Segment Any-Quality Images with Generative Latent Space Enhancement
Pith reviewed 2026-05-22 23:42 UTC · model grok-4.3
The pith
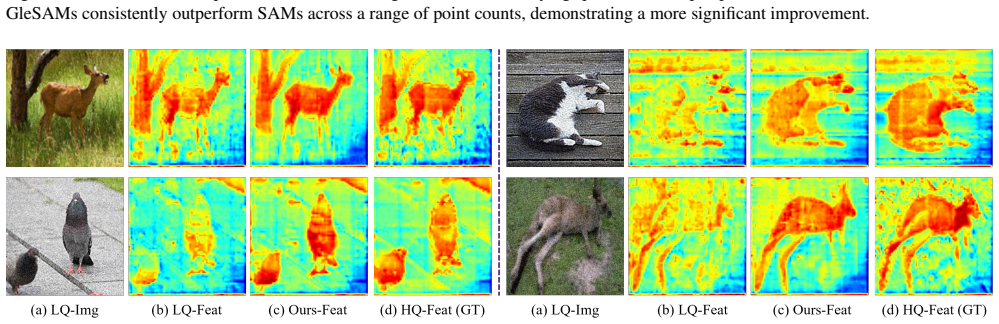
GleSAM adapts latent diffusion inside SAM to restore high-quality features from degraded images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting the latent diffusion process to operate directly in the latent space of a pre-trained SAM, GleSAM reconstructs high-quality representations from degraded inputs. Two compatibility techniques ensure the enhanced features remain usable by the original segmentation head. The approach requires only minimal additional learnable parameters, enabling efficient application to SAM and SAM2 while supporting generalization across image qualities.
What carries the argument
Generative Latent space Enhancement (GleSAM), which performs the generative diffusion process in the latent space of SAM to reconstruct high-quality representations compatible with the segmentation head.
If this is right
- GleSAM applies to pre-trained SAM and SAM2 using only minimal additional learnable parameters.
- It improves segmentation robustness on complex degradations while keeping performance on clear images.
- It maintains useful accuracy on degradation types not encountered during training.
- The LQSeg dataset supplies greater diversity of degradation types and levels for training and evaluation.
- Two compatibility techniques allow the pre-trained diffusion model to integrate with the segmentation framework.
Where Pith is reading between the lines
- The same latent-space enhancement pattern could be tested on other vision foundation models facing input-quality variation.
- Real-world pipelines that encounter mixed-quality imagery might reduce reliance on separate quality-restoration stages.
- Extending the approach to video or 3D data would require checking whether the latent diffusion remains stable across frames or views.
Load-bearing premise
The diffusion process in SAM's latent space can reconstruct high-quality features that stay compatible with the pre-trained segmentation head without adding artifacts or needing major retraining.
What would settle it
Running GleSAM on a set of severely degraded test images produces segmentation masks whose intersection-over-union with ground truth is lower than the masks produced by unmodified SAM on the same images.
Figures













read the original abstract
Despite their success, Segment Anything Models (SAMs) experience significant performance drops on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Specifically, we adapt the concept of latent diffusion to SAM-based segmentation frameworks and perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation, thereby improving segmentation. Additionally, we introduce two techniques to improve compatibility between the pre-trained diffusion model and the segmentation framework. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. We also construct the LQSeg dataset with a greater diversity of degradation types and levels for training and evaluating the model. Extensive experiments demonstrate that GleSAM significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GleSAM, which adapts latent diffusion to operate directly in the latent space of pre-trained SAM (and SAM2) models in order to reconstruct higher-quality representations from degraded inputs. Two unspecified compatibility techniques are introduced to align the diffusion outputs with the segmentation head; only minimal additional parameters are required. A new LQSeg dataset with diverse degradation types and levels is constructed for training and evaluation. Experiments are claimed to show substantial gains on complex degradations, retention of performance on clean images, and generalization to unseen degradations.
