OpenRTLSet: A Fully Open-Source Dataset for Large Language Model-based Verilog Module Design
Pith reviewed 2026-06-27 13:43 UTC · model grok-4.3
The pith
OpenRTLSet supplies the largest fully open Verilog dataset of 131,000 modules to train language models on hardware design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
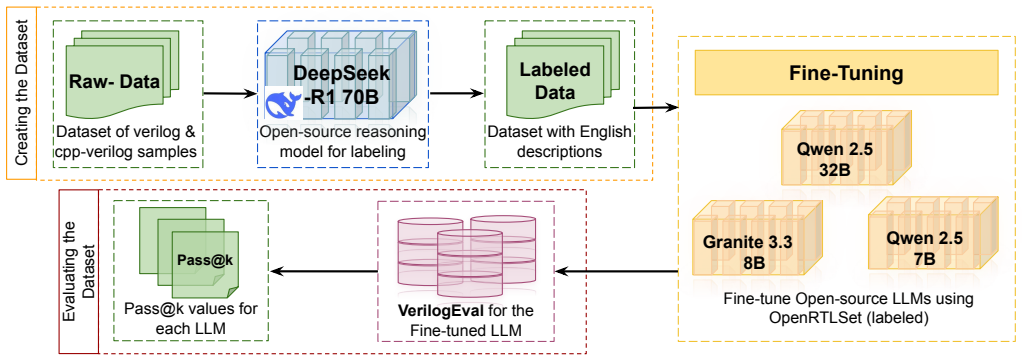
OpenRTLSet is the largest fully open-source dataset for hardware design, containing over 131,000 Verilog modules drawn from GitHub repositories, VHDL-to-Verilog translations, and synthesizable C/C++ translations, each accompanied by natural language descriptions generated by DeepSeek-R1 so that language models can be fine-tuned for Verilog module creation.
What carries the argument
The OpenRTLSet dataset, which merges raw open Verilog, translated modules, and paired natural-language descriptions to support LLM fine-tuning for hardware code generation.
If this is right
- Open-source datasets can match or exceed the results of restricted datasets for Verilog generation tasks.
- Models from 7B to 32B parameters can be fine-tuned on the data, with choices for context from Verilator C++ files and for INT4 versus BF16 quantization.
- The combination of multiple source types expands the diversity of training examples available to the community.
- The same approach can be repeated to grow the dataset further without licensing barriers.
Where Pith is reading between the lines
- The translation pipeline could be applied to additional legacy codebases to grow open hardware training resources.
- Researchers might add automated verification steps to confirm the correctness of translated modules before release.
- The dataset lowers the entry cost for academic groups to experiment with LLM-based hardware tools.
- Similar collection methods could be used for other hardware description languages beyond Verilog.
Load-bearing premise
The automatic translations from VHDL and C/C++ produce correct and synthesizable Verilog modules and the generated natural language descriptions accurately reflect each module's function without errors.
What would settle it
Running the same fine-tuning and evaluation pipeline on OpenRTLSet versus a comparable proprietary dataset and finding that models trained on OpenRTLSet produce lower rates of functionally correct Verilog on standard hardware benchmarks.
Figures
read the original abstract
OpenRTLSet introduces the largest fully open-source dataset for hardware design, offering over 131,000 diverse Verilog code samples to the research community and industry. Our dataset uniquely combines Verilog code from GitHub repositories (102k modules), VHDL translations (5k modules), and synthesizable C/C++ translations (24k modules), all freely accessible without proprietary restrictions. Using the reasoning model DeepSeek-R1, we generated paired natural language descriptions for each code sample, enabling fine-tuning of various language model families (e.g., Qwen and Granite) for Verilog code generation. Our dataset explores multiple options, including Verilator-generated C++ files as additional context during labeling, quantization techniques (INT4 vs. BF16), and performance differences across model sizes (7B-32B parameters). OpenRTLSet demonstrates that open-source approaches can achieve superior performance in hardware design tasks, establishing a new foundation for accessible research and commercial use in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OpenRTLSet as the largest fully open-source dataset for LLM-based Verilog module design, containing over 131,000 samples: 102k Verilog modules from GitHub, 5k from VHDL translations, and 24k from synthesizable C/C++ translations. Paired natural language descriptions are generated for each using DeepSeek-R1, with explorations of fine-tuning Qwen and Granite models under varying conditions (e.g., Verilator context, INT4 vs. BF16 quantization, 7B-32B sizes). The work claims this demonstrates that open-source approaches can achieve superior performance in hardware design tasks.
