AI Failures in the Eyes of the Downstream Developer: A First Look at Concerns, Practices, and Challenges
Pith reviewed 2026-05-22 23:06 UTC · model grok-4.3
The pith
Downstream developers decide whether AI failures like data leakage and bias get addressed or overlooked when reusing pre-trained models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Downstream developers are aware of several AI failure modes when reusing pre-trained models yet face practical barriers in recognition and mitigation, leading some risks to be inadvertently overlooked during the development of AI-based software.
What carries the argument
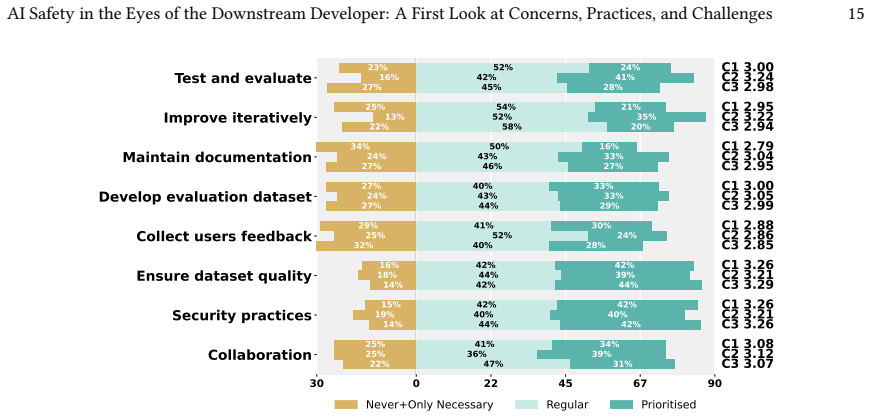
Mixed-method study of interviews and survey responses that captures developer perspectives on AI failure concerns, practices, and challenges.
If this is right
- Immediate risks such as data leakage or model bias may remain unaddressed in real deployments because developers do not always recognize or prioritize them.
- Existing technical taxonomies and mitigation proposals may not match the constraints developers actually face when integrating pre-trained models.
- Development processes for AI-based software could benefit from targeted support that aligns with observed developer practices rather than ideal mitigation steps.
- Training or tooling that focuses only on technical failure modes without addressing reported practical challenges is unlikely to change developer behavior.
Where Pith is reading between the lines
- The findings suggest that future research should test whether developer-focused interventions, such as checklists or automated checks integrated into common workflows, actually increase recognition of overlooked risks.
- One implication is that organizations reusing pre-trained models may need to adjust their review processes to account for the specific gaps in practice identified here rather than relying solely on upstream model documentation.
- The work points toward the value of repeating similar studies in more specialized domains, such as safety-critical systems, to see whether the same patterns hold.
Load-bearing premise
The 16 interview participants and 86 survey respondents form a sufficiently representative sample of downstream developers who reuse pre-trained models.
What would settle it
A larger follow-up study that finds substantially different patterns of concern recognition or mitigation practices among a broader population of downstream developers would undermine the reported findings.
Figures






read the original abstract
With the advancement of AI models, more software systems are adopting AI as a component to facilitate automation. Pre-trained models (PTMs) have become a cornerstone of AI-based software, allowing for rapid integration and development with lower training cost. However, their adoption also introduces failure modes such as data leakage and biased outputs, that may require careful handling by downstream developers. While previous research has proposed taxonomies of these technical concerns and various mitigation strategies, how downstream developers address these issues during the development of general AI-based software when reusing PTMs remains unexplored. Understanding downstream developers' perspectives is essential because they directly influence how these potential failures concerns translate into practice, such as determining whether immediate risks like data leakage or model bias are recognised, mitigated, or inadvertently overlooked in real-world deployments. This study investigates downstream developers' concerns, practices and perceived challenges regarding practical AI failures during the development of AI-based software. To achieve this, we conducted a mixed-method study, including interviews with 16 participants, a survey of 86 practitioners,
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a mixed-methods empirical study of downstream developers who reuse pre-trained models (PTMs) in general AI-based software. It claims to be the first investigation of their concerns, practices, and perceived challenges around AI failures (e.g., data leakage, model bias). Data come from semi-structured interviews with 16 participants followed by a survey of 86 practitioners; the central thesis is that these developers' perspectives determine whether technical failure risks are recognized, mitigated, or overlooked in practice.
