Holmes: A Benchmark to Assess the Linguistic Competence of Language Models
Pith reviewed 2026-05-24 02:05 UTC · model grok-4.3
The pith
A new benchmark shows language models' linguistic competence grows with size but is shaped by architecture and instruction tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
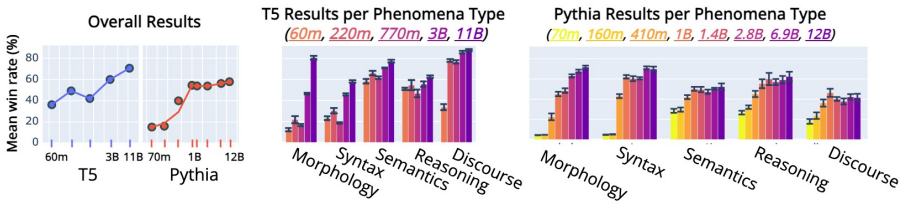
Holmes demonstrates that linguistic competence in language models correlates with model size, yet model architecture and instruction tuning exert significant additional influence, especially on morphology and syntax tasks.
What carries the argument
Classifier-based probing of internal representations to isolate linguistic competence across syntax, morphology, semantics, reasoning, and discourse phenomena.
Load-bearing premise
Classifier probes on internal states can measure unconscious linguistic competence without being contaminated by other model abilities or by the choice of probe itself.
What would settle it
Finding that instruction-tuned models show no consistent difference from base models on morphology or syntax probes would undermine the claim that tuning influences linguistic competence.
Figures












read the original abstract
We introduce Holmes, a new benchmark designed to assess language models (LMs) linguistic competence - their unconscious understanding of linguistic phenomena. Specifically, we use classifier-based probing to examine LMs' internal representations regarding distinct linguistic phenomena (e.g., part-of-speech tagging). As a result, we meet recent calls to disentangle LMs' linguistic competence from other cognitive abilities, such as following instructions in prompting-based evaluations. Composing Holmes, we review over 270 probing studies and include more than 200 datasets to assess syntax, morphology, semantics, reasoning, and discourse phenomena. Analyzing over 50 LMs reveals that, aligned with known trends, their linguistic competence correlates with model size. However, surprisingly, model architecture and instruction tuning also significantly influence performance, particularly in morphology and syntax. Finally, we propose FlashHolmes, a streamlined version that reduces the computation load while maintaining high-ranking precision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Holmes, a benchmark that aggregates over 200 datasets from 270 probing studies to evaluate language models' linguistic competence via classifier-based probing of internal representations across syntax, morphology, semantics, reasoning, and discourse. Analysis of more than 50 LMs shows performance correlates with model size but is also affected by architecture and instruction tuning (especially morphology/syntax); FlashHolmes is proposed as a reduced-compute variant that preserves ranking precision.
Significance. If the probing methodology isolates unconscious linguistic competence without contamination, the work supplies a large-scale, prompting-independent benchmark that can reveal design-factor effects beyond scale and supports more targeted model development.
major comments (2)
- [Abstract and Methods] Abstract and Methods (probing setup): The central claim that classifier-based probing disentangles linguistic competence from instruction-following rests on the assumption that probe results are invariant to classifier choice, regularization, and training regime. No ablations (linear vs. non-linear probes, different seeds, or regularization strengths) are reported to verify that model rankings or the architecture/instruction-tuning effects on morphology and syntax remain stable under these variations.
- [Results] Results section (architecture and tuning effects): The reported significant influence of model architecture and instruction tuning on morphology and syntax performance lacks explicit controls for potential confounds such as training-data overlap between the probed LMs and the 200+ datasets or differences in pretraining objectives; without these, the attribution to architecture/tuning rather than data leakage cannot be isolated.
minor comments (1)
- [FlashHolmes proposal] The description of FlashHolmes should include the exact subset selection criteria and quantitative ranking correlation (e.g., Spearman rho) with the full Holmes benchmark to allow independent verification.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strengths and limitations of our work. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods (probing setup): The central claim that classifier-based probing disentangles linguistic competence from instruction-following rests on the assumption that probe results are invariant to classifier choice, regularization, and training regime. No ablations (linear vs. non-linear probes, different seeds, or regularization strengths) are reported to verify that model rankings or the architecture/instruction-tuning effects on morphology and syntax remain stable under these variations.
Authors: We agree that additional ablations would strengthen the robustness claim. In the revised manuscript we will report results with both linear and non-linear (MLP) probes, multiple random seeds, and a range of regularization strengths to confirm that model rankings and the architecture/instruction-tuning effects remain stable. revision: yes
-
Referee: [Results] Results section (architecture and tuning effects): The reported significant influence of model architecture and instruction tuning on morphology and syntax performance lacks explicit controls for potential confounds such as training-data overlap between the probed LMs and the 200+ datasets or differences in pretraining objectives; without these, the attribution to architecture/tuning rather than data leakage cannot be isolated.
