metasnf: Meta Clustering with Similarity Network Fusion in R
Pith reviewed 2026-05-23 18:59 UTC · model grok-4.3
The pith
The metasnf R package applies meta clustering to SNF solutions so users can select clusters by context-specific usefulness instead of standard quality metrics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Meta clustering of SNF cluster solutions surfaces groupings that align with context-specific utility criteria rather than context-agnostic measures of cluster quality.
What carries the argument
Meta clustering applied to a collection of SNF-derived cluster solutions, where the solutions themselves become the input data for a second round of clustering.
If this is right
- Users can search a wider range of SNF cluster solutions without manual inspection of each one.
- Cluster selection can incorporate external or domain-specific criteria instead of relying solely on silhouette scores or similar measures.
- The same meta-clustering step can be combined with the package's visualization and validation tools to inspect the chosen groupings.
- SNf-based subtype discovery workflows gain an additional layer that organizes solutions by similarity before final selection.
Where Pith is reading between the lines
- The approach could be tested on non-biomedical multi-modal datasets to check whether the utility advantage holds outside the paper's primary domain.
- If meta-clusters correspond to distinct biological mechanisms, downstream analyses might focus on one meta-cluster at a time rather than on individual solutions.
- The method assumes that proximity in the space of cluster solutions correlates with similarity in practical usefulness, which could be checked by comparing meta-cluster membership against independent utility labels.
Load-bearing premise
Clustering the cluster solutions themselves will reliably produce groups that are more useful under context-specific criteria than solutions chosen by standard quality metrics.
What would settle it
On a dataset with an independently measured context-specific utility score, the meta-clustered solutions show no higher average utility than solutions chosen by conventional internal validation metrics.
Figures









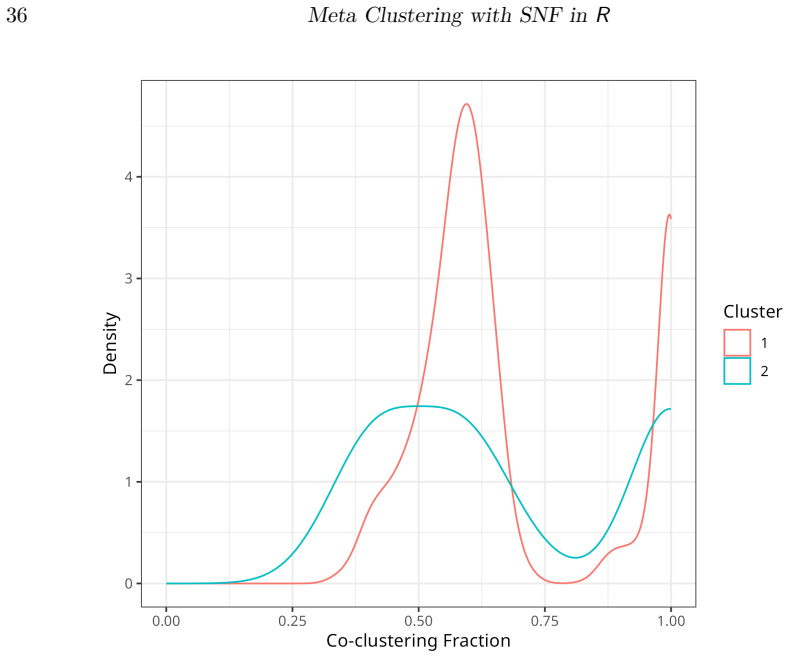
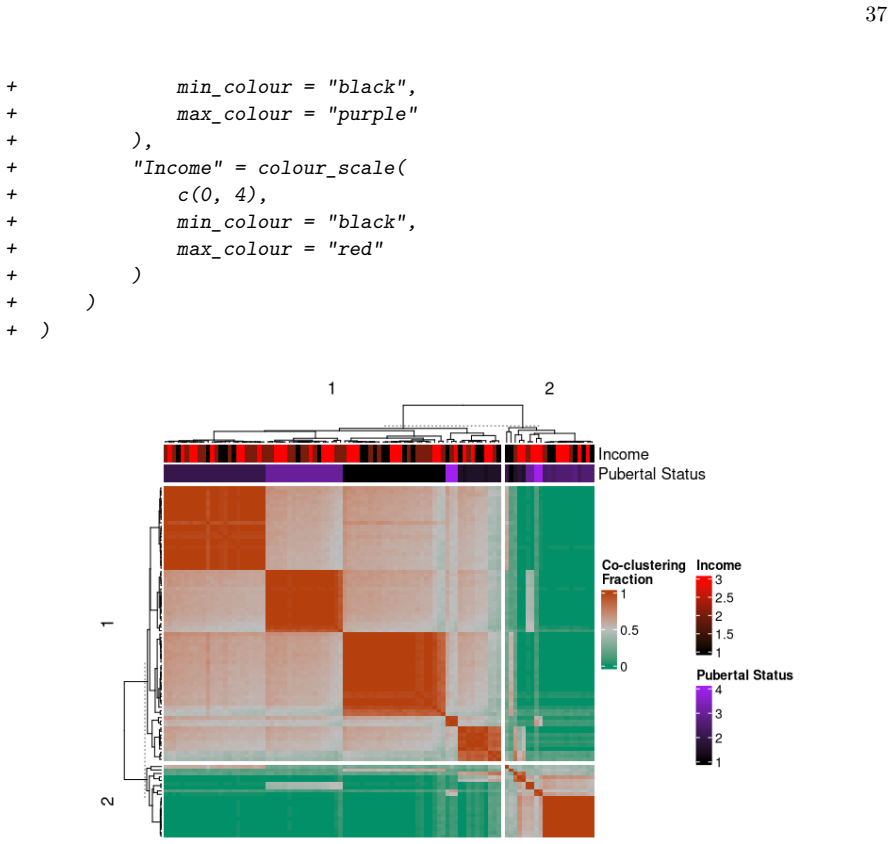








read the original abstract
metasnf is an R package that enables users to apply meta clustering, a method for efficiently searching a broad space of cluster solutions by clustering the solutions themselves, to clustering workflows based on similarity network fusion (SNF). SNF is a multi-modal data integration algorithm commonly used for biomedical subtype discovery. The package also contains functions to assist with cluster visualization, characterization, and validation. This package can help researchers identify SNF-derived cluster solutions that are guided by context-specific utility over context-agnostic measures of quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the metasnf R package, which implements meta-clustering on SNF-derived cluster solutions to enable efficient search over a broad space of clustering outcomes from multi-modal data integration. It also provides supporting functions for cluster visualization, characterization, and validation. The central claim is that this approach allows identification of SNF cluster solutions guided by context-specific utility rather than standard, context-agnostic quality metrics.
