3DMambaComplete: Exploring Structured State Space Model for Point Cloud Completion
Pith reviewed 2026-05-24 02:06 UTC · model grok-4.3
The pith
Mamba's selection mechanism completes point clouds by encoding features without pooling-induced detail loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
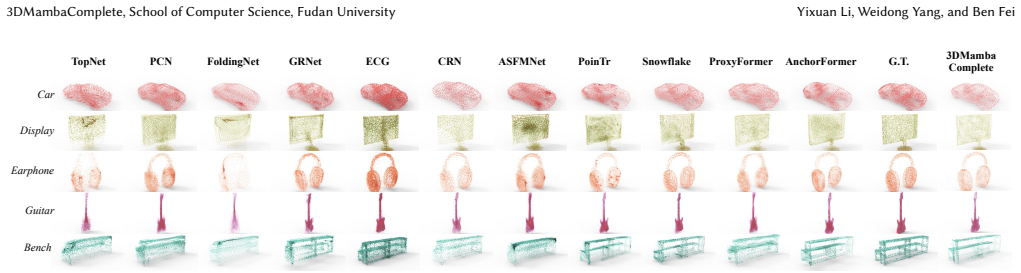
3DMambaComplete encodes incomplete point clouds with Mamba's selection mechanism inside the HyperPoint Generation module to predict a compact set of HyperPoints, then applies a spread operation to disperse them spatially and a deformation step that converts their 2D mesh representation into a dense 3D point cloud; this pipeline is claimed to avoid the local-detail erosion typical of pooling while keeping computation lower than attention, resulting in outputs that exceed existing methods on standard completion benchmarks.
What carries the argument
Mamba selection mechanism inside HyperPoint Generation, which encodes features and predicts HyperPoints that are then spread and deformed into the final 3D structure.
If this is right
- Point cloud sequences can be processed at lower computational cost while retaining local detail.
- Downsampled HyperPoints serve as an effective intermediate representation for 3D reconstruction.
- The deformation of 2D meshes into 3D points produces denser and more accurate completions than direct upsampling.
- Qualitative and quantitative gains hold across multiple established point-cloud benchmarks.
Where Pith is reading between the lines
- The same Mamba-plus-HyperPoint pattern may transfer to other 3D tasks such as denoising or upsampling.
- If the efficiency gains scale, the method could support completion on edge devices with limited memory.
- State-space selection offers a general alternative to attention when global context must be modeled without explicit pairwise comparisons.
Load-bearing premise
Mamba's selection mechanism together with the HyperPoint spread and deformation steps can capture and reconstruct fine local geometry without the losses introduced by pooling in Transformer pipelines.
What would settle it
On the PCN or Completion3D benchmark, if the Chamfer distance or F-Score of 3DMambaComplete does not exceed that of the strongest published Transformer completion model under identical training settings.
Figures






read the original abstract
Point cloud completion aims to generate a complete and high-fidelity point cloud from an initially incomplete and low-quality input. A prevalent strategy involves leveraging Transformer-based models to encode global features and facilitate the reconstruction process. However, the adoption of pooling operations to obtain global feature representations often results in the loss of local details within the point cloud. Moreover, the attention mechanism inherent in Transformers introduces additional computational complexity, rendering it challenging to handle long sequences effectively. To address these issues, we propose 3DMambaComplete, a point cloud completion network built on the novel Mamba framework. It comprises three modules: HyperPoint Generation encodes point cloud features using Mamba's selection mechanism and predicts a set of Hyperpoints. A specific offset is estimated, and the down-sampled points become HyperPoints. The HyperPoint Spread module disperses these HyperPoints across different spatial locations to avoid concentration. Finally, a deformation method transforms the 2D mesh representation of HyperPoints into a fine-grained 3D structure for point cloud reconstruction. Extensive experiments conducted on various established benchmarks demonstrate that 3DMambaComplete surpasses state-of-the-art point cloud completion methods, as confirmed by qualitative and quantitative analyses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3DMambaComplete, a point cloud completion architecture that replaces Transformer-based global feature encoding with the Mamba structured state space model. The network consists of a HyperPoint Generation module that uses Mamba's input-dependent selection to encode features, estimate offsets, and downsample to a set of HyperPoints; a HyperPoint Spread module that disperses these points spatially; and a final deformation stage that converts a 2D mesh representation of the HyperPoints into a dense 3D point cloud. The central claim is that this design avoids the local-detail loss associated with pooling in Transformers while achieving linear complexity, and that extensive experiments on established benchmarks show quantitative and qualitative superiority over prior state-of-the-art methods.
