MissNODAG: Differentiable Cyclic Causal Graph Learning from Incomplete Data
Pith reviewed 2026-05-23 19:12 UTC · model grok-4.3
The pith
MissNODAG recovers both cyclic causal graphs and the missingness mechanism from partially observed data by alternating imputation with likelihood maximization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MissNODAG integrates an additive noise model with an expectation-maximization procedure that alternates between imputing missing values and optimizing the observed data likelihood, thereby recovering both the underlying cyclic causal graph and the missingness mechanism from partially observed data, including data missing not at random, and establishes consistency guarantees under exact maximization of the score function in the large-sample limit.
What carries the argument
The alternating imputation and likelihood-optimization loop inside a differentiable additive-noise-model framework that jointly updates graph parameters and missingness parameters.
If this is right
- Causal graphs containing feedback loops become identifiable from incomplete records.
- Missingness mechanisms that depend on the unobserved values themselves can be recovered alongside the graph.
- Consistency of the recovered graph and missingness parameters holds when the score function is maximized exactly as the number of samples grows.
- The same procedure applies to both synthetic data generated from known cyclic models and real gene-perturbation measurements.
Where Pith is reading between the lines
- The differentiability of the framework opens the possibility of scaling the method to graphs with hundreds of nodes by replacing the inner optimization with gradient steps.
- If the additive noise assumption is relaxed to other identifiable noise models, the same alternating structure might extend to non-Gaussian or heteroscedastic settings without changing the outer EM loop.
- Success on gene data suggests the method could be tested on other domains where both cycles and non-random missingness appear, such as longitudinal health records or sensor networks.
Load-bearing premise
The observed data are generated by an additive noise model whose parameters and missingness mechanism can be recovered together by alternating imputation steps with direct maximization of the observed likelihood.
What would settle it
A large-sample simulation in which the true cyclic graph and missingness parameters are known but the alternating procedure returns inconsistent estimates even when the score is maximized exactly at each iteration.
Figures





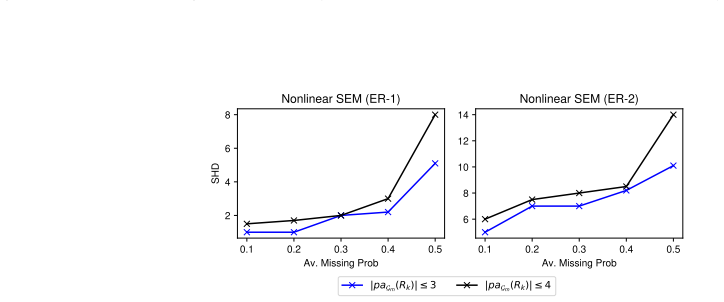



read the original abstract
Causal discovery in real-world systems, such as biological networks, is often complicated by feedback loops and incomplete data. Standard algorithms, which assume acyclic structures or fully observed data, struggle with these challenges. To address this gap, we propose MissNODAG, a differentiable framework for learning both the underlying cyclic causal graph and the missingness mechanism from partially observed data, including data missing not at random. Our framework integrates an additive noise model with an expectation-maximization procedure, alternating between imputing missing values and optimizing the observed data likelihood, to uncover both the cyclic structures and the missingness mechanism. We establish consistency guarantees under exact maximization of the score function in the large sample setting. Finally, we demonstrate the effectiveness of MissNODAG through synthetic experiments and an application to real-world gene perturbation data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MissNODAG, a differentiable framework combining an additive noise model with an EM-style procedure (alternating imputation and likelihood optimization) to jointly recover cyclic causal graphs and missingness mechanisms (including MNAR) from incomplete data. It claims consistency guarantees under exact maximization of the observed-data score in the large-sample limit and reports effectiveness on synthetic experiments plus a real-world gene perturbation application.
