What's DAT? Three Case Studies of Measuring Software Development Productivity at Meta With Diff Authoring Time
Pith reviewed 2026-05-23 00:48 UTC · model grok-4.3
The pith
DAT measures how long engineers take to author code changes with integrated telemetry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
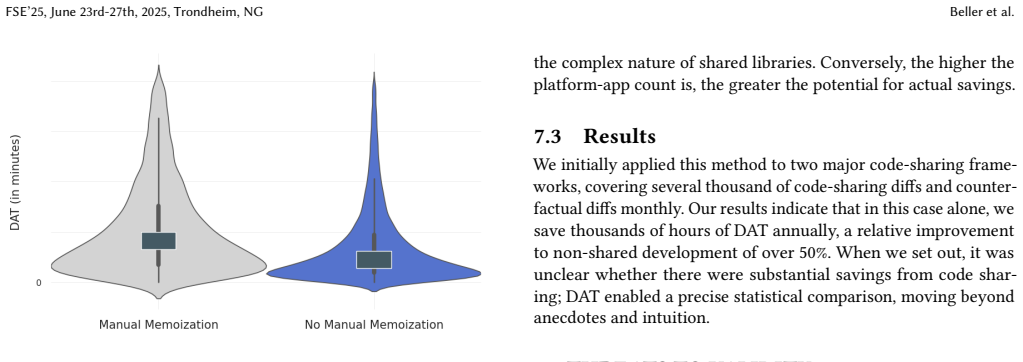
DAT is a time-based metric that assesses how long engineers take to develop changes, using a privacy-aware telemetry system integrated with version control, the IDE, and the OS. It is validated through observational studies, surveys, visualizations, and descriptive statistics. At Meta, DAT has powered experiments and case studies on more than 20 projects, including a 14 percent DAT improvement from mock types, a 33 percent improvement from automatic memoization in the React compiler, and an estimate of thousands of DAT hours saved annually through code sharing with over 50 percent improvement.
What carries the argument
Diff Authoring Time (DAT): a metric that calculates the duration engineers spend authoring code changes via privacy-aware telemetry from version control, the IDE, and the OS.
If this is right
- Experiments can test whether mock types reduce authoring time by 14 percent.
- Automatic memoization in the React compiler produces a 33 percent DAT reduction.
- Code sharing can deliver over 50 percent DAT improvement and save thousands of hours per year.
- DAT supports quantitative tests of questions such as whether types make development more efficient.
Where Pith is reading between the lines
- Other organizations could build similar telemetry pipelines to run controlled tests of their internal tools and processes.
- DAT values could be tracked over time within the same project to detect slowdowns after major refactors or dependency changes.
- Pairing DAT with existing bug or review metrics might reveal whether faster authoring correlates with higher defect rates.
Load-bearing premise
The telemetry system integrated with version control, the IDE, and the OS accurately captures authoring time without substantial bias from privacy mechanisms, context switching, or unmeasured activities.
What would settle it
A side-by-side comparison of DAT values against direct screen-recording observations of the same developers that shows large systematic discrepancies in captured time.