Significance. If the central claims are substantiated, the work would be significant for extending SAM-family models to real-world low-quality imagery without full retraining. Credit is due for constructing the LQSeg dataset with greater diversity of degradations and for demonstrating generalization to unseen degradations; the minimal-parameter design is also a practical strength.
major comments (2)
- [Abstract] Abstract: the central claim that diffusion performed in the pre-trained SAM latent space yields representations usable by the (frozen or lightly adapted) segmentation head rests on two unspecified compatibility techniques; without equations, architecture details, or ablations showing preservation of geometric/semantic properties (e.g., no shift in embedding distribution or injection of high-frequency artifacts), the claim cannot be evaluated.
- [Method] The weakest assumption—that the reverse diffusion process in SAM’s ViT-based latent space remains distributionally compatible with the decoder—is load-bearing yet unsupported by any reported diagnostic (cosine similarity, feature-map visualization, or ablation removing the compatibility techniques) in the provided text.
minor comments (1)
- [Abstract] The abstract would be clearer if the two compatibility techniques were named or briefly characterized rather than left unspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying details from the manuscript and indicating revisions to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that diffusion performed in the pre-trained SAM latent space yields representations usable by the (frozen or lightly adapted) segmentation head rests on two unspecified compatibility techniques; without equations, architecture details, or ablations showing preservation of geometric/semantic properties (e.g., no shift in embedding distribution or injection of high-frequency artifacts), the claim cannot be evaluated.
Authors: The two compatibility techniques (Latent Space Alignment and Conditional Feature Injection) are specified with equations and architecture diagrams in Section 3.2 of the manuscript. We agree the abstract is too brief on this point and will revise it to name the techniques and note their minimal-parameter nature. We will also add a dedicated ablation subsection (with embedding cosine similarity and distribution shift metrics) to the experiments to directly address preservation of geometric and semantic properties. revision: yes
-
Referee: [Method] The weakest assumption—that the reverse diffusion process in SAM’s ViT-based latent space remains distributionally compatible with the decoder—is load-bearing yet unsupported by any reported diagnostic (cosine similarity, feature-map visualization, or ablation removing the compatibility techniques) in the provided text.
