Learning Bayesian Game Families, with Application to Mechanism Design
Pith reviewed 2026-05-23 02:12 UTC · model grok-4.3
The pith
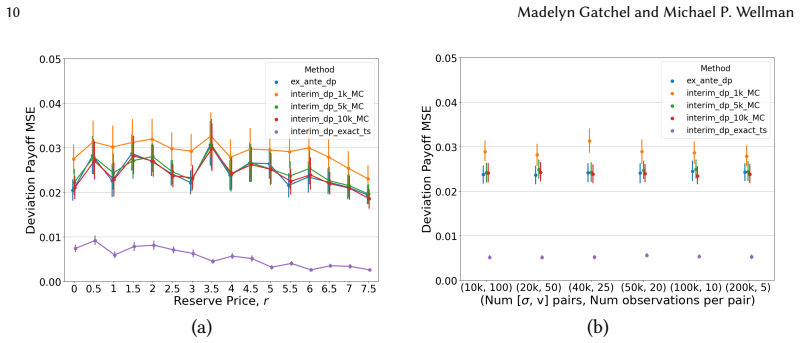
An interim model for Bayesian game families matches ex ante learning on trained data but outperforms it on new mechanism parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By learning an interim game-family model conditioned on one player's type, the method obtains ex ante payoff predictions through marginalization that match direct ex ante learning within the trained range of mechanism parameters and surpass it in extrapolation, while also enabling computation of piecewise best-response strategies without additional data.
What carries the argument
The interim game-family model conditioned on a single player's type, which marginalizes to produce ex ante payoffs.
Load-bearing premise
The family of games must be parametrically related so that one interim-stage model conditioned on a single player's type can capture the structure and support accurate marginalization to ex ante payoffs.
What would settle it
A parametric game family in which the interim model's extrapolated Nash-approximation error exceeds that of a directly learned ex ante model would falsify the claimed performance advantage.
Figures










read the original abstract
Learning or estimating game models from data typically entails inducing separate models for each setting, even if the games are parametrically related. In empirical mechanism design, for example, this approach requires learning a new game model for each candidate setting of the mechanism parameter. Recent work has shown the data efficiency benefits of learning a single parameterized model for families of related games. In Bayesian games -- a typical model for mechanism design -- payoffs depend on both the actions and types of the players. We show how to exploit this structure by learning an interim game-family model that conditions on a single player's type. We compare this to the baseline approach of directly learning the ex ante payoff function, which gives payoffs in expectation of all player types. By marginalizing over player type, the interim model can also provide ex ante payoff predictions, as necessary for Bayes-Nash equilibrium approximation. We also leverage the interim model to compute new beneficial piecewise best-response strategies, without any additional sample data. We validate our method through a case study of a dynamic sponsored search auction. For both payoff accuracy and Nash-approximation error, the interim model matches the ex ante model on the trained range, and outperforms ex ante in extrapolation. Our case study demonstrates that Bayesian game-family models can support comprehensive mechanism design, and that through interim-stage modeling we can enhance expressivity and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes learning an interim game-family model for Bayesian games by conditioning on a single player's type, which can be marginalized over types to recover ex ante payoffs for Bayes-Nash equilibrium approximation. This is contrasted with directly learning the ex ante payoff function. In a case study on dynamic sponsored search auctions, the interim model is reported to match the ex ante model on the training range while outperforming it on extrapolation for both payoff prediction error and Nash-approximation error; the interim model is additionally used to derive new piecewise best-response strategies without extra samples.
Significance. If the empirical comparison holds under the reported protocol, the work demonstrates a structurally motivated way to improve data efficiency and extrapolation when learning parameterized families of Bayesian games, with direct relevance to empirical mechanism design. The explicit construction of the interim model to exploit type dependence, followed by marginalization, is a clear strength.
major comments (1)
- The central empirical claim (interim model matches on training range and outperforms in extrapolation for payoff accuracy and Bayes-Nash error) is presented without any description of experimental design, sample sizes, training procedures, or statistical tests in the provided text. This prevents evaluation of whether the reported superiority is load-bearing or reproducible.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the significance of our work. We address the major comment below and will incorporate the requested details into a revised manuscript.
read point-by-point responses
-
Referee: The central empirical claim (interim model matches on training range and outperforms in extrapolation for payoff accuracy and Bayes-Nash error) is presented without any description of experimental design, sample sizes, training procedures, or statistical tests in the provided text. This prevents evaluation of whether the reported superiority is load-bearing or reproducible.