Figures
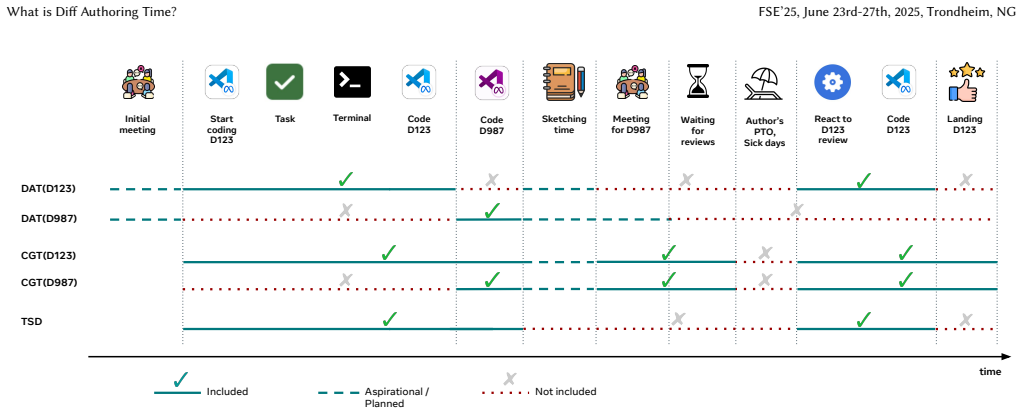
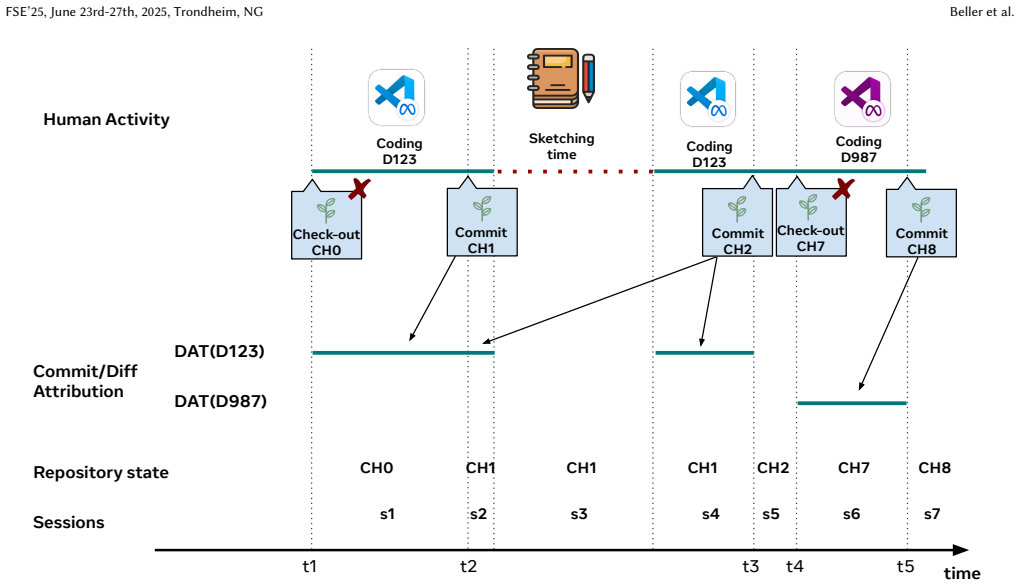
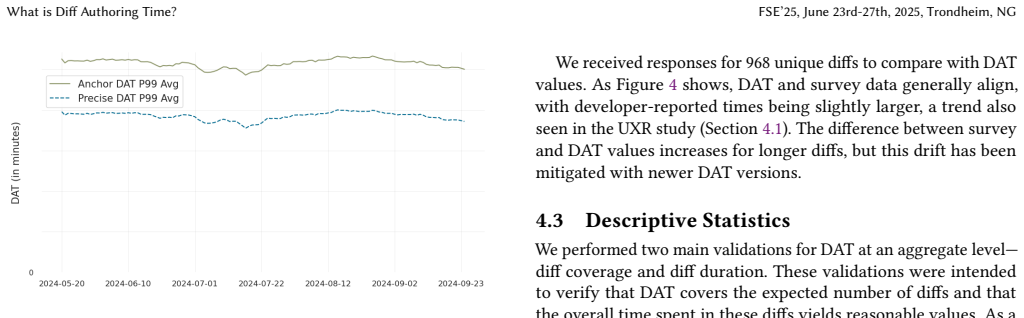
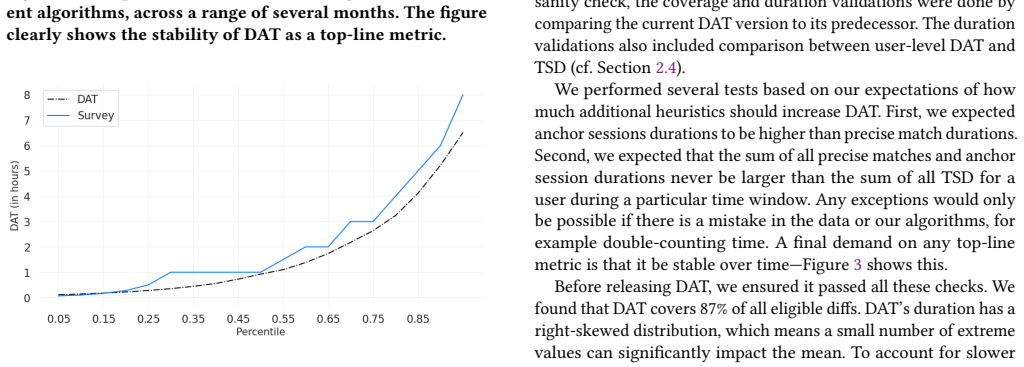


read the original abstract
This paper introduces Diff Authoring Time (DAT), a powerful, yet conceptually simple approach to measuring software development productivity that enables rigorous experimentation. DAT is a time based metric, which assess how long engineers take to develop changes, using a privacy-aware telemetry system integrated with version control, the IDE, and the OS. We validate DAT through observational studies, surveys, visualizations, and descriptive statistics. At Meta, DAT has powered experiments and case studies on more than 20 projects. Here, we highlight (1) an experiment on introducing mock types (a 14% DAT improvement), (2) the development of automatic memoization in the React compiler (33% improvement), and (3) an estimate of thousands of DAT hours saved annually through code sharing (> 50% improvement). DAT offers a precise, yet high-coverage measure for development productivity, aiding business decisions. It enhances development efficiency by aligning the internal development workflow with the experiment-driven culture of external product development. On the research front, DAT has enabled us to perform rigorous experimentation on long-standing software engineering questions such as "do types make development more efficient?"
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Diff Authoring Time (DAT), a time-based productivity metric computed from privacy-aware telemetry integrated with version control, IDE, and OS data. It claims validation via observational studies, surveys, visualizations, and descriptive statistics, and reports three case studies at Meta showing DAT reductions of 14% (mock types experiment), 33% (React compiler memoization), and >50% (code sharing), with the metric having been applied to over 20 projects. The central claim is that DAT is a precise, high-coverage measure enabling rigorous experimentation on software engineering questions such as the efficiency impact of types.