Significance. If the consistency result and the optimization procedure can be aligned, the work would address an important gap in causal discovery for cyclic systems with incomplete observations. The integration of differentiability with cyclic ANMs and MNAR handling is a potentially useful technical contribution, though its practical impact depends on closing the gap between the exact-maximizer theorem and the implemented alternating algorithm.
major comments (2)
- [Abstract] Abstract: The consistency theorem is stated only for exact global maximization of the score function. The described algorithm instead alternates imputation with gradient-based maximization of a differentiable surrogate over graph parameters and missingness mechanism. For non-convex observed-data likelihoods arising from cyclic ANMs, this procedure has no guarantee of reaching the global maximizer, so the theorem does not directly apply to the output of MissNODAG. This gap is load-bearing for the central claim that the method 'uncovers' the true graph and missingness mechanism.
- [Abstract] Abstract (and § on method): The paper does not appear to provide a proof or argument that the alternating optimization converges to the exact maximizer (or to a point whose implied graph is consistent) for the non-convex cyclic case with MNAR parameters. Without such a result or additional assumptions that rule out spurious stationary points, the consistency guarantee remains disconnected from the implemented procedure.
minor comments (1)
- [Abstract] The abstract refers to 'synthetic experiments' and 'real-world gene perturbation data' but provides no quantitative metrics, baseline comparisons, or controls for the missingness mechanism; these details should be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the important distinction between the consistency result under exact maximization and the practical alternating optimization procedure. We address the two major comments below and will revise the manuscript to clarify the scope of the theoretical claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The consistency theorem is stated only for exact global maximization of the score function. The described algorithm instead alternates imputation with gradient-based maximization of a differentiable surrogate over graph parameters and missingness mechanism. For non-convex observed-data likelihoods arising from cyclic ANMs, this procedure has no guarantee of reaching the global maximizer, so the theorem does not directly apply to the output of MissNODAG. This gap is load-bearing for the central claim that the method 'uncovers' the true graph and missingness mechanism.
Authors: We agree that the consistency theorem applies strictly to exact global maximization of the observed-data score, while the implemented MissNODAG algorithm performs alternating imputation and gradient-based optimization of a surrogate, which offers no global optimality guarantee in the non-convex setting induced by cyclic ANMs and MNAR parameters. This is a substantive gap. In the revision we will modify the abstract, introduction, and theoretical section to state explicitly that consistency holds under the assumption of exact maximization (as currently written), and we will add a dedicated paragraph in the method section discussing the distinction, the non-convexity challenges, and the fact that the algorithm is a practical heuristic whose output may correspond to local optima. revision: yes
-
Referee: [Abstract] Abstract (and § on method): The paper does not appear to provide a proof or argument that the alternating optimization converges to the exact maximizer (or to a point whose implied graph is consistent) for the non-convex cyclic case with MNAR parameters. Without such a result or additional assumptions that rule out spurious stationary points, the consistency guarantee remains disconnected from the implemented procedure.
