FCVSR: A Frequency-aware Method for Compressed Video Super-Resolution
Pith reviewed 2026-05-23 03:46 UTC · model grok-4.3
The pith
FCVSR processes frequency subbands separately in space and tracks their temporal changes to improve compressed video super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FCVSR consists of a motion-guided adaptive alignment network and a multi-frequency feature refinement module, trained with a frequency-aware contrastive loss, to differentiate frequency subbands spatially while capturing temporal frequency dynamics for compressed video super-resolution.
What carries the argument
The multi-frequency feature refinement module, which separates and refines distinct frequency subbands while incorporating motion alignment and contrastive training.
If this is right
- The model delivers up to 0.14 dB PSNR improvement over the second-best method on standard compressed video SR benchmarks.
- Model complexity stays lower than competing approaches while achieving the reported quality gains.
- The frequency-aware contrastive loss enables reconstruction of finer spatial details than standard losses.
- Spatio-temporal frequency information is handled more effectively than in earlier frequency-domain video SR techniques.
Where Pith is reading between the lines
- The same subband separation and temporal tracking could be tested on related tasks such as compressed video denoising.
- Replacing the contrastive loss with other frequency-sensitive objectives might further reduce artifacts in low-bitrate footage.
- The motion-guided alignment component could be isolated and applied to non-frequency video enhancement pipelines.
Load-bearing premise
Differentiating frequency subbands spatially and tracking their temporal dynamics will prevent suboptimal results and produce measurable quality gains over prior frequency-based methods.
What would settle it
Running the three public compressed video SR datasets through FCVSR and finding no PSNR improvement or higher complexity than the second-best existing model would falsify the central performance claim.
Figures







read the original abstract
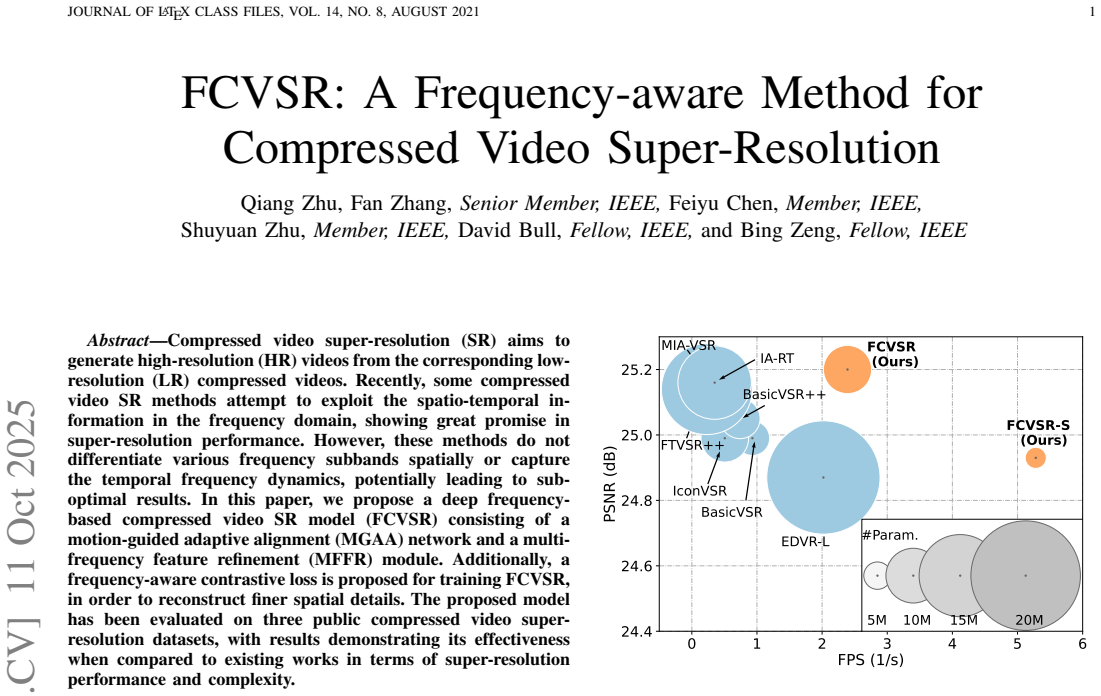
Compressed video super-resolution (SR) aims to generate high-resolution (HR) videos from the corresponding low-resolution (LR) compressed videos. Recently, some compressed video SR methods attempt to exploit the spatio-temporal information in the frequency domain, showing great promise in super-resolution performance. However, these methods do not differentiate various frequency subbands spatially or capture the temporal frequency dynamics, potentially leading to suboptimal results. In this paper, we propose a deep frequency-based compressed video SR model (FCVSR) consisting of a motion-guided adaptive alignment (MGAA) network and a multi-frequency feature refinement (MFFR) module. Additionally, a frequency-aware contrastive loss is proposed for training FCVSR, in order to reconstruct finer spatial details. The proposed model has been evaluated on three public compressed video super-resolution datasets, with results demonstrating its effectiveness when compared to existing works in terms of super-resolution performance (up to a 0.14dB gain in PSNR over the second-best model) and complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FCVSR, a deep frequency-based model for compressed video super-resolution consisting of a motion-guided adaptive alignment (MGAA) network, a multi-frequency feature refinement (MFFR) module, and a frequency-aware contrastive loss. It claims that explicitly differentiating frequency subbands spatially and capturing temporal frequency dynamics yields up to 0.14 dB PSNR gains over prior methods on three public datasets while also improving complexity.
