Prior shift estimation for positive unlabeled data through the lens of kernel embedding
Pith reviewed 2026-05-23 01:39 UTC · model grok-4.3
The pith
A direct kernel-embedding estimator recovers the class prior in positive-unlabeled data with prior shift by solving an explicit distribution-matching optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The class prior is recovered directly as the explicit solution to a distribution-matching optimization that aligns kernel embeddings of the positive and mixed source samples with the target sample; the resulting estimator is asymptotically consistent and admits an explicit non-asymptotic bound on its deviation from the unknown prior that can be evaluated in practice.
What carries the argument
Kernel embedding distribution matching in a reproducing kernel Hilbert space, which converts the prior-recovery task into an explicit convex optimization whose solution is the estimated mixing proportion.
If this is right
- The estimator converges to the true prior as the number of samples increases.
- A non-asymptotic, computable bound on the estimation error is available without further modeling.
- The estimator exhibits a simple geometric interpretation based on distances between embedded distributions.
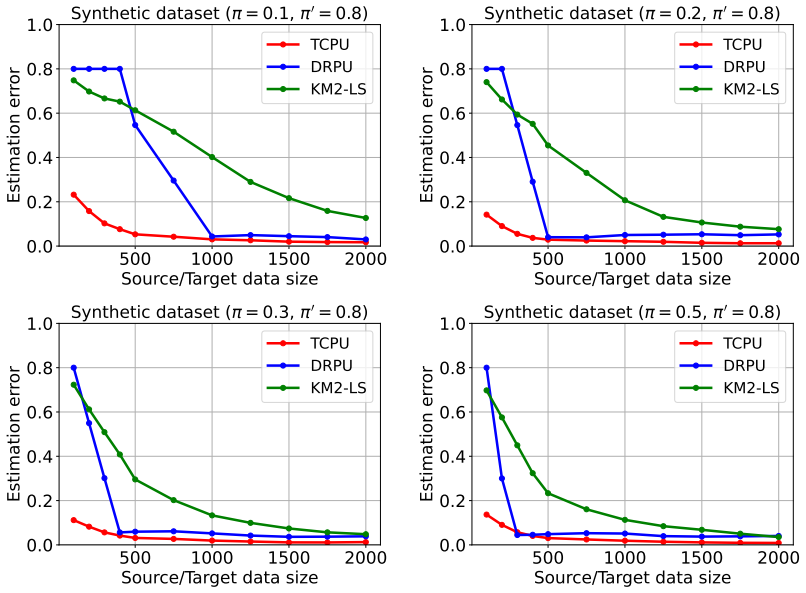
- On both synthetic and real data the method matches or exceeds the accuracy of existing competitors while avoiding posterior estimation.
Where Pith is reading between the lines
- The geometric formulation may allow the same matching idea to be applied to other forms of label shift without redesigning the loss.
- Because the estimator is explicit, it can be plugged into existing positive-unlabeled algorithms as a drop-in prior without retraining auxiliary models.
- The finite-sample bound supplies a practical way to decide how much target data is needed before the prior estimate is reliable enough for downstream use.
Load-bearing premise
The optimization problem that aligns the kernel embeddings has a unique solution that equals the unknown class prior.
What would settle it
In large samples the estimator systematically deviates from the true prior even though the kernel embeddings of the positive, mixed, and target distributions are accurately estimated.
Figures








read the original abstract
We study estimation of a class prior for unlabeled target samples which possibly differs from that of source population. Moreover, it is assumed that the source data is partially observable: only samples from the positive class and from the whole population are available (PU learning scenario). We introduce a novel direct estimator of a class prior which avoids estimation of posterior probabilities in both populations and has a simple geometric interpretation. It is based on a distribution matching technique together with kernel embedding in a Reproducing Kernel Hilbert Space and is obtained as an explicit solution to an optimisation task. We establish its asymptotic consistency as well as an explicit non-asymptotic bound on its deviation from the unknown prior, which is calculable in practice. We study finite sample behaviour for synthetic and real data and show that the proposal works consistently on par or better than its competitors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a novel direct estimator for the class prior in positive-unlabeled (PU) data under possible prior shift. The estimator is derived from distribution matching via kernel embeddings in an RKHS, obtained as an explicit solution to an optimization task. It avoids posterior probability estimation in both populations, admits a geometric interpretation, and the authors claim asymptotic consistency together with an explicit non-asymptotic deviation bound that is calculable in practice. Finite-sample performance is reported to be competitive with existing methods on synthetic and real data.