Authors: We confirm that the manuscript contains no convergence argument showing that the alternating procedure reaches the global maximizer or a consistent graph estimator in the non-convex cyclic MNAR setting. Deriving such a guarantee would require additional assumptions or analysis that are not present. In revision we will therefore weaken the language in the abstract and method description to avoid implying that the implemented algorithm inherits the consistency result, and we will include an explicit caveat about possible local optima and sensitivity to initialization, supported by the existing synthetic experiments that demonstrate practical performance. revision: yes
- A proof or argument establishing convergence of the alternating optimization to the exact global maximizer (or to a consistent estimator) for non-convex cyclic ANMs with MNAR parameters
Circularity Check
No significant circularity; consistency theorem stated separately from algorithmic procedure
full rationale
The provided abstract and text present a consistency guarantee explicitly conditioned on exact maximization of the observed-data score in the large-sample limit. This is a standard asymptotic statement and does not reduce by construction to the EM-style alternating imputation/optimization steps actually implemented. No equations, self-citations, or fitted parameters are shown to be renamed as predictions or to define the target graph by tautology. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Data generated by additive noise model
Reference graph
Works this paper leans on
-
[1]
Am \'e ndola, C., Dettling, P., Drton, M., Onori, F., and Wu, J. (2020). Structure learning for cyclic linear causal models. In Conference on Uncertainty in Artificial Intelligence , pages 999--1008. PMLR
work page 2020
-
[2]
T., Duvenaud, D., and Jacobsen, J.-H
Behrmann, J., Grathwohl, W., Chen, R. T., Duvenaud, D., and Jacobsen, J.-H. (2019). Invertible residual networks. In International Conference on Machine Learning , pages 573--582. PMLR
work page 2019
-
[3]
Bhattacharya, R., Nabi, R., Shpitser, I., and Robins, J. M. (2020). Identification in missing data models represented by directed acyclic graphs. In Uncertainty in artificial intelligence , pages 1149--1158. PMLR
work page 2020
-
[4]
Bhattacharya, R., Nagarajan, T., Malinsky, D., and Shpitser, I. (2021). Differentiable causal discovery under unmeasured confounding. In International Conference on Artificial Intelligence and Statistics , pages 2314--2322. PMLR
work page 2021
-
[5]
Bollen, K. A. (1989). Structural equations with latent variables , volume 210. John Wiley & Sons
work page 1989
-
[6]
Carter, R. L. (2006). Solutions for missing data in structural equation modeling. Research & Practice in Assessment , 1:4--7
work page 2006
-
[7]
Chen, L. S., Prentice, R. L., and Wang, P. (2014). A penalized em algorithm incorporating missing data mechanism for gaussian parameter estimation. Biometrics , 70(2):312--322
work page 2014
-
[8]
Chen, R. T., Behrmann, J., Duvenaud, D. K., and Jacobsen, J.-H. (2019). Residual flows for invertible generative modeling. Advances in Neural Information Processing Systems , 32
work page 2019
-
[9]
Drton, M., Fox, C., and Wang, Y. S. (2019). Computation of maximum likelihood estimates in cyclic structural equation models . The Annals of Statistics , 47(2):663 -- 690
work page 2019
-
[10]
Frangieh, C. J., Melms, J. C., Thakore, P. I., Geiger-Schuller, K. R., Ho, P., Luoma, A. M., Cleary, B., Jerby-Arnon, L., Malu, S., Cuoco, M. S., et al. (2021). Multimodal pooled Perturb - CITE - seq screens in patient models define mechanisms of cancer immune evasion. Nature genetics , 53(3):332--341
work page 2021
-
[11]
W., Shaked, O., Naqvi, S., Sinnott-Armstrong, N., Kathiria, A., Garrido, C