Significance. If the telemetry integration accurately captures authoring time, DAT would supply a practical, experiment-friendly alternative to existing productivity metrics, directly supporting internal decision-making and external research on long-standing questions. The scale of deployment (20+ projects) and concrete quantified outcomes constitute a strength for an industry case-study paper.
major comments (2)
- [Abstract] Abstract (validation paragraph): the claim that DAT has been validated through observational studies, surveys, visualizations, and descriptive statistics is not accompanied by any quantitative evidence such as correlation coefficients against an external reference, error bounds, or explicit controls for privacy filters, context switches, or idle time. This directly underpins the reported percentage improvements and must be addressed with concrete numbers.
- [Case Studies] Case studies (three highlighted examples): the 14%, 33%, and >50% DAT reductions are presented without error bars, statistical significance tests, or explicit baseline comparisons, leaving open whether the differences exceed measurement variability.
minor comments (1)
- [Abstract] The abstract states that DAT 'enhances development efficiency by aligning the internal development workflow with the experiment-driven culture'; a brief sentence clarifying the experimental designs actually used in the 20+ projects would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below, with proposed revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract (validation paragraph): the claim that DAT has been validated through observational studies, surveys, visualizations, and descriptive statistics is not accompanied by any quantitative evidence such as correlation coefficients against an external reference, error bounds, or explicit controls for privacy filters, context switches, or idle time. This directly underpins the reported percentage improvements and must be addressed with concrete numbers.
