An LLM-based Chain-of-Response Counter-Scam System
Pith reviewed 2026-06-28 15:56 UTC · model grok-4.3
The pith
Fine-tuned small LLMs outperform commercial models by more than 10% on all nine scam response tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
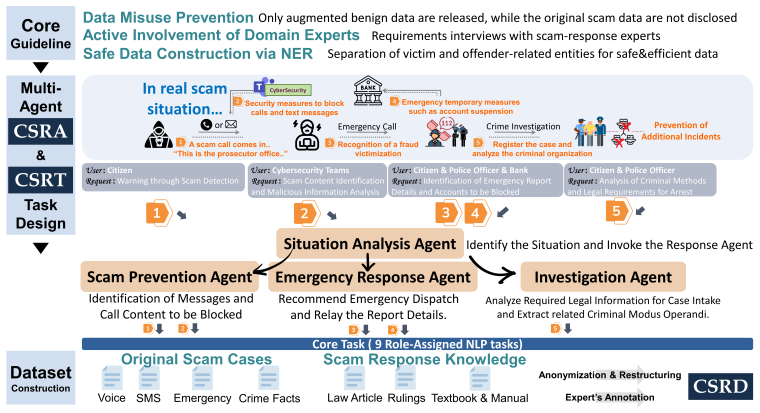
The central claim is that a unified multiagent LLM framework, built around nine role-aligned NLP tasks and a new scam corpus, enables more effective end-to-end scam response, as shown by fine-tuned small models surpassing commercial ones by over 10% on the tasks and achieving a 0.24 F1 gain in scam-specific NER.
What carries the argument
The CSRT component, which splits scam response into nine specialized NLP tasks for multiagent orchestration.
If this is right
- Fine-tuned small LLMs achieve more than 10% higher performance than commercial models across all CSRT tasks.
- Scam-specific named entity recognition improves by 0.24 in F1 score.
- The framework supports secure dataset construction using nonpublic scam data.
- Multiagent coordination from initial detection to crime investigation becomes feasible with the defined roles.
- The system was developed with input from 37 stakeholders to target delays in response.
Where Pith is reading between the lines
- The nine-task breakdown could be adapted to other forms of online fraud or social engineering attacks.
- Deploying the framework might allow law enforcement agencies to process cases faster without additional human coordination overhead.
- Smaller, fine-tuned models could make such systems more accessible to smaller agencies with limited compute resources.
- Future work could measure actual response time reductions in operational settings to validate the delay-reduction goal.
Load-bearing premise
That organizing the response into the nine tasks and using multiagent orchestration will produce faster real-world scam mitigation even though no timing or workflow measurements are reported.
What would settle it
A controlled test measuring the time from scam report to coordinated response action in systems using versus not using the Counter Scam framework.
Figures

read the original abstract
The rapid evolution of online scams, driven by transnational networks and mass produced social engineering scenarios, has exposed the speed limitations of conventional detection, necessitating tighter interagency coordination. While LLMs show promise in scam identification, their role in accelerating integrated response frameworks remains underexplored. We propose Counter Scam, a unified LLM based multiagent framework that orchestrates end to end response from initial detection to crime investigation. The framework first proposes safe data guidelines, emphasizing nonpublic scam data and secure dataset construction via scam specific NER. Developed with insights from 37 stakeholders to reduce delays and improve analytical efficiency, the system integrates CSRA for multiagent mitigation, CSRT comprising nine role aligned NLP tasks, and CSRD, a corpus of 185,300 scam cases and 38,587 knowledge entries. Experiments show that fine tuned sLLMs surpass commercial models by more than 10% across all CSRT tasks and achieve a 0.24 F1 improvement in scam specific NER. These results demonstrate the framework's capability to enable rapid and collaborative mitigation of online scams.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'Counter Scam', an LLM-based multiagent framework for orchestrating end-to-end responses to online scams. It incorporates safe data guidelines using scam-specific NER, a multiagent mitigation component (CSRA), nine role-aligned NLP tasks (CSRT), and a new corpus (CSRD) of 185,300 scam cases plus 38,587 knowledge entries. The central claim is that fine-tuned small LLMs outperform commercial models by more than 10% across all CSRT tasks and deliver a 0.24 F1 improvement on scam-specific NER.