Freimer, J. W., Shaked, O., Naqvi, S., Sinnott-Armstrong, N., Kathiria, A., Garrido, C. M., Chen, A. F., Cortez, J. T., Greenleaf, W. J., Pritchard, J. K., and Marson, A. (2022). Systematic discovery and perturbation of regulatory genes in human T cells reveals the architecture of immune networks. Nature Genetics , pages 1--12
work page 2022
-
[12]
Friedman, N. (1998). The bayesian structural em algorithm. In Conference on Uncertainty in Artificial Intelligence
work page 1998
-
[13]
Gain, A. and Shpitser, I. (2018). Structure learning under missing data. In International conference on probabilistic graphical models , pages 121--132. PMLR
work page 2018
-
[14]
Gao, E., Ng, I., Gong, M., Shen, L., Huang, W., Liu, T., Zhang, K., and Bondell, H. (2022). Missdag: Causal discovery in the presence of missing data with continuous additive noise models. Advances in Neural Information Processing Systems , 35:5024--5038
work page 2022
-
[15]
Getzen, E., Ungar, L., Mowery, D., Jiang, X., and Long, Q. (2023). Mining for equitable health: Assessing the impact of missing data in electronic health records. Journal of biomedical informatics , 139:104269
work page 2023
-
[16]
Ghassami, A., Yang, A., Kiyavash, N., and Zhang, K. (2020). Characterizing distribution equivalence and structure learning for cyclic and acyclic directed graphs. In International Conference on Machine Learning , pages 3494--3504. PMLR
work page 2020
-
[17]
Guo, A., Zhao, J., and Nabi, R. (2023). Sufficient identification conditions and semiparametric estimation under missing not at random mechanisms. In Uncertainty in Artificial Intelligence , pages 777--787. PMLR
work page 2023
-
[18]
Hall, B. C. (2013). Lie Groups, Lie Algebras, and Representations , pages 333--366. Springer New York, New York, NY
work page 2013
-
[19]
Hauser, A. and B \"u hlmann, P. (2012). Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs. The Journal of Machine Learning Research , 13(1):2409--2464
work page 2012
-
[20]
Heinze-Deml, C., Peters, J., and Meinshausen, N. (2018). Invariant causal prediction for nonlinear models. Journal of Causal Inference , 6(2)
work page 2018
-
[21]
Huetter, J.-C. and Rigollet, P. (2020). Estimation rates for sparse linear cyclic causal models. In Peters, J. and Sontag, D., editors, Proceedings of the 36th Conference on Uncertainty in Artificial Intelligence (UAI) , volume 124 of Proceedings of Machine Learning Research , pages 1169--1178. PMLR
work page 2020
-
[22]
Hutchinson, M. F. (1989). A stochastic estimator of the trace of the influence matrix for L aplacian smoothing splines. Communications in Statistics-Simulation and Computation , 18(3):1059--1076
work page 1989
-
[23]
Hyttinen, A., Eberhardt, F., and Hoyer, P. O. (2012). Learning linear cyclic causal models with latent variables. The Journal of Machine Learning Research , 13(1):3387--3439
work page 2012
-
[24]
Imbens, G. W. and Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences . Cambridge University Press
work page 2015
-
[25]
Jang, E., Gu, S., and Poole, B. (2016). Categorical reparameterization with G umbel- S oftmax. arXiv preprint arXiv:1611.01144
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Kingma, D. P. and Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[27]
Koller, D. and Friedman, N. (2009). Probabilistic graphical models: principles and techniques . MIT press
work page 2009
-
[28]
Kyono, T., Zhang, Y., Bellot, A., and van der Schaar, M. (2021). Miracle: Causally-aware imputation via learning missing data mechanisms. Advances in Neural Information Processing Systems , 34:23806--23817
work page 2021
-
[29]
Lacerda, G., Spirtes, P., Ramsey, J., and Hoyer, P. O. (2008). Discovering cyclic causal models by independent components analysis. In Proceedings of the Twenty-Fourth Conference on Uncertainty in Artificial Intelligence , UAI'08, page 366–374, Arlington, Virginia, USA. AUAI Press
work page 2008
-
[30]
Lee, H.-C., Danieletto, M., Miotto, R., Cherng, S. T., and Dudley, J. T. (2019). Scaling structural learning with NO-BEARS to infer causal transcriptome networks. In Pacific Symposium on Biocomputing 2020 , pages 391--402. World Scientific
