SCASeg: Strip Cross-Attention for Efficient Semantic Segmentation
Pith reviewed 2026-05-23 17:01 UTC · model grok-4.3
The pith
SCASeg replaces skip connections with lateral strip cross-attention using encoder features as queries to achieve competitive segmentation accuracy at higher efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
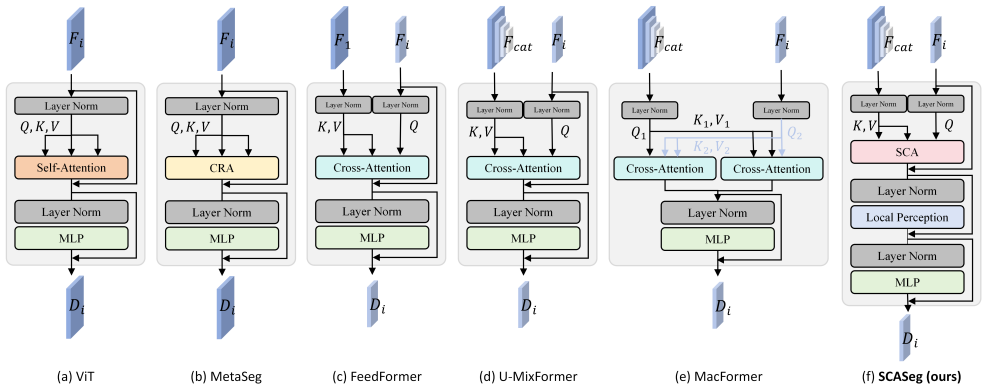
SCASeg establishes that a decoder using encoder features directly as queries in cross-attention, integrated via a Cross-Layer Block that unifies multi-stage features with convolutional local perception, and compressed into strip attention patterns, delivers competitive semantic segmentation performance with greater efficiency than standard decoder designs.
What carries the argument
Strip Cross-Attention with the Cross-Layer Block (CLB), where encoder features serve as queries and compressed hierarchical maps supply keys and values in strip form.
If this is right
- SCASeg adapts to multiple encoder backbones while preserving efficiency gains.
- The strip compression lowers memory footprint and raises inference speed relative to vanilla cross-attention.
- The decoder maintains competitive accuracy on ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012 across different compute budgets.
- CLB integration enables capture of both global dependencies and local context across scales.
Where Pith is reading between the lines
- The channel-compression trick for creating strip attention could be tested in other dense-prediction heads to reduce compute.
- Lateral query design might transfer to related tasks such as instance segmentation or object detection.
- Deployment trials on edge hardware would reveal whether the reported speedups translate to real-time settings.
Load-bearing premise
The design assumes encoder features as queries plus CLB integration and channel compression will reliably boost multi-scale interaction and efficiency without hidden costs to generalization or stability on untested backbones or domains.
What would settle it
A controlled test in which SCASeg underperforms a standard decoder on a previously unused backbone or dataset would show the performance gains do not hold generally.
Figures








read the original abstract
The Vision Transformer (ViT) has achieved notable success in computer vision, with its variants widely validated across various downstream tasks, including semantic segmentation. However, as general-purpose visual encoders, ViT backbones often do not fully address the specific requirements of task decoders, highlighting opportunities for designing decoders optimized for efficient semantic segmentation. This paper proposes Strip Cross-Attention (SCASeg), an innovative decoder head specifically designed for semantic segmentation. Instead of relying on the conventional skip connections, we utilize lateral connections between encoder and decoder stages, leveraging encoder features as Queries in cross-attention modules. Additionally, we introduce a Cross-Layer Block (CLB) that integrates hierarchical feature maps from various encoder and decoder stages to form a unified representation for Keys and Values. The CLB also incorporates the local perceptual strengths of convolution, enabling SCASeg to capture both global and local context dependencies across multiple layers, thus enhancing feature interaction at different scales and improving overall efficiency. To further optimize computational efficiency, SCASeg compresses the channels of queries and keys into one dimension, creating strip-like patterns that reduce memory usage and increase inference speed compared to traditional vanilla cross-attention. Experiments show that SCASeg's adaptable decoder delivers competitive performance across various setups, outperforming leading segmentation architectures on benchmark datasets, including ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012, even under diverse computational constraints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SCASeg, a decoder head for semantic segmentation on ViT backbones. It replaces conventional skip connections with lateral connections that use encoder features as Queries in cross-attention, introduces a Cross-Layer Block (CLB) that fuses hierarchical encoder/decoder maps into Keys and Values while adding convolutional local context, and compresses query/key channels to a single dimension to produce strip-like attention patterns that reduce memory and increase speed. Experiments claim that this decoder outperforms leading segmentation architectures on ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012 under varied computational budgets.
