From XAI to MLOps: Explainable Concept Drift Detection with Profile Drift Detection
Pith reviewed 2026-05-23 06:35 UTC · model grok-4.3
The pith
Profile Drift Detection tracks changes in partial dependence profiles to identify concept drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that changes in Partial Dependence Profiles can be turned into drift metrics that detect when the conditional relationship P(Y|X) has shifted, supply an interpretable signal about which features drive the change, and do so with lower computational cost than repeated full retraining or exhaustive distribution comparisons.
What carries the argument
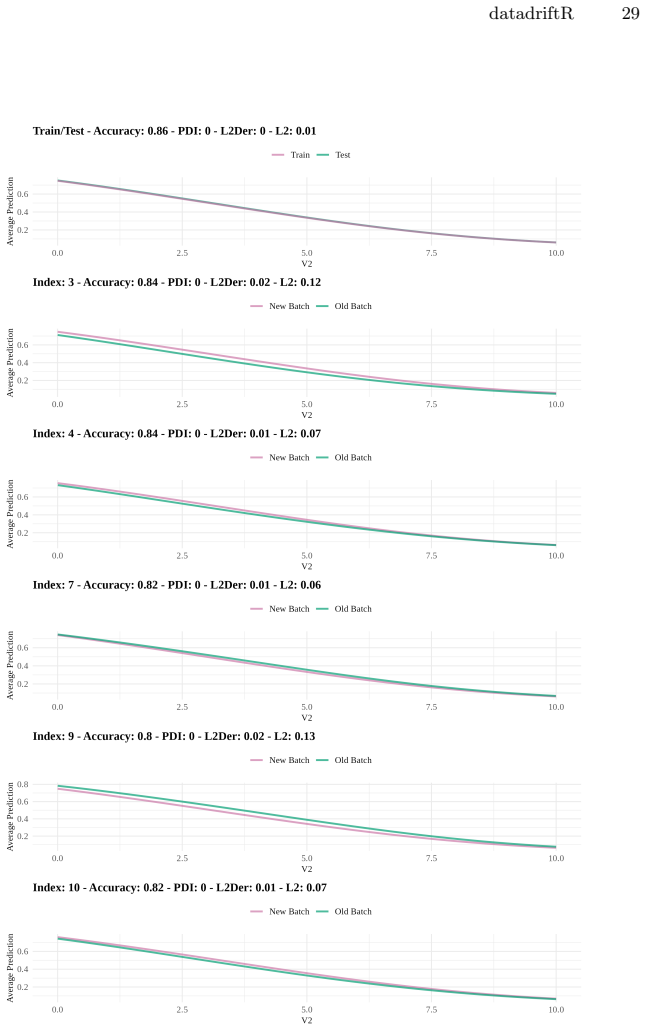
Profile Drift Detection (PDD), which converts differences between successive Partial Dependence Profiles into scalar drift scores using newly defined distance measures.
If this is right
- Model monitoring pipelines can trigger retraining based on profile shifts rather than waiting for accuracy to fall.
- The same PDP data used for drift detection also supplies feature-level explanations of why the drift occurred.
- The computational cost stays low enough for continuous operation on streaming data without full model rebuilds at every step.
- Integration with existing MLOps workflows becomes direct because PDPs are already produced by many explainability libraries.
- Sensitivity-stability trade-offs in drift signals can be tuned by adjusting the profile comparison window or metric threshold.
Where Pith is reading between the lines
- The same profile-based approach might be applied to other local or global explanation methods beyond partial dependence to create a family of drift detectors.
- In regulated domains the explanatory output of PDD could serve as auditable documentation for when and why a model was updated.
- Combining PDD with marginal-distribution drift detectors could separate pure concept drift from covariate shift in a single monitoring layer.
- The efficiency claim suggests the method could scale to high-velocity streams where full PDP recomputation at every batch would otherwise become prohibitive.
Load-bearing premise
That shifts visible in partial dependence profiles reliably indicate changes in the conditional input-output relationship rather than marginal distribution changes, noise, or unrelated artifacts.
What would settle it
A controlled stream containing a documented change only in P(Y|X) where the PDD metrics remain flat while model error rises sharply, or a stream with no P(Y|X) change where PDD metrics trigger repeated alerts.
