On the Reliability of Information Retrieval From MDS Coded Data in DNA Storage
Pith reviewed 2026-05-23 03:33 UTC · model grok-4.3
The pith
MDS-coded DNA storage retrieval success probability depends on sequencing reads, code rates, and error probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The probability of successful data retrieval from MDS-coded DNA storage under i.i.d. substitution errors is a function of the total sequencing reads, their distribution, inner and outer code rates, and substitution probabilities, with explicit expressions provided for this dependence.
What carries the argument
Concatenated inner-outer MDS codes whose success probability is derived from strand coverage and the error-correction capability of each code layer.
If this is right
- The minimum number of sequencing reads needed for a target reliability level can be calculated directly from the expressions.
- An optimal split of redundancy between the inner and outer MDS codes can be identified for given read counts and error rates.
- Designers can trade sequencing depth against code rates while still meeting a reliability target.
Where Pith is reading between the lines
- The same style of coverage-based analysis could be applied to insertion-deletion errors typical in DNA sequencing.
- Storage systems might use the expressions to set dynamic read-depth targets based on observed error rates.
- The approach connects to reliability questions in other noisy storage media that employ concatenated coding.
Load-bearing premise
Substitution errors occur independently and identically across all sequenced symbols, with the inner-outer MDS codes serving as the sole error-correction mechanism.
What would settle it
Sequencing experiments that produce clustered or correlated substitution errors whose observed retrieval rate deviates from the derived probability expressions.
Figures



read the original abstract
This work presents a theoretical analysis of the probability of successfully retrieving data encoded with MDS codes (e.g., Reed-Solomon codes) in DNA storage systems. We study this probability under independent and identically distributed (i.i.d.) substitution errors, focusing on a common code design strategy that combines inner and outer MDS codes. Our analysis demonstrates how this probability depends on factors such as the total number of sequencing reads, their distribution across strands, the rates of the inner and outer codes, and the substitution error probabilities. These results provide actionable insights into optimizing DNA storage systems under reliability constraints, including determining the minimum number of sequencing reads needed for reliable data retrieval and identifying the optimal balance between the rates of inner and outer MDS codes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a theoretical analysis of the probability of successful data retrieval from DNA storage systems using concatenated inner and outer MDS codes (e.g., Reed-Solomon) under an i.i.d. substitution error model. It derives explicit expressions showing the dependence of this probability on the total number of sequencing reads, their distribution across strands, the inner and outer code rates, and the substitution error probability, with the aim of providing optimization guidelines such as minimum read counts and rate balancing.
Significance. If the derivations hold, the work supplies actionable closed-form or computable expressions for retrieval success probability in a standard concatenated MDS setup, which can directly inform DNA storage system design without sole reliance on simulation. This is a strength in a field where explicit analytical tools for reliability under memoryless errors are valuable; the approach is internally consistent with the binomial coverage plus MDS threshold decoding path common in the literature.
minor comments (2)
- [Abstract] The abstract states that the analysis 'demonstrates how this probability depends on' the listed factors but does not indicate whether the final expressions are closed-form, involve finite sums, or require numerical evaluation; a brief clarification would improve accessibility.
- A table collecting the notation for inner/outer code parameters (length, dimension, rate) and error model variables would aid readability, as the current inline definitions are scattered.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The provided summary accurately reflects the paper's contributions and scope.
Circularity Check
No significant circularity
full rationale
The paper frames its contribution as a theoretical derivation of retrieval success probability under an explicit i.i.d. substitution error model, using standard binomial coverage per strand followed by MDS decoding thresholds for the inner-outer concatenation. No equations reduce a claimed prediction to a fitted parameter on the same data, no self-citation is load-bearing for the central expressions, and the derivation path is internally consistent with the stated assumptions without importing uniqueness theorems or ansatzes from prior author work. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Substitution errors occur independently and identically distributed across sequenced symbols.