Significance. If the experimental superiority and the claimed preservation of local geometry both hold, the work would constitute the first demonstration of Mamba-based point cloud completion and would supply a concrete efficiency argument (linear vs. quadratic complexity) together with a new set of architectural primitives (HyperPoint generation, spread, and 2D-to-3D deformation). These elements could influence subsequent work on long-sequence 3D tasks. The significance is currently limited by the absence of any reported dataset names, metrics, baseline implementations, ablation studies, or error analysis that would allow independent verification of the performance claims.
major comments (1)
- [Abstract / HyperPoint Generation module] Abstract (and the description of the HyperPoint Generation module): the central motivation states that pooling operations in Transformers cause loss of local details, yet the proposed pipeline explicitly downsamples the input after offset estimation to produce the HyperPoints on which Mamba operates. No analysis is supplied showing that this downsampling step preserves the fine-grained geometry that the method claims to protect; if the downsampling discards information before or during Mamba encoding, the claimed advantage over pooling-based Transformers does not follow.
minor comments (2)
- [Abstract] The abstract asserts superiority on 'various established benchmarks' but supplies no concrete dataset names, metrics (e.g., CD, EMD, F-score), baseline list, or quantitative tables; these details are required for any performance claim.
- The terms 'HyperPoints', 'HyperPoint Spread module', and 'deformation method' are introduced without a preceding definition or reference to prior usage; a short notational or architectural diagram would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the single major comment point by point below, providing clarification and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / HyperPoint Generation module] Abstract (and the description of the HyperPoint Generation module): the central motivation states that pooling operations in Transformers cause loss of local details, yet the proposed pipeline explicitly downsamples the input after offset estimation to produce the HyperPoints on which Mamba operates. No analysis is supplied showing that this downsampling step preserves the fine-grained geometry that the method claims to protect; if the downsampling discards information before or during Mamba encoding, the claimed advantage over pooling-based Transformers does not follow.
Authors: We thank the referee for this insightful observation. The HyperPoint Generation module applies Mamba's input-dependent selection mechanism to encode features from the full input sequence prior to offset estimation and downsampling; the subsequent downsampling produces a compact set of HyperPoints that serve as the basis for the spread and deformation stages. This selection process is designed to be adaptive rather than fixed like pooling, potentially retaining more task-relevant local geometry. However, we acknowledge that the manuscript does not include dedicated analysis (e.g., ablation on downsampling ratios or quantitative measures of local feature preservation) to directly demonstrate this advantage. We will add such analysis, including visualizations and comparative metrics, to the revised manuscript. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks
full rationale
The paper presents an architectural proposal (HyperPoint Generation using Mamba selection, followed by Spread and deformation modules) whose performance is asserted via quantitative/qualitative results on established point-cloud benchmarks. No equations, fitted parameters, or predictions are shown that reduce by construction to the inputs; no self-citation chains or uniqueness theorems are invoked as load-bearing; the Mamba reference is external. The derivation chain is therefore self-contained against independent data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mamba's selection mechanism can effectively encode features from point cloud data
invented entities (2)
-
HyperPoints
no independent evidence
-
HyperPoint Spread module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Mamba Encoder takes the feature values of the downsampled points as input, and the Mamba Block reorders them. The data is scanned in a specific order...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Panos Achlioptas, Olga Diamanti, Ioannis Mitliagkas, and Leonidas Guibas. 2018. Learning representations and generative models for 3d point clouds. In Interna- tional conference on machine learning . PMLR, 40–49
work page 2018
-
[2]
Yingjie Cai, Kwan-Yee Lin, Chao Zhang, Qiang Wang, Xiaogang Wang, and Hongsheng Li. 2022. Learning a structured latent space for unsupervised point cloud completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5543–5553