Significance. If the package implements the described functionality correctly, it supplies a practical R tool for biomedical researchers using SNF for subtype discovery, addressing the common issue of selecting among many possible cluster solutions. The work is a software contribution rather than a methodological advance or empirical demonstration; no machine-checked proofs, reproducible benchmarks, or falsifiable predictions are included.
major comments (2)
- [Abstract] Abstract: the assertion that the package 'can help researchers identify SNF-derived cluster solutions that are guided by context-specific utility over context-agnostic measures of quality' is presented as a capability without any accompanying code examples, simulated or real-data demonstrations, or comparisons showing that meta-clustering yields solutions preferred under context-specific criteria.
- The manuscript supplies no validation results, error analysis, or benchmarks against existing SNF or clustering packages, leaving the practical utility of the meta-clustering workflow unsupported by evidence.
minor comments (1)
- The manuscript would be strengthened by including at least one worked example (e.g., code and output) illustrating the meta-clustering workflow on a small dataset.
Simulated Author's Rebuttal
We thank the referee for their review of our manuscript on the metasnf R package. We address the major comments below, noting that this is a software description paper focused on providing practical tools for SNF workflows rather than a methodological contribution with new empirical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the package 'can help researchers identify SNF-derived cluster solutions that are guided by context-specific utility over context-agnostic measures of quality' is presented as a capability without any accompanying code examples, simulated or real-data demonstrations, or comparisons showing that meta-clustering yields solutions preferred under context-specific criteria.
Authors: We agree that the abstract claim would be strengthened by explicit support. The package is designed to enable users to apply meta-clustering and then evaluate solutions using any context-specific criteria they define (e.g., alignment with external labels or domain knowledge). In the revised manuscript we will add a dedicated section with code examples and a simulated-data demonstration illustrating this workflow. revision: yes
-
Referee: The manuscript supplies no validation results, error analysis, or benchmarks against existing SNF or clustering packages, leaving the practical utility of the meta-clustering workflow unsupported by evidence.
Authors: As a software contribution paper, the primary goal is to document the implemented functionality rather than to conduct comparative benchmarks. We acknowledge that the current manuscript does not include validation results or error analysis. To address the concern we will incorporate a short example workflow section that applies standard cluster validation metrics to meta-clustered solutions on simulated data. revision: yes
Circularity Check
No significant circularity; software description only
full rationale
The manuscript is a package announcement describing the metasnf R package and its meta-clustering functionality for SNF workflows. It contains no equations, no derivation chain, no fitted parameters presented as predictions, and no load-bearing self-citations of mathematical results. The central claim is purely descriptive of what the software enables (searching cluster solutions via meta-clustering for context-specific utility), with no reduction of any asserted result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
metasnf is an R package that enables users to apply meta clustering... to clustering workflows based on similarity network fusion (SNF).