Significance. If the sampling and analysis hold, the work supplies concrete, practitioner-grounded evidence on an under-studied population and could directly inform tooling, guidelines, and training for PTM reuse. The mixed-method design and focus on downstream (rather than model-building) developers are strengths that distinguish it from prior taxonomies of AI failures.
major comments (2)
- [§3 and §4] §3 (Study Design) and §4 (Participant Demographics): the central claim that downstream developers' perspectives shape risk recognition requires the 16+86 sample to capture relevant variation among practitioners who reuse PTMs in general AI-based software. No recruitment channels, inclusion/exclusion criteria, screening questions, or verification that participants actually reuse PTMs (as opposed to training models themselves) are reported. This omission directly undermines the generalizability asserted in the abstract and motivation sections.
- [§5 and §6] §5 (Findings) and §6 (Discussion): several reported concerns and challenges are presented as representative of the population, yet the paper provides no response rate, non-response analysis, or comparison of the sample against known demographics of PTM-reusing developers. Without these, the mapping from observed practices to the claim that risks are “inadvertently overlooked” rests on an unverified convenience sample.
minor comments (2)
- [Abstract] The abstract sentence describing the survey is truncated (“a survey of 86 practitioners,”).
- [Tables/Figures] Table and figure captions should explicitly state the number of respondents per item and any filtering applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our mixed-methods study. The comments highlight opportunities to strengthen the reporting of our sampling approach, which we will address in revision. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Study Design) and §4 (Participant Demographics): the central claim that downstream developers' perspectives shape risk recognition requires the 16+86 sample to capture relevant variation among practitioners who reuse PTMs in general AI-based software. No recruitment channels, inclusion/exclusion criteria, screening questions, or verification that participants actually reuse PTMs (as opposed to training models themselves) are reported. This omission directly undermines the generalizability asserted in the abstract and motivation sections.
Authors: We agree that the current manuscript lacks sufficient detail on recruitment and verification procedures. In the revised version we will expand §3 to report: recruitment channels (LinkedIn groups, Reddit communities focused on ML engineering, and targeted outreach via professional networks); inclusion criteria (software practitioners who have reused at least one PTM in a production or near-production system); exclusion criteria (individuals whose primary role is model training or research); screening questions (self-reported experience with PTM integration and confirmation that they do not train models themselves); and verification steps (during interviews, participants were asked to describe specific PTM reuse examples, which were used to confirm eligibility). These additions will directly support the claim that the sample targets downstream developers. revision: yes
-
Referee: [§5 and §6] §5 (Findings) and §6 (Discussion): several reported concerns and challenges are presented as representative of the population, yet the paper provides no response rate, non-response analysis, or comparison of the sample against known demographics of PTM-reusing developers. Without these, the mapping from observed practices to the claim that risks are “inadvertently overlooked” rests on an unverified convenience sample.
Authors: We acknowledge that the survey used convenience sampling via public channels, which prevents calculation of a response rate or formal non-response analysis. In revision we will add an explicit limitations paragraph in §6 that (a) states the sampling method and its implications, (b) discusses potential self-selection bias, and (c) compares sample demographics (role, experience, organization size) against publicly available industry reports on AI/ML practitioners where such benchmarks exist. We will also rephrase findings language to emphasize observed patterns within the sample rather than population representativeness, while retaining the value of the mixed-methods insights for an under-studied population. revision: partial
Circularity Check
Empirical study with no derivation chain or self-referential reductions
full rationale
The paper reports results from a mixed-methods empirical study (16 interviews + 86 survey responses) on developer concerns and practices. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. Claims are grounded directly in participant responses rather than any reduction to prior self-citations or constructed inputs. Sample representativeness is a validity concern but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported concerns and practices from interviews and surveys accurately reflect real development behavior.