work page 2022
-
[3]
Zhikai Chen, Fuchen Long, Zhaofan Qiu, Ting Yao, Wengang Zhou, Jiebo Luo, and Tao Mei. 2023. AnchorFormer: Point Cloud Completion From Discriminative Nodes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13581–13590
work page 2023
-
[4]
François Chollet. 2017. Xception: Deep learning with depthwise separable con- volutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1251–1258
work page 2017
-
[5]
Ben Fei, Weidong Yang, Wen-Ming Chen, Zhijun Li, Yikang Li, Tao Ma, Xing Hu, and Lipeng Ma. 2022. Comprehensive review of deep learning-based 3d point cloud completion processing and analysis. IEEE Transactions on Intelligent Transportation Systems 23, 12 (2022), 22862–22883
work page 2022
-
[6]
Ben Fei, Weidong Yang, Wen-Ming Chen, and Lipeng Ma. 2022. VQ-DcTr: Vector- quantized autoencoder with dual-channel transformer points splitting for 3D point cloud completion. In Proceedings of the 30th ACM international conference on multimedia. 4769–4778
work page 2022
-
[7]
Ben Fei, Weidong Yang, Lipeng Ma, and Wen-Ming Chen. 2023. DcTr: Noise- robust point cloud completion by dual-channel transformer with cross-attention. Pattern Recognition 133 (2023), 109051
work page 2023
-
[8]
Ben Fei, Rui Zhang, Weidong Yang, Zhijun Li, and Wen-Ming Chen. 2024. Pro- gressive Growth for Point Cloud Completion by Surface-Projection Optimization. IEEE Transactions on Intelligent Vehicles (2024)
work page 2024
-
[9]
Albert Gu and Tri Dao. 2023. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. 2020. Hippo: Recurrent memory with optimal polynomial projections. Advances in neural information processing systems 33 (2020), 1474–1487
work page 2020
-
[11]
Albert Gu, Karan Goel, and Christopher Ré. 2021. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
Albert Gu, Isys Johnson, Karan Goel, Khaled Saab, Tri Dao, Atri Rudra, and Christopher Ré. 2021. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems 34 (2021), 572–585
work page 2021
- [13]
-
[14]
Zitian Huang, Yikuan Yu, Jiawen Xu, Feng Ni, and Xinyi Le. 2020. Pf-net: Point fractal network for 3d point cloud completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 7662–7670
work page 2020
-
[15]
Shanshan Li, Pan Gao, Xiaoyang Tan, and Mingqiang Wei. 2023. ProxyFormer: Proxy Alignment Assisted Point Cloud Completion with Missing Part Sensitive Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9466–9475
work page 2023
- [16]
- [17]
-
[18]
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. 2024. Vmamba: Visual state space model. arXiv preprint arXiv:2401.10166 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Shitong Luo and Wei Hu. 2021. Diffusion probabilistic models for 3d point cloud generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2837–2845
work page 2021
- [20]
-
[21]
Jun Ma, Feifei Li, and Bo Wang. 2024. U-mamba: Enhancing long-range de- pendency for biomedical image segmentation. arXiv preprint arXiv:2401.04722 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
Paritosh Mittal, Yen-Chi Cheng, Maneesh Singh, and Shubham Tulsiani. 2022. Autosdf: Shape priors for 3d completion, reconstruction and generation. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 306–315
work page 2022
-
[24]
Trung Nguyen, Quang-Hieu Pham, Tam Le, Tung Pham, Nhat Ho, and Binh- Son Hua. 2021. Point-set distances for learning representations of 3d point clouds. In Proceedings of the IEEE/CVF international conference on computer vision . 10478–10487
work page 2021
-
[25]
Liang Pan. 2020. ECG: Edge-aware point cloud completion with graph convolu- tion. IEEE Robotics and Automation Letters 5, 3 (2020), 4392–4398
work page 2020
-
[26]
Yatian Pang, Wenxiao Wang, Francis EH Tay, Wei Liu, Yonghong Tian, and Li Yuan. 2022. Masked autoencoders for point cloud self-supervised learning. In European conference on computer vision . Springer, 604–621
work page 2022
-
[27]
Jonathan Pilault, Mahan Fathi, Orhan Firat, Chris Pal, Pierre-Luc Bacon, and Ross Goroshin. 2024. Block-state transformers. Advances in Neural Information Processing Systems 36 (2024)
work page 2024
- [28]
-
[29]
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. 2017. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition . 652–660
work page 2017
-
[30]
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. 2017. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Advances in neural information processing systems 30 (2017)
work page 2017
- [31]
-
[32]
Jimmy TH Smith, Andrew Warrington, and Scott W Linderman. 2022. Simplified state space layers for sequence modeling. arXiv preprint arXiv:2208.04933 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Marina Sokolova, Nathalie Japkowicz, and Stan Szpakowicz. 2006. Beyond ac- curacy, F-score and ROC: a family of discriminant measures for performance evaluation. In Australasian joint conference on artificial intelligence . Springer, 1015–1021