Figures





read the original abstract
Predictive models often degrade in performance due to evolving data distributions, a phenomenon known as data drift. Among its forms, concept drift, where the relationship between explanatory variables and the response variable changes, is particularly challenging to detect and adapt to. Traditional drift detection methods often rely on metrics such as accuracy or marginal variable distributions, which may fail to capture subtle but important conceptual changes. This paper proposes a novel method, Profile Drift Detection (PDD), which enables both the detection of concept drift and an enhanced understanding of its underlying causes by leveraging an explainable AI tool: Partial Dependence Profiles (PDPs). PDD quantifies changes in PDPs through new drift metrics that are sensitive to shifts in the data stream while remaining computationally efficient. This approach is aligned with MLOps practices, emphasizing continuous model monitoring and adaptive retraining in dynamic environments. Experiments on synthetic and real-world datasets demonstrate that PDD outperforms existing methods by maintaining high predictive performance while effectively balancing sensitivity and stability in drift signals. The results highlight its suitability for real-time applications, and the paper concludes by discussing the method's advantages, limitations, and potential extensions to broader use cases.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Profile Drift Detection (PDD), a method that leverages Partial Dependence Profiles (PDPs) to detect and explain concept drift by quantifying changes via newly defined drift metrics. It claims computational efficiency, alignment with MLOps for continuous monitoring, and outperformance over existing methods on synthetic and real-world datasets in terms of predictive performance and the sensitivity-stability tradeoff in drift signals.
Significance. If the central claims hold, PDD would supply an interpretable, PDP-based alternative to black-box drift detectors, potentially aiding root-cause analysis of drift in production ML systems. The emphasis on efficiency and explainability could support real-time MLOps pipelines, though the absence of detailed experimental protocols limits immediate assessment of practical impact.
major comments (1)
- [Abstract] Abstract: The claim that PDD specifically detects concept drift (changes in P(Y|X)) rests on an untested attribution. PDPs are defined as E[f(X) | X_j = x_j] with the expectation taken over the marginal of the remaining features; therefore shifts in the joint distribution P(X) alone can alter PDPs without any change in the conditional relationship. No reweighting, fixed reference distribution, or decomposition isolating P(Y|X) effects is described.
minor comments (2)
- The abstract asserts outperformance but supplies no information on datasets, baselines, quantitative metrics, detection-delay statistics, or significance tests, impeding evaluation of the experimental claims.
- Notation for the new drift metrics should be introduced with explicit formulas and computational complexity statements to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help clarify the scope of our claims. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that PDD specifically detects concept drift (changes in P(Y|X)) rests on an untested attribution. PDPs are defined as E[f(X) | X_j = x_j] with the expectation taken over the marginal of the remaining features; therefore shifts in the joint distribution P(X) alone can alter PDPs without any change in the conditional relationship. No reweighting, fixed reference distribution, or decomposition isolating P(Y|X) effects is described.
Authors: We appreciate the referee highlighting this subtlety in the definition of partial dependence profiles. The manuscript claims to detect concept drift but does not provide a mechanism to isolate changes in P(Y|X) from those in P(X). We agree that this attribution is not tested or supported by the described method. We will revise the abstract and the main text to accurately describe PDD as detecting changes in PDPs, which can be caused by either type of drift, and elaborate on how this approach still offers explanatory benefits for MLOps monitoring despite not being specific to concept drift alone. This will be addressed in the revised manuscript. revision: yes
Circularity Check
No circularity; new metrics defined on established PDPs
full rationale
The paper defines PDD via novel drift metrics applied to Partial Dependence Profiles, with no equations or claims reducing by construction to fitted parameters, self-citations, or renamed inputs. The abstract and described method frame the contribution as new quantification of PDP changes for drift detection, independent of the target concept-drift signal. No load-bearing self-citation chains or ansatz smuggling appear; the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PDD quantifies changes in PDPs through new drift metrics... L2 distance, first-order derivative distance (L2Der), and the Partial Dependence Index (PDI)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on synthetic and real-world datasets demonstrate that PDD outperforms existing methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alaiz-Rodr \' guez, R., and Japkowicz, N. (2008). Assessing the impact of changing environments on classifier performance. In Advances in Artificial Intelligence, pages 13--24. Springer