Authors: We agree that the manuscript requires a more detailed account of the experimental protocol to support reproducibility and evaluation of the empirical results. In the revised version we will add a dedicated experimental section that specifies: the total number of samples collected and how they were partitioned into training, validation, and test sets; the precise training procedures and hyper-parameters used for both the interim and ex-ante models; the ranges of mechanism parameters over which training and extrapolation were performed; and the statistical metrics and any hypothesis tests employed to compare payoff prediction error and Nash-approximation error. These additions will make the central claims fully evaluable. revision: yes
Circularity Check
Empirical comparison; no load-bearing circularity in derivation
full rationale
The paper's core contribution is an empirical case study in dynamic sponsored search comparing an interim-stage Bayesian game-family model (conditioned on one player's type) against a direct ex ante payoff model. Claims of matching accuracy on the trained range and superior extrapolation rest on reported experimental metrics for payoff error and Bayes-Nash approximation error after marginalization; these are data-driven outcomes, not quantities forced by construction from fitted parameters or self-citations. The modeling choice to exploit type dependence is stated explicitly as a design decision enabling marginalization, without any equation reducing to its own input. No uniqueness theorems, ansatzes smuggled via citation, or renamed known results appear in the provided abstract or reader summary. Minor self-citation (if present) is not load-bearing for the central empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
American Economic Review 97, 1 (2007), 242–259
Internet Advertising and the Generalized Second-Price Auction: Selling Billions of Dollars Worth of Keywords. American Economic Review 97, 1 (2007), 242–259. Learning Bayesian Game Families, with Application to Mechanism Design 19 Sevan G. Ficici, David C. Parkes, and Avi Pfeffer
work page 2007
-
[2]
Scientific Reports 12, 1 (2022), 16937
Designing All-Pay Auctions Using Deep Learning and Multi-Agent Simulation. Scientific Reports 12, 1 (2022), 16937. Patrick R. Jordan, Michael P. Wellman, and Guha Balakrishnan
work page 2022
-
[3]
Mathematical Biosciences 40, 1 (1978), 145–156
Evolutionary Stable Strategies and Game Dynamics. Mathematical Biosciences 40, 1 (1978), 145–156. David R. M. Thompson and Kevin Leyton-Brown
work page 1978
-
[4]
Games and Economic Behavior 102 (2017), 583–623
Computational Analysis of Perfect-Information Position Auctions. Games and Economic Behavior 102 (2017), 583–623. Hal R. Varian
work page 2017
-
[5]
International Journal of Industrial Organization 25, 6 (2007), 1163–1178
Position Auctions. International Journal of Industrial Organization 25, 6 (2007), 1163–1178. Yevgeniy Vorobeychik, Christopher Kiekintveld, and Michael P. Wellman
work page 2007
-
[6]
International Journal of Electronic Business 6, 2 (2008),
Equilibrium Analysis of Dynamic Bidding in Sponsored Search Auctions. International Journal of Electronic Business 6, 2 (2008),
work page 2008
-
[7]
Autonomous Agents and Multi-Agent Systems 25, 2 (2012), 313–351
Constrained Automated Mechanism Design for Infinite Games of Incomplete Information. Autonomous Agents and Multi-Agent Systems 25, 2 (2012), 313–351. Yevgeniy Vorobeychik, Michael P. Wellman, and Satinder Singh
work page 2012
- [8]
- [9]
-
[10]
Journal of Artificial Intelligence Research 82 (2025)
Empirical Game-Theoretic Analysis: A Survey. Journal of Artificial Intelligence Research 82 (2025). Bryce Wiedenbeck, Fengjun Yang, and Michael Wellman
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.