- standard math Mixed-method designs combining interviews and surveys are appropriate for exploring unexplored practitioner views.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. https://www.industry.gov.au/publications/australias-artificial-intelligence-ethics-principles/australias-ai-ethics-principles. [Accessed 30-06-2025]
work page 2025
-
[2]
[n. d.]. About — Deon — deon.drivendata.org. https://deon.drivendata.org/#data-science-ethics-checklist. [Accessed 01-07-2025]
work page 2025
-
[3]
[n. d.]. AI Risk Management Framework — nist.gov. https://www.nist.gov/itl/ai-risk-management-framework. [Accessed 24-02-2025]
work page 2025
-
[4]
[n. d.]. Futurium | European AI Alliance - Welcome to the ALTAI portal! — futurium.ec.europa.eu. https://futurium.ec.europa.eu/en/european-ai- alliance/pages/welcome-altai-portal. [Accessed 24-02-2025]
work page 2025
-
[5]
[n. d.]. GitHub Acceptable Use Policies - GitHub Docs — docs.github.com. https://docs.github.com/en/site-policy/acceptable-use-policies/github- acceptable-use-policies. [Accessed 28-02-2025]
work page 2025
-
[6]
[n. d.]. Information security, cybersecurity and privacy protection — Evaluation criteria for IT security (ISO/IEC 15408-5). https://www.iso.org/ standard/72917.html. [Accessed 12-03-2025]
work page 2025
-
[7]
[n. d.]. Information technology — Artificial intelligence — Management system (ISO 42001). https://www.iso.org/standard/81230.html. [Accessed 25-02-2025]
work page 2025
-
[8]
[n. d.]. Safetensors — huggingface.co. https://huggingface.co/docs/safetensors/en/index. [Accessed 05-02-2025]
work page 2025
-
[9]
[n. d.]. The AI Act Explorer | EU Artificial Intelligence Act — artificialintelligenceact.eu. https://artificialintelligenceact.eu/ai-act-explorer/. [Accessed 30-06-2025]
work page 2025
-
[10]
[n. d.]. Welcome to the Artificial Intelligence Incident Database — incidentdatabase.ai. https://incidentdatabase.ai/. [Accessed 01-02-2025]
work page 2025
-
[11]
Avinash Agarwal and Harsh Agarwal. 2024. A seven-layer model with checklists for standardising fairness assessment throughout the AI lifecycle. AI and Ethics 4, 2 (2024), 299–314
work page 2024
-
[12]
Tanvir Rahman Akash, NDJ Lessard, Nayem Rahman Reza, and Md Shakil Islam. 2024. Investigating Methods to Enhance Data Privacy in Business, Especially in sectors like Analytics and Finance. Journal of Computer Science and Technology Studies 6, 5 (2024), 143–151
work page 2024
-
[13]
Sanna J Ali, Angèle Christin, Andrew Smart, and Riitta Katila. 2023. Walking the walk of AI ethics: Organizational challenges and the individualization of risk among ethics entrepreneurs. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency . 217–226
work page 2023
-
[14]
Saleema Amershi, Andrew Begel, Christian Bird, Robert DeLine, Harald Gall, Ece Kamar, Nachiappan Nagappan, Besmira Nushi, and Thomas Zimmermann. 2019. Software engineering for machine learning: A case study. In 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP) . IEEE, 291–300
work page 2019
-
[15]
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. 2016. Concrete problems in AI safety. arXiv preprint arXiv:1606.06565 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[16]
Dharun Anandayuvaraj, Matthew Campbell, Arav Tewari, and James C Davis. 2024. FAIL: Analyzing Software Failures from the News Using LLMs. In 39th IEEE/ACM International Conference on Automated Software Engineering . 506–518
work page 2024
-
[17]
Dharun Anandayuvaraj, Pujita Thulluri, Justin Figueroa, Harshit Shandilya, and James C Davis. 2023. Incorporating failure knowledge into design decisions for iot systems: A controlled experiment on novices. In 2023 IEEE/ACM 5th International Workshop on Software Engineering Research and Practices for the IoT (SERP4IoT). IEEE, 33–37
work page 2023
-
[18]
Ronald E Anderson. 1992. ACM code of ethics and professional conduct. Communications of the ACM (CACM) 35, 5 (1992), 94–99