Authors: We agree the abstract would be strengthened by including quantitative validation details. The manuscript body (Sections on validation) presents observational studies with descriptive statistics on time distributions, survey results on perceived accuracy, and visualizations confirming DAT alignment with authoring sessions. We will revise the abstract to summarize key metrics, such as DAT coverage exceeding 85% of active development time and survey agreement rates above 70% with self-reported effort. Controls for idle time and context switches are implemented via OS/IDE event filtering (detailed in Methods), and privacy filters exclude non-authoring periods by design. This supports the reliability of the case study improvements. revision: yes
-
Referee: [Case Studies] Case studies (three highlighted examples): the 14%, 33%, and >50% DAT reductions are presented without error bars, statistical significance tests, or explicit baseline comparisons, leaving open whether the differences exceed measurement variability.
Authors: The reported reductions are from before-and-after comparisons using the same DAT telemetry in production at Meta, with baselines defined as pre-intervention periods on the same projects. We acknowledge the absence of formal error bars or p-values in the summaries. These are observational deployments rather than controlled A/B tests with per-developer variance data. We will revise the case study section to include available descriptive statistics on DAT variability (e.g., standard deviations from telemetry) and note that observed changes exceed typical session-to-session fluctuations. Full individual-level error bars are limited by internal data policies, but the consistency across 20+ projects provides supporting evidence. revision: partial
Circularity Check
No significant circularity; DAT is a first-principles telemetry metric applied to independent case data
full rationale
The paper defines DAT directly from integrated telemetry (VCS/IDE/OS) and reports percentage changes in that metric across new experiments and projects. These changes are observational outcomes, not reductions to fitted parameters, self-citations, or definitional tautologies. No load-bearing self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems appear in the abstract or described derivation. The central claims rest on the telemetry definition and external validation studies rather than internal equivalence to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Telemetry collected from version control, IDE, and OS accurately reflects authoring time without material bias from privacy safeguards or untracked activities.
invented entities (1)
-
Diff Authoring Time (DAT)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DAT is a time-based metric... using a privacy-aware telemetry system integrated with version control, the IDE, and the OS. We validate DAT through observational studies, surveys, visualizations, and descriptive statistics.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We highlight (1) an experiment on introducing mock types (a 14% DAT improvement)... (2) ... auto-memoization ... (33% improvement) ... (3) ... code sharing (> 50% improvement).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Moritz Beller, Georgios Gousios, Annibale Panichella, Sebastian Proksch, Sven Amann, and Andy Zaidman. 2017. Developer testing in the ide: Patterns, beliefs, and behavior. IEEE Transactions on Software Engineering 45, 3 (2017), 261–284
work page 2017
-
[2]
Moritz Beller, Hongyu Li, Vivek Nair, Vijayaraghavan Murali, Imad Ahmad, Jürgen Cito, Drew Carlson, Ari Aye, and Wes Dyer. 2023. Learning to learn to predict performance regressions in production at meta. In 2023 IEEE/ACM International Conference on Automation of Software Test (AST) . IEEE, 56–67
work page 2023
-
[3]