Authors: We acknowledge that the current text relies primarily on end-task metrics and qualitative examples for compatibility. We will add the requested diagnostics (cosine similarity between pre- and post-diffusion latents, feature-map visualizations, and an ablation that removes the two compatibility techniques) as a new paragraph in Section 4.2 of the revised manuscript. revision: yes
Circularity Check
No circularity; method and claims rest on external pre-trained models plus new empirical validation
full rationale
The paper adapts an existing latent diffusion concept to the latent space of a pre-trained SAM, introduces two unspecified compatibility techniques, adds minimal parameters, constructs a new LQSeg dataset, and reports external experimental results on degraded and clear images. No equations, self-citations, or fitted parameters are shown that reduce any claimed prediction or uniqueness result to the inputs by construction. The derivation chain is self-contained against external benchmarks and does not invoke load-bearing self-citations or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent diffusion models can be adapted to the latent space of pre-trained SAM frameworks with only minimal additional learnable parameters while preserving segmentation capability.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation... Feature Distribution Alignment (FDA) and Channel Replicate and Expansion (CRE)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GleSAM significantly improves segmentation robustness on complex degradations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Segdiff: Image segmentation with diffusion probabilistic models
Tomer Amit, Tal Shaharbany, Eliya Nachmani, and Lior Wolf. Segdiff: Image segmentation with diffusion proba- bilistic models. arXiv preprint arXiv:2112.00390, 2021. 3
-
[2]
Label-efficient se- mantic segmentation with diffusion models
Dmitry Baranchuk, Andrey V oynov, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Label-efficient se- mantic segmentation with diffusion models. In International Conference on Learning Representations, 2022. 3
work page 2022
-
[3]
Just a hint: Point-supervised camouflaged object detection
Huafeng Chen, Dian Shao, Guangqian Guo, and Shan Gao. Just a hint: Point-supervised camouflaged object detection. In European Conference on Computer Vision , pages 332– 348, 2024. 1
work page 2024
-
[4]
Sam-cod: Sam-guided unified framework for weakly- supervised camouflaged object detection
Huafeng Chen, Pengxu Wei, Guangqian Guo, and Shan Gao. Sam-cod: Sam-guided unified framework for weakly- supervised camouflaged object detection. In European Con- ference on Computer Vision, pages 315–331, 2024. 1
work page 2024
-
[5]
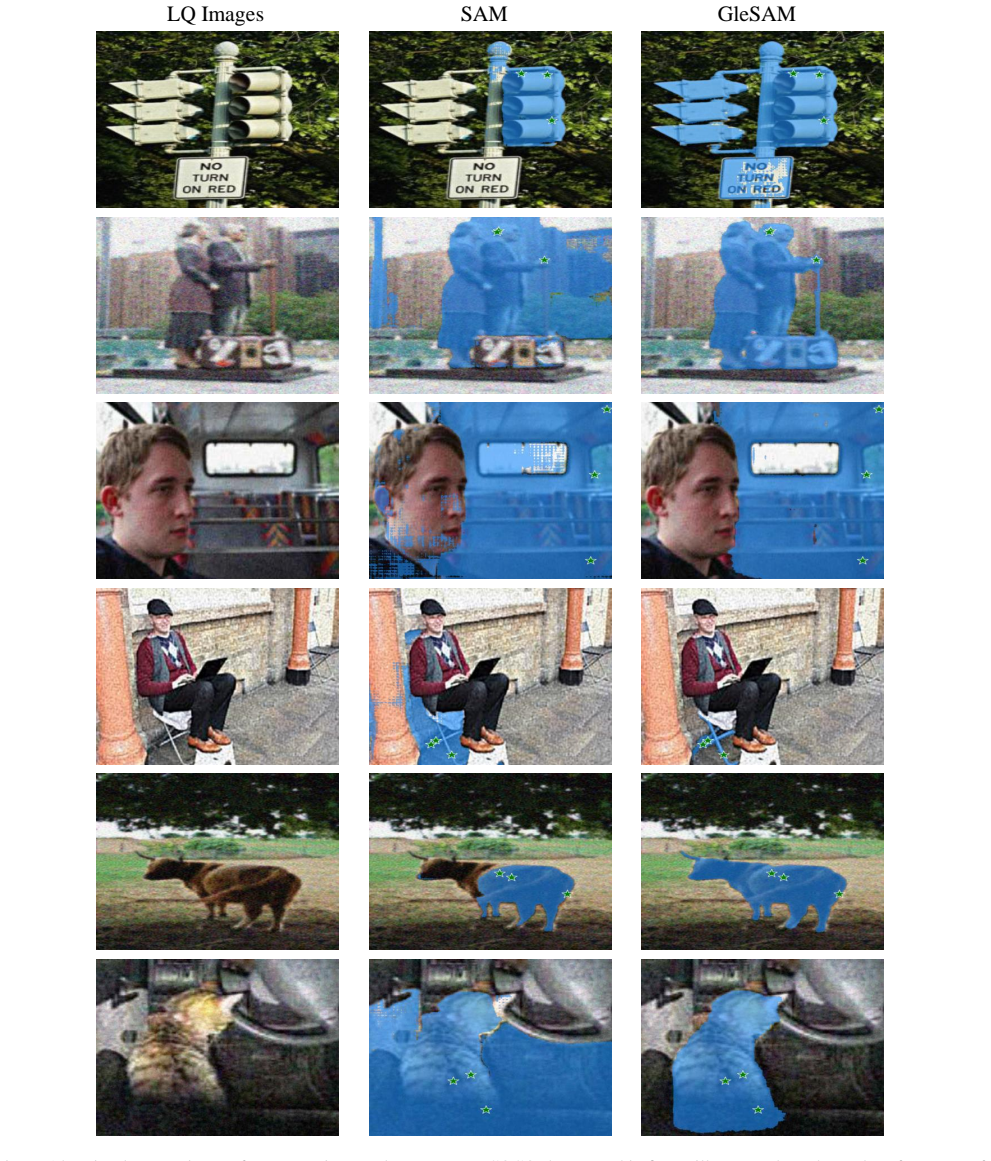
Rsprompter: LQ Images SAM GleSAM Figure 12
Keyan Chen, Chenyang Liu, Hao Chen, Haotian Zhang, Wenyuan Li, Zhengxia Zou, and Zhenwei Shi. Rsprompter: LQ Images SAM GleSAM Figure 12. Visual comparisons of SAM and GleSAM on the unseen ECSSD dataset under RobustSeg-style degradations, such as rain, snow, low-light conditions, and others. The results demonstrate the superior generalization capability o...