Significance. If the performance claims are robust, the design offers a practical route to more efficient task-specific decoders that combine global cross-attention with local convolution and hierarchical fusion, potentially improving inference speed and memory footprint for ViT-based segmentation without sacrificing accuracy on standard benchmarks.
major comments (2)
- [Method (strip cross-attention and CLB description)] The central efficiency claim rests on compressing query and key channels to one dimension while relying on the CLB convolution path to recover multi-scale interactions; no ablation isolates whether this reduction discards irrecoverable per-channel distinctions that affect representational capacity under distribution shift.
- [Experiments section] The outperformance claims on ADE20K, Cityscapes, COCO-Stuff, and Pascal VOC require explicit reporting of baselines, training protocols, statistical significance, and error bars; the abstract provides none, and the manuscript must demonstrate that gains are not attributable to unstated hyper-parameter advantages or single-run variance.
minor comments (2)
- [Method] Notation for the CLB integration of hierarchical maps should be formalized with explicit equations rather than prose description to allow reproducibility.
- [Figures] Figure captions for attention visualizations should state the exact input resolution and backbone used so readers can interpret the strip patterns.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions that will be incorporated.
read point-by-point responses
-
Referee: [Method (strip cross-attention and CLB description)] The central efficiency claim rests on compressing query and key channels to one dimension while relying on the CLB convolution path to recover multi-scale interactions; no ablation isolates whether this reduction discards irrecoverable per-channel distinctions that affect representational capacity under distribution shift.
Authors: We agree that an explicit ablation isolating the channel compression would strengthen the claims. In the revised manuscript we will add an ablation comparing the 1D strip cross-attention against a full-channel cross-attention variant (both with and without the CLB) on ADE20K and Cityscapes. This will quantify any loss in per-channel representational capacity and confirm that the convolutional path within the CLB recovers the necessary multi-scale interactions. revision: yes
-
Referee: [Experiments section] The outperformance claims on ADE20K, Cityscapes, COCO-Stuff, and Pascal VOC require explicit reporting of baselines, training protocols, statistical significance, and error bars; the abstract provides none, and the manuscript must demonstrate that gains are not attributable to unstated hyper-parameter advantages or single-run variance.