Significance. If the translations are functionally equivalent and the descriptions are accurate, the fully open release of a dataset at this scale would be a valuable contribution, enabling reproducible fine-tuning experiments and lowering barriers for research in LLM-assisted hardware design.
major comments (2)
- [Abstract] Abstract: The central claim that the 5k VHDL and 24k C/C++ translations yield correct, synthesizable Verilog and that DeepSeek-R1 descriptions faithfully capture functionality rests on unverified assertions. No equivalence checking, synthesis pass rates, testbench coverage, or validation of the generated descriptions is reported, which is load-bearing for the dataset's utility in fine-tuning and the 'superior performance' assertion.
- [Abstract] Abstract: The statement that the dataset 'demonstrates that open-source approaches can achieve superior performance' lacks any reported quantitative results, baselines, metrics, or evaluation protocol, preventing assessment of whether the claim holds for the translated subsets or overall.
minor comments (1)
- The abstract would benefit from explicit definitions of key terms such as 'synthesizable' and 'superior performance' to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the claims regarding translation correctness and performance superiority require either supporting evidence or appropriate qualification, and we will revise the manuscript to address these issues directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the 5k VHDL and 24k C/C++ translations yield correct, synthesizable Verilog and that DeepSeek-R1 descriptions faithfully capture functionality rests on unverified assertions. No equivalence checking, synthesis pass rates, testbench coverage, or validation of the generated descriptions is reported, which is load-bearing for the dataset's utility in fine-tuning and the 'superior performance' assertion.
Authors: We acknowledge that the manuscript reports no equivalence checking, synthesis pass rates, testbench coverage, or other validation for the VHDL-to-Verilog and C/C++-to-Verilog translations, nor for the accuracy of the DeepSeek-R1 descriptions. The translations were generated using standard conversion approaches, but these steps were not formally verified at scale. In the revised version we will add an explicit limitations subsection describing the dataset construction process, state that the translated modules are released without additional equivalence or synthesis validation, and qualify all related claims accordingly. revision: yes
-
Referee: [Abstract] Abstract: The statement that the dataset 'demonstrates that open-source approaches can achieve superior performance' lacks any reported quantitative results, baselines, metrics, or evaluation protocol, preventing assessment of whether the claim holds for the translated subsets or overall.
Authors: The abstract claim that the dataset demonstrates superior performance of open-source approaches is not supported by quantitative results, baselines, or an evaluation protocol in the current manuscript. The fine-tuning explorations are described qualitatively but without the metrics needed to substantiate superiority. We will revise the abstract to remove this claim and instead highlight the dataset's role in enabling future reproducible evaluations by the community. revision: yes
Circularity Check
No circularity: dataset release without derivation chain
full rationale
The paper introduces OpenRTLSet as a data collection assembled from GitHub Verilog, VHDL-to-Verilog translations, C/C++-to-Verilog translations, and DeepSeek-R1-generated natural-language descriptions. No equations, fitted parameters, uniqueness theorems, or predictive claims appear in the manuscript. The central contribution is the release of 131k modules; any performance claims on downstream fine-tuning rest on external use rather than an internal derivation that reduces to the paper's own inputs by construction. Self-citation load-bearing, ansatz smuggling, and renaming of known results are absent.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Code llama: Open foundation models for code,
B. Roziere, J. Gehring, F. Gloeckle, S. Sootla, I. Gat, X. E. Tan, Y . Adi, J. Liu, R. Sauvestre, T. Remezet al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
Pith/arXiv arXiv 2023
-
[2]
Deepseek-coder: When the large language model meets programming–the rise of code intelligence,
D. Guo, Q. Zhu, D. Yang, Z. Xie, K. Dong, W. Zhang, G. Chen, X. Bi, Y . Wu, Y . Liet al., “Deepseek-coder: When the large language model meets programming–the rise of code intelligence,”arXiv preprint arXiv:2401.14196, 2024
Pith/arXiv arXiv 2024
-
[3]
Qwen2. 5-coder technical report,
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Danget al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
Pith/arXiv arXiv 2024
-
[4]
Pybench: Evaluating llm agent on various real-world coding tasks,
Y . Zhang, Y . Pan, Y . Wang, and J. Cai, “Pybench: Evaluating llm agent on various real-world coding tasks,”arXiv preprint arXiv:2407.16732, 2024
arXiv 2024
-
[5]
Stelocoder: a decoder-only llm for multi-language to python code translation,
J. Pan, A. Sad ´e, J. Kim, E. Soriano, G. Sole, and S. Flamant, “Stelocoder: a decoder-only llm for multi-language to python code translation,”arXiv preprint arXiv:2310.15539, 2023
arXiv 2023
-
[6]
Enhancing javascript source code understanding with graph-aligned large language models,
T. Vadoce, J. Pritchard, and C. Fairbanks, “Enhancing javascript source code understanding with graph-aligned large language models,” 2024
2024
-
[7]
A study of vulnerability repair in javascript programs with large language models,
T. K. Le, S. Alimadadi, and S. Y . Ko, “A study of vulnerability repair in javascript programs with large language models,” inCompanion Proceedings of the ACM Web Conference 2024, 2024, pp. 666–669
2024
-
[8]
Where are large language models for code generation on github?