work page 2024
-
[6]
Dif- fusiondet: Diffusion model for object detection
Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Dif- fusiondet: Diffusion model for object detection. In Proceed- ings of the IEEE/CVF international conference on computer vision, pages 19830–19843, 2023. 3
work page 2023
-
[7]
A generalist framework for panoptic segmen- tation of images and videos
Ting Chen, Lala Li, Saurabh Saxena, Geoffrey Hinton, and David J Fleet. A generalist framework for panoptic segmen- tation of images and videos. InProceedings of the IEEE/CVF international conference on computer vision , pages 909– 919, 2023. 3
work page 2023
-
[8]
Robustsam: Segment anything robustly on de- graded images
Wei-Ting Chen, Yu-Jiet V ong, Sy-Yen Kuo, Sizhou Ma, and Jian Wang. Robustsam: Segment anything robustly on de- graded images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 4081– 4091, 2024. 1, 2, 3, 5, 6, 7, 8, 9, 10
work page 2024
-
[9]
Global contrast based salient region detection
Ming-Ming Cheng, Niloy J Mitra, Xiaolei Huang, Philip HS Torr, and Shi-Min Hu. Global contrast based salient region detection. IEEE transactions on pattern analysis and ma- chine intelligence, 37(3):569–582, 2014. 2, 5
work page 2014
-
[10]
Adapting segment anything model for change detection in vhr remote sensing images
Lei Ding, Kun Zhu, Daifeng Peng, Hao Tang, Kuiwu Yang, and Lorenzo Bruzzone. Adapting segment anything model for change detection in vhr remote sensing images. IEEE Transactions on Geoscience and Remote Sensing, 2024. 1
work page 2024
-
[11]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020. 9
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Semantic segmentation of degraded images using layer-wise feature adjustor
Kazuki Endo, Masayuki Tanaka, and Masatoshi Okutomi. Semantic segmentation of degraded images using layer-wise feature adjustor. In Proceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision , pages 3205–3213, 2023. 1, 2
work page 2023
-
[13]
Shan Gao, Guangqian Guo, Hanqiao Huang, and CL Philip Chen. Go deep or broad? exploit hybrid network architecture for weakly supervised object classification and localization. IEEE Transactions on Neural Networks and Learning Sys- tems, 2023. 1
work page 2023
-
[14]
Prompting diffusion representations for cross-domain semantic segmentation
Rui Gong, Martin Danelljan, Han Sun, Julio Delgado Man- gas, and Luc Van Gool. Prompting diffusion representations for cross-domain semantic segmentation. arXiv preprint arXiv:2307.02138, 2023. 3
-
[15]
Degraded image semantic seg- mentation with dense-gram networks
Dazhou Guo, Yanting Pei, Kang Zheng, Hongkai Yu, Yuhang Lu, and Song Wang. Degraded image semantic seg- mentation with dense-gram networks. IEEE Transactions on Image Processing, 29:782–795, 2019. 2
work page 2019
-
[16]
Save the tiny, save the all: hi- erarchical activation network for tiny object detection
Guangqian Guo, Pengfei Chen, Xuehui Yu, Zhenjun Han, Qixiang Ye, and Shan Gao. Save the tiny, save the all: hi- erarchical activation network for tiny object detection. IEEE transactions on circuits and systems for video technology, 34 (1):221–234, 2023. 1
work page 2023
-
[17]
Guangqian Guo, Dian Shao, Chenguang Zhu, Sha Meng, Xuan Wang, and Shan Gao. P2p: Transforming from point supervision to explicit visual prompt for object detection and segmentation. In Proceedings of the Thirty-Third Interna- tional Joint Conference on Artificial Intelligence, 2024. 1
work page 2024
-
[18]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019. 2, 5, 6
work page 2019
-
[19]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017. 1
work page 2017
-
[20]
Radiometric ccd camera calibration and noise estimation
Glenn E Healey and Raghava Kondepudy. Radiometric ccd camera calibration and noise estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence , 16(3):267– 276, 1994. 1, 3, 10
work page 1994
-
[21]
Benchmarking neu- ral network robustness to common corruptions and perturba- tions
Dan Hendrycks and Thomas Dietterich. Benchmarking neu- ral network robustness to common corruptions and perturba- tions. In International Conference on Learning Representa- tions, 2018. 10
work page 2018