Significance. If the central claims are substantiated, the work would supply a direct, geometrically interpretable alternative to posterior-based prior estimators in PU learning and label-shift settings. The combination of an explicit optimization solution with a practical non-asymptotic bound would be a useful theoretical and computational contribution to kernel methods for distribution matching.
major comments (1)
- [Abstract] Abstract: the claims of asymptotic consistency, an explicit non-asymptotic bound calculable in practice, and that the optimization yields the class prior without posterior estimation or biasing modeling choices are load-bearing for the central contribution, yet the full derivations, proofs, assumptions, and experimental details are not available in the provided text, preventing verification of soundness or the weakest assumption identified in the reader report.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the importance of verifying the central claims. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of asymptotic consistency, an explicit non-asymptotic bound calculable in practice, and that the optimization yields the class prior without posterior estimation or biasing modeling choices are load-bearing for the central contribution, yet the full derivations, proofs, assumptions, and experimental details are not available in the provided text, preventing verification of soundness or the weakest assumption identified in the reader report.
Authors: The provided excerpt in this review contains only the abstract. The full manuscript (arXiv:2502.21194) contains the complete derivations, proofs under the stated assumptions (including RKHS properties and kernel choice), the explicit non-asymptotic deviation bound, and all experimental details. The estimator is obtained as the closed-form solution to the distribution-matching objective in the RKHS, which directly yields the prior without requiring posterior estimation in either population. We are happy to supply specific proof excerpts or additional clarification if the referee wishes to examine particular steps. revision: no
Circularity Check
No circularity detected from abstract
full rationale
The abstract presents the estimator as an explicit solution to an optimization task using kernel embedding and distribution matching, with separate claims of asymptotic consistency and a calculable non-asymptotic bound. No equations, self-citations, fitted parameters renamed as predictions, or self-referential definitions are visible in the provided text. The derivation chain cannot be walked beyond the abstract, so no load-bearing step reduces to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the 32th AAAI Conference on Artificial Intelligence
Bekker, J., Davis, J.: Estimating the class prior in positive and unlabeled data through decision tree induction. In: Proceedings of the 32th AAAI Conference on Artificial Intelligence. pp. 1–8 (2018)
work page 2018
-
[2]
Machine Learning 109, 719–760 (2020)
Bekker, J., Davis, J.: Learning from positive and unlabeled data: a survey. Machine Learning 109, 719–760 (2020)
work page 2020
-
[3]
Journal of Machine Learn- ing Research11, 2973–3009 (2010)
Blanchard, G., Lee, G., Scott, C.: Semi-supervised novelty detection. Journal of Machine Learn- ing Research11, 2973–3009 (2010)
work page 2010
-
[4]
In: Proceedings of the 37th International Conference on Machine Learning
Chen, X., Chen, W., Chen, T., Yuan, Y., Gong, C., Chen, K., Wang, Z.: Self-PU: Self boosted and calibrated positive-unlabeled training. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20 (2020)
work page 2020
-
[5]
In: Proceedings of the European Conferencce on Machine Learning (2023)
Dussap, B., Blanchard, G., Ch´ erif-Abdellatif, B.E.: Label shift quantification with robustness guarantees via distribution feature matching. In: Proceedings of the European Conferencce on Machine Learning (2023)
work page 2023
-
[6]
Elkan, C., Noto, K.: Learning classifiers from only positive and unlabeled data. In: Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 213–220. KDD ’08 (2008)
work page 2008
-
[7]
Data Mining and Knowledge Dis- covery17, 164–206 (2008)
Forman, G.: Quantifying counts and costs via classification. Data Mining and Knowledge Dis- covery17, 164–206 (2008)
work page 2008
-
[8]
In: Advances in Neural Information Processing Systems