Authors: We will revise the experimental section to include a dedicated table of training hyperparameters and protocols, ensuring all baselines are reproduced under identical settings. We will also report mean and standard deviation over three random seeds for the main results and update the abstract with key quantitative metrics. These additions will demonstrate that the reported gains are robust and not attributable to single-run variance or undisclosed hyper-parameter choices. revision: yes
Circularity Check
No circularity: empirical architecture validated on benchmarks
full rationale
The paper introduces SCASeg as a decoder design using strip cross-attention and CLB, then reports competitive results on ADE20K, Cityscapes, COCO-Stuff, and Pascal VOC via direct experiments. No derivation chain, first-principles predictions, or equations exist that reduce outputs to inputs by construction. Claims rest on benchmark comparisons rather than self-definitional fits, self-citation load-bearing, or renamed known results. This matches the default case of a non-circular empirical CV contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Xcit: Cross-covariance image transformers
Alaaeldin Ali, Hugo Touvron, Mathilde Caron, Piotr Bo- janowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Na- talia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. Xcit: Cross-covariance image transformers. Advances in Neural Information processing Systems, 34:20014–20027, 2021. 2, 5
work page 2021
-
[2]
Medical image segmentation review: The suc- cess of u-net
Reza Azad, Ehsan Khodapanah Aghdam, Amelie Rauland, Yiwei Jia, Atlas Haddadi Avval, Afshin Bozorgpour, Sanaz Karimijafarbigloo, Joseph Paul Cohen, Ehsan Adeli, and Dorit Merhof. Medical image segmentation review: The suc- cess of u-net. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10076–10095, 2024. 1
work page 2024
-
[3]
Coco- stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco- stuff: Thing and stuff classes in context. In CVPR, pages 1209–1218, 2018. 6, 7
work page 2018
-
[4]
Sdpt: Semantic- aware dimension-pooling transformer for image segmenta- tion
Hu Cao, Guang Chen, Hengshuang Zhao, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, and Alois Knoll. Sdpt: Semantic- aware dimension-pooling transformer for image segmenta- tion. IEEE Transactions on Intelligent Transportation Sys- tems, 25(11):15934–15946, 2024. 6
work page 2024
-
[5]
Pem: Prototype-based efficient maskformer for image segmentation
Niccol `o Cavagnero, Gabriele Rosi, Claudia Cuttano, Francesca Pistilli, Marco Ciccone, Giuseppe Averta, and Fabio Cermelli. Pem: Prototype-based efficient maskformer for image segmentation. In CVPR, pages 15804–15813,
-
[6]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for seman- tic image segmentation. arXiv preprint arXiv:1706.05587 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Encoder-decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, pages 801–818, 2018. 2
work page 2018
-
[8]
Per- pixel classification is not all you need for semantic segmen- tation
Bowen Cheng, Alex Schwing, and Alexander Kirillov. Per- pixel classification is not all you need for semantic segmen- tation. Advances in Neural Information Processing Systems, 34:17864–17875, 2021. 1, 3
work page 2021
-
[9]
Masked-attention mask transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In CVPR, pages 1290–1299, 2022. 2
work page 2022
-
[10]
MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark
MMSegmentation Contributors. MMSegmentation: Openmmlab semantic segmentation toolbox and benchmark. https : / / github . com / open - mmlab/mmsegmentation, 2020. 6
work page 2020
-
[11]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In CVPR, pages 3213–3223, 2016. 6, 2, 3, 4
work page 2016
-
[12]
Boundary-aware feature propa- gation for scene segmentation