work page 1992
-
[19]
Maurício Aniche, Christoph Treude, Igor Steinmacher, Igor Wiese, Gustavo Pinto, Margaret-Anne Storey, and Marco Aurélio Gerosa. 2018. How modern news aggregators help development communities shape and share knowledge. InProceedings of the 40th International conference on software engineering. 499–510
work page 2018
-
[20]
Peerachai Banyongrakkul, Mansooreh Zahedi, Patanamon Thongtanunam, Christoph Treude, and Haoyu Gao. 2025. From Release to Adoption: Challenges in Reusing Pre-trained AI Models for Downstream Developers. 2025 IEEE International Conference on Software Maintenance and Evolution (ICSME) (2025)
work page 2025
-
[21]
Daniel A Beach. 1989. Identifying the random responder. The Journal of psychology 123, 1 (1989), 101–103
work page 1989
-
[22]
Lee A Becker. 2000. Effect size (ES). (2000)
work page 2000
-
[23]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative research in psychology 3, 2 (2006), 77–101
work page 2006
-
[24]
Larissa Braz, Christian Aeberhard, Gül Çalikli, and Alberto Bacchelli. 2022. Less is more: supporting developers in vulnerability detection during code review. In 44th International conference on software engineering . 1317–1329
work page 2022
-
[25]
Kathy Charmaz. 2006. Constructing grounded theory: A practical guide through qualitative analysis . sage
work page 2006
-
[26]
Shamik Chaudhuri, Kingshuk Dasgupta, Isaac Hepworth, Michael Le, Mark Lodato, Mihai Maruseac, Sarah Meiklejohn, Tehila Minkus, and Kara Olive. 2024. Securing the AI Software Supply Chain . Technical Report. Google. Manuscript submitted to ACM 26 Gao et al
work page 2024
-
[27]
Pin-Yu Chen and Sijia Liu. 2023. Holistic adversarial robustness of deep learning models. In AAAI Conference on Artificial Intelligence , Vol. 37. 15411–15420
work page 2023
-
[28]
Nathan Chong, Byron Cook, Jonathan Eidelman, Konstantinos Kallas, Kareem Khazem, Felipe R Monteiro, Daniel Schwartz-Narbonne, Serdar Tasiran, Michael Tautschnig, and Mark R Tuttle. 2021. Code-level model checking in the software development workflow at Amazon web services. Software: Practice and Experience 51, 4 (2021), 772–797
work page 2021
-
[29]
Monica Ciolacu, Ali Fallah Tehrani, Leon Binder, and Paul Mugur Svasta. 2018. Education 4.0-Artificial Intelligence assisted higher education: early recognition system with machine learning to support students’ success. InIEEE International Symposium for Design and Technology in Electronic Packaging. IEEE, 23–30
work page 2018
-
[30]
Daniela S Cruzes and Tore Dyba. 2011. Recommended steps for thematic synthesis in software engineering. In 2011 international symposium on empirical software engineering and measurement . IEEE, 275–284
work page 2011
-
[31]
James C Davis, Purvish Jajal, Wenxin Jiang, Taylor R Schorlemmer, Nicholas Synovic, and George K Thiruvathukal. 2023. Reusing deep learning models: Challenges and directions in software engineering. In 2023 IEEE John Vincent Atanasoff International Symposium on Modern Computing (JV A). IEEE, 17–30
work page 2023
-
[32]
Gregory Falco, Ben Shneiderman, Julia Badger, Ryan Carrier, Anton Dahbura, David Danks, Martin Eling, Alwyn Goodloe, Jerry Gupta, Christopher Hart, et al. 2021. Governing AI safety through independent audits. Nature Machine Intelligence 3, 7 (2021), 566–571
work page 2021
-
[33]
Marcelo Fernandes, Samuel Ferino, Anny Fernandes, Uirá Kulesza, Eduardo Aranha, and Christoph Treude. 2022. Devops education: An interview study of challenges and recommendations. In ACM/IEEE 44th International Conference on Software Engineering: Software Engineering Education and Training. 90–101
work page 2022
-
[34]
Eve Fleisig, Genevieve Smith, Madeline Bossi, Ishita Rustagi, Xavier Yin, and Dan Klein. 2024. Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination. In 2024 Conference on Empirical Methods in Natural Language Processing , Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Flo...