-
[22]
Denoising dif- fusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models. Advances in neural information processing systems, pages 6840–6851, 2020. 2, 3
work page 2020
-
[23]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
On the robustness of segment anything
Yihao Huang, Yue Cao, Tianlin Li, Felix Juefei-Xu, Di Lin, Ivor W Tsang, Yang Liu, and Qing Guo. On the robustness of segment anything. arXiv preprint arXiv:2305.16220, 2023. 1, 3
-
[25]
Ddp: Diffusion model for dense visual prediction
Yuanfeng Ji, Zhe Chen, Enze Xie, Lanqing Hong, Xihui Liu, Zhaoqiang Liu, Tong Lu, Zhenguo Li, and Ping Luo. Ddp: Diffusion model for dense visual prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 21741–21752, 2023. 3
work page 2023
-
[26]
Benchmarking the robustness of semantic segmentation models
Christoph Kamann and Carsten Rother. Benchmarking the robustness of semantic segmentation models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8828–8838, 2020. 2
work page 2020
-
[27]
Segment anything in high qual- ity
Lei Ke, Mingqiao Ye, Martin Danelljan, Yu-Wing Tai, Chi- Keung Tang, Fisher Yu, et al. Segment anything in high qual- ity. Advances in Neural Information Processing Systems, 36,
-
[28]
Alexander Kirillov, Kaiming He, Ross Girshick, Carsten Rother, and Piotr Doll´ar. Panoptic segmentation. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 9404–9413, 2019. 1
work page 2019
-
[29]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. arXiv preprint arXiv:2304.02643, 2023. 1, 2, 3, 5, 7, 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Text-image align- ment for diffusion-based perception
Neehar Kondapaneni, Markus Marks, Manuel Knott, Rog´erio Guimaraes, and Pietro Perona. Text-image align- ment for diffusion-based perception. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13883–13893, 2024. 3
work page 2024
-
[31]
Fifo: Learning fog-invariant features for foggy scene segmentation
Sohyun Lee, Taeyoung Son, and Suha Kwak. Fifo: Learning fog-invariant features for foggy scene segmentation. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18911–18921, 2022. 2
work page 2022
-
[32]
Asam: Boosting seg- ment anything model with adversarial tuning
Bo Li, Haoke Xiao, and Lv Tang. Asam: Boosting seg- ment anything model with adversarial tuning. In Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3699–3710, 2024. 3
work page 2024
-
[33]
Dn-detr: Accelerate detr training by intro- ducing query denoising
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by intro- ducing query denoising. In Proceedings of the IEEE con- ference on computer vision and pattern recognition , pages 13619–13627, 2022. 9, 10, 14
work page 2022
-
[34]
Deep interactive thin object selection
Jun Hao Liew, Scott Cohen, Brian Price, Long Mai, and Ji- ashi Feng. Deep interactive thin object selection. In Pro- ceedings of the IEEE Winter Conference on Applications of Computer Vision, pages 305–314, 2021. 2, 5, 6
work page 2021
-
[35]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014. 2, 5, 6, 14
work page 2014
-
[36]
Diff- bir: Towards blind image restoration with generative diffu- sion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Wanli Ouyang, Yu Qiao, and Chao Dong. Diff- bir: Towards blind image restoration with generative diffu- sion prior. arXiv preprint arXiv:2308.15070, 2023. 3, 6
-
[37]
Automatic estimation and re- moval of noise from a single image
Ce Liu, Richard Szeliski, Sing Bing Kang, C Lawrence Zit- nick, and William T Freeman. Automatic estimation and re- moval of noise from a single image. IEEE transactions on pattern analysis and machine intelligence , 30(2):299–314,
-
[38]
Digi- tal camera identification from sensor pattern noise
Jan Lukas, Jessica Fridrich, and Miroslav Goljan. Digi- tal camera identification from sensor pattern noise. IEEE Transactions on Information Forensics and Security , 1(2): 205–214, 2006. 1, 3, 10
work page 2006
-
[39]
Segment anything in medical images
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images. Nature Communications, 15(1):654, 2024. 1, 3
work page 2024
-
[40]
Segment anything model for medical image analysis: an experimental study
