5896
work page 2019
-
[7]
Rethinking individual global max in cooperative multi-agent reinforcement learning,
Y . Hong, Y . Jin, and Y . Tang, “Rethinking individual global max in cooperative multi-agent reinforcement learning,” in the 36th Annual Conference on Neural Information Processing Systems (NIPS 2022) , vol. 35, 2022, pp. 32 438–32 449
work page 2022
-
[8]
Coor- dinated reinforcement learning,
C. Guestrin, M. G. Lagoudakis, and R. Parr, “Coor- dinated reinforcement learning,” in the 19th Interna- tional Conference (ICML 2002), University of New South Wales, Sydney, Australia, 2002, pp. 227–234
work page 2002
-
[9]
Pic: Permuta- tion invariant critic for multi-agent deep reinforcement learning,
I.-J. Liu, R. A. Yeh, and A. G. Schwing, “Pic: Permuta- tion invariant critic for multi-agent deep reinforcement learning,” in the 3rd Conference on Robot Learning (CoRL 2019), Osaka, Japan , vol. 100, 2020, pp. 590– 602
work page 2019
-
[10]
W. Boehmer, V . Kurin, and S. Whiteson, “Deep coordi- nation graphs,” in the 37th International Conference on Machine Learning (ICML 2020), Virtual Event, vol. 119, 2020, pp. 980–991
work page 2020
-
[11]
Graph convolutional value decomposi- tion in multi-agent reinforcement learning,
N. Naderializadeh, F. H. Hung, S. Soleyman, and D. Khosla, “Graph convolutional value decomposi- tion in multi-agent reinforcement learning,” CoRR, vol. abs/2010.04740, 2020
-
[12]
Deep implicit coordination graphs for multi-agent reinforcement learning,
S. Li, J. K. Gupta, P. Morales, R. E. Allen, and M. J. Kochenderfer, “Deep implicit coordination graphs for multi-agent reinforcement learning,” in the 20th Interna- tional Conference on Autonomous Agents and Multiagent Systems (AAMAS 2021), Virtual Event, United Kingdom , 2021, pp. 764–772
work page 2021
-
[13]
Self-organized polynomial-time coordination graphs,
Q. Yang, W. Dong, Z. Ren, J. Wang, T. Wang, and C. Zhang, “Self-organized polynomial-time coordination graphs,” in International Conference on Machine Learn- ing (ICML 2022), Baltimore, Maryland, USA , vol. 162, 2022, pp. 24 963–24 979
work page 2022
-
[14]
Context-aware sparse deep coordination graphs,
T. Wang, L. Zeng, W. Dong, Q. Yang, Y . Yu, and C. Zhang, “Context-aware sparse deep coordination graphs,” in the 10th International Conference on Learn- ing Representations (ICLR 2022), Virtual Event , 2022
work page 2022
-
[15]
Learning to score behaviors for guided policy optimization,
A. Pacchiano, J. Parker-Holder, Y . Tang, K. Choroman- ski, A. Choromanska, and M. Jordan, “Learning to score behaviors for guided policy optimization,” in the 37th International Conference on Machine Learning, (ICML 2020), vol. 119, 13–18 Jul 2020, pp. 7445–7454
work page 2020
-
[16]
W. Du and S. Ding, “A survey on multi-agent deep re- inforcement learning: from the perspective of challenges and applications,” Artificial Intelligence Review, vol. 54, no. 5, pp. 3215–3238, 2021
work page 2021
-
[17]
A review of coop- erative multi-agent deep reinforcement learning,
A. Oroojlooy and D. Hajinezhad, “A review of coop- erative multi-agent deep reinforcement learning,” Appl. Intell., vol. 53, no. 11, pp. 13 677–13 722, 2023
work page 2023
-
[18]
Multi-agent actor-critic for mixed cooperative-competitive environments,
R. Lowe, Y . Wu, A. Tamar, J. Harb, P. Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” in the 30th An- nual Conference on Neural Information Processing Sys- tems (NIPS 2017), Long Beach, CA, USA , 2017, pp. 6379–6390
work page 2017
-
[19]
Counterfactual multi-agent policy gradients,
J. N. Foerster, G. Farquhar, T. Afouras, N. Nardelli, and S. Whiteson, “Counterfactual multi-agent policy gradients,” in the 32nd AAAI Conference on Artificial Intelligence (AAAI 2018), New Orleans, Louisiana, USA , 2018, pp. 2974–2982