Henghui Ding, Xudong Jiang, Ai Qun Liu, Nadia Magnenat Thalmann, and Gang Wang. Boundary-aware feature propa- gation for scene segmentation. In ICCV, pages 6819–6829,
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Dual attention network for scene segmentation
Jun Fu, Jing Liu, Haijie Tian, Yong Li, Yongjun Bao, Zhiwei Fang, and Hanqing Lu. Dual attention network for scene segmentation. In CVPR, pages 3146–3154, 2019. 1, 2
work page 2019
-
[15]
Cmt: Convolutional neural networks meet vision transformers
Jianyuan Guo, Kai Han, Han Wu, Yehui Tang, Xinghao Chen, Yunhe Wang, and Chang Xu. Cmt: Convolutional neural networks meet vision transformers. In CVPR, pages 12175–12185, 2022. 2, 5
work page 2022
-
[16]
Segnext: Rethink- ing convolutional attention design for semantic segmenta- tion
Meng-Hao Guo, Cheng-Ze Lu, Qibin Hou, Zhengning Liu, Ming-Ming Cheng, and Shi-Min Hu. Segnext: Rethink- ing convolutional attention design for semantic segmenta- tion. Advances in Neural Information Processing Systems , 35:1140–1156, 2022. 1, 2, 6, 7, 3
work page 2022
-
[17]
Adaptive pyramid context network for semantic seg- mentation
Junjun He, Zhongying Deng, Lei Zhou, Yali Wang, and Yu Qiao. Adaptive pyramid context network for semantic seg- mentation. In CVPR, pages 7519–7528, 2019. 2
work page 2019
-
[18]
Derek Hoiem, Santosh K Divvala, and James H Hays. Pas- cal voc 2008 challenge. World Literature Today, 24(1):1–4,
work page 2008
-
[19]
Ccnet: Criss-cross attention for semantic segmentation
Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. Ccnet: Criss-cross attention for semantic segmentation. In ICCV, pages 603– 612, 2019. 2
work page 2019
-
[20]
Metaseg: Metaformer-based global contexts-aware network for efficient semantic segmentation
Beoungwoo Kang, Seunghun Moon, Yubin Cho, Hyunwoo Yu, and Suk-Ju Kang. Metaseg: Metaformer-based global contexts-aware network for efficient semantic segmentation. In WACV, pages 434–443, 2024. 2, 5, 6, 7, 1, 3
work page 2024
-
[21]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. In ICCV, pages 4015–4026, 2023. 1
work page 2023
-
[22]
Lisa: Reasoning segmenta- tion via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmenta- tion via large language model. In CVPR, pages 9579–9589,
-
[23]
Semantic image segmenta- tion with deep convolutional nets and fully connected crfs
Chen Liang-Chieh, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan Yuille. Semantic image segmenta- tion with deep convolutional nets and fully connected crfs. In ICLR, 2015. 2
work page 2015
-
[24]
Scale-aware modulation meet transformer
Weifeng Lin, Ziheng Wu, Jiayu Chen, Jun Huang, and Lian- wen Jin. Scale-aware modulation meet transformer. InICCV, pages 6015–6026, 2023. 2, 5
work page 2023
-
[25]
Auto- deeplab: Hierarchical neural architecture search for semantic image segmentation
Chenxi Liu, Liang-Chieh Chen, Florian Schroff, Hartwig Adam, Wei Hua, Alan L Yuille, and Li Fei-Fei. Auto- deeplab: Hierarchical neural architecture search for semantic image segmentation. In CVPR, pages 82–92, 2019. 2
work page 2019
-
[26]
Bpkd: Boundary privileged knowledge distillation for semantic segmentation
Liyang Liu, Zihan Wang, Minh Hieu Phan, Bowen Zhang, Jinchao Ge, and Yifan Liu. Bpkd: Boundary privileged knowledge distillation for semantic segmentation. In WACV, pages 1062–1072, 2024. 2
work page 2024
-
[27]
Fully convolutional networks for semantic segmentation
Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In CVPR, pages 3431–3440, 2015. 1, 2 9
work page 2015
-
[28]
Efficient modulation for vision net- works
Xu Ma, Xiyang Dai, Jianwei Yang, Bin Xiao, Yinpeng Chen, Yun Fu, and Lu Yuan. Efficient modulation for vision net- works. arXiv preprint arXiv:2403.19963, 2024. 1, 2
-
[29]
Large kernel matters–improve semantic segmenta- tion by global convolutional network
Chao Peng, Xiangyu Zhang, Gang Yu, Guiming Luo, and Jian Sun. Large kernel matters–improve semantic segmenta- tion by global convolutional network. InCVPR, pages 4353– 4361, 2017. 2