Maciej A Mazurowski, Haoyu Dong, Hanxue Gu, Jichen Yang, Nicholas Konz, and Yixin Zhang. Segment anything model for medical image analysis: an experimental study. Medical Image Analysis, 89:102918, 2023. 1
work page 2023
-
[41]
Im- proved knowledge distillation via teacher assistant
Seyed Iman Mirzadeh, Mehrdad Farajtabar, Ang Li, Nir Levine, Akihiro Matsukawa, and Hassan Ghasemzadeh. Im- proved knowledge distillation via teacher assistant. In Pro- ceedings of the AAAI conference on artificial intelligence , pages 5191–5198, 2020. 2
work page 2020
-
[42]
Swiftbrush: One-step text-to-image diffusion model with variational score distilla- tion
Thuan Hoang Nguyen and Anh Tran. Swiftbrush: One-step text-to-image diffusion model with variational score distilla- tion. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2024. 3
work page 2024
-
[43]
Ld-znet: A latent diffusion ap- proach for text-based image segmentation
Koutilya Pnvr, Bharat Singh, Pallabi Ghosh, Behjat Sid- diquie, and David Jacobs. Ld-znet: A latent diffusion ap- proach for text-based image segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 4157–4168, 2023. 3
work page 2023
-
[44]
Promptir: Prompting for all-in- one image restoration
Vaishnav Potlapalli, Syed Waqas Zamir, Salman H Khan, and Fahad Shahbaz Khan. Promptir: Prompting for all-in- one image restoration. Advances in Neural Information Pro- cessing Systems, 36, 2024. 6
work page 2024
-
[45]
Yu Qiao, Chaoning Zhang, Taegoo Kang, Donghun Kim, Chenshuang Zhang, and Choong Seon Hong. Robustness of sam: Segment anything under corruptions and beyond.arXiv preprint arXiv:2306.07713, 2023. 1, 3
-
[46]
Improving robustness of semantic segmentation to motion-blur using class-centric augmenta- tion
AN Rajagopalan et al. Improving robustness of semantic segmentation to motion-blur using class-centric augmenta- tion. In Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition , pages 10470–10479,
-
[47]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Ro- man R ¨adle, Chloe Rolland, Laura Gustafson, et al. Sam2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714, 2024. 1, 3, 9
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2, 3, 5, 13
work page 2022
-
[49]
Hi- era: A hierarchical vision transformer without the bells-and- whistles
Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, et al. Hi- era: A hierarchical vision transformer without the bells-and- whistles. In International Conference on Machine Learning, pages 29441–29454. PMLR, 2023. 9
work page 2023
-
[50]
Improved handling of motion blur in online object detection
Mohamed Sayed and Gabriel Brostow. Improved handling of motion blur in online object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1706–1716, 2021. 10
work page 2021
-
[51]
Laion-5b: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural In- formation Processing Systems, 35:25278–25294, 2022. 2
work page 2022
-
[52]
Robustness of segment anything model (sam) for autonomous driving in adverse weather conditions
Xinru Shan and Chaoning Zhang. Robustness of segment anything model (sam) for autonomous driving in adverse weather conditions. arXiv preprint arXiv:2306.13290, 2023. 1, 3
-
[53]
Interactive 3d medical image segmentation with sam
Chuyun Shen, Wenhao Li, Yuhang Shi, and Xiangfeng Wang. Interactive 3d medical image segmentation with sam
- [54]
-
[55]
Hierarchical image saliency detection on extended cssd
Jianping Shi, Qiong Yan, Li Xu, and Jiaya Jia. Hierarchical image saliency detection on extended cssd. IEEE transac- tions on pattern analysis and machine intelligence , 38(4): 717–729, 2015. 2, 5, 6, 9
work page 2015
-
[56]
Jpeg-resistant adversarial im- ages
Richard Shin and Dawn Song. Jpeg-resistant adversarial im- ages. In NIPS 2017 workshop on machine learning and com- puter security, page 8, 2017. 11
work page 2017
-
[57]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. In International Conference on Learning Representations, 2021. 2, 3
work page 2021
-
[58]
Effective rotate: Learning rotation-robust proto- type for aerial object detection
Chaowei Wang, Guangqian Guo, Chang Liu, Dian Shao, and Shan Gao. Effective rotate: Learning rotation-robust proto- type for aerial object detection. IEEE Transactions on Geo- science and Remote Sensing, 2024. 1