work page 2018
-
[20]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,” IEEE Trans. Neural Networks Learn. Syst., vol. 32, no. 1, pp. 4–24, 2021
work page 2021
-
[21]
Multi-agent game abstraction via graph attention neural network,
Y . Liu, W. Wang, Y . Hu, J. Hao, X. Chen, and Y . Gao, “Multi-agent game abstraction via graph attention neural network,” in the 34th AAAI Conference on Artificial Intelligence (AAAI 2020), New York, NY, USA, , 2020, pp. 7211–7218
work page 2020
-
[22]
Learning nearly decomposable value functions via communication minimization,
T. Wang, J. Wang, C. Zheng, and C. Zhang, “Learning nearly decomposable value functions via communication minimization,” in the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 2020
work page 2020
-
[23]
Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples,
W. Duan, J. Xuan, M. Qiao, and J. Lu, “Learning from the dark: Boosting graph convolutional neural networks with diverse negative samples,” in the 36th AAAI Con- ference on Artificial Intelligence (AAAI 2022), Virtual Event. AAAI Press, 2022, pp. 6550–6558
work page 2022
-
[24]
Graph con- volutional reinforcement learning,
J. Jiang, C. Dun, T. Huang, and Z. Lu, “Graph con- volutional reinforcement learning,” in 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia , 2020
work page 2020
-
[25]
Actor-attention-critic for multi- agent reinforcement learning,
S. Iqbal and F. Sha, “Actor-attention-critic for multi- agent reinforcement learning,” in the 36th International Conference on Machine Learning (ICML 2019), Long Beach, California, USA , vol. 97, 2019, pp. 2961–2970
work page 2019
-
[26]
ROMA: multi-agent reinforcement learning with emergent roles,
T. Wang, H. Dong, V . R. Lesser, and C. Zhang, “ROMA: multi-agent reinforcement learning with emergent roles,” in the 37th International Conference on Machine Learn- ing (ICML 2020), Virtual Event , vol. 119, 2020, pp. 9876–9886
work page 2020
-
[27]
Reducing bus bunching with asyn- chronous multi-agent reinforcement learning,
J. Wang and L. Sun, “Reducing bus bunching with asyn- chronous multi-agent reinforcement learning,” in Pro- ceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI 2021), Virtual Event / Montreal, Canada, 19-27 August , 2021, pp. 426–433
work page 2021
-
[28]
Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting,” in the 27th International Joint Con- ference on Artificial Intelligence (IJCAI 2018), Stock- JOURNAL OF LATEX CLASS FILES, VOL. X, NO. X, 2024 14 holm, Sweden, 2018, pp. 3634–3640
work page 2018
-
[29]
Connecting the dots: Multivariate time series forecasting with graph neural networks,
Z. Wu, S. Pan, G. Long, J. Jiang, X. Chang, and C. Zhang, “Connecting the dots: Multivariate time series forecasting with graph neural networks,” in The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2020), Virtual Event, CA, USA, 2020, pp. 753–763
work page 2020
-
[30]
Multivariate time series forecasting with latent graph inference.arXiv preprint arXiv:2203.03423,
V . G. Satorras, S. S. Rangapuram, and T. Januschowski, “Multivariate time series forecasting with latent graph inference,” CoRR, vol. abs/2203.03423, 2022
-
[31]
Neural relational inference for interacting sys- tems,
T. N. Kipf, E. Fetaya, K. Wang, M. Welling, and R. S. Zemel, “Neural relational inference for interacting sys- tems,” in the 35th International Conference on Machine Learning (ICML 2018), Stockholmsm ¨assan, Stockholm, Sweden, vol. 80. PMLR, 2018, pp. 2693–2702
work page 2018
-
[32]
Learn- ing discrete structures for graph neural networks,