work page 2019
-
[31]
C.-X., Jiang, B., and Marlin, B
Li, S. C.-X., Jiang, B., and Marlin, B. (2019). Learning from incomplete data with generative adversarial networks. In International Conference on Learning Representations
work page 2019
-
[32]
Little, R. J. and Rubin, D. B. (2019). Statistical analysis with missing data , volume 793. John Wiley & Sons
work page 2019
-
[33]
Lopez, R., H \"u tter, J.-C., Pritchard, J., and Regev, A. (2022). Large-scale differentiable causal discovery of factor graphs. Advances in Neural Information Processing Systems , 35:19290--19303
work page 2022
-
[34]
Luo, Y., Cai, X., Zhang, Y., Xu, J., et al. (2018). Multivariate time series imputation with generative adversarial networks. Advances in neural information processing systems , 31
work page 2018
-
[35]
Meek, C. (1997). Graphical Models: Selecting causal and statistical models . PhD thesis, Carnegie Mellon University
work page 1997
-
[36]
Mohan, K. and Pearl, J. (2021). Graphical models for processing missing data. Journal of the American Statistical Association , 116(534):1023--1037
work page 2021
-
[37]
Mohan, K., Pearl, J., and Tian, J. (2013). Graphical models for inference with missing data. In Burges, C., Bottou, L., Welling, M., Ghahramani, Z., and Weinberger, K., editors, Advances in Neural Information Processing Systems , volume 26. Curran Associates, Inc
work page 2013
-
[38]
Mooij, J. M. and Heskes, T. (2013). Cyclic causal discovery from continuous equilibrium data. In Uncertainty in Artificial Intelligence
work page 2013
-
[39]
Muzellec, B., Josse, J., Boyer, C., and Cuturi, M. (2020). Missing data imputation using optimal transport. In International Conference on Machine Learning , pages 7130--7140. PMLR
work page 2020
-
[40]
Nabi, R. and Bhattacharya, R. (2023). On testability and goodness of fit tests in missing data models. In Uncertainty in Artificial Intelligence , pages 1467--1477. PMLR
work page 2023
-
[41]
Nabi, R., Bhattacharya, R., and Shpitser, I. (2020). Full law identification in graphical models of missing data: Completeness results. In International conference on machine learning , pages 7153--7163. PMLR
work page 2020
- [42]
-
[43]
Ng, I., Ghassami, A., and Zhang, K. (2020). On the role of sparsity and DAG constraints for learning linear dags. Advances in Neural Information Processing Systems , 33:17943--17954
work page 2020
-
[44]
Ng, I., Zhu, S., Fang, Z., Li, H., Chen, Z., and Wang, J. (2022). Masked gradient-based causal structure learning. In Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) , pages 424--432. SIAM
work page 2022
-
[45]
Pearl, J. (2009a). Causality . Cambridge University Press, 2 edition
-
[46]
Pearl, J. (2009b). Causality: Models, Reasoning, and Inference . Cambridge University Press, 2 edition
-
[47]
Richardson, T. (1996). A discovery algorithm for directed cyclic graphs. In Proceedings of the Twelfth international conference on Uncertainty in artificial intelligence , pages 454--461
work page 1996
-
[48]
Rudin, W. (1953). Principles of M athematical A nalysis . McGraw-Hill Book Company, Inc., New York-Toronto-London
work page 1953
-
[49]
Sachs, K., Perez, O., Pe'er, D., Lauffenburger, D. A., and Nolan, G. P. (2005). Causal protein-signaling networks derived from multiparameter single-cell data. Science , 308(5721):523--529
work page 2005
-
[50]
Saeed, B., Belyaeva, A., Wang, Y., and Uhler, C. (2020). Anchored causal inference in the presence of measurement error. In Conference on uncertainty in artificial intelligence , pages 619--628. PMLR
work page 2020
-
[51]
Seaman, S. R. and White, I. R. (2013). Review of inverse probability weighting for dealing with missing data. Statistical methods in medical research , 22(3):278--295
work page 2013
-
[52]
Segal, E., Pe'er, D., Regev, A., Koller, D., Friedman, N., and Jaakkola, T. (2005). Learning module networks. Journal of Machine Learning Research , 6(4)
