From Action Labels to Sets: Rethinking Action Supervision for Imitation Learning from Corrective Feedback
Pith reviewed 2026-05-23 03:57 UTC · model grok-4.3
The pith
Imitation learning replaces single action labels with sets of desired actions built from human corrections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
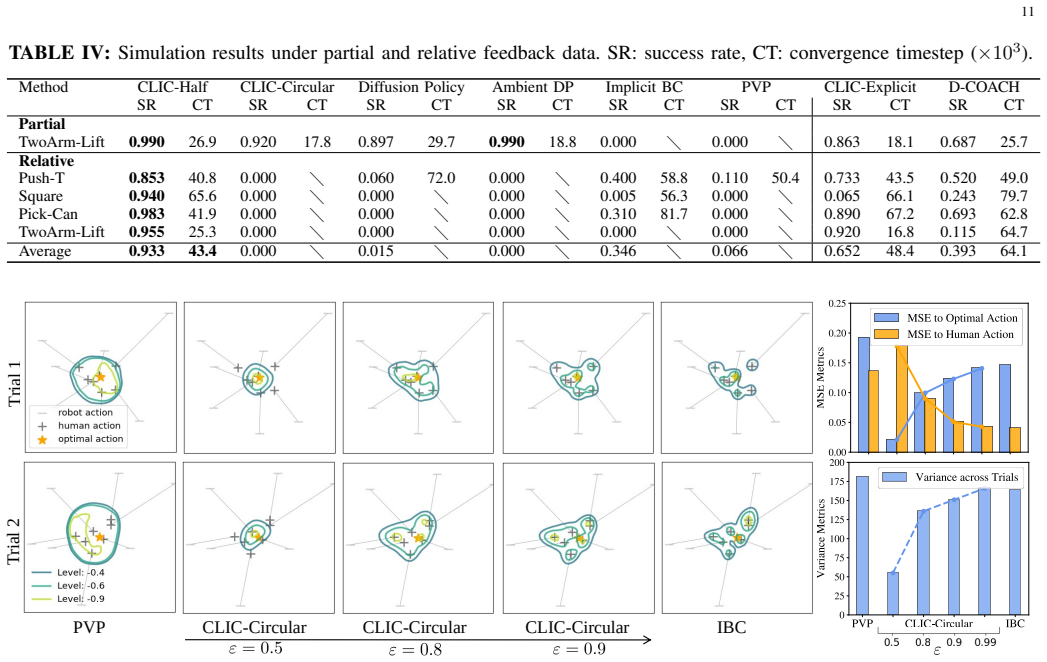
The paper establishes that imitation learning from corrective feedback can be reformulated by constructing sets of desired actions from human corrections and optimizing policies to distribute probability mass across these sets, rather than targeting single actions. This set-based supervision naturally accommodates imperfect feedback and enables representation of complex behaviors.
What carries the argument
Set-valued action targets constructed from human corrections and optimized via contrastive policy learning to place probability mass over the sets.
If this is right
- The formulation accommodates both absolute and relative corrections.
- It supports representation of complex multi-modal behaviors.
- Performance remains competitive with state-of-the-art methods under accurate data.
- Robustness increases substantially under noisy, relative, and partial feedback.
Where Pith is reading between the lines
- This set-based view could allow effective learning from fewer total corrections by tolerating ambiguity in each one.
- The same supervision change might improve other imitation methods that currently rely on point labels.
- Policies trained this way could show better real-world generalization when human input varies across sessions.
Load-bearing premise
Sets of desired actions constructed from human corrections reliably capture the intended behavior without systematic bias or inconsistency.
What would settle it
A controlled experiment where the true set of optimal actions is known in advance and a policy trained on constructed sets from simulated corrections fails to assign high probability to that true set.
Figures













read the original abstract
Behavior cloning (BC) optimizes policies by treating human demonstrations as pointwise action labels. While effective with accurate action labels, this formulation is brittle in practice: when human-provided actions are imperfect, treating each label as an exact target can steer the policy away from the underlying desired behavior, particularly when expressive models are used (e.g., energy-based models). As a result, we propose a human-in-the-loop alternative that replaces pointwise supervision with set-valued action targets. We introduce Contrastive policy Learning from Interactive Corrections (CLIC). CLIC leverages human corrections to construct and refine sets of desired actions, and optimizes a policy to place probability mass over these sets rather than over a single action target. This formulation naturally accommodates both absolute and relative corrections and can represent complex multi-modal behaviors. Extensive simulation and real-robot experiments show that the proposed approach leads to effective policy learning across diverse settings: CLIC remains competitive with the state of the art under accurate data while being substantially more robust under noisy, relative, and partial feedback. Our implementation is publicly available at https://clic-webpage.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Contrastive policy Learning from Interactive Corrections (CLIC) as an alternative to standard behavior cloning. Instead of optimizing policies toward pointwise action labels from demonstrations, CLIC uses human corrections to construct and refine sets of desired actions and trains the policy to place probability mass over these sets. The approach is claimed to handle absolute and relative corrections, support multi-modal behaviors, and remain competitive with state-of-the-art methods on clean data while being more robust to noisy, relative, and partial feedback, as shown in simulation and real-robot experiments. The implementation is released publicly.