work page 2006
-
[34]
Lyne P Tchapmi, Vineet Kosaraju, Hamid Rezatofighi, Ian Reid, and Silvio Savarese. 2019. Topnet: Structural point cloud decoder. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 383–392
work page 2019
-
[35]
Keneni W Tesema, Lyndon Hill, Mark W Jones, Muneeb I Ahmad, and Gary KL Tam. 2023. Point Cloud Completion: A Survey. IEEE Transactions on Visualization and Computer Graphics (2023)
work page 2023
- [36]
- [37]
-
[38]
Xiaogang Wang, Marcelo H Ang Jr, and Gim Hee Lee. 2020. Cascaded refinement network for point cloud completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 790–799
work page 2020
-
[39]
Yida Wang, David Joseph Tan, Nassir Navab, and Federico Tombari. 2022. Learn- ing local displacements for point cloud completion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition . 1568–1577
work page 2022
-
[40]
Weikun Wu, Yan Zhang, David Wang, and Yunqi Lei. 2020. SK-Net: Deep learning on point cloud via end-to-end discovery of spatial keypoints. In Proceedings of the AAAI Conference on Artificial Intelligence , Vol. 34. 6422–6429
work page 2020
-
[41]
Yaqi Xia, Yan Xia, Wei Li, Rui Song, Kailang Cao, and Uwe Stilla. 2021. Asfm- net: Asymmetrical siamese feature matching network for point completion. In Proceedings of the 29th ACM international conference on multimedia . 1938–1947
work page 2021
-
[42]
Peng Xiang, Xin Wen, Yu-Shen Liu, Yan-Pei Cao, Pengfei Wan, Wen Zheng, and Zhizhong Han. 2021. Snowflakenet: Point cloud completion by snowflake point deconvolution with skip-transformer. InProceedings of the IEEE/CVF international conference on computer vision . 5499–5509
work page 2021
-
[43]
Haozhe Xie, Hongxun Yao, Shangchen Zhou, Jiageng Mao, Shengping Zhang, and Wenxiu Sun. 2020. Grnet: Gridding residual network for dense point cloud completion. In European Conference on Computer Vision . Springer, 365–381
work page 2020
-
[44]
Zhaohu Xing, Tian Ye, Yijun Yang, Guang Liu, and Lei Zhu. 2024. Segmamba: Long-range sequential modeling mamba for 3d medical image segmentation. arXiv preprint arXiv:2401.13560 (2024). 3DMambaComplete, School of Computer Science, Fudan University Yixuan Li, Weidong Yang, and Ben Fei
-
[45]
Xingguang Yan, Liqiang Lin, Niloy J Mitra, Dani Lischinski, Daniel Cohen-Or, and Hui Huang. 2022. Shapeformer: Transformer-based shape completion via sparse representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 6239–6249
work page 2022
-
[46]
Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. 2018. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE confer- ence on computer vision and pattern recognition . 206–215
work page 2018
- [47]
- [48]
-
[49]
Xumin Yu, Yongming Rao, Ziyi Wang, Zuyan Liu, Jiwen Lu, and Jie Zhou. 2021. Pointr: Diverse point cloud completion with geometry-aware transformers. In Proceedings of the IEEE/CVF international conference on computer vision . 12498– 12507
work page 2021
-
[50]
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu
-
[51]
In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Point-bert: Pre-training 3d point cloud transformers with masked point modeling. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 19313–19322
-
[52]
Wentao Yuan, Tejas Khot, David Held, Christoph Mertz, and Martial Hebert. 2018. Pcn: Point completion network. In 2018 international conference on 3D vision (3DV). IEEE, 728–737
work page 2018
-
[53]
Junzhe Zhang, Xinyi Chen, Zhongang Cai, Liang Pan, Haiyu Zhao, Shuai Yi, Chai Kiat Yeo, Bo Dai, and Chen Change Loy. 2021. Unsupervised 3d shape completion through gan inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 1768–1777
work page 2021
-
[54]
Rui Zhang, Jingyi Xu, Weidong Yang, Lipeng Ma, Menglong Chen, and Ben Fei
-
[55]
Learning Density Regulated and Multi-View Consistent Unsigned Distance Fields. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 8366–8370
work page 2024
- [56]
-
[57]
Xuancheng Zhang, Yutong Feng, Siqi Li, Changqing Zou, Hai Wan, Xibin Zhao, Yandong Guo, and Yue Gao. 2021. View-guided point cloud completion. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 15890–15899
work page 2021
- [58]
-
[59]
Haoran Zhou, Yun Cao, Wenqing Chu, Junwei Zhu, Tong Lu, Ying Tai, and Chengjie Wang. 2022. Seedformer: Patch seeds based point cloud completion with upsample transformer. In European conference on computer vision . Springer, 416–432
work page 2022
-
[60]
Linqi Zhou, Yilun Du, and Jiajun Wu. 2021. 3d shape generation and comple- tion through point-voxel diffusion. In Proceedings of the IEEE/CVF international conference on computer vision . 5826–5835
work page 2021
-
[61]
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. 2024. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv preprint arXiv:2401.09417 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.