Significance. If the reported gains can be isolated to the frequency-aware components, the work would provide a concrete advance in handling compressed video SR by addressing a stated limitation of prior frequency-domain methods. The evaluation on public datasets and reported complexity improvements are positive features.
major comments (2)
- [§4] §4 (Experiments): The paper reports up to 0.14 dB PSNR improvement but provides no component-wise ablations that isolate the contribution of spatial frequency subband differentiation within MFFR or temporal frequency dynamics within MGAA (e.g., MFFR with vs. without per-subband spatial processing). Without these controls, the central attribution of the observed delta to the frequency-aware design choices cannot be verified.
- [§3.2] §3.2 (MFFR module): The description of multi-frequency feature refinement does not include quantitative analysis showing that the per-subband spatial differentiation produces measurable refinement gains independent of the overall network capacity or the contrastive loss.
minor comments (2)
- [Abstract] Abstract and §1: The claim that prior methods 'do not differentiate various frequency subbands spatially' would benefit from a brief citation or table contrasting the exact architectural choices in the referenced works.
- [§4] §4: Table reporting PSNR/SSIM should include standard deviations or multiple runs to support the 0.14 dB claim as statistically meaningful.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for stronger isolation of our frequency-aware components. We address each point below and will revise the manuscript to incorporate additional ablations and analysis.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The paper reports up to 0.14 dB PSNR improvement but provides no component-wise ablations that isolate the contribution of spatial frequency subband differentiation within MFFR or temporal frequency dynamics within MGAA (e.g., MFFR with vs. without per-subband spatial processing). Without these controls, the central attribution of the observed delta to the frequency-aware design choices cannot be verified.
Authors: We agree that the current experiments do not include the requested component-wise controls (e.g., MFFR with vs. without per-subband spatial processing, or MGAA variants isolating temporal frequency dynamics). The reported gains are shown via full-model comparisons against prior methods, but these do not fully isolate the frequency subband contributions from overall capacity or the contrastive loss. We will add the suggested ablation studies in the revised manuscript, including quantitative results for the isolated components, to directly verify their contributions to the 0.14 dB PSNR delta. revision: yes
-
Referee: [§3.2] §3.2 (MFFR module): The description of multi-frequency feature refinement does not include quantitative analysis showing that the per-subband spatial differentiation produces measurable refinement gains independent of the overall network capacity or the contrastive loss.
