Extreme Value Analysis based on Blockwise Top-Two Order Statistics
Pith reviewed 2026-05-23 02:25 UTC · model grok-4.3
The pith
A bias-corrected estimator from blockwise top-two order statistics consistently estimates extreme-value parameters in time series and improves efficiency over standard block maxima methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The target parameters of the extreme-value distribution also appear in the limiting joint distribution of the top-two order statistics per block. Maximizing an independence log-likelihood based on these statistics produces an inconsistent estimator under typical time-series dependence, but an explicit bias correction yields a consistent estimator that is asymptotically more efficient than the classical block-maxima estimator for functionals such as high return levels.
What carries the argument
The bias-corrected maximum-likelihood estimator constructed from the joint limiting distribution of the blockwise top-two order statistics.
If this is right
- The estimator remains consistent for the extreme-value parameters under standard mixing conditions on the time series.
- It achieves lower asymptotic variance than the block-maxima estimator when estimating high quantiles or return periods.
- Finite-sample performance improves for moderate block sizes in both independent and dependent data.
- The method extends the classical block-maxima framework without requiring a change in block length or data collection.
Where Pith is reading between the lines
- The same correction idea might apply to the top three or top k order statistics per block for further variance reduction.
- Practitioners estimating return levels from annual maxima could reprocess existing data to extract the second-largest value and obtain tighter intervals.
- The approach could be combined with existing declustering techniques when dependence within blocks is strong.
Load-bearing premise
The joint limiting distribution of the top two order statistics within blocks must match the form implied by the extreme-value parameters under the dependence present in the time series.
What would settle it
A simulation study in which the proposed estimator fails to converge in probability to the true extreme-value parameters as the number of blocks grows, while the classical block-maxima estimator does converge, would falsify the consistency claim.
Figures











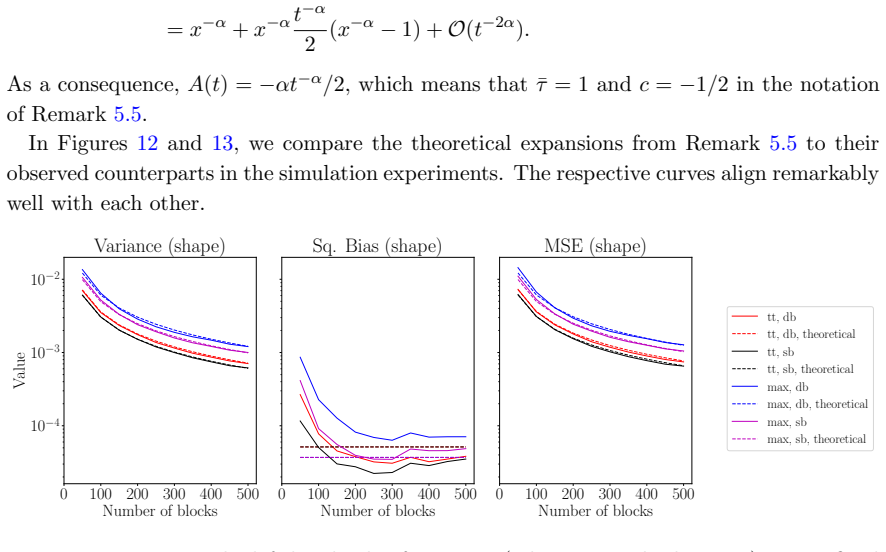








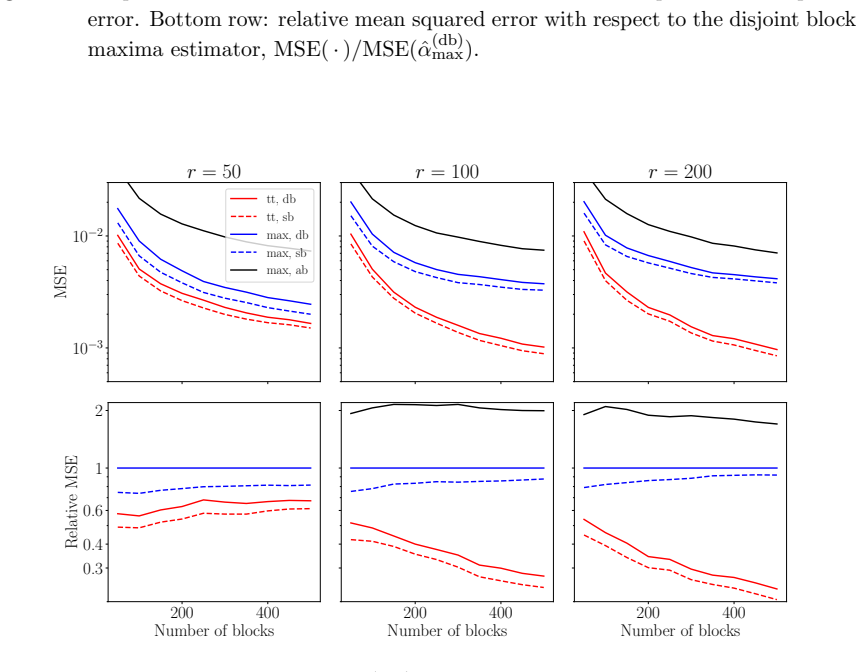





read the original abstract
Extreme value analysis for time series is often based on the block maxima method, in particular for environmental applications. In the classical univariate case, the latter is based on fitting an extreme-value distribution to the sample of (annual) block maxima. Mathematically, the target parameters of the extreme-value distribution also show up in limit results for other high order statistics, which suggests estimation based on blockwise large order statistics. It is shown that a naive approach based on maximizing an independence log-likelihood yields an estimator that is inconsistent in general. A consistent, bias-corrected estimator is proposed, and is analyzed theoretically and in finite-sample simulation studies. The new estimator is shown to be more efficient than traditional counterparts, for instance for estimating large return levels or return periods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using blockwise top-two order statistics for extreme value analysis of time series, rather than only block maxima. It shows that a naive estimator maximizing an independence log-likelihood is inconsistent in general, derives a bias correction from limit results for order statistics to obtain a consistent estimator, analyzes its theoretical properties, and demonstrates via finite-sample simulations that it is more efficient than standard block-maxima approaches for estimating large return levels and return periods.