Significance. If the set-construction procedure from corrections proves reliable, the method could meaningfully improve robustness in human-in-the-loop imitation learning, particularly with expressive models prone to overfitting imperfect labels. The public code release and dual simulation/real-robot validation are positive attributes that support reproducibility and practical relevance.
minor comments (3)
- The abstract asserts competitive performance and robustness but does not name the specific baselines, metrics, or statistical tests used; §4 or §5 should include a concise table or paragraph summarizing these to allow immediate assessment of the experimental claims.
- The description of how correction sets are constructed and refined (mentioned in the abstract) would benefit from an explicit algorithmic listing or pseudocode early in §3 to clarify the mapping from absolute/relative/partial feedback to set elements.
- Figure captions and axis labels in the experimental results should explicitly state the number of trials or seeds used for each curve to support the robustness claims.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work, the recognition of its potential significance for robust human-in-the-loop imitation learning, and the recommendation for minor revision. The referee's description accurately reflects the core ideas of CLIC, including the shift from pointwise to set-valued supervision and the empirical validation across simulation and real-robot settings. No major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a new imitation learning formulation (CLIC) that replaces pointwise action labels with sets constructed from human corrections, optimizing policy probability mass over those sets. No equations, derivations, or self-citations are exhibited that reduce the central claim or any 'prediction' to a fitted input or prior result by construction. The set-construction step and loss are presented as independent of the target outcomes, with experiments asserted to validate performance on both clean and noisy data; the derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLIC leverages human corrections to construct and refine sets of desired actions, and optimizes a policy to place probability mass over these sets rather than over a single action target.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the desired action space ˆA(ar,ah) such that ... Inclusion of human action; exclusion of robot action
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Wavelet Policy: Imitation Learning in the Scale Domain with World Prior Memory
Wavelet Policy combines world prior memory from background images with wavelet-domain multi-scale action modeling via a single-encoder multiple-decoder architecture to improve long-horizon robotic imitation learning.
Reference graph
Works this paper leans on
-
[1]
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” inConf. on Robot Learn., pp. 158–168, PMLR, 2022
work page 2022
-
[2]
An algorithmic perspective on imitation learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters, et al., “An algorithmic perspective on imitation learning,”Found. Trends Robotics, vol. 7, no. 1-2, pp. 1–179, 2018
work page 2018
-
[3]
Re- cent advances in robot learning from demonstration,
H. Ravichandar, A. S. Polydoros, S. Chernova, and A. Billard, “Re- cent advances in robot learning from demonstration,”Annu. Review Control. Robotics, Auton. Syst., vol. 3, no. 1, pp. 297–330, 2020
work page 2020
-
[4]
A survey of imitation learning: Algorithms, recent developments, and challenges,
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi, “A survey of imitation learning: Algorithms, recent developments, and challenges,” IEEE Trans. on Cybern., 2024
work page 2024
-
[5]
A survey of communicating robot learning during human-robot in- teraction,
S. Habibian, A. A. Valdivia, L. H. Blumenschein, and D. P. Losey, “A survey of communicating robot learning during human-robot in- teraction,”The Int. J. Robotics Research, vol. 0, no. 0, p. 02783649241281369, 0
-
[6]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proc. Robotics: Sci. Syst. (RSS), 2023
work page 2023
-
[7]
Conditional energy- based models for implicit policies: The gap between theory and prac- tice,