work page 2008
-
[2]
Baena-Garc a, M., del Campo- \'A vila, J., Fidalgo, R., Bifet, A., Gavalda, R., and Morales-Bueno, R. (2006). Early drift detection method. In Fourth International Workshop on Knowledge Discovery from Data Streams, volume 6, pages 77--86
work page 2006
-
[3]
Biecek, P. (2019). Model development process. arXiv preprint arXiv:1907.04461
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Biecek, P., and Burzykowski, T. (2021). Explanatory model analysis: explore, explain, and examine predictive models. Chapman and Hall/CRC
work page 2021
-
[5]
A., Jia, H., Travers, A., Zhang, B., Lie, D., and Papernot, N
Bourtoule, L., Chandrasekaran, V., Choquette-Choo, C. A., Jia, H., Travers, A., Zhang, B., Lie, D., and Papernot, N. (2020). Machine Unlearning. arXiv preprint arXiv:1912.03817
-
[6]
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. Springer
work page 2001
-
[7]
Cieslak, D. A., and Chawla, N. V. (2009). A framework for monitoring classifiers’ performance: when and why failure occurs? Knowledge and Information Systems, 18(1):83--108
work page 2009
-
[8]
Dar, U., and Cavus, M. (2023). A novel concept drift detection method based on the partial dependence profile disparity index. In 7th International Researchers, Statisticians, and Young Statisticians Congress
work page 2023
-
[9]
Dar, U., and Cavus, M. (2024). Explainable detection of data drift using partial dependence disparity index in real datasets. In V. International Applied Statistics Congress
work page 2024
-
[10]
Dem s ar, J., and Bosni \'c , Z. (2018). Detecting concept drift in data streams using model explanation. Expert Systems with Applications, 92:546--559
work page 2018
-
[11]
Duckworth, C., Chmiel, F. P., Burns, D. K., Zlatev, Z. D., White, N. M., Daniels, T. W. V., Kiuber, M., and Boniface, M. J. (2021). Using explainable machine learning to characterize data drift and detect emergent health risks for emergency department admissions during COVID-19. Scientific Reports, 11(1):23017
work page 2021
-
[12]
Elwell, R., and Polikar, R. (2011). Incremental learning of concept drift in nonstationary environments. IEEE Transactions on Neural Networks, 22(10):1517--1531
work page 2011
-
[13]
D., Ramos-Jiménez, G., Morales-Bueno, R., Ortiz-Díaz, A., and Caballero-Mota, Y
Frías-Blanco, I., Campo-Ávila, J. D., Ramos-Jiménez, G., Morales-Bueno, R., Ortiz-Díaz, A., and Caballero-Mota, Y. (2015). Online and non-parametric drift detection methods based on Hoeffding’s bounds. IEEE Transactions on Knowledge and Data Engineering, 27(3), 810-823
work page 2015
-
[14]
Fumagalli, F., Muschalik, M., Hüllermeier, E., and Hammer, B. (2023). Incremental permutation feature importance (iPFI): Towards online explanations on data streams. Machine Learning, 112(12), 4863-4903
work page 2023
-
[15]
Gama, J., Medas, P., Castillo, G., and Rodrigues, P. (2004). Learning with drift detection. In Advances in Artificial Intelligence, pages 286--295. Springer
work page 2004
- [16]
-
[17]
Harries, M., Wales, N. S., and others. (1999). Splice-2 comparative evaluation: Electricity pricing. University of New South Wales, School of Computer Science and Engineering
work page 1999
- [18]
-
[19]
Hulten, G., Spencer, L., and Domingos, P. (2001). Mining time-changing data streams. In Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, pages 97--106
work page 2001
-
[20]
Ikonomovska, E., Gama, J., and Džeroski, S. (2011). Learning model trees from evolving data streams. Data Mining and Knowledge Discovery, 23, 128-168
work page 2011
-
[21]
Inglis, A., Parnell, A., and Hurley, C. B. (2022). Visualizing variable importance and variable interaction effects in machine learning models. Journal of Computational and Graphical Statistics, 31(3), 766-778
work page 2022
-
[22]
Kobylińska, K., Krzyziński, M., Machowicz, R., Adamek, M., and Biecek, P. (2024). Exploration of the Rashomon Set Assists Trustworthy Explanations for Medical Data. IEEE Journal of Biomedical and Health Informatics, 28(11), 6454–6465. IEEE
work page 2024
-
[23]
Korycki, Ł., and Krawczyk, B. (2023). Adversarial concept drift detection under poisoning attacks for robust data stream mining. Machine Learning, 112(10), 4013-4048
work page 2023
-
[24]
Kulinski, S., and Inouye, D. I. (2023). Towards explaining distribution shifts. In International Conference on Machine Learning, 17931–17952. PMLR
work page 2023
-
[25]
Lundberg, S. M., and Lee, S.-I. (2017). A Unified Approach to Interpreting Model Predictions. In Advances in Neural Information Processing Systems 30, 4765–4774. I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.)