- domain assumption Data recovery is performed solely by the inner and outer MDS codes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 2 expresses α(r), β(r), γ(r) via binomial CDF/PMF on symbol error rate ϵ'(r) under BDD radius t = (n'-k')/2.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3 reduces successful retrieval to SN(r) ≥ K where SN is sum of independent Zj(rj) ∈ {-1,0,+1}.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Rydning, “Worldwide idc global datasphere forecast, 2022–2026: enterprise organizations driving most of the data growth,”International Data Corporation (IDC), 2022
work page 2022
-
[2]
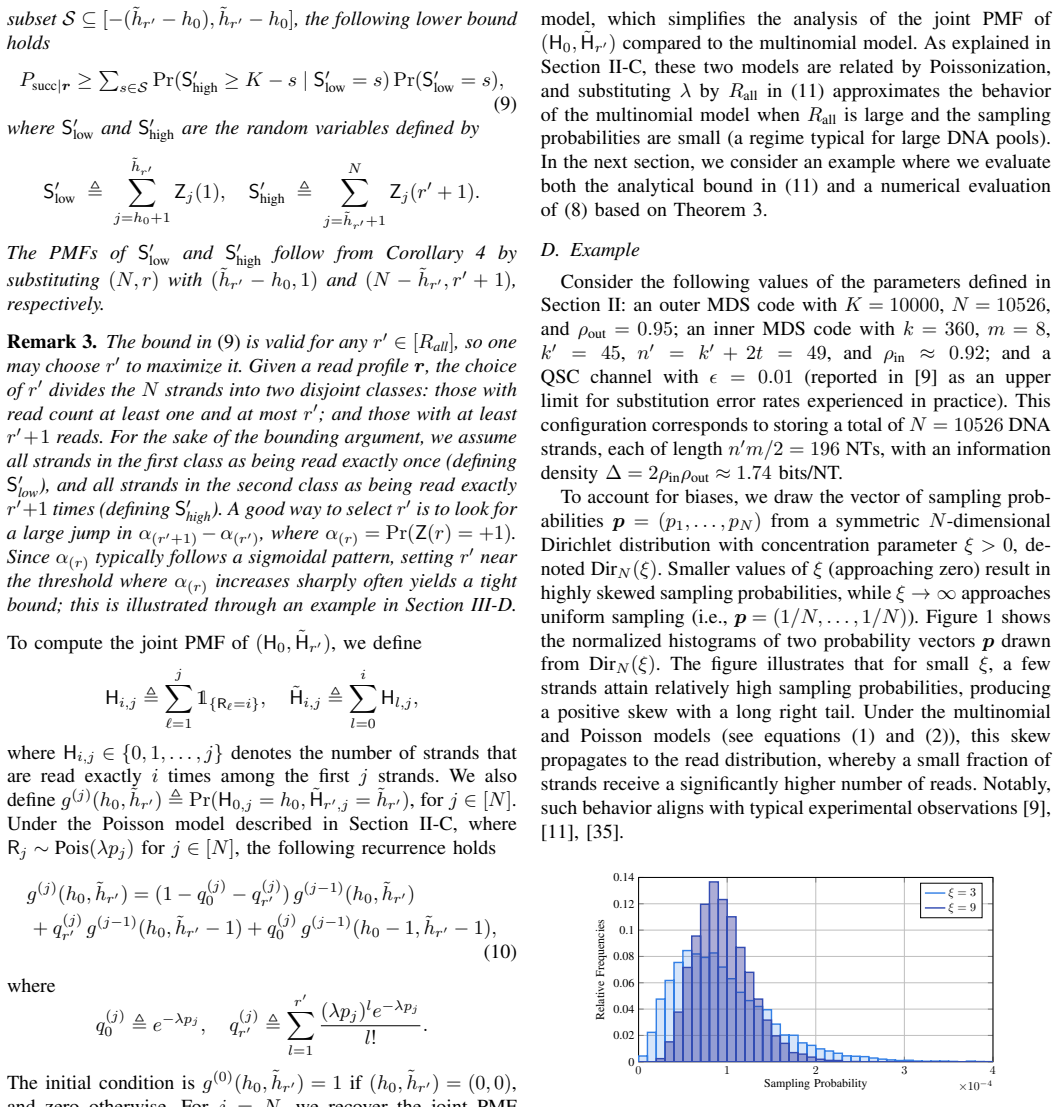
Next-generation digital informa- tion storage in DNA,
G. M. Church, Y . Gao, and S. Kosuri, “Next-generation digital informa- tion storage in DNA,”Science, vol. 337, no. 6102, pp. 1628–1628, 2012
work page 2012
-
[3]
Robust chemical preservation of digital information on DNA in silica with error- correcting codes,
R. N. Grass, R. Heckel, M. Puddu, D. Paunescu, and W. J. Stark, “Robust chemical preservation of digital information on DNA in silica with error- correcting codes,”Angewandte Chemie International Edition, vol. 54, no. 8, pp. 2552–2555, 2015
work page 2015
-
[4]
Molecular digital data storage using DNA,
L. Ceze, J. Nivala, and K. Strauss, “Molecular digital data storage using DNA,”Nature Reviews Genetics, vol. 20, no. 8, pp. 456–466, 2019
work page 2019
-
[5]
DNA-based storage: Trends and methods,
S. H. T. Yazdi, H. M. Kiah, E. Garcia-Ruiz, J. Ma, H. Zhao, and O. Milenkovic, “DNA-based storage: Trends and methods,”IEEE Trans- actions on Molecular, Biological and Multi-Scale Communications, vol. 1, no. 3, pp. 230–248, 2015
work page 2015
-
[6]
Information-theoretic foundations of DNA data storage,
I. Shomorony, R. Heckelet al., “Information-theoretic foundations of DNA data storage,”Foundations and Trends® in Communications and Information Theory, vol. 19, no. 1, pp. 1–106, 2022
work page 2022
-
[7]
A characterization of the DNA data storage channel,