Significance. If the joint limiting distribution assumption holds under the paper's dependence conditions, the bias-corrected estimator could improve efficiency by extracting additional information from the second-largest value per block without introducing extra parameters, offering a practical advance for environmental time-series applications where block maxima alone are inefficient.
major comments (2)
- [derivation of bias correction (following abstract claim on limit results for other high order statistics)] The consistency proof for the bias-corrected estimator requires that the joint asymptotic distribution of the top-two order statistics per block depends on the extreme-value parameters and known constants only, without residual unknown dependence features from the time series mixing or clustering structure. This is invoked via general limit results for high-order statistics but needs explicit verification that the correction formula restores consistency under the serial dependence assumed in the model; without this, the central claim that the estimator is consistent does not follow.
- [simulation studies] Simulation designs must be checked to ensure they do not inadvertently satisfy the joint tail dependence assumption used for the correction; if the data-generating processes used in §5 are such that the top-two joint limit matches the independence case or a specific form, the reported efficiency gains may not generalize to the broader class of dependent series where the naive estimator is inconsistent.
minor comments (2)
- [introduction and notation] Clarify notation for the blockwise top-two statistics (e.g., denote the second order statistic explicitly) to avoid ambiguity when referring to the joint distribution.
- [theoretical analysis] Add a reference or brief derivation sketch for the specific joint limit law of the top two under the mixing conditions used, even if citing a standard result.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the major comments point by point below.
read point-by-point responses
-
Referee: The consistency proof for the bias-corrected estimator requires that the joint asymptotic distribution of the top-two order statistics per block depends on the extreme-value parameters and known constants only, without residual unknown dependence features from the time series mixing or clustering structure. This is invoked via general limit results for high-order statistics but needs explicit verification that the correction formula restores consistency under the serial dependence assumed in the model; without this, the central claim that the estimator is consistent does not follow.
Authors: We appreciate this observation. Under the mixing and clustering conditions of the manuscript, the referenced general limit theorems for high-order statistics ensure the joint limiting distribution of the top-two per block is determined solely by the extreme-value parameters and the extremal index (a known model constant). The bias correction is derived directly from this distribution. To address the request for explicit verification, the revised manuscript will include an added remark in Section 3 (or a short appendix) confirming that the correction eliminates inconsistency without residual unknown dependence terms. revision: partial
-
Referee: Simulation designs must be checked to ensure they do not inadvertently satisfy the joint tail dependence assumption used for the correction; if the data-generating processes used in §5 are such that the top-two joint limit matches the independence case or a specific form, the reported efficiency gains may not generalize to the broader class of dependent series where the naive estimator is inconsistent.
Authors: We agree this verification is important. The DGPs in Section 5 are stationary dependent processes (with clustering) chosen precisely so that the naive independence-likelihood estimator is inconsistent, consistent with the theoretical results. The joint limits follow the general dependent form rather than independence. In the revision we will add a short confirmation (e.g., a table or paragraph) showing that the chosen DGPs produce inconsistency of the naive estimator, supporting generalizability of the reported efficiency gains. revision: yes
Circularity Check
No circularity: estimator derived from asymptotic limit theorems for order statistics
full rationale
The paper starts from known limit results in which EV parameters appear for high-order statistics, shows via direct argument that the independence-likelihood estimator is inconsistent under serial dependence, then constructs a bias correction whose form follows from those same limits. No step reduces the final estimator to a re-expression of fitted values, no load-bearing self-citation is invoked, and the consistency claim rests on external asymptotic theory rather than on the estimator itself. The derivation is therefore self-contained against the stated limit theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Limit theorems for high-order statistics in extreme value theory hold for the underlying time series and allow the extreme-value parameters to appear in the joint limiting distribution of the top two order statistics per block.