Authors: The MFFR description in §3.2 emphasizes the architectural motivation for per-subband spatial differentiation to address limitations of prior frequency-domain methods. However, we acknowledge the absence of quantitative controls isolating these gains from network capacity or the contrastive loss. In revision, we will supplement the section with controlled experiments (e.g., MFFR variants with/without subband-specific processing) reporting independent refinement metrics to demonstrate the measurable contribution. revision: yes
Circularity Check
No circularity: empirical architecture evaluated on public benchmarks
full rationale
The paper proposes a neural architecture (MGAA + MFFR + frequency-aware contrastive loss) for compressed video SR and reports PSNR gains on three public datasets. No derivation chain, first-principles predictions, or fitted quantities are present; performance claims rest on external empirical evaluation rather than any self-definition, self-citation load-bearing step, or renaming of known results. The method is self-contained against standard benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
W. Zheng, H. Xu, P. Li, R. Wang, and X. Shao, “Sac-rsm: A high-performance uav-side road surveillance model based on super-resolution assisted learning,”IEEE Internet of Things Journal, 2024
work page 2024
-
[2]
Human face super-resolution on poor quality surveillance video footage,
M. Farooq, M. N. Dailey, A. Mahmood, J. Moonrinta, and M. Ekpanyapong, “Human face super-resolution on poor quality surveillance video footage,”Neural Computing and Applica- tions, vol. 33, pp. 13 505–13 523, 2021
work page 2021
-
[3]
Z. Chen, L. Yang, J.-H. Lai, and X. Xie, “Cunerf: Cube-based neural radiance field for zero-shot medical image arbitrary-scale super resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 185–21 195
work page 2023
-
[4]
Rethink- ing dual-stream super-resolution semantic learning in medical image segmentation,
Z. Qiu, Y . Hu, X. Chen, D. Zeng, Q. Hu, and J. Liu, “Rethink- ing dual-stream super-resolution semantic learning in medical image segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
work page 2023
-
[5]
A super-resolution-based feature map compression for machine-oriented video coding,
J.-H. Kang, M. S. Ali, H.-W. Jeong, C.-K. Choi, Y . Kim, S. Y . Jeong, S.-H. Bae, and H. Y . Kim, “A super-resolution-based feature map compression for machine-oriented video coding,” IEEE Access, vol. 11, pp. 34 198–34 209, 2023
work page 2023
-
[6]
Luma-only resampling-based video coding with cnn-based super resolu- tion,
C. Lin, Y . Li, J. Li, K. Zhang, and L. Zhang, “Luma-only resampling-based video coding with cnn-based super resolu- tion,” in2023 IEEE International Conference on Visual Com- munications and Image Processing, 2023, pp. 1–5
work page 2023
-
[7]
Optical flow estimation using a spatial pyramid network,
A. Ranjan and M. J. Black, “Optical flow estimation using a spatial pyramid network,” inProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition, 2017, pp. 4161–4170
work page 2017
-
[8]
Raft: Recurrent all-pairs field transforms for optical flow,
Z. Teed and J. Deng, “Raft: Recurrent all-pairs field transforms for optical flow,” inProceedings of the European Conference on Computer Vision, 2020, pp. 402–419
work page 2020
-
[9]
Deformable convolutional networks,
J. Dai, H. Qi, Y . Xiong, Y . Li, G. Zhang, H. Hu, and Y . Wei, “Deformable convolutional networks,” inProceedings of the IEEE International Conference on Computer Vision, 2017, pp. 764–773
work page 2017
-
[10]
Deformable convnets v2: More deformable, better results,
X. Zhu, H. Hu, S. Lin, and J. Dai, “Deformable convnets v2: More deformable, better results,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2019, pp. 9308–9316
work page 2019
-
[11]
Vivit: A video vision transformer,
A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu ˇci´c, and C. Schmid, “Vivit: A video vision transformer,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 6836–6846
work page 2021
-
[12]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,”Advances in Neural Information Processing Systems, vol. 35, pp. 8633–8646, 2022
work page 2022
-
[13]
Basicvsr: The search for essential components in video super-resolution and beyond,
K. C. Chan, X. Wang, K. Yu, C. Dong, and C. C. Loy, “Basicvsr: The search for essential components in video super-resolution and beyond,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 4947– 4956