Authors: We acknowledge the potential confound. Because training data for most of the 50+ models is not fully public, exhaustive overlap checks across 200+ datasets are not feasible. We will add an explicit limitations paragraph discussing this issue and will verify overlaps where training data is known; the consistency of effects across independently collected probing datasets from 270 studies provides supporting evidence that the architecture and tuning signals are not solely due to leakage. revision: partial
Circularity Check
Benchmark aggregates existing datasets; central claims are empirical observations with no reduction to fitted inputs or self-citation chains by construction
full rationale
The paper compiles Holmes from >200 existing datasets drawn from a review of 270 prior probing studies and applies classifier-based probing to >50 LMs to report size correlations plus architecture and instruction-tuning effects. No equations define a quantity in terms of itself, no parameters are fitted on a subset and then relabeled as predictions of closely related quantities, and no load-bearing premise rests on a self-citation whose validity is unverified outside the present work. The derivation chain consists of dataset aggregation followed by direct empirical measurement and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classifier-based probing on frozen representations measures unconscious linguistic competence independent of task performance.
Reference graph
Works this paper leans on
-
[1]
What you can cram into a single $&!#* vector: Probing sentence embeddings for lin- guistic properties. In Proceedings of the 56th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers) , pages 2126–2136, Melbourne, Australia. Asso- ciation for Computational Linguistics. Mike Conover, Matt Hayes, Ankit Mathur, Jian- wei X...
-
[2]
Debertav3: Improving deberta us- ing electra-style pre-training with gradient- disentangled embedding sharing. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. 2021. Deberta: decoding- enhanced bert with disentangled at...
-
[3]
Discourse probing of pretrained language models. In Proceedings of the 2021 Confer- ence of the North American Chapter of the As- sociation for Computational Linguistics: Hu- man Language Technologies, pages 3849–3864, Online. Association for Computational Linguis- tics. Katarzyna Krasnowska-Kiera ´s and Alina Wróblewska. 2019. Empirical linguistic study ...
work page 2021
-
[4]
BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceed- ings of the 58th Annual Meeting of the As- sociation for Computational Linguistics , pages 7871–7880, Online. Association for Computa- tional Linguistics. Percy Liang, Rishi Bommasani, Tony Lee, Dim- itris Tsipras, Dilara Soylu, M...
-
[5]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Holistic evaluation of language models. Transactions on Machine Learning Research . Featured Certification, Expert Certification. Tal Linzen, Emmanuel Dupoux, and Yoav Gold- berg. 2016. Assessing the ability of LSTMs to learn syntax-sensitive dependencies. Transac- tions of the Association for Computational Lin- guistics, 4:521–535. Yinhan Liu, Myle Ott, ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Are emergent abilities in large lan- guage models just in-context learning? CoRR, abs/2309.01809. Kyle Mahowald, Anna A. Ivanova, Idan A. Blank, Nancy Kanwisher, Joshua B. Tenenbaum, and Evelina Fedorenko. 2024. Dissociating lan- guage and thought in large language models. Trends in Cognitive Sciences. Peter Hugoe Matthews. 2014. The concise Ox- ford dict...
-
[7]
State of what art? A call for multi-prompt LLM evaluation. CoRR, abs/2401.00595. Michael Mohler, Mary Brunson, Bryan Rink, and Marc Tomlinson. 2016. Introducing the LCC metaphor datasets. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16) , pages 4221–4227, Portorož, Slovenia. European Lan- guage Resources ...
-
[8]
DisSent: Learning sentence represen- tations from explicit discourse relations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 4497–4510, Florence, Italy. Association for Computational Linguistics. Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. 2020. Adversarial NLI:...
-
[9]
Language models are unsupervised mul- titask learners. OpenAI blog, 1(8):9. Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu
-
[10]
Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67. Robert Henry Robins. 2013. A short history of linguistics. Routledge. Pedro Rodriguez, Joe Barrow, Alexander Miserlis Hoyle, John P. Lalor, Robin Jia, and Jor- dan Boyd-Graber. 2021. Evaluation examples are not equally inf...
-
[11]
Llama 2: Open Foundation and Fine-Tuned Chat Models
BEIR: A heterogeneous benchmark for zero-shot evaluation of information retrieval models. In Proceedings of the Neural Informa- tion Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Bench- marks 2021, December 2021, virtual. Lucas Torroba Hennigen, Adina Williams, and Ryan Cotterell. 2020. Intrinsic probing through dimension sel...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[12]
How far can camels go? exploring the state of instruction tuning on open resources. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural In- formation Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Yizhong Wang, Swaroop Mishra, Pegah Alipoor- molabashi, Yeganeh Kordi, Amirreza Mirzaei, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Probelm: Plausibility ranking evaluation for language models. CoRR, abs/2404.03818. Amir Zeldes. 2017. The GUM corpus: Creat- ing multilayer resources in the classroom. Lan- guage Resources and Evaluation , 51(3):581– 612. Xikun Zhang, Deepak Ramachandran, Ian Tenney, Yanai Elazar, and Dan Roth. 2020. Do language embeddings capture scales? In Proceedings ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.