L. Franceschi, M. Niepert, M. Pontil, and X. He, “Learn- ing discrete structures for graph neural networks,” in the 36th International Conference on Machine Learning (ICML 2019), Long Beach, California, USA , vol. 97, 2019, pp. 1972–1982
work page 2019
-
[33]
Discrete graph structure learning for forecasting multiple time series,
C. Shang, J. Chen, and J. Bi, “Discrete graph structure learning for forecasting multiple time series,” in the 9th International Conference on Learning Representations (ICLR 2021), Virtual Event, Austria , 2021
work page 2021
-
[34]
Evolvehypergraph: Group-aware dynamic relational reasoning for trajectory prediction,
J. Li, C. Hua, J. Park, H. Ma, V . M. Dax, and M. J. Kochenderfer, “Evolvehypergraph: Group-aware dynamic relational reasoning for trajectory prediction,” CoRR, vol. abs/2208.05470, 2022
-
[35]
Approximation capabilities of multilayer feedforward networks,
K. Hornik, “Approximation capabilities of multilayer feedforward networks,” Neural Networks , vol. 4, no. 2, pp. 251–257, 1991
work page 1991
-
[36]
Categorical reparameter- ization with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameter- ization with gumbel-softmax,” in the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, 2017
work page 2017
-
[37]
The concrete distribution: A continuous relaxation of discrete random variables,
C. J. Maddison, A. Mnih, and Y . W. Teh, “The concrete distribution: A continuous relaxation of discrete random variables,” in the 5th International Conference on Learn- ing Representations (ICLR 2017),Toulon, France , 2017
work page 2017
-
[38]
Diffusion con- volutional recurrent neural network: Data-driven traffic forecasting,
Y . Li, R. Yu, C. Shahabi, and Y . Liu, “Diffusion con- volutional recurrent neural network: Data-driven traffic forecasting,” in the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 2018
work page 2018
-
[39]
Layer- diverse negative sampling for graph neural networks,
W. Duan, J. Lu, Y . G. Wang, and J. Xuan, “Layer- diverse negative sampling for graph neural networks,” Transactions on Machine Learning Research , 2024
work page 2024
-
[40]
Semi-supervised classifi- cation with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classifi- cation with graph convolutional networks,” in the 5th International Conference on Learning Representations (ICLR 2017), Toulon, France, April 24-26 , 2017
work page 2017
-
[41]
The starcraft multi- agent challenge,
M. Samvelyan, T. Rashid, C. S. de Witt, G. Farquhar, N. Nardelli, T. G. J. Rudner, C. Hung, P. H. S. Torr, J. N. Foerster, and S. Whiteson, “The starcraft multi- agent challenge,” in the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS 2019), Montreal, QC, Canada, , 2019, pp. 2186–2188
work page 2019
-
[42]
Lenient learning in independent- learner stochastic cooperative games,
E. Wei and S. Luke, “Lenient learning in independent- learner stochastic cooperative games,” J. Mach. Learn. Res., vol. 17, pp. 84:1–84:42, 2016
work page 2016
-
[43]
W. Sun, C. Lee, and C. Lee, “DFAC framework: Fac- torizing the value function via quantile mixture for multi-agent distributional q-learning,” in Proceedings of the 38th International Conference on Machine Learning (ICML 2021) 2021, 18-24 July 2021, Virtual Event , ser. Proceedings of Machine Learning Research, vol. 139, 2021, pp. 9945–9954
work page 2021
-
[44]
The surprising effectiveness of PPO in cooperative multi-agent games,
C. Yu, A. Velu, E. Vinitsky, J. Gao, Y . Wang, A. M. Bayen, and Y . Wu, “The surprising effectiveness of PPO in cooperative multi-agent games,” in The Annual Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, November 28 - December 9, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.