work page 2021
-
[14]
Temporal consis- tency learning of inter-frames for video super-resolution,
M. Liu, S. Jin, C. Yao, C. Lin, and Y . Zhao, “Temporal consis- tency learning of inter-frames for video super-resolution,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 33, no. 4, pp. 1507–1520, 2022
work page 2022
-
[15]
Tdan: Temporally- deformable alignment network for video super-resolution,
Y . Tian, Y . Zhang, Y . Fu, and C. Xu, “Tdan: Temporally- deformable alignment network for video super-resolution,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3360–3369
work page 2020
-
[16]
Edvr: Video restoration with enhanced deformable convolu- tional networks,
X. Wang, K. C. Chan, K. Yu, C. Dong, and C. Change Loy, “Edvr: Video restoration with enhanced deformable convolu- tional networks,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2019, pp. 1954–1963
work page 2019
-
[17]
Learning trajectory- aware transformer for video super-resolution,
C. Liu, H. Yang, J. Fu, and X. Qian, “Learning trajectory- aware transformer for video super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5687–5696
work page 2022
-
[18]
Learning degradation-robust spatiotemporal frequency-transformer for video super-resolution,
Z. Qiu, H. Yang, J. Fu, D. Liu, C. Xu, and D. Fu, “Learning degradation-robust spatiotemporal frequency-transformer for video super-resolution,”IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 14 888–14 904, 2023
work page 2023
-
[19]
Upscale-a- video: Temporal-consistent diffusion model for real-world video super-resolution,
S. Zhou, P. Yang, J. Wang, Y . Luo, and C. C. Loy, “Upscale-a- video: Temporal-consistent diffusion model for real-world video super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2535– 2545
work page 2024
-
[20]
Motion-guided latent diffusion for temporally consistent real-world video super- resolution,
X. Yang, C. He, J. Ma, and L. Zhang, “Motion-guided latent diffusion for temporally consistent real-world video super- resolution,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 224–242
work page 2025
-
[21]
Video compression based on spatio-temporal resolution adaptation,
M. Afonso, F. Zhang, and D. R. Bull, “Video compression based on spatio-temporal resolution adaptation,”IEEE Transactions on JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13 Circuits and Systems for Video Technology, vol. 29, no. 1, pp. 275–280, 2018
work page 2021
-
[22]
Down-sampling based video coding using super-resolution technique,
M. Shen, P. Xue, and C. Wang, “Down-sampling based video coding using super-resolution technique,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 21, no. 6, pp. 755–765, 2011
work page 2011
-
[23]
Efficient video compression via content-adaptive super-resolution,
M. Khani, V . Sivaraman, and M. Alizadeh, “Efficient video compression via content-adaptive super-resolution,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 4521–4530
work page 2021
-
[24]
Learned low bitrate video compression with space-time super- resolution,
J. Yang, C. Yang, F. Xiong, F. Wang, and R. Wang, “Learned low bitrate video compression with space-time super- resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1786– 1790
work page 2022
-
[25]
D. Bull and F. Zhang,Intelligent image and video compression: communicating pictures. Academic Press, 2021
work page 2021
-
[26]
Blind quality enhancement for compressed video,
Q. Ding, L. Shen, L. Yu, H. Yang, and M. Xu, “Blind quality enhancement for compressed video,”IEEE Transactions on Multimedia, pp. 5782–5794, 2023
work page 2023
-
[27]
Video compression artifacts removal with spatial-temporal attention- guided enhancement,
N. Jiang, W. Chen, J. Lin, T. Zhao, and C.-W. Lin, “Video compression artifacts removal with spatial-temporal attention- guided enhancement,”IEEE Transactions on Multimedia, pp. 5657–5669, 2023
work page 2023
-
[28]
Spatio-temporal detail information retrieval for compressed video quality en- hancement,
D. Luo, M. Ye, S. Li, C. Zhu, and X. Li, “Spatio-temporal detail information retrieval for compressed video quality en- hancement,”IEEE Transactions on Multimedia, vol. 25, pp. 6808–6820, 2022
work page 2022
-
[29]
Comisr: Compression-informed video super-resolution,
