Compress then Merge: From Multiple LoRAs into One Low-Rank Adapter
Pith reviewed 2026-06-28 11:23 UTC · model grok-4.3
The pith
Compress-then-Merge produces one rank-r LoRA from many task adapters by projecting them into shared subspaces first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
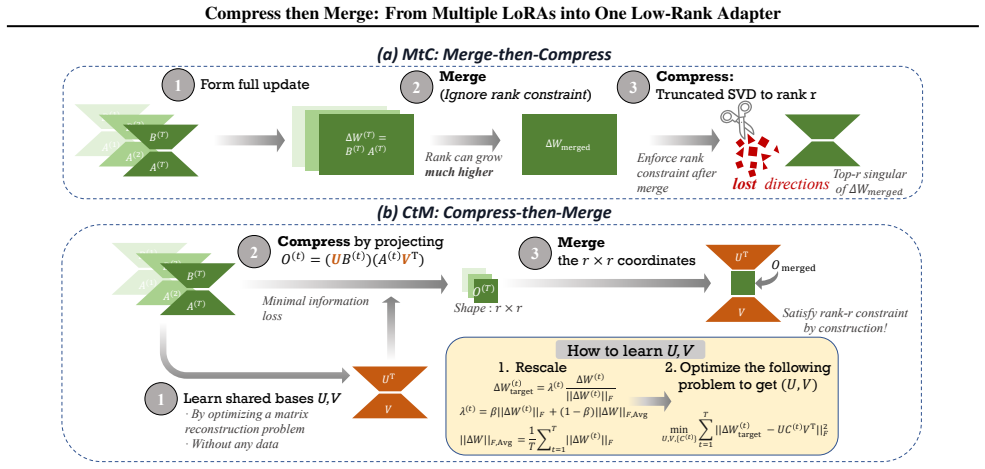
CtM first computes shared r-dimensional subspaces from the LoRA weight matrices to capture common structure across adapters, projects each adapter into these subspaces to obtain r by r coordinates, and then applies standard merging rules inside the reduced space, thereby guaranteeing a rank-r output without any post-hoc truncation.
What carries the argument
The shared r-dimensional subspaces computed from the LoRA weight matrices, which serve as the basis for projecting adapters into an r by r coordinate space where merging occurs.
If this is right
- The final merged adapter is guaranteed to have rank at most r with no need for SVD truncation.
- All merging arithmetic takes place inside the r by r core space spanned by the concatenated LoRA factors.
- The method produces higher task performance than existing single-LoRA-output baselines on the tested models.
- The performance gap to full-parameter merging methods is reduced while retaining the low-rank deployment benefit.
Where Pith is reading between the lines
- The same projection-first idea could be applied to merge other low-rank parameterizations beyond the specific LoRA form used here.
- If the subspaces prove stable across many adapters, the approach might scale to consolidating dozens of task adapters into one without retraining.
- One could measure how the quality of the shared subspaces changes when adapters come from increasingly dissimilar tasks.
Load-bearing premise
The shared r-dimensional subspaces calculated only from the LoRA weight matrices contain enough common structure across adapters to support effective merging after projection.
What would settle it
A direct comparison showing that CtM merged adapters perform no better than adapters merged after random projection into an r-dimensional space of the same size would falsify the claim that the computed subspaces add value.