Fukumizu, K., Gretton, A., Sun, X., Sch¨ olkopf, B.: Kernel measures of conditional dependence. In: Advances in Neural Information Processing Systems. vol. 20 (2007)
work page 2007
-
[9]
IEEE Transactions on Knowledge and Data Engineering18(1), 6–20 (2006)
Fung, G.P.C., Yu, J.X., Lu, H., Yu, P.S.: Text classification without negative examples revisit. IEEE Transactions on Knowledge and Data Engineering18(1), 6–20 (2006)
work page 2006
-
[10]
In: Proceedings of the 34th International Conference on Neural Information Processing Systems
Garg, S., Wu, Y., Balakrishnan, S., Lipton, Z.C.: A unified view of label shift estimation. In: Proceedings of the 34th International Conference on Neural Information Processing Systems. pp. 1–11. NIPS’ 20 (2020)
work page 2020
-
[11]
IEEE Trans Pattern Anal Mach Intell pp
Gong, C., Wang, Q., Liu, T., Han, B., You, J., Yang, J., Tao, D.: Instance-dependent positive and unlabeled learning with labeling bias estimation. IEEE Trans Pattern Anal Mach Intell pp. 1–16 (2021)
work page 2021
-
[12]
Gonz´ alez, P., Casta˜ no, A., Chawla, N., Coz, J.: A review on quantification learning. ACM Comput. Surv.50(5) (2017)
work page 2017
-
[13]
Journal of Machine Learning Research13, 723–773 (2012)
Gretton, A., Borgwardt, K., Rasch, M., Sch¨ olkopf, B., Smola, A.: A kernel two-sample test. Journal of Machine Learning Research13, 723–773 (2012)
work page 2012
-
[14]
In: Proceedings of the 31th International Conferencce on Machine Learning
Iyer, A., Nath, S., Sarawagi, S.: Maximum mean discrepancy for class ratio estimation: con- vergence bounds and kernel selection. In: Proceedings of the 31th International Conferencce on Machine Learning. IMLR W & CP vol. 32 (2014)
work page 2014
-
[15]
In: Proceedings of the 30th International Conference on Neural Information Processing Systems
Jain, S., White, M., Radivojac, P.: Estimating the class prior and posterior from noisy positives and unlabeled data. In: Proceedings of the 30th International Conference on Neural Information Processing Systems. p. 2693–2701 (2016) 23
work page 2016
-
[16]
In: Proceedings of the International Conference on Neural Information Processing Systems
Kiryo, R., Niu, G., du Plessis, M.C., Sugiyama, M.: Positive-unlabeled learning with non- negative risk estimator. In: Proceedings of the International Conference on Neural Information Processing Systems. pp. 1674–1684. NIPS’17 (2017)
work page 2017
-
[17]
Briefings in Bioinformatics23(1) (2021)
Li, F., Dong, S., Leier, A., Han, M., Guo, X., Xu, J., Wang, X., Pan, S., Jia, C., Zhang, Y., Webb, G., Coin, L.J.M., Li, C., Song, J.: Positive-unlabeled learning in bioinformatics and computational biology: a brief review. Briefings in Bioinformatics23(1) (2021)
work page 2021
-
[18]
In: Proceedings of the 18th International Joint Conference on Artificial Intelligence
Li, X., Liu, B.: Learning to classify texts using positive and unlabeled data. In: Proceedings of the 18th International Joint Conference on Artificial Intelligence. p. 587–592. IJCAI’03 (2003)
work page 2003
-
[19]
In: Proceedings of the 35th International Conference on Machine Learning
Lipton, Z.C., Wang, Y., Smola, A.J.: Detecting and correcting for label shift with black box predictors. In: Proceedings of the 35th International Conference on Machine Learning. pp. 3128–3136. ICML’ 18 (2018)
work page 2018
-
[20]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Luo, C., Zhao, P., Chen, C., Qiao, B., Du, C., Zhang, H., Wu, W., Cai, S., He, B., Rajmohan, S., Lin, Q.: Pulns: Positive-unlabeled learning with effective negative sample selector. In: Proceedings of the AAAI Conference on Artificial Intelligence. AAAI’21, vol. 35, pp. 8784–8792 (2021)
work page 2021
-
[21]
Mc Diarmid, C.: On the method of bounded differences. Survey in Combinatorics pp. 148–188 (1989)
work page 1989
-
[22]
Fundamenta Informaticae191, 1–17 (2024)
Mielniczuk, J., Wawrze´ nczyk, A.: Single-sample versus case-control sampling scheme for Posi- tive Unlabeled data: the story of two scenarios. Fundamenta Informaticae191, 1–17 (2024)
work page 2024
-
[23]
Machine Learning112, 889–919 (2023)
Nakajima, S., Siguyama, M.: Positive-unlabeled classification under class-prior shift: a prior- invariant approach based on density ratio estimation. Machine Learning112, 889–919 (2023)
work page 2023
-
[24]
In: Advances in Neural Information Processing Systems
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: Pytorch: An imperative style, high-performance deep learning library. In: Advances in Neural Informat...