work page 2017
-
[30]
A transformer-based decoder for semantic segmentation with multi-level context mining
Bowen Shi, Dongsheng Jiang, Xiaopeng Zhang, Han Li, Wenrui Dai, Junni Zou, Hongkai Xiong, and Qi Tian. A transformer-based decoder for semantic segmentation with multi-level context mining. In ECCV, pages 624–639. Springer, 2022. 1, 2
work page 2022
-
[31]
Feedformer: Revisiting transformer decoder for ef- ficient semantic segmentation
Jae-hun Shim, Hyunwoo Yu, Kyeongbo Kong, and Suk-Ju Kang. Feedformer: Revisiting transformer decoder for ef- ficient semantic segmentation. In AAAI, pages 2263–2271,
-
[32]
Segmenter: Transformer for semantic segmenta- tion
Robin Strudel, Ricardo Garcia, Ivan Laptev, and Cordelia Schmid. Segmenter: Transformer for semantic segmenta- tion. In ICCV, pages 7262–7272, 2021. 2, 3
work page 2021
-
[33]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems, 30:1–11, 2017. 1
work page 2017
-
[34]
Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation
Qiang Wan, Zilong Huang, Jiachen Lu, YU Gang, and Li Zhang. Seaformer: Squeeze-enhanced axial transformer for mobile semantic segmentation. In ICLR, 2023. 6, 2
work page 2023
-
[35]
Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model
Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, Dacheng Tao, and Liangpei Zhang. Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model. Advances in Neural Information Processing Systems, 36, 2024. 1
work page 2024
-
[36]
Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaim- ing He. Non-local neural networks. In CVPR, pages 7794– 7803, 2018. 2
work page 2018
-
[37]
Chunlong Xia, Xinliang Wang, Feng Lv, Xin Hao, and Yifeng Shi. Vit-comer: Vision transformer with convolu- tional multi-scale feature interaction for dense predictions. In CVPR, pages 5493–5502, 2024. 2, 3
work page 2024
-
[38]
Segformer: Simple and efficient design for semantic segmentation with transform- ers
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transform- ers. Advances in Neural Information Processing Systems , 34:12077–12090, 2021. 2, 6, 7, 3
work page 2021
-
[39]
Lightweight real-time semantic seg- mentation network with efficient transformer and cnn
Guoan Xu, Juncheng Li, Guangwei Gao, Huimin Lu, Jian Yang, and Dong Yue. Lightweight real-time semantic seg- mentation network with efficient transformer and cnn. IEEE Transactions on Intelligent Transportation Systems, 24(12): 15897–15906, 2023. 1
work page 2023
-
[40]
Mac- former: Semantic segmentation with fine object boundaries
Guoan Xu, Wenfeng Huang, Tao Wu, Ligeng Chen, Wenjing Jia, Guangwei Gao, Xiatian Zhu, and Stuart Perry. Mac- former: Semantic segmentation with fine object boundaries. arXiv preprint arXiv:2408.05699, 2024. 2, 1
-
[41]
Sctnet: Single-branch cnn with transformer semantic information for real-time segmen- tation
Zhengze Xu, Dongyue Wu, Changqian Yu, Xiangxiang Chu, Nong Sang, and Changxin Gao. Sctnet: Single-branch cnn with transformer semantic information for real-time segmen- tation. In AAAI, pages 6378–6386, 2024. 2, 6
work page 2024
-
[42]
Multi-scale rep- resentations by varing window attention for semantic seg- mentation
Haotian Yan, Ming Wu, and Chuang Zhang. Multi-scale rep- resentations by varing window attention for semantic seg- mentation. In ICLR, 2024. 6
work page 2024
-
[43]
Multi-scale rep- resentations by varying window attention for semantic seg- mentation
Haotian Yan, Ming Wu, and Chuang Zhang. Multi-scale rep- resentations by varying window attention for semantic seg- mentation. In ICLR, 2024. 6, 7, 2, 3
work page 2024
-
[44]
U-mixformer: Unet- like transformer with mix-attention for efficient semantic segmentation
Seul-Ki Yeom and Julian von Klitzing. U-mixformer: Unet- like transformer with mix-attention for efficient semantic segmentation. arXiv preprint arXiv:2312.06272 , 2023. 2, 3, 6, 7, 1