Figures

read the original abstract
Low-rank adaptation (LoRA) enables parameter-efficient specialization of foundation models, but the proliferation of task-specific adapters fragments capabilities across many adapters, complicating reuse and deployment. We study the problem of merging $T$ LoRAs into a single rank-$r$ LoRA, thereby preserving the benefits of low-rank structure. Existing Merge-then-Compress pipelines treat the rank constraint as an afterthought: they merge adapters in the full parameter space, then compress the merged result to rank $r$ via truncated SVD. However, full-parameter merging may destroy the low-rank structure, making it difficult for subsequent compression to recover an effective rank-$r$ LoRA. We propose Compress-then-Merge (CtM), a reversed pipeline that enforces the rank-$r$ bottleneck before merging: CtM computes shared $r$-dimensional subspaces using only the LoRA weights to capture cross-adapter common structure, projects each adapter into the shared subspaces to obtain $r\times r$ coordinates, and then applies standard merging rules in this reduced space. CtM guarantees a rank-$r$ LoRA by construction, avoiding post-hoc truncation, and enables efficient computation in the core space spanned by concatenated LoRA factors. Experiments across multiple models and tasks show that CtM consistently outperforms existing single-LoRA-output baselines while narrowing the performance gap to full-parameter merging methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Compress-then-Merge (CtM) to combine T task-specific LoRAs into a single rank-r LoRA. Unlike merge-then-compress pipelines that merge in full parameter space then truncate via SVD, CtM first computes shared r-dimensional subspaces solely from the concatenated LoRA A/B weight factors across adapters, projects each adapter into these subspaces to obtain r×r coordinates, and performs merging (e.g., via standard rules) in the reduced space. This guarantees a rank-r output by construction. Experiments on multiple models and tasks are reported to show consistent outperformance over single-LoRA baselines while narrowing the gap to full-parameter merging.
Significance. If the central claims hold, CtM provides an efficient, structure-preserving alternative for multi-adapter merging that avoids destroying low-rank properties during full-space operations. The reversed pipeline and use of weight-derived subspaces are algorithmic strengths that could aid deployment of specialized foundation models without post-hoc compression artifacts.
major comments (2)
- [§3.2] §3.2 (subspace computation): the shared r-dimensional basis is obtained from concatenated LoRA factors alone; no ablation or analysis is provided to test whether this subspace retains directions relevant to downstream task performance (as opposed to generic weight alignment), which is load-bearing for the claim that projection preserves merging effectiveness.
- [Experiments] Experiments section (performance tables): while consistent outperformance is asserted, the description of baselines, exact merging rules applied in the r×r space, and presence/absence of error bars or statistical tests is insufficient to evaluate the strength of the cross-method comparisons.
minor comments (2)
- [§3.1] The notation distinguishing the original LoRA factors from the projected r×r coordinates could be introduced with an explicit equation in §3.1 for clarity.
- [Figure 1] Figure 1 (pipeline diagram) would benefit from labeling the exact dimensionality at each step to match the text description.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (subspace computation): the shared r-dimensional basis is obtained from concatenated LoRA factors alone; no ablation or analysis is provided to test whether this subspace retains directions relevant to downstream task performance (as opposed to generic weight alignment), which is load-bearing for the claim that projection preserves merging effectiveness.
Authors: The subspaces are derived exclusively from the task-specific LoRA weight factors, which by definition encode the directions that drive each adapter's downstream performance. Concatenating these factors and extracting the shared basis therefore aligns the projection with cross-task structure in the adaptation space rather than generic weight statistics. While the manuscript does not contain an explicit ablation against non-task-derived bases, the reported gains over merge-then-compress baselines provide indirect evidence that task-relevant directions are retained. In revision we will add a targeted analysis (e.g., cosine alignment with task gradients or a controlled comparison to random subspaces) to make this claim more direct. revision: yes
-
Referee: [Experiments] Experiments section (performance tables): while consistent outperformance is asserted, the description of baselines, exact merging rules applied in the r×r space, and presence/absence of error bars or statistical tests is insufficient to evaluate the strength of the cross-method comparisons.
Authors: We agree that additional detail is required for rigorous evaluation. The revised manuscript will (i) enumerate all baselines with implementation specifics, (ii) state the precise merging operators (e.g., arithmetic mean, task-vector addition) applied inside the r×r coordinate space, and (iii) report means and standard deviations over multiple random seeds together with statistical significance tests where appropriate. revision: yes
Circularity Check
No circularity: algorithmic procedure with explicit by-construction guarantee
full rationale
The paper presents CtM as a direct algorithmic pipeline: shared r-dimensional subspaces are computed from the concatenated LoRA factors, each adapter is projected to obtain r×r coordinates, and merging occurs in that space. The rank-r guarantee is stated explicitly as holding 'by construction' of this procedure rather than derived from any fitted parameter or self-referential equation. No equations, self-citations, or 'predictions' are shown that reduce the output to a renaming or re-fitting of the inputs. The method is self-contained as a sequence of linear-algebra operations on the given weight matrices, with performance evaluated separately via experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LoRA weight matrices contain sufficient information to identify shared cross-adapter subspaces via standard linear algebra operations.