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The meta clustering procedure proposed by Caruana et al. (2006) to address... disparities between context-agnostic metrics of cluster quality and context-specific usefulness
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
summarize_dl: Return a summary of the data present in adata_list. R> summarize_dl(data_list) name type domain length width 1 subcortical_volume continuous neuroimaging 87 31 2 household_income continuous demographics 87 2 3 pubertal_status continuous demographics 87 2 R> summarize_dl(data_list, scope = "feature") name type domain 1 smri_vol_scs_cbwmatterl...
-
[2]
collapse_dl: Convert adata_list to a single data frame. R> collapse_dl(data_list) R> class(collapse_dl(data_list)) "tbl_df" "tbl" "data.frame" C. Alternative formats for data list generation C.1. Named nested components Explicitly specifying each nested component during data list creation can improve code legi- bility. R> library("metasnf") R> heart_rate_...
work page 1990
-
[3]
spectral_eigen: Number of clusters determined by eigen-gap heuristic
-
[4]
spectral_rot: Number of clusters determined by rotation cost heuristic
-
[5]
spectral_two: Yields a two cluster solution 59
-
[6]
spectral_three: Yields a three cluster solution
-
[7]
And so on, up tospectral_eight. A custom clustering algorithms list can be created by adding more clustering algorithms to sample from: R> clust_algs_list <- generate_clust_algs_list( + "two_cluster_spectral" = spectral_two, + "five_cluster_spectral" = spectral_five + ) R> summarize_clust_algs_list(clust_algs_list) alg_number algorithm 1 1 spectral_eigen ...
-
[8]
The function takes a singleN × N similarity (not distance) matrix as its only input
-
[9]
The function returns a named list with two components: • The first item (named "solution") is a single N-dimensional vector of numbers corresponding to the observations in the similarity matrix • The second item (named "nclust") is a single integer indicating the number of clusters that the algorithm is supposed to have generated The function should not t...
-
[10]
euclidean_distance Discrete distances:
-
[11]
euclidean_distance Ordinal distances:
-
[14]
The first layer of the list contains one element per feature type
gower_distance The distance metrics list is a named, nested list. The first layer of the list contains one element per feature type. Each of those elements contains a list of any number of distance calculating 62 Meta Clustering with SNF in R functions. The distance calculating functions themselves accept raw input data frames and a vector of feature weig...
-
[15]
euclidean_distance (Euclidean distance):
-
[16]
sn_euclidean_distance (Standardized and normalized Euclidean distance): • Standardizes and normalizes data prior to Euclidean distance calculation
-
[17]
gower_distance (Gower’s distance):
-
[18]
siw_euclidean_distance (Squared, including weights, Euclidean distance) • Applyfeatureweightsifprovidedtodataframe, thencalculatesEuclideandistance, then squares the results
-
[19]
sew_euclidean_distance (Squared, excluding weights, Euclidean distance) • Apply square root of feature weights to data frame, then calculates Euclidean distance, then squares the results
-
[20]
hamming_distance (Hamming distance) Any of these functions can be accessed upon loadingmetasnf and can be formatted into a custom distance_metrics_list as follows: R> my_distance_metrics <- generate_distance_metrics_list( + continuous_distances = list( + "standard_norm_euclidean" = sn_euclidean_distance + ), + discrete_distances = list( + "standard_norm_e...
-
[21]
standard_norm_euclidean 63 Discrete distances:
-
[22]
standard_norm_euclidean Ordinal distances:
-
[23]
euclidean_distance Categorical distances:
-
[24]
gower_distance Mixed distances:
-
[25]
gower_distance To replace the default distance metrics rather than add on to them, thekeep_defaults parameter can be set to FALSE during distance metrics list generation. In this case, users must ensure that at least one metric is provided for each of the 5 recognized feature types (continuous, discrete, ordinal, categorical, and mixed). This distance met...
-
[26]
The first parameter,df, is a data frame that contains no UID column and contains an arbitrary number of feature columns
-
[27]
The second parameter,weights_row is a named vector of weights corresponding to the features in df. While it is necessary for the function to accept aweights_row, it is not necessary for the function to make use of this row. When writing code to apply weights to features within a function, one common approach is to convert theweights_row to a diagonal matr...
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.