work page 2024
-
[35]
Haoyu Gao, Christoph Treude, and Mansooreh Zahedi. 2023. Evaluating transfer learning for simplifying github readmes. In ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering
work page 2023
-
[36]
Haoyu Gao, Christoph Treude, and Mansooreh Zahedi. 2025. Adapting Installation Instructions in Rapidly Evolving Software Ecosystems. IEEE Transactions on Software Engineering (2025)
work page 2025
-
[37]
Haoyu Gao, Mansooreh Zahedi, Christoph Treude, Sarita Rosenstock, and Marc Cheong. 2024. Documenting ethical considerations in open source ai models. In International Symposium on Empirical Software Engineering and Measurement
work page 2024
-
[38]
Vahid Garousi and Mika V Mäntylä. 2016. When and what to automate in software testing? A multi-vocal literature review. Information and Software Technology 76 (2016), 92–117
work page 2016
-
[39]
Christoph Gladisch, Thomas Heinz, Christian Heinzemann, Jens Oehlerking, Anne von Vietinghoff, and Tim Pfitzer. 2019. Experience paper: Search-based testing in automated driving control applications. In 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 26–37
work page 2019
-
[40]
Youdi Gong, Guangzhen Liu, Yunzhi Xue, Rui Li, and Lingzhong Meng. 2023. A survey on dataset quality in machine learning. Information and Software Technology (2023), 107268
work page 2023
-
[41]
P Goyal. 2017. Accurate, large minibatch SG D: training imagenet in 1 hour. arXiv preprint arXiv:1706.02677 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Greg Guest, Arwen Bunce, and Laura Johnson. 2006. How many interviews are enough? An experiment with data saturation and variability. Field methods 18, 1 (2006), 59–82
work page 2006
-
[43]
Philipp Hacker, Andreas Engel, and Marco Mauer. 2023. Regulating ChatGPT and other large generative AI models. In Proceedings of the 2023 ACM conference on fairness, accountability, and transparency . 1112–1123
work page 2023
-
[44]
Jose Hernández-Orallo, Fernando Martínez-Plumed, Shahar Avin, Jess Whittlestone, and Seán Ó hÉigeartaigh. 2020. AI paradigms and AI safety: mapping artefacts and techniques to safety issues. In ECAI 2020. IOS Press, 2521–2528
work page 2020
-
[45]
HiddenLayer. 2025. HiddenLayer AI Threat Landscape Report. https://hiddenlayer.com/company/newsroom/hiddenlayer-ai-threat-landscape- report/. [Accessed 14-Mar-2025]
work page 2025
-
[46]
Rashina Hoda, James Noble, and Stuart Marshall. 2012. Self-organizing roles on agile software development teams. IEEE Transactions on Software Engineering 39, 3 (2012), 422–444
work page 2012
-
[47]
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. 2025. Model context protocol (mcp): Landscape, security threats, and future research directions. arXiv preprint arXiv:2503.23278 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Siw Elisabeth Hove and Bente Anda. 2005. Experiences from conducting semi-structured interviews in empirical software engineering research. In 11th IEEE International Software Metrics Symposium (METRICS’05). IEEE, 10–pp
work page 2005
-
[49]
Pei-Yun Hsueh, Prem Melville, and Vikas Sindhwani. 2009. Data quality from crowdsourcing: a study of annotation selection criteria. In NAACL HLT 2009 workshop on active learning for natural language processing . 27–35
work page 2009
-
[50]
Hugging Face. 2025. Hugging Face Hub Documentation. https://huggingface.co/docs/hub/index Accessed: March 13, 2025
work page 2025
-
[51]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Petra Jääskeläinen, Camilo Sanchez, and André Holzapfel. 2025. Anticipatory Technology Ethics Reflection By Eliciting Creative AI Imaginaries Through Fictional Research Abstracts. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency . 125–136. Manuscript submitted to ACM AI Safety in the Eyes of the Downstream Developer:...
work page 2025
-
[53]
Purvish Jajal, Wenxin Jiang, Arav Tewari, Erik Kocinare, Joseph Woo, Anusha Sarraf, Yung-Hsiang Lu, George K Thiruvathukal, and James C Davis
-
[54]
Interoperability in deep learning: A user survey and failure analysis of onnx model converters. In Proceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA) . 1466–1478
-
[55]
Ziwei Ji, Tiezheng Yu, Yan Xu, Nayeon Lee, Etsuko Ishii, and Pascale Fung. 2023. Towards mitigating LLM hallucination via self reflection. In Findings of the Association for Computational Linguistics: EMNLP 2023 . 1827–1843
work page 2023
-
[56]
Wenxin Jiang, Vishnu Banna, Naveen Vivek, Abhinav Goel, Nicholas Synovic, George K Thiruvathukal, and James C Davis. 2024. Challenges and practices of deep learning model reengineering: A case study on computer vision. Empirical Software Engineering (EMSE) (2024)