X. Yu, L. Liu, X. Hu, J. W. Keung, J. Liu, and X. Xia, “Where are large language models for code generation on github?”arXiv preprint arXiv:2406.19544, 2024
arXiv 2024
-
[9]
Software/hardware co-design for llm and its application for design verification,
L. J. Wan, Y . Huang, Y . Li, H. Ye, J. Wang, X. Zhang, and D. Chen, “Software/hardware co-design for llm and its application for design verification,” in2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2024, pp. 435–441
2024
-
[10]
New solutions on llm acceleration, optimization, and application,
Y . Huang, L. J. Wan, H. Ye, M. Jha, J. Wang, Y . Li, X. Zhang, and D. Chen, “New solutions on llm acceleration, optimization, and application,” inProceedings of the 61st ACM/IEEE Design Automation Conference, 2024, pp. 1–4
2024
-
[11]
Llm-aided efficient hardware design automation,
K. Xu, R. Qiu, Z. Zhao, G. L. Zhang, U. Schlichtmann, and B. Li, “Llm-aided efficient hardware design automation,”arXiv preprint arXiv:2410.18582, 2024
arXiv 2024
-
[12]
A survey of research in large language models for electronic design automation,
J. Pan, G. Zhou, C.-C. Chang, I. Jacobson, J. Hu, and Y . Chen, “A survey of research in large language models for electronic design automation,” ACM Transactions on Design Automation of Electronic Systems, 2025
2025
-
[13]
The potential of llms in hardware design,
S. Alsaqer, S. Alajmi, I. Ahmad, and M. Alfailakawi, “The potential of llms in hardware design,”Journal of Engineering Research, 2024
2024
-
[14]
Dave: Deriving automatically verilog from english,
H. Pearce, B. Tan, and R. Karri, “Dave: Deriving automatically verilog from english,” inProceedings of the 2020 ACM/IEEE Workshop on Machine Learning for CAD, 2020, pp. 27–32
2020
-
[15]
Verigen: A large language model for verilog code generation,
S. Thakur, B. Ahmad, H. Pearce, B. Tan, B. Dolan-Gavitt, R. Karri, and S. Garg, “Verigen: A large language model for verilog code generation,” ACM Transactions on Design Automation of Electronic Systems, vol. 29, no. 3, pp. 1–31, 2024
2024
-
[16]
Codev: Empowering llms for verilog generation through multi-level summarization,
Y . Zhao, D. Huang, C. Li, P. Jin, Z. Nan, T. Ma, L. Qi, Y . Pan, Z. Zhang, R. Zhang, X. Zhang, Z. Du, Q. Guo, X. Hu, and Y . Chen, “Codev: Empowering llms for verilog generation through multi-level summarization,” https://iprc-dip.github.io/CodeV, accessed: 2024-11-22
2024
-
[17]
Benchmarking large language models for auto- mated verilog rtl code generation,
S. Thakur, B. Ahmad, Z. Fan, H. Pearce, B. Tan, R. Karri, B. Dolan- Gavitt, and S. Garg, “Benchmarking large language models for auto- mated verilog rtl code generation,” in2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), 2023, pp. 1–6
2023
-
[18]
Evaluating llms for hardware design and test,
J. Blocklove, S. Garg, R. Karri, and H. Pearce, “Evaluating llms for hardware design and test,” in2024 IEEE LLM Aided Design Workshop (LAD), 2024, pp. 1–6
2024
-
[19]
Redefining chip design with ai-powered eda tools: Synopsys.ai,
A. Narayanan, “Redefining chip design with ai-powered eda tools: Synopsys.ai,” https://www.synopsys.com/blogs/chip-design/ synopsys-ai-eda-tools.html, Mar. 2023, accessed: 2024-11-22
2023
-
[20]
Domain- adapted llms for vlsi design and verification: A case study on formal verification,
M. Liu, M. Kang, G. B. Hamad, S. Suhaib, and H. Ren, “Domain- adapted llms for vlsi design and verification: A case study on formal verification,” in2024 IEEE 42nd VLSI Test Symposium (VTS), 2024, pp. 1–4
2024
-
[21]
Pyranet: A multi-layered hierarchical dataset for verilog,
B. Nadimi, G. O. Boutaib, and H. Zheng, “Pyranet: A multi-layered hierarchical dataset for verilog,”arXiv preprint arXiv:2412.06947, 2024
arXiv 2024
-
[22]
Mg-verilog: Multi- grained dataset towards enhanced llm-assisted verilog generation,