work page 2024
-
[59]
Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model
Di Wang, Jing Zhang, Bo Du, Minqiang Xu, Lin Liu, Dacheng Tao, and Liangpei Zhang. Samrs: Scaling-up re- mote sensing segmentation dataset with segment anything model. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2023. 3
work page 2023
-
[60]
Segrefiner: Towards model- agnostic segmentation refinement with discrete diffusion process
Mengyu Wang, Henghui Ding, Jun Hao Liew, Jiajun Liu, Yao Zhao, and Yunchao Wei. Segrefiner: Towards model- agnostic segmentation refinement with discrete diffusion process. Advances in Neural Information Processing Sys- tems, 36:79761–79780, 2023. 3
work page 2023
-
[61]
Real-esrgan: Training real-world blind super-resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In Proceedings of the IEEE/CVF inter- national conference on computer vision , pages 1905–1914,
work page 1905
-
[62]
End-to-end video instance segmentation with transformers
Yuqing Wang, Zhaoliang Xu, Xinlong Wang, Chunhua Shen, Baoshan Cheng, Hao Shen, and Huaxia Xia. End-to-end video instance segmentation with transformers. In Proceed- ings of the IEEE conference on computer vision and pattern recognition, pages 8741–8750, 2021. 1
work page 2021
-
[63]
An empiri- cal study on the robustness of the segment anything model (sam)
Yuqing Wang, Yun Zhao, and Linda Petzold. An empiri- cal study on the robustness of the segment anything model (sam). Pattern Recognition, page 110685, 2024. 1, 2, 3
work page 2024
-
[64]
Semantic-aware sam for point- prompted instance segmentation
Zhaoyang Wei, Pengfei Chen, Xuehui Yu, Guorong Li, Jian- bin Jiao, and Zhenjun Han. Semantic-aware sam for point- prompted instance segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 3585–3594, 2024. 3
work page 2024
-
[65]
Medsegdiff: Medical image segmentation with diffusion probabilistic model
Junde Wu, Rao Fu, Huihui Fang, Yu Zhang, Yehui Yang, Haoyi Xiong, Huiying Liu, and Yanwu Xu. Medsegdiff: Medical image segmentation with diffusion probabilistic model. In Medical Imaging with Deep Learning , pages 1623–1639. PMLR, 2024. 3
work page 2024
-
[66]
Medsegdiff-v2: Diffusion-based medical im- age segmentation with transformer
Junde Wu, Wei Ji, Huazhu Fu, Min Xu, Yueming Jin, and Yanwu Xu. Medsegdiff-v2: Diffusion-based medical im- age segmentation with transformer. In Proceedings of the AAAI Conference on Artificial Intelligence , pages 6030– 6038, 2024. 3
work page 2024
-
[67]
One-step effective diffusion network for real-world image super-resolution
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution. arXiv preprint arXiv:2406.08177, 2024. 3
-
[68]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. In European Conference on Computer Vision , pages 162–
-
[69]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, 2024. 3
work page 2024
-
[70]
BD D100K: A diverse driving video database with scalable annotation tooling,
Fisher Yu, Wenqi Xian, Yingying Chen, Fangchen Liu, Mike Liao, Vashisht Madhavan, Trevor Darrell, et al. Bdd100k: A diverse driving video database with scalable annotation tool- ing. arXiv preprint arXiv:1805.04687, 2018. 9
-
[71]
Deblurring by realistic blurring
Kaihao Zhang, Wenhan Luo, Yiran Zhong, Lin Ma, Bjorn Stenger, Wei Liu, and Hongdong Li. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2737–2746,
-
[72]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timo- fte. Designing a practical degradation model for deep blind image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4791– 4800, 2021. 2, 5, 11
work page 2021
-
[73]
Unleashing text-to-image diffu- sion models for visual perception
Wenliang Zhao, Yongming Rao, Zuyan Liu, Benlin Liu, Jie Zhou, and Jiwen Lu. Unleashing text-to-image diffu- sion models for visual perception. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 5729–5739, 2023. 3
work page 2023
-
[74]
Medical sam 2: Seg- ment medical images as video via segment anything model
Jiayuan Zhu, Yunli Qi, and Junde Wu. Medical sam 2: Seg- ment medical images as video via segment anything model
- [75]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.