D.-N. Ta, E. Cousineau, H. Zhao, and S. Feng, “Conditional energy- based models for implicit policies: The gap between theory and prac- tice,”arXiv preprint arXiv:2207.05824, 2022
-
[8]
Goal conditioned imitation learning using score-based diffusion policies,
M. Reuss, M. Li, X. Jia, and R. Lioutikov, “Goal conditioned imitation learning using score-based diffusion policies,” inRobotics: Sci. Syst., 2023
work page 2023
-
[9]
Fast and robust visuomotor riemannian flow matching policy,
H. Ding, N. Jaquier, J. Peters, and L. Rozo, “Fast and robust visuomotor riemannian flow matching policy,”arXiv preprint arXiv:2412.10855, 2024
-
[10]
Deep generative models in robotics: A survey on learning from multimodal demonstrations,
J. Urain, A. Mandlekar, Y . Du, M. Shafiullah, D. Xu, K. Fragkiadaki, G. Chalvatzaki, and J. Peters, “Deep generative models in robotics: A survey on learning from multimodal demonstrations,”arXiv preprint arXiv:2408.04380, 2024
-
[11]
Interactive imitation learning in robotics: A survey,
C. Celemin, R. P ´erez-Dattari, E. Chisari, G. Franzese, L. de Souza Rosa, R. Prakash, Z. Ajanovi ´c, M. Ferraz, A. Valada, J. Kober,et al., “Interactive imitation learning in robotics: A survey,”Found. Trends Robotics, vol. 10, no. 1-2, pp. 1–197, 2022
work page 2022
-
[12]
Reinforcement learning of motor skills using policy search and human corrective advice,
C. Celemin, G. Maeda, J. Ruiz-del Solar, J. Peters, and J. Kober, “Reinforcement learning of motor skills using policy search and human corrective advice,”The Int. J. Robotics Research, vol. 38, no. 14, pp. 1560–1580, 2019
work page 2019
-
[13]
Contin- uous control for high-dimensional state spaces: An interactive learning approach,
R. P ´erez-Dattari, C. Celemin, J. Ruiz-del Solar, and J. Kober, “Contin- uous control for high-dimensional state spaces: An interactive learning approach,” in2019 Int. Conf. on Robotics Autom. (ICRA), pp. 7611– 7617, IEEE, 2019
work page 2019
-
[14]
An interactive framework for learning continuous actions policies based on corrective feedback,
C. Celemin and J. Ruiz-del Solar, “An interactive framework for learning continuous actions policies based on corrective feedback,”J. Intell. & Robotic Syst., vol. 95, pp. 77–97, 2019
work page 2019
-
[15]
Implicit generation and modeling with energy based models,
Y . Du and I. Mordatch, “Implicit generation and modeling with energy based models,” inAdv. Neural Inf. Process. Syst., vol. 32, 2019
work page 2019
-
[16]
Towards tight convex relaxations for contact- rich manipulation,
B. P. Graesdal, S. Y . C. Chia, T. Marcucci, S. Morozov, A. Amice, P. A. Parrilo, and R. Tedrake, “Towards tight convex relaxations for contact- rich manipulation,” inProc. Robotics: Sci. Syst. (RSS), 2024
work page 2024
-
[17]
Y . Song and D. P. Kingma, “How to train your energy-based models,” arXiv preprint arXiv:2101.03288, 2021
-
[18]
Deep unsupervised learning using nonequilibrium thermodynamics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” inInt. Conf. on Mach. Learn., pp. 2256–2265, PMLR, 2015
work page 2015
-
[19]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdv. Neural Inf. Process. Syst., vol. 33, pp. 6840–6851, 2020
work page 2020
-
[20]
Score-based generative modeling through stochastic differ- ential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differ- ential equations,” inInt. Conf. on Learn. Represent., 2021
work page 2021
-
[21]
Energy-based contact planning under uncertainty for robot air hockey,
J. Jankowski, A. Maric, P. Liu, D. Tateo, J. Peters, and S. Calinon, “Energy-based contact planning under uncertainty for robot air hockey,” CoRR, 2024
work page 2024
-
[22]
Z. Zhang, J. Hong, A. M. S. Enayati, and H. Najjaran, “Using im- plicit behavior cloning and dynamic movement primitive to facilitate reinforcement learning for robot motion planning,”IEEE Trans. on Robotics, 2024
work page 2024
-
[23]
Iifl: Implicit interactive fleet learning from heterogeneous human supervisors,
G. Datta, R. Hoque, A. Gu, E. Solowjow, and K. Goldberg, “Iifl: Implicit interactive fleet learning from heterogeneous human supervisors,” in Conf. on Robot Learn., pp. 2340–2356, PMLR, 2023
work page 2023
-
[24]
Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation,
S.-W. Lee and Y .-L. Kuo, “Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation,”arXiv preprint arXiv:2410.14868, 2024