R. Heckel, G. Mikutis, and R. N. Grass, “A characterization of the DNA data storage channel,”Scientific reports, vol. 9, no. 1, p. 9663, 2019
work page 2019
-
[8]
Reading and writing digital data in DNA,
L. C. Meiser, P. L. Antkowiak, J. Koch, W. D. Chen, A. X. Kohll, W. J. Stark, R. Heckel, and R. N. Grass, “Reading and writing digital data in DNA,”Nature protocols, vol. 15, no. 1, pp. 86–101, 2020
work page 2020
-
[9]
A digital twin for DNA data storage based on comprehensive quantification of errors and biases,
A. L. Gimpel, W. J. Stark, R. Heckel, and R. N. Grass, “A digital twin for DNA data storage based on comprehensive quantification of errors and biases,”Nature Communications, vol. 14, no. 1, p. 6026, 2023
work page 2023
-
[10]
Forward error correction for DNA data storage,
M. Blawat, K. Gaedke, I. Huetter, X.-M. Chen, B. Turczyk, S. Inverso, B. W. Pruitt, and G. M. Church, “Forward error correction for DNA data storage,”Procedia Computer Science, vol. 80, pp. 1011–1022, 2016
work page 2016
-
[11]
DNA fountain enables a robust and efficient storage architecture,
Y . Erlich and D. Zielinski, “DNA fountain enables a robust and efficient storage architecture,”science, vol. 355, no. 6328, pp. 950–954, 2017
work page 2017
-
[12]
Portable and error-free DNA-based data storage,
S. H. T. Yazdi, R. Gabrys, and O. Milenkovic, “Portable and error-free DNA-based data storage,”Scientific reports, vol. 7, no. 1, p. 5011, 2017
work page 2017
-
[13]
Random access in large-scale DNA data storage,
L. Organick, S. D. Ang, Y .-J. Chen, R. Lopez, S. Yekhanin, K. Makarychev, M. Z. Racz, G. Kamath, P. Gopalan, B. Nguyenet al., “Random access in large-scale DNA data storage,”Nature biotechnology, vol. 36, no. 3, pp. 242–248, 2018
work page 2018
-
[14]
S. Chandak, J. Neu, K. Tatwawadi, J. Mardia, B. Lau, M. Kubit, R. Hulett, P. Griffin, M. Wootters, T. Weissmanet al., “Overcoming high nanopore basecaller error rates for DNA storage via basecaller-decoder integration and convolutional codes,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020,...