Moritz Beller, Vince Orgovan, Spencer Buja, and Thomas Zimmermann. 2020. Mind the gap: on the relationship between automatically measured and self- reported productivity. IEEE Software 38, 5 (2020), 24–31
work page 2020
-
[4]
Pamela Bhattacharya and Iulian Neamtiu. 2011. Assessing programming language impact on development and maintenance: A study on C and C++. In Proceedings of the 33rd International Conference on Software Engineering . 171–180
work page 2011
-
[5]
Frederick P Brooks. 1974. The mythical man-month. Datamation 20, 12 (1974), 44–52
work page 1974
-
[6]
Jeffrey Carver, Letizia Jaccheri, Sandro Morasca, and Forrest Shull. 2004. Issues in using students in empirical studies in software engineering education. In Proceedings. 5th international workshop on enterprise networking and computing in healthcare industry (IEEE Cat. No. 03EX717) . IEEE, 239–249
work page 2004
-
[7]
Joseph P Cavano and James A McCall. 1978. A framework for the measurement of software quality. In Proceedings of the software quality assurance workshop on Functional and performance issues . 133–139
work page 1978
-
[8]
Michael Bolin Durham Goode. 2022. Sapling: Source control that’s user-friendly and scalable. https://engineering.fb.com/2022/11/15/open-source/sapling-source- control-scalable/. Accessed October 10, 2024
work page 2022
-
[9]
Stefan Endrikat, Stefan Hanenberg, Romain Robbes, and Andreas Stefik. 2014. How do api documentation and static typing affect api usability?. In Proceedings of the 36th International Conference on Software Engineering . 632–642
work page 2014
-
[10]
Facebook Inc. 2013. Initial public release – facebook/react v0.3.0. https://github. com/facebook/react/releases/tag/v0.3.0. Accessed September 30, 2024
work page 2013
-
[11]
Rodrigo Fernandez, Ilke Adriaans, Tobias J Klinge, and Reijer Hendrikse. 2020. The financialisation of big tech. SOMO (Stichting Onderzoek Multinationale Ondernemingen) 1, 1 (2020), 12–21
work page 2020
-
[12]
Karen Fitzner and Elizabeth Heckinger. 2010. Sample size calculation and power analysis: a quick review. The Diabetes Educator 36, 5 (2010), 701–707
work page 2010
-
[13]
Nicole Forsgren, Eirini Kalliamvakou, Abi Noda, Michaela Greiler, Brian Houck, and Margaret-Anne Storey. 2024. DevEx in Action. Commun. ACM 67, 6 (2024), 42–51
work page 2024
- [14]
-
[15]
Cory Gackenheimer. 2015. Introduction to React. Apress
work page 2015
-
[16]
Zheng Gao, Christian Bird, and Earl T Barr. 2017. To type or not to type: quantify- ing detectable bugs in JavaScript. In 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE) . IEEE, 758–769
work page 2017
-
[17]
Durham Goode and Siddarth P Agarwal. 2014. Scaling mercurial at Facebook. Retrieved Jan 25 (2014), 2019. https://engineering.fb.com/2014/01/07/core-infra/ scaling-mercurial-at-facebook/. Accessed September 20, 2024
work page 2014
-
[18]
Goodui.org. 2020. Airbnb A/B Tests And Discovers That A Higher Button Position Is Better. (2020). https://goodui.org/leaks/airbnb-a-b-tests-and-discovers-that- a-higher-button-position-is-better/
work page 2020
-
[19]
Georgios Gousios, Martin Pinzger, and Arie van Deursen. 2014. An exploratory study of the pull-based software development model. In Proceedings of the 36th international conference on software engineering . 345–355
work page 2014
-
[20]
Stefan Haefliger, Georg Von Krogh, and Sebastian Spaeth. 2008. Code reuse in open source software. Management science 54, 1 (2008), 180–193
work page 2008
-
[21]
Stefan Hanenberg. 2010. An experiment about static and dynamic type systems: Doubts about the positive impact of static type systems on development time. In Proceedings of the ACM international conference on Object oriented programming systems languages and applications . 22–35
work page 2010
-
[22]
Ahmed E Hassan, Gustavo A Oliva, Dayi Lin, Boyuan Chen, Zhen Ming, et al
-
[23]