-
[25]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” inAdv. Neu- ral Inf. Process. Syst., vol. 30, 2017
work page 2017
-
[26]
Learning preferences for manipulation tasks from online coactive feedback,
A. Jain, S. Sharma, T. Joachims, and A. Saxena, “Learning preferences for manipulation tasks from online coactive feedback,”The Int. J. Robotics Research, vol. 34, no. 10, pp. 1296–1313, 2015
work page 2015
-
[27]
K. Lee, L. M. Smith, and P. Abbeel, “Pebble: Feedback-efficient interac- tive reinforcement learning via relabeling experience and unsupervised pre-training,” inInt. Conf. on Mach. Learn., pp. 6152–6163, PMLR, 2021
work page 2021
-
[28]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Rad- ford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” inAdv. Neural Inf. Process. Syst., vol. 33, pp. 3008–3021, 2020
work page 2020
-
[29]
Trajectory improvement and reward learning from comparative language feedback,
Z. Yang, M. Jun, J. Tien, S. Russell, A. Dragan, and E. Biyik, “Trajectory improvement and reward learning from comparative language feedback,” in8th Annu. Conf. on Robot Learn., 2024
work page 2024
-
[30]
Contrastive preference learning: Learning from human feedback without reinforcement learning,
J. Hejna, R. Rafailov, H. Sikchi, C. Finn, S. Niekum, W. B. Knox, and D. Sadigh, “Contrastive preference learning: Learning from human feedback without reinforcement learning,” inThe Twelfth Int. Conf. on Learn. Represent., 2024
work page 2024
-
[31]
Calibrating sequence likelihood improves conditional language generation,
Y . Zhao, M. Khalman, R. Joshi, S. Narayan, M. Saleh, and P. J. Liu, “Calibrating sequence likelihood improves conditional language generation,” inThe Eleventh Int. Conf. on Learn. Represent., 2022
work page 2022
-
[32]
Direct preference optimization: Your language model is secretly a reward model,
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn, “Direct preference optimization: Your language model is secretly a reward model,” inAdv. Neural Inf. Process. Syst., vol. 36, 2024
work page 2024
-
[33]
Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations,
D. Brown, W. Goo, P. Nagarajan, and S. Niekum, “Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations,” inInt. Conf. on Mach. Learn., pp. 783–792, PMLR, 2019
work page 2019
-
[34]
Batch active learning of reward functions from human preferences,
E. Biyik, N. Anari, and D. Sadigh, “Batch active learning of reward functions from human preferences,”ACM Trans. on Human-Robot Interact., vol. 13, no. 2, pp. 1–27, 2024
work page 2024
-
[35]
Hindsight PRIORs for reward learning from human preferences,
M. Verma and K. Metcalf, “Hindsight PRIORs for reward learning from human preferences,” inThe Twelfth Int. Conf. on Learn. Represent., 2024
work page 2024
-
[36]
Learning robot objectives from physical human interaction,
A. Bajcsy, D. P. Losey, M. K. O’malley, and A. D. Dragan, “Learning robot objectives from physical human interaction,” inConf. on Robot Learn., pp. 217–226, PMLR, 2017
work page 2017
-
[37]
Including uncertainty when learning from human corrections,
D. P. Losey and M. K. O’Malley, “Including uncertainty when learning from human corrections,” inConf. on Robot Learn., pp. 123–132, PMLR, 2018
work page 2018
-
[38]
Learning from human directional corrections,
W. Jin, T. D. Murphey, Z. Lu, and S. Mou, “Learning from human directional corrections,”IEEE Trans. on Robotics, vol. 39, no. 1, pp. 625–644, 2022
work page 2022
-
[39]
Interactive learning with corrective feedback for policies based on deep neural networks,
R. P ´erez-Dattari, C. Celemin, J. Ruiz-del Solar, and J. Kober, “Interactive learning with corrective feedback for policies based on deep neural networks,” inProc. 2018 Int. Symp. on Exp. Robotics, pp. 353–363, Springer, 2020
work page 2018
-
[40]
I. Lopez Bosque, “Towards corrective deep imitation learning in data intensive environments: Helping robots to learn faster by leveraging human knowledge,” master’s thesis, Delft University of Technology, Nov. 2021
work page 2021
-
[41]
Interactive imitation learning in 18 state-space,
S. Jauhri, C. Celemin, and J. Kober, “Interactive imitation learning in 18 state-space,” inConf. on Robot Learn., pp. 682–692, PMLR, 2021
work page 2021
-