Reference graph
Works this paper leans on
-
[1]
[Bei+04] Beirlant, J. et al. Statistics of extremes . Wiley Series in Probability and Statis- tics. Theory and applications, With contributions from Daniel De Waal and Chris Ferro. John Wiley & Sons, Ltd., Chichester, 2004, pp. xiv+490. doi: 10.1002/0470012382. [BGT87] Bingham, N. H., Goldie, C. M., and Teugels, J. L. Regular variation. Vol
-
[2]
Encyclopedia of Mathematics and its Applications. Cambridge University Press, Cambridge, 1987, pp. xx+491. doi: 10.1017/CBO9780511721434. [BJ22] B¨ ucher, A. and Jennessen, T. “Statistical analysis for stationary time series at extreme levels: new estimators for the limiting cluster size distribution”. In: Stochastic Process. Appl. 149 (2022), pp. 75–106....
-
[3]
Maximum likelihood estimators based on the block maxima method
doi: 10.1214/23-AOS2260. [Col01] Coles, S. An introduction to statistical modeling of extreme values . Springer Se- ries in Statistics. Springer-Verlag London, Ltd., London, 2001, pp. xiv+208.doi: 10.1007/978-1-4471-3675-0 . [DF19] Dombry, C. and Ferreira, A. “Maximum likelihood estimators based on the block maxima method”. In: Bernoulli 25.3 (2019), pp. ...
-
[4]
doi: 10.1017/CBO9780511802843. 90 [Dom15] Dombry, C. “Existence and consistency of the maximum likelihood estimators for the extreme value index within the block maxima framework”. In: Bernoulli 21.1 (2015), pp. 420–436. doi: 10.3150/13-BEJ573. [Dou94] Doukhan, P. Mixing. Vol
-
[5]
Lecture Notes in Statistics. Properties and exam- ples. Springer-Verlag, New York, 1994, pp. xii+142.doi: 10.1007/978-1-4612- 2642-0. [DP02] Dehling, H. and Philipp, W. “Empirical Process Techniques for Dependent Data”. In: Empirical Process Techniques for Dependent Data. Ed. by H. Dehling, T. Mikosch, and M. Sørensen. Boston, MA: Birkh¨ auser Boston, 200...
-
[6]
On the block maxima method in extreme value theory: PWM estimators
[FH15] Ferreira, A. and Haan, L. de. “On the block maxima method in extreme value theory: PWM estimators”. In: Ann. Statist. 43.1 (2015), pp. 276–298. doi:
work page 2015
-
[7]
Sur la distribution limite du terme maximum d’une s´ erie al´ eatoire
1214/14-AOS1280. [Gne43] Gnedenko, B. “Sur la distribution limite du terme maximum d’une s´ erie al´ eatoire”. In: Ann. of Math. (2) 44 (1943), pp. 423–453. doi: 10.2307/1968974. [Hau25] Haufs, E. xtremes, a Python package containing auxiliary EVA functionalities . https://github.com/haufse/xtremes
-
[8]
On the extreme order statistics for a stationary sequence
[Hsi88] Hsing, T. “On the extreme order statistics for a stationary sequence”. In: Stochas- tic Process. Appl. 29.1 (1988), pp. 155–169. doi: 10 . 1016 / 0304 - 4149(88 ) 90035-X. [Hsi91] Hsing, T. “Estimating the parameters of rare events”. In: Stochastic Process. Appl. 37.1 (1991), pp. 117–139. doi: 10.1016/0304-4149(91)90064-J. [HWW85] Hosking, J. R. M...
-
[9]
All Block Maxima method for estimating the extreme value index
arXiv: 2010.15950 [math.ST]. 91 [PW80] Prescott, P. and Walden, A. T. “Maximum likelihood estimation of the param- eters of the generalized extreme-value distribution”. In: Biometrika 67.3 (1980), pp. 723–724. doi: 10.1093/biomet/67.3.723. [RD02] Ramesh, N. and Davison, A. “Local models for exploratory analysis of hydro- logical extremes”. In: Journal of ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/biomet/67.3.723 2010
-
[10]
Applied Probability. A Series of the Applied Probability Trust. Springer-Verlag, New York, 1987, pp. xii+320. doi: 10.1007/978-0-387-75953-1 . [Rob09a] Robert, C. Y. “Asymptotic distributions for the intervals estimators of the ex- tremal index and the cluster-size probabilities”. In: J. Statist. Plann. Inference 139.9 (2009), pp. 3288–3309. doi: 10.1016/...
-
[11]
Estimation of parameters and large quantiles based on the k largest observations
Cambridge Series in Statis- tical and Probabilistic Mathematics. Cambridge University Press, Cambridge, 1998, pp. xvi+443. doi: 10.1017/CBO9780511802256. [Wei78] Weissman, I. “Estimation of parameters and large quantiles based on the k largest observations”. In: J. Amer. Statist. Assoc. 73.364 (1978), pp. 812–815. doi: 10.2307/2286285. [Wel72] Welsch, R. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.