Reference graph
Works this paper leans on
-
[1]
Alipour, M. and Amiri, M. M. Towards reversible model merging for low-rank weights.ArXiv, abs/2510.14163,
-
[2]
Revisiting weight averaging for model merging.ArXiv, abs/2412.12153,
Choi, J., Kim, D., Lee, C., and Hong, S. Revisiting weight averaging for model merging.ArXiv, abs/2412.12153,
-
[3]
Think you have solved question answering? try arc, the AI2 reasoning challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the AI2 reasoning challenge. ArXiv, abs/1803.05457,
-
[4]
Goodfellow, I. J., Erhan, D., Carrier, P. L., Courville, A. C., Mirza, M., Hamner, B., Cukierski, W., Tang, Y ., Thaler, D., Lee, D., Zhou, Y ., Ramaiah, C., Feng, F., Li, R., Wang, X., Athanasakis, D., Shawe-Taylor, J., Milakov, M., Park, J., Ionescu, R. T., Popescu, M., Grozea, C., Bergstra, J., Xie, J., Romaszko, L., Xu, B., Zhang, C., and Bengio, Y . ...
-
[5]
Y ., Pang, T., Du, C., and Lin, M
Huang, C., Liu, Q., Lin, B. Y ., Pang, T., Du, C., and Lin, M. Lorahub: Efficient cross-task generalization via dynamic lora composition.ArXiv, abs/2307.13269,
-
[6]
Nguyen, T., Huu-Tien, D., Suzuki, T., and Nguyen, L. Regmean++: Enhancing effectiveness and generaliza- tion of regression mean for model merging.ArXiv, abs/2508.03121,
-
[7]
The e2e dataset: New challenges for end-to-end generation.arXiv preprint arXiv:1706.09254,
Novikova, J., Duˇsek, O., and Rieser, V . The e2e dataset: New challenges for end-to-end generation.arXiv preprint arXiv:1706.09254,
-
[8]
Lora vs full fine-tuning: An illusion of equivalence
Shuttleworth, R., Andreas, J., Torralba, A., and Sharma, P. Lora vs full fine-tuning: An illusion of equivalence. ArXiv, abs/2410.21228,
-
[9]
LoRA merging with SVD: Understanding interference and preserving performance
Tang, D., Yadav, P., Sung, Y .-L., Yoon, J., and Bansal, M. LoRA merging with SVD: Understanding interference and preserving performance. InICML 2025 Workshop on Reliable and Responsible Foundation Models,
2025
-
[10]
The caltech-ucsd birds-200-2011 dataset
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Tech- nology,
2011
-
[11]
Xiao, H., Rasul, K., and V ollgraf, R. Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms.ArXiv, abs/1708.07747,
-
[12]
Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild
Zhao, Z., Gan, L., Wang, G., Zhou, W., Yang, H., Kuang, K., and Wu, F. Loraretriever: Input-aware lora retrieval and composition for mixed tasks in the wild. InACL (Findings), volume ACL 2024 ofFindings of ACL, pp. 4447–4462. Association for Computational Linguistics,
2024
-
[13]
Decouple and orthogonalize: A data- free framework for lora merging.ArXiv, abs/2505.15875,
Zheng, S., Wang, H., Huang, C., Wang, X., Chen, T., Fan, J., Hu, S., and Ye, P. Decouple and orthogonalize: A data- free framework for lora merging.ArXiv, abs/2505.15875,
-
[14]
Models.For reproducibility, we adopt the publicly released KnOTS LoRA adapters on HuggingFace as our task-specific experts
and CoreSpace (Panariello et al., 2025), we evaluate merging methods on both vision tasks and NLI tasks. Models.For reproducibility, we adopt the publicly released KnOTS LoRA adapters on HuggingFace as our task-specific experts. For vision tasks, we use CLIP ViT-B/32 as the base model, and the LoRAs are trained with rank rin=16, LoRA scaling α=16, and dro...