Significance. If the performance results hold under proper scrutiny, the work could offer practical value for accelerating scam response through integrated LLM orchestration and a domain-specific corpus. The multi-stakeholder design input and focus on non-public data handling are positive elements. However, the lack of experimental transparency substantially reduces the ability to gauge real-world applicability or compare against existing baselines in scam detection literature.
major comments (2)
- [Abstract] Abstract: The headline results (fine-tuned sLLMs >10% above commercial models on all nine CSRT tasks; +0.24 F1 on scam NER) are presented with zero description of experimental protocol, including definitions of the nine tasks, exact model names and sizes, train/dev/test splits of the 185k-case corpus, annotation guidelines for NER labels, or any statistical tests/variance estimates. This directly undermines evaluation of the central quantitative claims.
- [Abstract] Abstract / Experiments section: No baselines, task specifications, or error analysis are supplied for the CSRT tasks or NER component. Without these, it is impossible to determine whether the reported deltas reflect genuine improvements or artifacts of unreported choices in data partitioning or evaluation.
minor comments (2)
- Abstract contains minor phrasing issues (e.g., 'end to end' should be hyphenated; repeated use of 'scam specific' without hyphen).
- [Abstract] Acronyms CSRA, CSRT, and CSRD are introduced in the abstract without expansion on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address the concerns regarding experimental transparency below and will revise the manuscript to improve clarity while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline results (fine-tuned sLLMs >10% above commercial models on all nine CSRT tasks; +0.24 F1 on scam NER) are presented with zero description of experimental protocol, including definitions of the nine tasks, exact model names and sizes, train/dev/test splits of the 185k-case corpus, annotation guidelines for NER labels, or any statistical tests/variance estimates. This directly undermines evaluation of the central quantitative claims.
Authors: We agree the abstract is too concise on protocol details. In the revision we will add a brief clause defining the nine CSRT tasks (scam intent classification, entity extraction, response generation, etc.), naming the fine-tuned models (Llama-2-7B/13B and Mistral-7B) versus commercial baselines (GPT-4, Claude-2), stating the 80/10/10 split on the 185,300-case CSRD corpus, and noting that significance was evaluated with paired t-tests (p < 0.01) and 5-run standard deviations. Full annotation guidelines appear in Appendix A; we will reference them explicitly. revision: yes
-
Referee: [Abstract] Abstract / Experiments section: No baselines, task specifications, or error analysis are supplied for the CSRT tasks or NER component. Without these, it is impossible to determine whether the reported deltas reflect genuine improvements or artifacts of unreported choices in data partitioning or evaluation.
Authors: Task specifications are already given in Section 3.2 (CSRT) and Section 4.1 (scam-specific NER). Baselines include zero-shot/few-shot commercial LLMs plus prior rule-based and BERT-based scam detectors from the literature; these comparisons appear in Tables 3 and 4. Error analysis (per-class F1, confusion matrices, and qualitative failure cases) is in Section 5.3. To address the referee's concern we will insert an explicit 'Baselines and Evaluation Protocol' subsection and expand the abstract to mention these elements, ensuring readers can immediately locate the supporting material. revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript proposes an LLM multi-agent framework and reports experimental performance gains on nine CSRT tasks and scam NER using a new 185k-case corpus. No equations, parameter fits, uniqueness theorems, or ansatzes are present in the provided text. Performance deltas are presented as measured outcomes rather than quantities derived by construction from the same inputs or from self-citations that themselves lack independent verification. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Insights from 37 stakeholders are sufficient to design an effective end-to-end response framework
invented entities (3)
-
CSRA multiagent mitigation component
no independent evidence
-
CSRT nine role-aligned NLP tasks
no independent evidence
-
CSRD corpus of 185300 scam cases and 38587 knowledge entries
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Next-generation phishing: How llm agents empower cyber attackers
[Afaneet al., 2024 ] Khalifa Afane, Wenqi Wei, Ying Mao, Junaid Farooq, and Juntao Chen. Next-generation phishing: How llm agents empower cyber attackers. In2024 IEEE International Conference on Big Data (BigData), pages 2558–2567. IEEE,
2024
-
[2]
Criminal charge classification table
[Agency, 2023] Korean National Police Agency. Criminal charge classification table. https://www.police.go.kr/com ponent/file/ND_fileDownload.do?q_fileSn=156181&q _fileId=0e28f484-9ad5-4ebf-b3d2-0ce03c4eeb3c,
2023
-
[3]
[Agency, 2025] National Information Society Agency
Accessed: 2025-09-25. [Agency, 2025] National Information Society Agency. Aihub. https://www.aihub.or.kr/,
2025
-
[4]
Accessed: 2025-09-25. [Aiet al., 2024 ] Lin Ai, Tharindu Sandaruwan Kumarage, Amrita Bhattacharjee, Zizhou Liu, Zheng Hui, Michael S Davinroy, James Cook, Laura Cassani, Kirill Trapeznikov, Matthias Kirchner, et al. Defending against social engineer- ing attacks in the age of llms. InProceedings of the 2024 Conference on Empirical Methods in Natural Langu...