work page 2020
-
[15]
Hedges error-correcting code for DNA storage corrects indels and allows sequence constraints,
W. H. Press, J. A. Hawkins, S. K. Jones Jr, J. M. Schaub, and I. J. Finkelstein, “Hedges error-correcting code for DNA storage corrects indels and allows sequence constraints,”Proceedings of the National Academy of Sciences, vol. 117, no. 31, pp. 18 489–18 496, 2020
work page 2020
-
[16]
Concatenated codes for multiple reads of a DNA sequence,
I. Maarouf, A. Lenz, L. Welter, A. Wachter-Zeh, E. Rosnes, and A. G. i Amat, “Concatenated codes for multiple reads of a DNA sequence,” IEEE Transactions on Information Theory, vol. 69, no. 2, pp. 910–927, 2023
work page 2023
-
[17]
M. Welzel, P. M. Schwarz, H. F. Löchel, T. Kabdullayeva, S. Clemens, A. Becker, B. Freisleben, and D. Heider, “DNA-aeon provides flexible arithmetic coding for constraint adherence and error correction in DNA storage,”Nature Communications, vol. 14, no. 1, p. 628, 2023
work page 2023
-
[18]
Short systematic codes for correcting random edit errors in DNA storage,
S. Kas Hanna, “Short systematic codes for correcting random edit errors in DNA storage,” in2024 IEEE International Symposium on Information Theory (ISIT), 2024, pp. 663–668
work page 2024
-
[19]
GC+ code: A systematic short blocklength code for correcting random edit errors in DNA storage,
——, “GC+ code: A systematic short blocklength code for correcting random edit errors in DNA storage,” 2025. [Online]. Available: https://arxiv.org/abs/2402.01244
-
[20]
Marker guess & check plus (MGC+): An efficient short blocklength code for random edit errors,
R. Khabbaz, M. Antonini, and S. Kas Hanna, “Marker guess & check plus (MGC+): An efficient short blocklength code for random edit errors,” in 2025 13th International Symposium on Topics in Coding (ISTC), 2025
work page 2025
-
[21]
Polynomial codes over certain finite fields,
I. S. Reed and G. Solomon, “Polynomial codes over certain finite fields,” Journal of the society for industrial and applied mathematics, vol. 8, no. 2, pp. 300–304, 1960
work page 1960
-
[22]
Cover your bases: How to minimize the sequencing coverage in DNA storage systems,
D. Bar-Lev, O. Sabary, R. Gabrys, and E. Yaakobi, “Cover your bases: How to minimize the sequencing coverage in DNA storage systems,” IEEE Transactions on Information Theory, vol. 71, no. 1, pp. 192–218, 2025
work page 2025
-
[23]
Sequencing coverage anal- ysis for combinatorial DNA-based storage systems,
I. Preuss, B. Galili, Z. Yakhini, and L. Anavy, “Sequencing coverage anal- ysis for combinatorial DNA-based storage systems,”IEEE Transactions on Molecular, Biological, and Multi-Scale Communications, 2024
work page 2024
-
[24]
Coding over coupon collector channels for combinatorial motif- based DNA storage,
R. Sokolovskii, P. Agarwal, L. Alberto Croquevielle, Z. Zhou, and T. Hei- nis, “Coding over coupon collector channels for combinatorial motif- based DNA storage,”IEEE Transactions on Communications, vol. 73, no. 6, pp. 3750–3760, 2025
work page 2025
-
[25]
Optimizing the decoding probability and cov- erage ratio of composite DNA,
T. Cohen and E. Yaakobi, “Optimizing the decoding probability and cov- erage ratio of composite DNA,” in2024 IEEE International Symposium on Information Theory (ISIT). IEEE, 2024, pp. 1949–1954
work page 2024
-
[26]
Efficient DNA-based data storage using shortmer combinatorial encoding,
I. Preuss, M. Rosenberg, Z. Yakhini, and L. Anavy, “Efficient DNA-based data storage using shortmer combinatorial encoding,”Scientific reports, vol. 14, no. 1, p. 7731, 2024
work page 2024
-
[27]
Covering all bases: The next inning in DNA sequencing efficiency,