work page 2024
-
[57]
Wenxin Jiang, Nicholas Synovic, Matt Hyatt, Taylor R Schorlemmer, Rohan Sethi, Yung-Hsiang Lu, George K Thiruvathukal, and James C Davis
-
[58]
In IEEE/ACM 45th International Conference on Software Engineering
An empirical study of pre-trained model reuse in the hugging face deep learning model registry. In IEEE/ACM 45th International Conference on Software Engineering. IEEE
-
[59]
Wenxin Jiang, Nicholas Synovic, Rohan Sethi, Aryan Indarapu, Matt Hyatt, Taylor R Schorlemmer, George K Thiruvathukal, and James C Davis
-
[60]
An empirical study of artifacts and security risks in the pre-trained model supply chain. In Proceedings of the 2022 ACM Workshop on Software Supply Chain Offensive Research and Ecosystem Defenses . 105–114
work page 2022
-
[61]
Wenxin Jiang, Jerin Yasmin, Jason Jones, Nicholas Synovic, Jiashen Kuo, Nathaniel Bielanski, Yuan Tian, George K Thiruvathukal, and James C Davis. 2024. Peatmoss: A dataset and initial analysis of pre-trained models in open-source software. In 2024 IEEE/ACM 21st International Conference on Mining Software Repositories (MSR) . IEEE, 431–443
work page 2024
-
[62]
Yeonsung Jung, Jaeyun Song, June Yong Yang, Jin-Hwa Kim, Sung-Yub Kim, and Eunho Yang. 2024. A Simple Remedy for Dataset Bias via Self-Influence: A Mislabeled Sample Perspective. In The Thirty-eighth Annual Conference on Neural Information Processing Systems . https: //openreview.net/forum?id=ZVrrPNqHFw
work page 2024
-
[63]
Andrej Karpathy. 2017. Software 2.0. https://karpathy.medium.com/software-2-0-a64152b37c35 Accessed: March 13, 2025
work page 2017
-
[64]
Foutse Khomh, Bram Adams, Jinghui Cheng, Marios Fokaefs, and Giuliano Antoniol. 2018. Software engineering for machine-learning applications: The road ahead. IEEE Software 35, 5 (2018), 81–84
work page 2018
-
[65]
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
Miryung Kim, Thomas Zimmermann, Robert DeLine, and Andrew Begel. 2017. Data scientists in software teams: State of the art and challenges. IEEE Transactions on Software Engineering 44, 11 (2017), 1024–1038
work page 2017
-
[67]
John C Knight. 2002. Safety critical systems: challenges and directions. In Proceedings of the 24th international conference on software engineering . 547–550
work page 2002
-
[68]
Charles W Krueger. 1992. Software reuse. ACM Computing Surveys (CSUR) 24, 2 (1992), 131–183
work page 1992
-
[69]
Hyunin Lee, Chanwoo Park, David Abel, and Ming Jin. 2025. A Black Swan Hypothesis: The Role of Human Irrationality in AI Safety. In The Thirteenth International Conference on Learning Representations
work page 2025
-
[70]
Sung Une Lee, Harsha Perera, Boming Xia, Yue Liu, Qinghua Lu, Liming Zhu, Olivier Salvado, and Jon Whittle. 2024. QB4AIRA: A Question Bank for Responsible AI Risk Assessment. IEEE Software (2024)
work page 2024
-
[71]
Timothy C Lethbridge, Susan Elliott Sim, and Janice Singer. 2005. Studying software engineers: Data collection techniques for software field studies. Empirical software engineering 10 (2005), 311–341
work page 2005
-
[72]
Nancy G. Leveson and Peter R. Harvey. 1983. Analyzing software safety. IEEE Transactions on Software Engineering (TSE) 5 (1983), 569–579
work page 1983
-
[73]
Chin-Yew Lin. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out. 74–81
work page 2004
-
[74]
Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li
-
[75]
Trustworthy LLMs: a Survey and Guideline for Evaluating Large Language Models' Alignment
Trustworthy llms: a survey and guideline for evaluating large language models’ alignment. arXiv preprint arXiv:2308.05374 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[76]
MH Lloyd and PJ Reeve. 2009. IEC 61508 and IEC 61511 assessments-some lessons learned. In 4th IET International Conference on System Safety
work page 2009
- [77]
-
[78]
Qinghua Lu, Liming Zhu, Xiwei Xu, Jon Whittle, Didar Zowghi, and Aurelie Jacquet. 2024. Responsible AI pattern catalogue: A collection of best practices for AI governance and engineering. Comput. Surveys 56, 7 (2024), 1–35
work page 2024
-
[79]
Robyn R. Lutz. 2000. Software engineering for safety: a roadmap. In Proceedings of the Conference on The Future of Software Engineering (Limerick, Ireland) (ICSE ’00). Association for Computing Machinery, New York, NY, USA, 213–226
work page 2000
-
[80]
Silverio Martínez-Fernández, Justus Bogner, Xavier Franch, Marc Oriol, Julien Siebert, Adam Trendowicz, Anna Maria Vollmer, and Stefan Wagner
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.