Y . Zhang, Z. Yu, Y . Fu, C. Wan, and Y . C. Lin, “Mg-verilog: Multi- grained dataset towards enhanced llm-assisted verilog generation,” in 2024 IEEE LLM Aided Design Workshop (LAD), 2024, pp. 1–5
2024
-
[23]
High-level synthesis for fpgas: From prototyping to deployment,
J. Cong, B. Liu, S. Neuendorffer, J. Noguera, K. Vissers, and Z. Zhang, “High-level synthesis for fpgas: From prototyping to deployment,”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 30, no. 4, pp. 473–491, 2011
2011
-
[24]
Fpga hls today: Successes, challenges, and opportunities,
J. Cong, J. Lau, G. Liu, S. Neuendorffer, P. Pan, K. Vissers, and Z. Zhang, “Fpga hls today: Successes, challenges, and opportunities,” ACM Trans. Reconfigurable Technol. Syst., vol. 15, no. 4, aug 2022. [Online]. Available: https://doi.org/10.1145/3530775
-
[25]
Scalehls: A new scalable high-level synthesis framework on multi-level intermediate representation,
H. Yeet al., “Scalehls: A new scalable high-level synthesis framework on multi-level intermediate representation,” inHPCA, 2022
2022
-
[26]
Scalehls: a scalable high-level synthesis framework with multi- level transformations and optimizations,
——, “Scalehls: a scalable high-level synthesis framework with multi- level transformations and optimizations,” inDAC, 2022
2022
-
[27]
Hida: A hierarchical dataflow compiler for high-level synthesis,
——, “Hida: A hierarchical dataflow compiler for high-level synthesis,” inASPLOS, 2024
2024
-
[28]
Chisel: constructing hardware in a scala embedded language,
J. Bachrach, H. V o, B. Richards, Y . Lee, A. Waterman, R. Avi ˇzienis, J. Wawrzynek, and K. Asanovi ´c, “Chisel: constructing hardware in a scala embedded language,” inProceedings of the 49th Annual Design Automation Conference, ser. DAC ’12. New York, NY , USA: Association for Computing Machinery, 2012, p. 1216–1225. [Online]. Available: https://doi.org...
-
[29]
Veryl: A new hardware description language as an altarnative to systemverilog,
N. Hatta, T. Ishitani, and R. Shioya, “Veryl: A new hardware description language as an altarnative to systemverilog,” 2024. [Online]. Available: https://arxiv.org/abs/2411.12983
arXiv 2024
-
[30]
Spade: An expression-based hdl with pipelines,
F. Skarman and O. Gustafsson, “Spade: An expression-based hdl with pipelines,” 2023. [Online]. Available: https://arxiv.org/abs/2304.03079
arXiv 2023
-
[31]
Betterv: Controlled verilog generation with discriminative guidance,
Z. Pei, H.-L. Zhen, M. Yuan, Y . Huang, and B. Yu, “Betterv: Controlled verilog generation with discriminative guidance,”arXiv preprint arXiv:2402.03375v3, May 2024. [Online]. Available: https: //arxiv.org/abs/2402.03375
arXiv 2024
-
[32]
[Online]
OpenAI, 2024. [Online]. Available: https://openai.com/policies/ row-terms-of-use/
2024
-
[33]
Ldoolitt/vhd2vl,
Ldoolitt, “Ldoolitt/vhd2vl,” https://github.com/ldoolitt/vhd2vl, accessed: 2024-11-22
2024
-
[34]
Veripool,
W. Snyder, “Veripool,” https://www.veripool.org/verilator/, accessed: 2024-11-22
2024
-
[35]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[36]
Verilogeval: Evaluating large language models for verilog code generation,
M. Liu, N. Pinckney, B. Khailany, and H. Ren, “Verilogeval: Evaluating large language models for verilog code generation,” 2023. [Online]. Available: https://arxiv.org/abs/2309.07544
arXiv 2023
-
[37]
Granite 3.0 language models,
I. Granite Team, “Granite 3.0 language models,” 2024
2024
-
[38]
A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2. 5 technical report,”arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[39]
Anthropic, “Claude,” https://www.anthropic.com/claude, 2024, accessed: 2024-03-14
2024
-
[40]
Gpt-4o: Enabling ai for daily life,
OpenAI, “Gpt-4o: Enabling ai for daily life,” https://openai.com/blog/ gpt-4o, 2024, accessed: 2024-03-14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.