Y . Li, P. Jin, F. Yang, C. Liu, M.-H. Yang, and P. Milan- far, “Comisr: Compression-informed video super-resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2543–2552
work page 2021
-
[30]
Compressed domain deep video super-resolution,
P. Chen, W. Yang, M. Wang, L. Sun, K. Hu, and S. Wang, “Compressed domain deep video super-resolution,”IEEE Trans- actions on Image Processing, vol. 30, pp. 7156–7169, 2021
work page 2021
-
[31]
A codec information assisted framework for efficient compressed video super-resolution,
H. Zhang, X. Zou, J. Guo, Y . Yan, R. Xie, and L. Song, “A codec information assisted framework for efficient compressed video super-resolution,” inEuropean Conference on Computer Vision, 2022, pp. 220–235
work page 2022
-
[32]
Compression-aware video super-resolution,
Y . Wang, T. Isobe, X. Jia, X. Tao, H. Lu, and Y .-W. Tai, “Compression-aware video super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2012–2021
work page 2023
-
[33]
Deep compressed video super-resolution with guidance of coding priors,
Q. Zhu, F. Chen, Y . Liu, S. Zhu, and B. Zeng, “Deep compressed video super-resolution with guidance of coding priors,”IEEE Transactions on Broadcasting, 2024
work page 2024
-
[34]
Fm- vsr: Feature multiplexing video super-resolution for compressed video,
G. He, S. Wu, S. Pei, L. Xu, C. Wu, K. Xu, and Y . Li, “Fm- vsr: Feature multiplexing video super-resolution for compressed video,”IEEE Access, vol. 9, pp. 88 060–88 068, 2021
work page 2021
-
[35]
Aim 2024 challenge on efficient video super-resolution for av1 compressed content,
M. V . Conde, Z. Lei, W. Li, C. Bampis, I. Katsavouni- dis, and R. Timofte, “Aim 2024 challenge on efficient video super-resolution for av1 compressed content,”arXiv preprint arXiv:2409.17256, 2024
-
[36]
Gaussian mask guided attention for compressed video super resolution,
L. Chen, “Gaussian mask guided attention for compressed video super resolution,” inIEEE 2023 20th International Computer Conference on Wavelet Active Media Technology and Informa- tion Processing, 2023, pp. 1–6
work page 2023
-
[37]
Learning spatiotemporal frequency-transformer for compressed video super-resolution,
Z. Qiu, H. Yang, J. Fu, and D. Fu, “Learning spatiotemporal frequency-transformer for compressed video super-resolution,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 257–273
work page 2022
-
[38]
Compressed video super- resolution based on hierarchical encoding,
Y . Jiang, S. Teng, Q. Zhu, C. Feng, C. Zeng, F. Zhang, S. Zhu, B. Zeng, and D. Bull, “Compressed video super- resolution based on hierarchical encoding,”arXiv preprint arXiv:2506.14381, 2025
-
[39]
Basicvsr++: Improving video super-resolution with enhanced propagation and alignment,
K. C. Chan, S. Zhou, X. Xu, and C. C. Loy, “Basicvsr++: Improving video super-resolution with enhanced propagation and alignment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5972– 5981
work page 2022
-
[40]
Towards progressive multi-frequency representation for image warping,
J. Xiao, Z. Lyu, C. Zhang, Y . Ju, C. Shui, and K.-M. Lam, “Towards progressive multi-frequency representation for image warping,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2995– 3004
work page 2024
-
[41]
Multi-frequency representation enhancement with privilege information for video super-resolution,
F. Li, L. Zhang, Z. Liu, J. Lei, and Z. Li, “Multi-frequency representation enhancement with privilege information for video super-resolution,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2023, pp. 12 814– 12 825
work page 2023
-
[42]
Online video super-resolution with convolu- tional kernel bypass grafts,
J. Xiao, X. Jiang, N. Zheng, H. Yang, Y . Yang, Y . Yang, D. Li, and K.-M. Lam, “Online video super-resolution with convolu- tional kernel bypass grafts,”IEEE Transactions on Multimedia, vol. 25, pp. 8972–8987, 2023
work page 2023
-
[43]
Fffn: Frame-by-frame feedback fusion network for video super-resolution,
J. Zhu, Q. Zhang, L. Fei, R. Cai, Y . Xie, B. Sheng, and X. Yang, “Fffn: Frame-by-frame feedback fusion network for video super-resolution,”IEEE Transactions on Multimedia, vol. 25, pp. 6821–6835, 2022
work page 2022
-
[44]
Omni- directional video super-resolution using deep learning,
A. A. Baniya, T.-K. Lee, P. W. Eklund, and S. Aryal, “Omni- directional video super-resolution using deep learning,”IEEE Transactions on Multimedia, vol. 26, pp. 540–554, 2023
work page 2023
-
[45]
Video super-resolution transformer with masked inter&intra- frame attention,