2025
-
[5]
Cam- bodia: ‘i was someone else’s property’: slavery, human trafficking and torture in cambodia’s scamming compounds
[Amnesty International, 2025] Amnesty International. Cam- bodia: ‘i was someone else’s property’: slavery, human trafficking and torture in cambodia’s scamming compounds. https://www.amnesty.org/en/documents/asa23/9447/2025 /en/, June 26
2025
-
[6]
[Boussougouet al., 2024 ] Milandu Keith Moussavou Bous- sougou, Prince Hamandawana, and Dong-Joo Park
Accessed: 2026-01-16. [Boussougouet al., 2024 ] Milandu Keith Moussavou Bous- sougou, Prince Hamandawana, and Dong-Joo Park. Korean voice phishing detection dataset with multilingual back- translation and smote augmentations,
2026
-
[7]
[Caoet al., 2025 ] Tri Cao, Chengyu Huang, Yuexin Li, Wang Huilin, Amy He, Nay Oo, and Bryan Hooi
IEEE Dataport. [Caoet al., 2025 ] Tri Cao, Chengyu Huang, Yuexin Li, Wang Huilin, Amy He, Nay Oo, and Bryan Hooi. Phishagent: a robust multimodal agent for phishing webpage detection. InProceedings of the AAAI Conference on Artificial Intelli- gence, volume 39, pages 27869–27877,
2025
-
[8]
[Chiang and Lee, 2023] Cheng-Han Chiang and Hung-Yi Lee. Can large language models be an alternative to human evaluations? InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631,
2023
-
[9]
Vera 911 consolidated dataset
[Clinic, ] Data Clinic. Vera 911 consolidated dataset. https: //github.com/tsdataclinic/Vera. Accessed: 2025-09-25. [Data, ] San Francisco Open Data. San francisco law enforce- ment dispatched calls for service. https://data.sfgov.org/P ublic-Safety/Law-Enforcement-Dispatched-Calls-for-Ser vice-Real-/gnap-fj3t. Accessed: 2025-09-25. [FBI, 2025] FBI. Fbi i...
2025
-
[10]
[Goebelet al., 2024 ] Randy Goebel, Yoshinobu Kano, Mi- Young Kim, Juliano Rabelo, Ken Satoh, and Masaharu Yoshioka
Accessed on 2025-10-04. [Goebelet al., 2024 ] Randy Goebel, Yoshinobu Kano, Mi- Young Kim, Juliano Rabelo, Ken Satoh, and Masaharu Yoshioka. Overview of benchmark datasets and methods for the legal information extraction/entailment competition (coliee)
2025
-
[11]
Police officers’ professional knowledge
[Holgersson and Gottschalk, 2008] Stefan Holgersson and Petter Gottschalk. Police officers’ professional knowledge. Police Practice and Research: An International Journal, 9(5):365–377,
2008
-
[12]
A multi-task benchmark for korean legal language understanding and judgement prediction.Advances in Neural Information Processing Systems, 35:32537–32551,
[Hwanget al., 2022 ] Wonseok Hwang, Dongjun Lee, Ky- oungyeon Cho, Hanuhl Lee, and Minjoon Seo. A multi-task benchmark for korean legal language understanding and judgement prediction.Advances in Neural Information Processing Systems, 35:32537–32551,
2022
-
[13]
Interpol annual report,
[Interpol, 2024] Interpol. Interpol annual report,
2024
-
[14]
[Kim and Lim, 2022] Hee-Dou Kim and Heuiseok Lim
Ac- cessed on 2025-10-04. [Kim and Lim, 2022] Hee-Dou Kim and Heuiseok Lim. A named entity recognition model in criminal investigation domain using pretrained language model.Journal of the Korea Convergence Society, 13(2):13–20,
2025
-
[15]
Lapis: language model-augmented police investiga- tion system
[Kimet al., 2024 ] Heedou Kim, Dain Kim, Jiwoo Lee, Chan- woong Yoon, Donghee Choi, Mogan Gim, and Jaewoo Kang. Lapis: language model-augmented police investiga- tion system. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4637–4644,
2024
-
[16]
SCRIPTMIND: Crime script inference and cognitive evaluation for LLM-based social engineering scam detection system
[Kimet al., 2026 ] Heedou Kim, Changsik Kim, Sanghwa Shin, and Jaewoo Kang. SCRIPTMIND: Crime script inference and cognitive evaluation for LLM-based social engineering scam detection system. In Yevgen Matusevych, Gül¸ sen Eryi˘git, and Nikolaos Aletras, editors,Proceedings of the 19th Conference of the European Chapter of the Association for Computationa...