work page 2005
-
[53]
G., Lopez, R., Mohan, R., Fekri, F., Biancalani, T., and Huetter, J.-C
Sethuraman, M. G., Lopez, R., Mohan, R., Fekri, F., Biancalani, T., and Huetter, J.-C. (2023). Nodags-flow: Nonlinear cyclic causal structure learning. In Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , volume 206 of Proceedings of Machine Learning Research , pages 6371--6387. PMLR
work page 2023
-
[54]
Singh, M. (1997). Learning bayesian networks from incomplete data. AAAI/IAAI , 1001:534--539
work page 1997
- [55]
-
[56]
N., Scheines, R., and Heckerman, D
Spirtes, P., Glymour, C. N., Scheines, R., and Heckerman, D. (2000). Causation, prediction, and search . MIT press
work page 2000
-
[57]
Stekhoven, D. J. and B \"u hlmann, P. (2012). Missforest—non-parametric missing value imputation for mixed-type data. Bioinformatics , 28(1):112--118
work page 2012
-
[58]
V., Visweswaran, S., and Spirtes, P
Strobl, E. V., Visweswaran, S., and Spirtes, P. L. (2018). Fast causal inference with non-random missingness by test-wise deletion. International journal of data science and analytics , 6:47--62
work page 2018
-
[59]
Sulik, J. J., Newlands, N. K., and Long, D. S. (2017). Encoding dependence in bayesian causal networks. Frontiers in Environmental Science , 4:84
work page 2017
-
[60]
Triantafillou, S. and Tsamardinos, I. (2015). Constraint-based causal discovery from multiple interventions over overlapping variable sets. The Journal of Machine Learning Research , 16(1):2147--2205
work page 2015
-
[61]
Tsamardinos, I., Brown, L. E., and Aliferis, C. F. (2006). The max-min hill-climbing bayesian network structure learning algorithm. Machine learning , 65(1):31--78
work page 2006
-
[62]
Tu, R., Zhang, C., Ackermann, P., Mohan, K., Kjellstr \"o m, H., and Zhang, K. (2019). Causal discovery in the presence of missing data. In The 22nd International Conference on Artificial Intelligence and Statistics , pages 1762--1770. PMLR
work page 2019
-
[63]
Van den Broeck, G., Mohan, K., Choi, A., Darwiche, A., and Pearl, J. (2015). Efficient algorithms for bayesian network parameter learning from incomplete data. In Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence , UAI'15, page 161–170, Arlington, Virginia, USA. AUAI Press
work page 2015
- [64]
-
[65]
Wang, Y., Solus, L., Yang, K., and Uhler, C. (2017). Permutation-based causal inference algorithms with interventions. Advances in Neural Information Processing Systems , 30
work page 2017
-
[66]
White, I. R., Royston, P., and Wood, A. M. (2011). Multiple imputation using chained equations: issues and guidance for practice. Statistics in medicine , 30(4):377--399
work page 2011
-
[67]
Wu, C. F. J. (1983). On the Convergence Properties of the EM Algorithm . The Annals of Statistics , 11(1):95 -- 103
work page 1983
-
[68]
Yu, Y., Chen, J., Gao, T., and Yu, M. (2019). DAG-GNN : DAG structure learning with graph neural networks. In International Conference on Machine Learning , pages 7154--7163. PMLR
work page 2019
-
[69]
A., Zhang, C., Xie, T., Tran, L., and Dobrin, R
Zhang, B., Gaiteri, C., Bodea, L.-G., Wang, Z., McElwee, J., Podtelezhnikov, A. A., Zhang, C., Xie, T., Tran, L., and Dobrin, R. (2013). Integrated systems approach identifies genetic nodes and networks in late-onset Alzheimer ’s disease. Cell , 153(3):707--720
work page 2013
-
[70]
Zheng, X., Aragam, B., Ravikumar, P. K., and Xing, E. P. (2018). DAG s with NO TEARS : Continuous optimization for structure learning. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R., editors, Advances in Neural Information Processing Systems , volume 31
work page 2018
-
[71]
Zheng, X., Dan, C., Aragam, B., Ravikumar, P., and Xing, E. (2020). Learning sparse nonparametric DAG s. In Chiappa, S. and Calandra, R., editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics , volume 108, pages 3414--3425
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.