2025
-
[15]
striped”, “dotted
instantiates the model with a sequence-classification head (3-way NLI) using HuggingFace AutoModelForSequenceClassification. During merging, only the LLaMA backbone (with LoRA layers) is merged; evaluation on each dataset uses its corresponding task-specific classification head (for binary NLI datasets, the missing label is masked). Datasets.For vision ta...
2013
-
[16]
not-entailment)
question answering into sentence-pair inference (entailment vs. not-entailment). •RTE(Wang et al., 2019): a binary textual entailment task in GLUE assembled from multiple RTE challenge datasets. • SCITAIL(Khot et al., 2018): a science-domain entailment dataset built from multiple-choice QA, pairing retrieved science sentences (premises) with question–answ...
2019
-
[17]
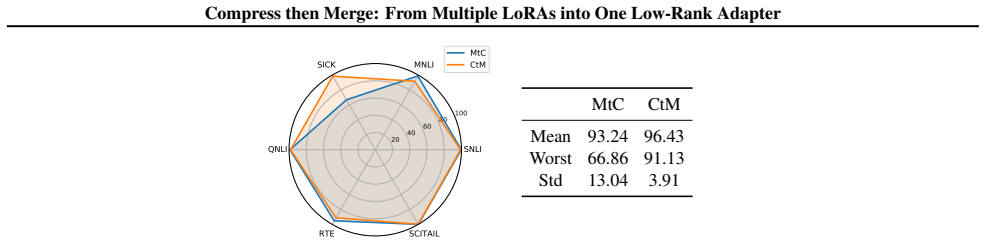
Specifically, MtC suffers a sharp collapse on SICK, which both lowers its mean retention and increases its cross-task variability
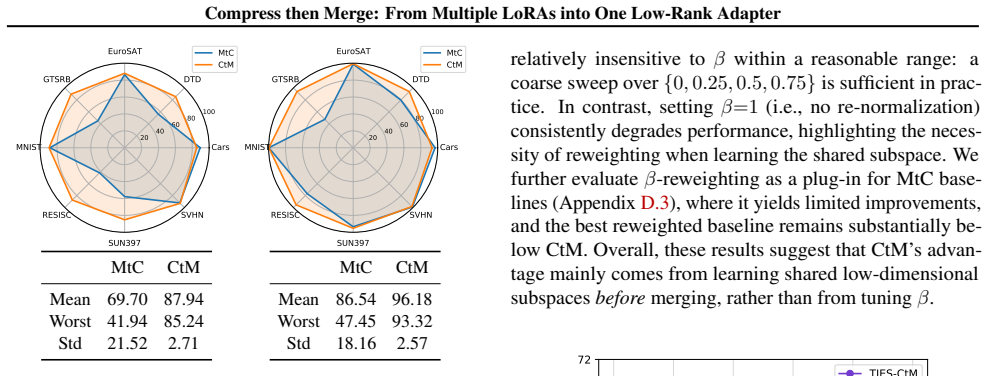
The conclusion remains consistent from the perspectives of mean performance, variance, and worst-case robustness: CtM improves the mean functional retention from 93.24% to 96.43%, reduces the cross-task standard deviation, and, more importantly, substantially improves the worst-task retention from 66.86% to 91.13%. Specifically, MtC suffers a sharp collap...
2023
-
[18]
For a given layer, we simply skip the LoRAs that are not injected at that layer and only process the remaining ones
Method Space Cars DTD EuroSAT GTSRB MNIST RESISC SUN397 SVHN Avg Each LoRA’s rank 16 16 8 8 4 4 32 32 – LoRA’s absolute accuracy 74.00 58.30 98.11 96.76 98.45 91.14 68.77 96.07 – LoRA-LEGO – 79.01 72.26 58.51 60.22 72.52 65.99 91.75 44.98 68.16 Iso-CTS – 81.57 80.47 39.22 40.20 64.40 63.10 91.76 42.63 62.92 Iso-C Full 80.01 72.26 54.85 54.15 83.95 65.08 9...