X. Zhou, L. Zhang, X. Zhao, K. Wang, L. Li, and S. Gu, “Video super-resolution transformer with masked inter&intra- frame attention,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 399– 25 408
work page 2024
-
[46]
En- hancing video super-resolution via implicit resampling-based alignment,
K. Xu, Z. Yu, X. Wang, M. B. Mi, and A. Yao, “En- hancing video super-resolution via implicit resampling-based alignment,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2546– 2555
work page 2024
-
[47]
Trajectory-aware shifted state space models for online video super-resolution,
Q. Zhu, X. Meng, Y . Jiang, F. Zhang, D. Bull, S. Zhu, and B. Zeng, “Trajectory-aware shifted state space models for online video super-resolution,”arXiv preprint arXiv:2508.10453, 2025
-
[48]
On bayesian adaptive video super reso- lution,
C. Liu and D. Sun, “On bayesian adaptive video super reso- lution,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 2, pp. 346–360, 2013
work page 2013
-
[49]
Robust web image/video super- resolution,
Z. Xiong, X. Sun, and F. Wu, “Robust web image/video super- resolution,”IEEE Transactions on Image Processing, vol. 19, no. 8, pp. 2017–2028, 2010
work page 2017
-
[50]
Q. Zhu, F. Chen, S. Zhu, Y . Liu, X. Zhou, R. Xiong, and B. Zeng, “Dvsrnet: Deep video super-resolution based on pro- gressive deformable alignment and temporal-sparse enhance- ment,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[51]
Video super-resolution with pyramid flow-guided deformable alignment network,
T. Qing, X. Ying, Z. Sha, and J. Wu, “Video super-resolution with pyramid flow-guided deformable alignment network,” in IEEE 2023 3rd International Conference on Electrical Engi- neering and Mechatronics Technology, 2023, pp. 758–764
work page 2023
-
[52]
Ctvsr: Collaborative spatial-temporal transformer for video super- resolution,
J. Tang, C. Lu, Z. Liu, J. Li, H. Dai, and Y . Ding, “Ctvsr: Collaborative spatial-temporal transformer for video super- resolution,”IEEE Transactions on Circuits and Systems for Video Technology, 2023
work page 2023
-
[53]
Lamd: Latent motion diffusion for video generation,
Y . Hu, Z. Chen, and C. Luo, “Lamd: Latent motion diffusion for video generation,”arXiv preprint arXiv:2304.11603, 2023
-
[54]
Learning spatial adaptation and temporal coherence in diffusion models for video super-resolution,
Z. Chen, F. Long, Z. Qiu, T. Yao, W. Zhou, J. Luo, and T. Mei, “Learning spatial adaptation and temporal coherence in diffusion models for video super-resolution,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9232–9241
work page 2024
-
[55]
S. Dong, F. Lu, Z. Wu, and C. Yuan, “Dfvsr: Directional fre- quency video super-resolution via asymmetric and enhancement alignment network.” inProceedings of the International Joint Conferences on Artificial Intelligence, 2023, pp. 681–689
work page 2023
-
[56]
Fast and accurate image super-resolution with deep laplacian pyramid networks,
W.-S. Lai, J.-B. Huang, N. Ahuja, and M.-H. Yang, “Fast and accurate image super-resolution with deep laplacian pyramid networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 41, no. 11, pp. 2599–2613, 2018. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
work page 2018
-
[57]
Fourier space losses for efficient perceptual image super-resolution,
D. Fuoli, L. Van Gool, and R. Timofte, “Fourier space losses for efficient perceptual image super-resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2360–2369
work page 2021
-
[58]
Focal frequency loss for image reconstruction and synthesis,
L. Jiang, B. Dai, W. Wu, and C. C. Loy, “Focal frequency loss for image reconstruction and synthesis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 13 919–13 929
work page 2021
-
[59]
Flownet: Learning optical flow with convolutional networks,
A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V . Golkov, P. Van Der Smagt, D. Cremers, and T. Brox, “Flownet: Learning optical flow with convolutional networks,” inProceedings of the IEEE International Conference on Com- puter Vision, 2015, pp. 2758–2766
work page 2015
-
[60]
Flownet 2.0: Evolution of optical flow estimation with deep networks,
E. Ilg, N. Mayer, T. Saikia, M. Keuper, A. Dosovitskiy, and T. Brox, “Flownet 2.0: Evolution of optical flow estimation with deep networks,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 2462– 2470
work page 2017
-
[61]