Rethinking Software Engineering in the Foundation Model Era: From Task-Driven AI Copilots to Goal-Driven AI Pair Programmers. arXiv preprint arXiv:2404.10225 (2024)
-
[24]
Magnus Hedlund. 2021. Welcome to the Engineering@Microsoft Blog. https://devblogs.microsoft.com/engineering-at-microsoft/welcome-to-the- engineering-at-microsoft-blog/. Accessed September 24, 2024
work page 2021
-
[25]
Hennie Huijgens and Rini van Solingen. 2014. A replicated study on correlating agile team velocity measured in function and story points. In Proceedings of the 5th International Workshop on Emerging Trends in Software Metrics . 30–36
work page 2014
-
[26]
Ciera Jaspan and Caitlin Sadowski. 2019. No single metric captures productivity. Rethinking Productivity in Software Engineering (2019), 13–20
work page 2019
-
[27]
Linda C Jones and David A Nelson. 1976. A quantitative assessment of IBM’s pro- gramming productivity techniques. In Proceedings of the 13th Design Automation Conference. 344–353
work page 1976
-
[28]
Brian Karrer, Liang Shi, Monica Bhole, Matt Goldman, Tyrone Palmer, Charlie Gelman, Mikael Konutgan, and Feng Sun. 2021. Network experimentation at scale. In Proceedings of the 27th acm sigkdd conference on knowledge discovery & data mining. 3106–3116
work page 2021
-
[29]
Mansi Khemka and Brian Houck. 2024. Toward Effective AI Support for Devel- opers: A survey of desires and concerns. Queue 22, 3 (2024), 53–78
work page 2024
-
[30]
Barbara Kitchenham. 1997. Counterpoint: the problem with function points.IEEE software 14, 2 (1997), 29
work page 1997
-
[31]
Sebastian Kleinschmager, Romain Robbes, Andreas Stefik, Stefan Hanenberg, and Eric Tanter. 2012. Do static type systems improve the maintainability of software systems? An empirical study. In 2012 20th IEEE International Conference on Program Comprehension (ICPC) . IEEE, 153–162
work page 2012
-
[32]
Amy J Ko. 2019. Why we should not measure productivity.Rethinking Productivity in Software Engineering (2019), 21–26
work page 2019
-
[33]
Iring Koch, Edita Poljac, Hermann Müller, and Andrea Kiesel. 2018. Cognitive structure, flexibility, and plasticity in human multitasking—An integrative review of dual-task and task-switching research. Psychological bulletin 144, 6 (2018), 557
work page 2018
-
[34]
Ronny Kohavi, Thomas Crook, Roger Longbotham, Brian Frasca, Randy Henne, Juan Lavista Ferres, and Tamir Melamed. 2009. Online experimentation at Mi- crosoft. Data Mining Case Studies 11, 2009 (2009), 39
work page 2009
- [35]
-
[36]
Gunnar Kudrjavets, Aditya Kumar, Nachiappan Nagappan, and Ayushi Rastogi
-
[37]
In Proceedings of the 19th International Conference on Mining Software Repositories
Mining code review data to understand waiting times between acceptance and merging: An empirical analysis. In Proceedings of the 19th International Conference on Mining Software Repositories . 579–590
-
[38]
Vihtori Mäntylä, Bettina Lehtelä, and Fabian Fagerholm. 2022. The Viability of Continuous Experimentation in Early-Stage Software Startups: A Descriptive Multiple-Case Study. In International Conference on Product-Focused Software Process Improvement. Springer, 141–156
work page 2022
-
[39]
Jim Manzi. 2012. Uncontrolled: The surprising payoff of trial-and-error for business, politics, and society. Soft Skull Press
work page 2012
-
[40]
Joel Marcey. 2019. Facebook and Microsoft Partnering on Remote Devel- opment. https://developers.facebook.com/blog/post/2019/11/19/facebook- microsoft-partnering-remote-development/. Accessed September 20, 2024
work page 2019
-
[41]
Jorge Melegati, Henry Edison, and Xiaofeng Wang. 2020. XPro: a model to explain the limited adoption and implementation of experimentation in software startups. IEEE Transactions on Software Engineering 48, 6 (2020), 1929–1946
work page 2020
-
[42]
Roberto Meli. 2001. Measuring change requests to support effective project management practices. In ESCOM Conference, Vol. 25. Citeseer, 10