work page 2019
-
[25]
In: Proceedings of the International Conference on Neural Information Processing Systems
du Plessis, M.C., Niu, G., Sugiyama, M.: Analysis of learning from positive and unlabeled data. In: Proceedings of the International Conference on Neural Information Processing Systems. pp. 703–711. NIPS’14 (2014)
work page 2014
-
[26]
In: Proceedings of The 33rd International Conference on Machine Learning
Ramaswamy, H., Scott, C., Tewari, A.: Mixture proportion estimation via kernel embeddings of distributions. In: Proceedings of The 33rd International Conference on Machine Learning. vol. 48, pp. 2052–2060 (2016)
work page 2052
-
[27]
Journal of Medical Systems46(5), 1–12 (2022)
Roland, T., Bock, C., Tschoellitsch, T., Maletzky, A., Hochreiter, S., Meier, J., Klambauer, G.: Domain shifts in machine learning based covid-19 diagnosis from blood tests. Journal of Medical Systems46(5), 1–12 (2022)
work page 2022
-
[28]
Neural Comput.14(1), 21–41 (2002)
Saerens, M., Latinne, P., Decaestecker, C.: Adjusting the outputs of a classifier to new a priori probabilities: a simple procedure. Neural Comput.14(1), 21–41 (2002)
work page 2002
-
[29]
International Journal of Approximate Reasoning 85, 159 – 177 (2017) 24
Sechidis, K., Sperrin, M., Petherick, E.S., Luj´ an, M., Brown, G.: Dealing with under-reported variables: An information theoretic solution. International Journal of Approximate Reasoning 85, 159 – 177 (2017) 24
work page 2017
-
[30]
Journal of Machine Learning Research18(86), 1–47 (2017)
Tolstikhin, I., Sriperumbudur, B.K., Muandet, K.: Minimax estimation of kernel mean embed- dings. Journal of Machine Learning Research18(86), 1–47 (2017)
work page 2017
-
[31]
Journal of Machine Learning Research20, 1–33 (2019)
Vaz, A., Izbicki, R., Stern, R.: Quantification under prior probability shift: the ratio estimator and its extensions. Journal of Machine Learning Research20, 1–33 (2019)
work page 2019
-
[32]
In: Proceedings of the 30th International Conferencce on Machine Learning (2014)
Zhang, K., Sch¨ olkopf, B., Muandet, K., Wang, Z.: Domain adaptation under target and condi- tional shift. In: Proceedings of the 30th International Conferencce on Machine Learning (2014)
work page 2014
-
[33]
Zhang, Z., Sabuncu, M.: Generalizec cross entropy loss for training neural networks with noisy labels. In: NIPS’18. pp. 8792 – 8802 (2018)
work page 2018
-
[34]
In: Proceedings of the Conference on Computer Vision and Pattern Recognition
Zhao, Y., Xu, Q., Jiang, Y., Wen, P., Huang, Q.: Dist-pu: Positive-unlabeled learning from a label distribution perspective. In: Proceedings of the Conference on Computer Vision and Pattern Recognition. pp. 14461–14470. CVPR’22 (2022) 25 Supplementary material 1 Additional theoretical results Lemma 4.Suppose thatM= sup x K(x, x)<∞andδ≤exp(−( √ 2 + 1)2/2)i...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.