Video enhancement with task-oriented flow,
T. Xue, B. Chen, J. Wu, D. Wei, and W. T. Freeman, “Video enhancement with task-oriented flow,”International Journal of Computer Vision, vol. 127, pp. 1106–1125, 2019
work page 2019
-
[62]
Ex- ploring temporal frequency spectrum in deep video deblurring,
Q. Zhu, M. Zhou, N. Zheng, C. Li, J. Huang, and F. Zhao, “Ex- ploring temporal frequency spectrum in deep video deblurring,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 12 428–12 437
work page 2023
-
[63]
Image super-resolution using very deep residual channel attention networks,
Y . Zhang, K. Li, K. Li, L. Wang, B. Zhong, and Y . Fu, “Image super-resolution using very deep residual channel attention networks,” inProceedings of the European Conference on Computer Vision, 2018, pp. 286–301
work page 2018
-
[64]
Motion-adaptive separable collaborative filters for blind motion deblurring,
C. Liu, X. Wang, X. Xu, R. Tian, S. Li, X. Qian, and M.- H. Yang, “Motion-adaptive separable collaborative filters for blind motion deblurring,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 25 595–25 605
work page 2024
-
[65]
Spatio-temporal filter adaptive network for video deblurring,
S. Zhou, J. Zhang, J. Pan, H. Xie, W. Zuo, and J. Ren, “Spatio-temporal filter adaptive network for video deblurring,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 2482–2491
work page 2019
-
[66]
Scale-wise convolution for image restoration,
Y . Fan, J. Yu, D. Liu, and T. S. Huang, “Scale-wise convolution for image restoration,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 10 770– 10 777
work page 2020
-
[67]
X. Gao, T. Qiu, X. Zhang, H. Bai, K. Liu, X. Huang, H. Wei, G. Zhang, and H. Liu, “Efficient multi-scale network with learn- able discrete wavelet transform for blind motion deblurring,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2733–2742
work page 2024
-
[68]
Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,
S. Nah, S. Baik, S. Hong, G. Moon, S. Son, R. Timofte, and K. Mu Lee, “Ntire 2019 challenge on video deblurring and super-resolution: Dataset and study,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition workshops, 2019, pp. 0–0
work page 2019
-
[69]
Adam: A Method for Stochastic Optimization
D. P. Kingma, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[70]
H. 264/avc to hevc video transcoder based on dynamic thresholding and content modeling,
E. Peixoto, T. Shanableh, and E. Izquierdo, “H. 264/avc to hevc video transcoder based on dynamic thresholding and content modeling,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 24, no. 1, pp. 99–112, 2013
work page 2013
-
[71]
Image quality assessment: from error visibility to structural similarity,
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: from error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004
work page 2004
-
[72]
Z. Li, C. Bampis, J. Novak, A. Aaron, K. Swanson, A. Moorthy, and J. Cock, “Vmaf: The journey continues,”Netflix Technology Blog, vol. 25, no. 1, 2018
work page 2018
-
[73]
Y . Jo, S. W. Oh, J. Kang, and S. J. Kim, “Deep video super- resolution network using dynamic upsampling filters without explicit motion compensation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3224–3232
work page 2018
-
[74]
Learning temporal coherence via self-supervision for gan- based video generation,
M. Chu, Y . Xie, J. Mayer, L. Leal-Taix ´e, and N. Thuerey, “Learning temporal coherence via self-supervision for gan- based video generation,”ACM Transactions on Graphics, vol. 39, no. 4, pp. 75–1, 2020
work page 2020
-
[75]
Detail-revealing deep video super-resolution,
X. Tao, H. Gao, R. Liao, J. Wang, and J. Jia, “Detail-revealing deep video super-resolution,” inProceedings of the IEEE Inter- national Conference on Computer Vision, 2017, pp. 4472–4480
work page 2017
-
[76]
Video super-resolution with recurrent structure-detail network,
T. Isobe, X. Jia, S. Gu, S. Li, S. Wang, and Q. Tian, “Video super-resolution with recurrent structure-detail network,” in European Conference on Computer Vision. Springer, 2020, pp. 645–660
work page 2020
-
[77]
Mucan: Multi-correspondence aggregation network for video super- resolution,
W. Li, X. Tao, T. Guo, L. Qi, J. Lu, and J. Jia, “Mucan: Multi-correspondence aggregation network for video super- resolution,” inEuropean Conference on Computer Vision. Springer, 2020, pp. 335–351
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.