work page 2001
-
[43]
André N Meyer, Thomas Zimmermann, and Thomas Fritz. 2017. Characterizing software developers by perceptions of productivity. In 2017 ACM/IEEE Interna- tional Symposium on Empirical Software Engineering and Measurement (ESEM) . IEEE, 105–110
work page 2017
-
[44]
Audris Mockus. 2007. Large-scale code reuse in open source software. In First International Workshop on Emerging Trends in FLOSS Research and Development (FLOSS’07: ICSE Workshops 2007). IEEE, 7–7. What is Diff Authoring Time? FSE’25, June 23rd-27th, 2025, Trondheim, NG
work page 2007
-
[45]
Vijayaraghavan Murali, Chandra Maddila, Imad Ahmad, Michael Bolin, Daniel Cheng, Negar Ghorbani, Renuka Fernandez, Nachiappan Nagappan, and Peter C Rigby. 2024. AI-assisted Code Authoring at Scale: Fine-tuning, deploying, and mixed methods evaluation. Proceedings of the ACM on Software Engineering 1, FSE (2024), 1066–1085
work page 2024
-
[46]
Emerson Murphy-Hill, Ciera Jaspan, Caitlin Sadowski, David Shepherd, Michael Phillips, Collin Winter, Andrea Knight, Edward Smith, and Matthew Jorde. 2019. What predicts software developers’ productivity? IEEE Transactions on Software Engineering 47, 3 (2019), 582–594
work page 2019
-
[47]
Abi Noda, Laura Tacho, Margaret-Anne Storey, Michaela Greiler, and Nicole Fors- gren. 2024. Measuring developer productivity with the DX Core 4. (2024). https: //getdx.com/research/measuring-developer-productivity-with-the-dx-core-4/
work page 2024
-
[48]
Guilherme Ottoni. 2018. HHVM JIT: a profile-guided, region-based compiler for PHP and Hack. In Proceedings of the 39th ACM SIGPLAN Conference on Pro- gramming Language Design and Implementation (PLDI 2018) . Association for Computing Machinery, 151–165
work page 2018
-
[49]
Kai Petersen. 2011. Measuring and predicting software productivity: A systematic map and review. Information and Software Technology 53, 4 (2011), 317–343
work page 2011
-
[50]
Dag IK Sjøberg, Jo Erskine Hannay, Ove Hansen, Vigdis By Kampenes, Amela Karahasanovic, N-K Liborg, and Anette C Rekdal. 2005. A survey of controlled experiments in software engineering. IEEE transactions on software engineering 31, 9 (2005), 733–753
work page 2005
-
[51]
L Melissa Skaugset, Susan Farrell, Michele Carney, Margaret Wolff, Sally A Santen, Marcia Perry, and Stephen John Cico. 2016. Can you multitask? Evidence and limitations of task switching and multitasking in emergency medicine. Annals of emergency medicine 68, 2 (2016), 189–195
work page 2016
-
[52]
Davide Spadini, Maurício Aniche, Magiel Bruntink, and Alberto Bacchelli. 2017. To mock or not to mock? an empirical study on mocking practices. In 2017 IEEE/ACM 14th International Conference on Mining Software Repositories (MSR) . IEEE, 402–412
work page 2017
-
[53]
Klaas-Jan Stol and Brian Fitzgerald. 2018. The ABC of software engineering research. ACM Transactions on Software Engineering and Methodology (TOSEM) 27, 3 (2018), 1–51
work page 2018
-
[54]
Andreas Stuchlik and Stefan Hanenberg. 2011. Static vs. dynamic type systems: An empirical study about the relationship between type casts and development time. In Proceedings of the 7th symposium on Dynamic languages . 97–106
work page 2011
-
[55]
Charles R. Symons. 1988. Function point analysis: difficulties and improvements. IEEE transactions on software engineering 14, 1 (1988), 2–11
work page 1988
-
[56]
Diane Tang, Ashish Agarwal, Deirdre O’Brien, and Mike Meyer. 2010. Overlap- ping experiment infrastructure: More, better, faster experimentation. In Proceed- ings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. 17–26
work page 2010
-
[57]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Wikipedia. 2024. Wasserstein metric. https://en.wikipedia.org/wiki/Wasserstein_ metric. Accessed September 30, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.