work page 2017
-
[26]
G., Silva, T., Lopes, H., and Bordignon, A
Mattos, J. G., Silva, T., Lopes, H., and Bordignon, A. L. (2021). Interpretable concept drift. Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 25th Iberoamerican Congress, CIARP 2021, Porto, Portugal, May 10-13, 2021, Revised Selected Papers 25, 271-280
work page 2021
-
[27]
Moosbauer, J., Herbinger, J., Casalicchio, G., Lindauer, M., and Bischl, B. (2021). Explaining hyperparameter optimization via partial dependence plots. Advances in Neural Information Processing Systems, 34, 2280-2291
work page 2021
-
[28]
G., Raeder, T., Alaiz-Rodr \' guez, R., Chawla, N
Moreno-Torres, J. G., Raeder, T., Alaiz-Rodr \' guez, R., Chawla, N. V., and Herrera, F. (2012). A unifying view on dataset shift in classification. Pattern Recognition, 45(1):521--530
work page 2012
-
[29]
Mougan, C., and Nielsen, D. S. (2023). Monitoring model deterioration with explainable uncertainty estimation via non-parametric bootstrap. Proceedings of the AAAI Conference on Artificial Intelligence, 37(12), 15037-15045
work page 2023
-
[30]
u llermeier, E. (2022). Agnostic explanation of model change based on feature importance. KI-K \
Muschalik, M., Fumagalli, F., Hammer, B., and H \"u llermeier, E. (2022). Agnostic explanation of model change based on feature importance. KI-K \"u nstliche Intelligenz , 36(3):211--224
work page 2022
-
[31]
Muschalik, M., Fumagalli, F., Jagtani, R., Hammer, B., and Hüllermeier, E. (2023). iPDP: On Partial Dependence Plots in Dynamic Modeling Scenarios. In World Conference on Explainable Artificial Intelligence, 177–194. Springer
work page 2023
- [32]
-
[33]
C., Barnes, G., Lam, C., and Tso, C
Rahmani, K., Thapa, R., Tsou, P., Chetty, S. C., Barnes, G., Lam, C., and Tso, C. F. (2023). Assessing the effects of data drift on the performance of machine learning models used in clinical sepsis prediction. International Journal of Medical Informatics, 173:104930
work page 2023
-
[34]
Sebasti \ a o, R., and Fernandes, J. M. (2017). Supporting the Page-Hinkley test with empirical mode decomposition for change detection. In International Symposium on Methodologies for Intelligent Systems, pages 492--498. Springer
work page 2017
-
[35]
Street, W. N., and Kim, Y. (2001). A streaming ensemble algorithm (SEA) for large-scale classification. In Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, pages 377--382
work page 2001
-
[36]
S trumbelj, E., Kononenko, I., and Robnik- S ikonja, M. (2009). Explaining instance classifications with interactions of subsets of feature values. Data & Knowledge Engineering, 68(10):886--904
work page 2009
-
[37]
Watson-Daniels, J., du Pin Calmon, F., D'Amour, A., Long, C., Parkes, D. C., and Ustun, B. (2024). Predictive Churn with the Set of Good Models. arXiv preprint arXiv:2402.07745
-
[38]
Zhang, K., and Fan, W. (2008). Forecasting skewed biased stochastic ozone days: analyses, solutions and beyond. Knowledge and Information Systems, 14:299--326
work page 2008
-
[39]
, " * write output.state after.block = add.period write
ENTRY address author booktitle chapter doi edition editor eid howpublished institution journal key month note number organization pages publisher school series title type url volume year label INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 'after.sentence := #3 '...
-
[40]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize ":" * " " *...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.