-
[45]
Context prior for scene seg- mentation
Changqian Yu, Jingbo Wang, Changxin Gao, Gang Yu, Chunhua Shen, and Nong Sang. Context prior for scene seg- mentation. In CVPR, pages 12416–12425, 2020. 2
work page 2020
-
[46]
Metaformer is actually what you need for vision
Weihao Yu, Mi Luo, Pan Zhou, Chenyang Si, Yichen Zhou, Xinchao Wang, Jiashi Feng, and Shuicheng Yan. Metaformer is actually what you need for vision. InCVPR, pages 10819– 10829, 2022. 2, 4
work page 2022
-
[47]
Object- contextual representations for semantic segmentation
Yuhui Yuan, Xilin Chen, and Jingdong Wang. Object- contextual representations for semantic segmentation. In ECCV, pages 173–190. Springer, 2020. 1, 2
work page 2020
-
[48]
Segfix: Model-agnostic boundary refinement for segmenta- tion
Yuhui Yuan, Jingyi Xie, Xilin Chen, and Jingdong Wang. Segfix: Model-agnostic boundary refinement for segmenta- tion. In ECCV, pages 489–506. Springer, 2020. 2
work page 2020
-
[49]
Con- text encoding for semantic segmentation
Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Con- text encoding for semantic segmentation. In CVPR, pages 7151–7160, 2018. 1, 2
work page 2018
-
[50]
Joint se- mantic segmentation and boundary detection using iterative pyramid contexts
Mingmin Zhen, Jinglu Wang, Lei Zhou, Shiwei Li, Tianwei Shen, Jiaxiang Shang, Tian Fang, and Long Quan. Joint se- mantic segmentation and boundary detection using iterative pyramid contexts. In CVPR, pages 13666–13675, 2020. 2
work page 2020
-
[51]
Rethinking semantic segmen- tation from a sequence-to-sequence perspective with trans- formers
Sixiao Zheng, Jiachen Lu, Hengshuang Zhao, Xiatian Zhu, Zekun Luo, Yabiao Wang, Yanwei Fu, Jianfeng Feng, Tao Xiang, Philip HS Torr, et al. Rethinking semantic segmen- tation from a sequence-to-sequence perspective with trans- formers. In CVPR, pages 6881–6890, 2021. 2, 3
work page 2021
-
[52]
Squeeze-and-attention networks for semantic segmentation
Zilong Zhong, Zhong Qiu Lin, Rene Bidart, Xiaodan Hu, Ibrahim Ben Daya, Zhifeng Li, Wei-Shi Zheng, Jonathan Li, and Alexander Wong. Squeeze-and-attention networks for semantic segmentation. In CVPR, pages 13065–13074,
-
[53]
Scene parsing through ade20k dataset
Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In CVPR, pages 633–641, 2017. 1, 6, 8, 2, 3 10 SCASeg: Strip Cross-Attention for Efficient Semantic Segmentation Supplementary Material This supplementary document provides additional in- sights and experimental results to compleme...
work page 2017
-
[54]
Relationship of CLB with Existing Attention Blocks In the main paper, we introduced a Cross-Layer Block (CLB) that blends hierarchical feature maps from different encoder and decoder stages to create a unified representa- tion for Keys and Values. In this Supplementary, we il- lustrate the relationship of the proposed Cross-Layer Block (CLB) to other SOTA...
-
[55]
Additional Experimental Comparisons with Medium-weight and Heavy-weight Models In the main paper, we compared the performance of the SCASeg (MiT-B0) with lightweight models. In this Sup- plementary, we present additional experimental comparison conducted with medium-weight and heavy-weight models on ADE20K and Cityscapes. 2.1. Medium-weight Models: As pre...
-
[56]
Additional Visualization Results Fig. 9 shows additional visual comparison of the segmen- tation results obtained on the Cityscapes datasets using our SCASeg and SOTA methods
-
[57]
Additional Ablation Studies Effectiveness of the Local Perception Module (LPM): Table 3 in the main paper also presents the results of com- bining SCA with LPM, forming the complete CLB struc- ture. With the addition of LPM, the parameter count and computational load become comparable to those of CA, while this combination achieves an increase in segmenta...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.