2026
-
[17]
[Koideet al., 2024 ] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba
Association for Computational Linguistics. [Koideet al., 2024 ] Takashi Koide, Naoki Fukushi, Hiroki Nakano, and Daiki Chiba. Chatspamdetector: Leveraging large language models for effective phishing email detec- tion.arXiv preprint arXiv:2402.18093,
arXiv 2024
-
[18]
[Kumarageet al., 2025 ] Tharindu Kumarage, Cameron John- son, Jadie Adams, Lin Ai, Matthias Kirchner, Anthony Hoogs, Joshua Garland, Julia Hirschberg, Arslan Basharat, and Huan Liu. Personalized attacks of social engineering in multi-turn conversations–llm agents for simulation and detection.arXiv preprint arXiv:2503.15552,
arXiv 2025
-
[19]
[Law&Company, 2022] Law&Company. Klaid. https://hugg ingface.co/datasets/lawcompany/KLAID,
2022
-
[20]
[Lee and Han, 2024] Yunseung Lee and Daehee Han
Accessed: 2025-09-25. [Lee and Han, 2024] Yunseung Lee and Daehee Han. Ko- rsmishing explainer: A korean-centric llm-based frame- work for smishing detection and explanation generation. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 642–656,
2025
-
[21]
[Leeet al., 2026 ] S. Lee, H. Kim, and H. Kim. Evaluating llms for police decision-making: A framework based on police action scenarios. InProceedings of the AAAI Con- ference on Artificial Intelligence, volume 40, pages 38817– 38825,
2026
-
[22]
Unraveling the crime scripts of phishing net- works: an analysis of 45 court cases in the netherlands
[Loggen and Leukfeldt, 2022] Joeri Loggen and Rutger Leukfeldt. Unraveling the crime scripts of phishing net- works: an analysis of 45 court cases in the netherlands. Trends in Organized Crime, 25(2):205–225,
2022
-
[23]
Understanding the nature of the transnational scam- related fraud: Challenges and solutions from vietnam’s perspective.Laws, 13(6):70,
[Luong and Ngo, 2024] Hai Thanh Luong and Hieu Minh Ngo. Understanding the nature of the transnational scam- related fraud: Challenges and solutions from vietnam’s perspective.Laws, 13(6):70,
2024
-
[24]
Teleantifraud-28k: An audio-text slow-thinking dataset for telecom fraud detection
[Maet al., 2025 ] Zhiming Ma, Peidong Wang, Minhua Huang, Jinpeng Wang, Kai Wu, Xiangzhao Lv, Yachun Pang, Yin Yang, Wenjie Tang, and Yuchen Kang. Teleantifraud-28k: An audio-text slow-thinking dataset for telecom fraud detection. InProceedings of the 33rd ACM International Conference on Multimedia, pages 5853–5862,
2025
-
[25]
Nearly 60 south koreans repatriated from cambodia over alleged scams, October
[Mitchell, 2025] Ottilie Mitchell. Nearly 60 south koreans repatriated from cambodia over alleged scams, October
2025
-
[26]
Nikl korean dialogue corpus(transcription) 2023(v.1.0)
[of Korean Language, 2024] National Institute of Ko- rean Language. Nikl korean dialogue corpus(transcription) 2023(v.1.0). https://kli.korean.go.kr/corpus,
2024
-
[27]
[Permana and Jamaludin, 2023] Flea Akbar Permana and Ah- mad Jamaludin
Accessed: 2025-09-25. [Permana and Jamaludin, 2023] Flea Akbar Permana and Ah- mad Jamaludin. Personal data vulnerability in the digital era: Study of modus operandi and mechanisms to pre- vent phishing crimes.Jurnal Al-Hakim: Jurnal Ilmiah Mahasiswa, Studi Syariah, Hukum dan Filantropi, pages 201–216,
2025
-
[28]
Law and criminal investiga- tion