[42]
Learning from active human involvement through proxy value propagation,
Z. Peng, W. Mo, C. Duan, Q. Li, and B. Zhou, “Learning from active human involvement through proxy value propagation,” inAdv. Neural Inf. Process. Syst., 2023
work page 2023
-
[43]
Reinforcement learning with deep energy-based policies,
T. Haarnoja, H. Tang, P. Abbeel, and S. Levine, “Reinforcement learning with deep energy-based policies,” inInt. Conf. on Mach. Learn., pp. 1352–1361, PMLR, 2017
work page 2017
-
[44]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inInt. Conf. on Mach. Learn., pp. 1861–1870, PMLR, 2018
work page 2018
-
[45]
Aligning human intent from imperfect demonstrations with confidence-based inverse soft-q learning,
X. Bu, W. Li, Z. Liu, Z. Ma, and P. Huang, “Aligning human intent from imperfect demonstrations with confidence-based inverse soft-q learning,” IEEE Robotics Autom. Lett., 2024
work page 2024
-
[46]
Bayesian reparameteri- zation of reward-conditioned reinforcement learning with energy-based models,
W. Ding, T. Che, D. Zhao, and M. Pavone, “Bayesian reparameteri- zation of reward-conditioned reinforcement learning with energy-based models,” inInt. Conf. on Mach. Learn., pp. 8053–8066, PMLR, 2023
work page 2023
-
[47]
Inverse preference learning: Preference-based rl without a reward function,
J. Hejna and D. Sadigh, “Inverse preference learning: Preference-based rl without a reward function,” inAdv. Neural Inf. Process. Syst., vol. 36, 2024
work page 2024
-
[48]
Learning from interventions: Human-robot interaction as both explicit and implicit feedback,
J. Spencer, S. Choudhury, M. Barnes, M. Schmittle, M. Chiang, P. Ra- madge, and S. Srinivasa, “Learning from interventions: Human-robot interaction as both explicit and implicit feedback,” in16th Robotics: Sci. Syst. RSS 2020, MIT Press Journals, 2020
work page 2020
-
[49]
Flow contrastive estimation of energy-based models,
R. Gao, E. Nijkamp, D. P. Kingma, Z. Xu, A. M. Dai, and Y . N. Wu, “Flow contrastive estimation of energy-based models,” inProc. IEEE/CVF Conf. on Comput. Vis. Pattern Recognit., pp. 7518– 7528, 2020
work page 2020
-
[50]
Hard negative mixing for contrastive learning,
Y . Kalantidis, M. B. Sariyildiz, N. Pion, P. Weinzaepfel, and D. Larlus, “Hard negative mixing for contrastive learning,” inAdv. Neural Inf. Process. Syst., vol. 33, pp. 21798–21809, 2020
work page 2020
-
[51]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[52]
S. Singh, S. Tu, and V . Sindhwani, “Revisiting energy based models as policies: Ranking noise contrastive estimation and interpolating energy models,”Trans. on Mach. Learn. Research, 2024
work page 2024
-
[53]
A reduction of imitation learn- ing and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learn- ing and structured prediction to no-regret online learning,” inProc. Fourteenth Int. Conf. on Artif. Intell. Stat., pp. 627–635, JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[54]
Hg- dagger: Interactive imitation learning with human experts,
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer, “Hg- dagger: Interactive imitation learning with human experts,” in2019 Int. Conf. on Robotics Autom. (ICRA), pp. 8077–8083, IEEE, 2019
work page 2019
-
[55]
Ambient diffusion: Learning clean distributions from corrupted data,
G. Daras, K. Shah, Y . Dagan, A. Gollakota, A. Dimakis, and A. Klivans, “Ambient diffusion: Learning clean distributions from corrupted data,” Adv. Neural Inf. Process. Syst., vol. 36, pp. 288–313, 2023
work page 2023
-
[56]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, S. Nasiriany, and Y . Zhu, “robosuite: A modular simulation framework and benchmark for robot learning,” inarXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[57]
R. P ´erez-Dattari, C. Celemin, G. Franzese, J. Ruiz-del Solar, and J. Kober, “Interactive learning of temporal features for control: Shap- ing policies and state representations from human feedback,”IEEE Robotics & Autom. Mag., vol. 27, no. 2, pp. 46–54, 2020
work page 2020
-
[58]
Bayesian learning via stochastic gradient langevin dynamics,
M. Welling and Y . W. Teh, “Bayesian learning via stochastic gradient langevin dynamics,” inProc. 28th Int. Conf. on Mach. Learn. (ICML-11), pp. 681–688, Citeseer, 2011
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.