H. Abraham, R. Gabrys, and E. Yaakobi, “Covering all bases: The next inning in DNA sequencing efficiency,” in2024 IEEE International Symposium on Information Theory (ISIT). IEEE, 2024, pp. 464–469
work page 2024
-
[28]
A combinatorial perspective on random access efficiency for DNA storage,
A. Gruica, D. Bar-Lev, A. Ravagnani, and E. Yaakobi, “A combinatorial perspective on random access efficiency for DNA storage,” in2024 IEEE International Symposium on Information Theory (ISIT), 2024
work page 2024
-
[29]
Improved read/write cost tradeoff in DNA-based data storage using ldpc codes,
S. Chandak, K. Tatwawadi, B. Lau, J. Mardia, M. Kubit, J. Neu, P. Griffin, M. Wootters, T. Weissman, and H. Ji, “Improved read/write cost tradeoff in DNA-based data storage using ldpc codes,” in2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton). IEEE, 2019, pp. 147–156
work page 2019
-
[30]
Gradhc: highly reliable gradual hash-based clustering for DNA storage systems,
D. Ben Shabat, A. Hadad, A. Boruchovsky, and E. Yaakobi, “Gradhc: highly reliable gradual hash-based clustering for DNA storage systems,” Bioinformatics, vol. 40, no. 5, p. btae274, 2024
work page 2024
-
[31]
Clover: tree structure-based efficient DNA clustering for DNA-based data storage,
G. Qu, Z. Yan, and H. Wu, “Clover: tree structure-based efficient DNA clustering for DNA-based data storage,”Briefings in Bioinformatics, vol. 23, no. 5, p. bbac336, 2022
work page 2022
-
[32]
Clustering billions of reads for DNA data storage,
C. Rashtchian, K. Makarychev, M. Racz, S. Ang, D. Jevdjic, S. Yekhanin, L. Ceze, and K. Strauss, “Clustering billions of reads for DNA data storage,”Advances in Neural Information Processing Systems, vol. 30, 2017
work page 2017
-
[33]
More on the decoder error probability for reed-solomon codes,
K.-M. Cheung, “More on the decoder error probability for reed-solomon codes,”IEEE Transactions on Information Theory, vol. 35, no. 4, pp. 895–900, 1989
work page 1989
-
[34]
Algebraic coding theory, revised ed,
E. R. Berlekamp, “Algebraic coding theory, revised ed,”Laguna Hills, CA: Aegean Park, 1984
work page 1984
-
[35]
Quantifying molecular bias in DNA data storage,
Y .-J. Chen, C. N. Takahashi, L. Organick, C. Bee, S. D. Ang, P. Weiss, B. Peck, G. Seelig, L. Ceze, and K. Strauss, “Quantifying molecular bias in DNA data storage,”Nature communications, vol. 11, no. 1, p. 3264, 2020
work page 2020
-
[36]
On the decoder error probability for reed- solomon codes (corresp.),
R. McEliece and L. Swanson, “On the decoder error probability for reed- solomon codes (corresp.),”IEEE Transactions on Information Theory, vol. 32, no. 5, pp. 701–703, 2003
work page 2003
-
[37]
On the error rate of binary bch codes under error-and-erasure decoding,
S. Miao, J. Mandelbaum, H. Jäkel, and L. Schmalen, “On the error rate of binary bch codes under error-and-erasure decoding,” 2025. [Online]. Available: https://arxiv.org/abs/2509.24794
-
[38]
K. Cai, Y . M. Chee, R. Gabrys, H. M. Kiah, and T. T. Nguyen, “Correcting a single indel/edit for DNA-based data storage: Linear-time encoders and order-optimality,”IEEE Transactions on Information Theory, vol. 67, no. 6, pp. 3438–3451, 2021
work page 2021
-
[39]
An improvement of convergence rate estimates in the lyapunov theorem
I. G. Shevtsova, “An improvement of convergence rate estimates in the lyapunov theorem.” inDoklady Mathematics, vol. 82, no. 3, 2010. APPENDIXA PROOF OFLEMMA1 Let ˜Y 1 , ˜Y 2 , . . . , ˜Y r ∈Σ n/2 be ther∈Nnoisy copies generated by the channel corresponding to a given DNA strand ˜x∈Σ n/2, whereΣ ={A,C,G,T}. For each position i∈[n/2], the consensus nucleot...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.