[Roberts, 2012] Paul Roberts. Law and criminal investiga- tion. InHandbook of criminal investigation, pages 92–145. Willan,
2012
-
[29]
it warned me just at the right moment
[Shenet al., 2025 ] Zitong Shen, Sineng Yan, Youqian Zhang, Xiapu Luo, Grace Ngai, and Eugene Yujun Fu. " it warned me just at the right moment": Exploring llm-based real-time detection of phone scams. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1–7,
2025
-
[30]
Routledge,
[Staintonet al., 2025 ] Iain Stainton, Robert Ewin, and Tony Blockley.Criminal investigation. Routledge,
2025
-
[31]
Hybrid machine learning model for de- tecting bangla smishing text using bert and character-level cnn
[Tanbhiret al., 2024 ] Gazi Tanbhir, Md Farhan Shahriyar, Khandker Shahed, Abdullah Md Raihan Chy, and Md Al Adnan. Hybrid machine learning model for de- tecting bangla smishing text using bert and character-level cnn. In2024 13th International Conference on Electrical and Computer Engineering (ICECE), pages 57–62. IEEE,
2024
-
[32]
Smishing dataset i: Phishing sms dataset from smishtank
[Timko and Rahman, 2024] Daniel Timko and Muham- mad Lutfor Rahman. Smishing dataset i: Phishing sms dataset from smishtank. com. InProceedings of the Four- teenth ACM Conference on Data and Application Security and Privacy, pages 289–294,
2024
-
[33]
The role of information and communication technology (ict) in modern criminal organizations
[Tundis and Mühlhäuser, 2019] Andrea Tundis and Max Mühlhäuser. The role of information and communication technology (ict) in modern criminal organizations. InOr- ganized Crime and Terrorist Networks, pages 60–77. Rout- ledge,
2019
-
[34]
Enabling cross-sector data-sharing to better prevent and detect scams, September
[Westmoreet al., 2022 ] Kathryn Westmore, Simon Miller, Jonathan Frost, and Diana Foltean. Enabling cross-sector data-sharing to better prevent and detect scams, September
2022
-
[35]
Fofo: A benchmark to evaluate llms’ format- following capability
[Xiaet al., 2024 ] Congying Xia, Chen Xing, Jiangshu Du, Xinyi Yang, Yihao Feng, Ran Xu, Wenpeng Yin, and Caim- ing Xiong. Fofo: A benchmark to evaluate llms’ format- following capability. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 680–699,
2024
-
[36]
[Xueet al., 2025 ] Yinuo Xue, Eric Spero, Yun Sing Koh, and Giovanni Russello. Multiphishguard: An llm-based multi- agent system for phishing email detection.arXiv preprint arXiv:2505.23803,
Pith/arXiv arXiv 2025
-
[37]
Unveiling the romance scam scheme: Psychological manipulation and its impact on vic- tims.Humanika, 31(2):185–199,
[Yosiandra and Sakariah, 2024] Syakira Yuniar Yosiandra and Dewi Saraswati Sakariah. Unveiling the romance scam scheme: Psychological manipulation and its impact on vic- tims.Humanika, 31(2):185–199,
2024
-
[38]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595– 46623,
[Zhenget al., 2023 ] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595– 46623,
2023
-
[39]
How does nlp benefit legal system: A summary of research on legal judgment prediction
[Zhonget al., 2020 ] Haoxi Zhong, Zhipeng Guo, Cunchao Tu, Zhiyuan Liu, and Maosong Sun. How does nlp benefit legal system: A summary of research on legal judgment prediction. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5218–5230, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.