2004
-
[19]
Additionally, we compare against representative low-rank-aware methods, including LoRA-LEGO, RobustMerge, and Iso-CTS
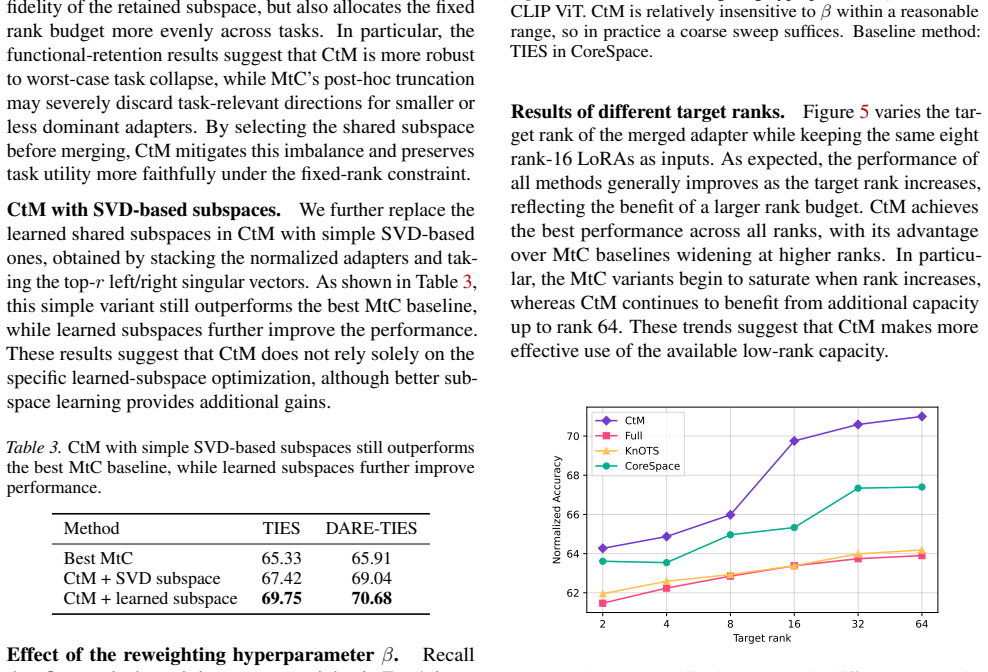
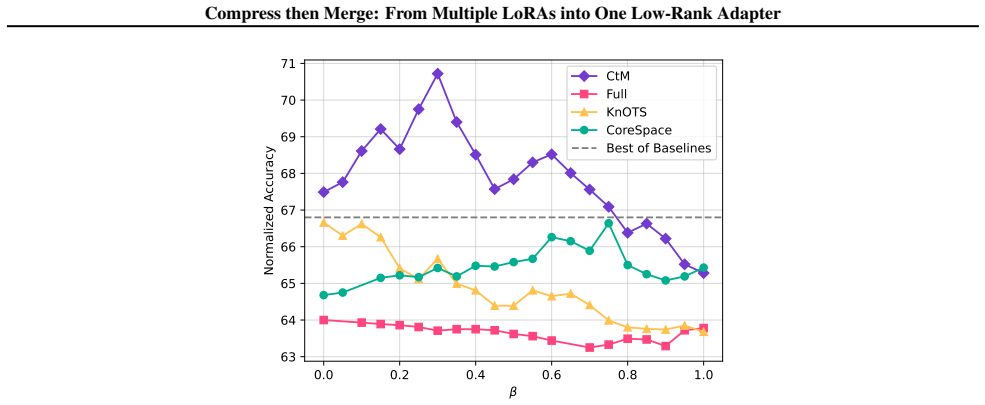
Since TIES is a competitive and representative approach in our main experiments, we instantiate our CtM framework withTIESas the underlying merge operator, and compare our approach against TIES applied in three different parameter spaces: (i) Full space, (ii) KnOTS space, and (iii) CoreSpace. Additionally, we compare against representative low-rank-aware ...
2025
-
[20]
These tasks cover diverse multimodal abilities, including question answering, grounding, classification, and captioning
as the base model and consider eight multimodal generative tasks. These tasks cover diverse multimodal abilities, including question answering, grounding, classification, and captioning. Following MM-MergeBench, we use task-specific rank-16 LoRAs on LLaV A-1.5-7B, with LoRA modules injected into all linear layers. We merge the eight task-specific LoRAs in...
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.