A 71.2-μW Speech Recognition Accelerator with Recurrent Spiking Neural Network
Pith reviewed 2026-05-22 23:33 UTC · model grok-4.3
The pith
A recurrent spiking neural network accelerator consumes 71.2 μW for real-time speech recognition on edge devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
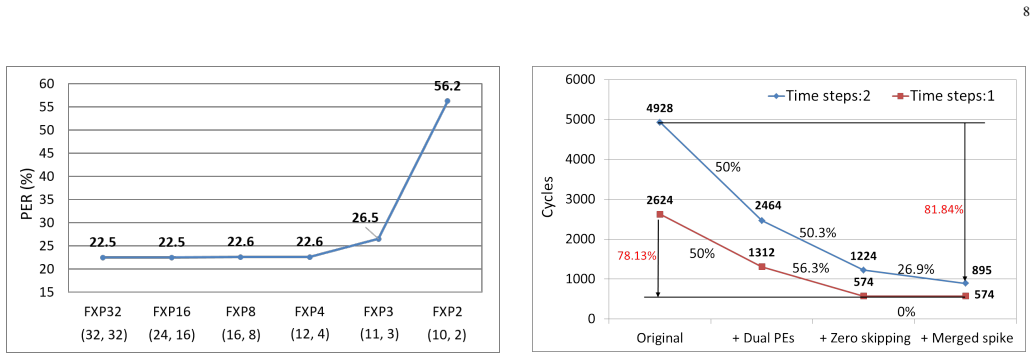
The authors designed a recurrent spiking neural network accelerator that exploits sparsity through mixed-level pruning, zero-skipping, merged spike techniques, parallel time-step execution for weight sharing, and input broadcasting to skip zero computations. After reducing the model from 2.79 MB to 0.1 MB via pruning and 4-bit fixed-point quantization, the hardware achieves 13.86 MMAC/S complexity. On TSMC 28-nm process the chip operates in real time at 100 kHz consuming 71.2 μW, exceeding prior designs, and reaches 28.41 TOPS/W energy efficiency and 1903.11 GOPS/mm² area efficiency when clocked at 500 MHz.
What carries the argument
Parallel time-step execution that resolves inter-time-step dependencies while enabling weight buffer power savings through sharing, paired with an input broadcasting scheme that removes zero computations arising from sparse spike activity.
Load-bearing premise
The pruned and 4-bit quantized recurrent spiking neural network retains sufficient speech recognition accuracy after a 96.42 percent size reduction.
What would settle it
A side-by-side accuracy measurement on a standard speech dataset showing that the compressed model falls below the minimum word-error-rate tolerance required by the target application.
Figures















read the original abstract
This paper introduces a 71.2-$\mu$W speech recognition accelerator designed for edge devices' real-time applications, emphasizing an ultra low power design. Achieved through algorithm and hardware co-optimizations, we propose a compact recurrent spiking neural network with two recurrent layers, one fully connected layer, and a low time step (1 or 2). The 2.79-MB model undergoes pruning and 4-bit fixed-point quantization, shrinking it by 96.42\% to 0.1 MB. On the hardware front, we take advantage of \textit{mixed-level pruning}, \textit{zero-skipping} and \textit{merged spike} techniques, reducing complexity by 90.49\% to 13.86 MMAC/S. The \textit{parallel time-step execution} addresses inter-time-step data dependencies and enables weight buffer power savings through weight sharing. Capitalizing on the sparse spike activity, an input broadcasting scheme eliminates zero computations, further saving power. Implemented on the TSMC 28-nm process, the design operates in real time at 100 kHz, consuming 71.2 $\mu$W, surpassing state-of-the-art designs. At 500 MHz, it has 28.41 TOPS/W and 1903.11 GOPS/mm$^2$ in energy and area efficiency, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the design and ASIC implementation of a 71.2 μW speech recognition accelerator in TSMC 28-nm CMOS. It is based on a compact recurrent spiking neural network (two recurrent layers plus one fully connected layer, time step of 1 or 2) that is reduced from 2.79 MB to 0.1 MB (96.42% reduction) via mixed-level pruning and 4-bit fixed-point quantization. Hardware optimizations include zero-skipping, merged-spike encoding, input broadcasting for sparse activity, and parallel time-step execution to enable weight sharing; the design reports real-time operation at 100 kHz with 13.86 MMAC/S complexity and peak efficiencies of 28.41 TOPS/W and 1903.11 GOPS/mm² at 500 MHz.
Significance. A verified physical implementation with measured power and area numbers on a standard process node would be a useful data point for ultra-low-power edge accelerators if the pruned/quantized recurrent SNN retains usable accuracy on a speech dataset. The co-design elements (mixed-level pruning, merged spikes, parallel time-step execution) and explicit exploitation of spike sparsity are concrete strengths that could be cited in follow-on work.
major comments (2)
- [Abstract] Abstract: the central performance claims (71.2 μW at 100 kHz, 28.41 TOPS/W, surpassing SOTA) rest on the assumption that the recurrent SNN after 96.42% pruning and 4-bit quantization still delivers usable speech-recognition accuracy, yet no accuracy figures, baseline comparisons, dataset results, or error analysis are supplied. This omission is load-bearing for any claim of practical utility.
- [Abstract / Results] The manuscript states a 90.49% complexity reduction to 13.86 MMAC/S but does not report the corresponding accuracy retention (or degradation) relative to the unpruned 2.79 MB model; without this datum the efficiency numbers cannot be interpreted as a complete system result.
minor comments (2)
- [Abstract] Abstract: the statement 'surpassing state-of-the-art designs' is not accompanied by a quantitative comparison table or cited references.
- Notation: 'MMAC/S' and 'TOPS/W' are used without an explicit definition of the MAC counting convention (e.g., whether multiply-accumulate or multiply-only) in the efficiency section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the manuscript to incorporate the requested accuracy information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims (71.2 μW at 100 kHz, 28.41 TOPS/W, surpassing SOTA) rest on the assumption that the recurrent SNN after 96.42% pruning and 4-bit quantization still delivers usable speech-recognition accuracy, yet no accuracy figures, baseline comparisons, dataset results, or error analysis are supplied. This omission is load-bearing for any claim of practical utility.
Authors: We agree that accuracy metrics are required to substantiate claims of practical utility. We will revise the abstract to report the speech-recognition accuracy of the pruned and quantized model, include baseline comparisons to the unpruned model, specify the dataset, and add a brief error analysis. revision: yes
-
Referee: [Abstract / Results] The manuscript states a 90.49% complexity reduction to 13.86 MMAC/S but does not report the corresponding accuracy retention (or degradation) relative to the unpruned 2.79 MB model; without this datum the efficiency numbers cannot be interpreted as a complete system result.
Authors: We acknowledge the need for this comparison. We will add explicit accuracy retention figures (before vs. after the 96.42% compression) to both the abstract and results section so that the reported efficiency can be interpreted in context. revision: yes
Circularity Check
No circularity; claims rest on ASIC measurements
full rationale
The paper reports a physical TSMC 28-nm ASIC implementation of a pruned recurrent SNN accelerator, with all performance numbers (71.2 μW at 100 kHz, 28.41 TOPS/W, 1903.11 GOPS/mm²) obtained from post-layout measurements rather than any mathematical derivation or fitted prediction. No equations, self-citations of uniqueness theorems, ansatzes, or self-definitional reductions appear in the abstract or described methodology; the pruning/quantization steps are presented as standard co-optimization techniques whose results are validated by the fabricated hardware, not by construction from the inputs themselves.
Axiom & Free-Parameter Ledger
free parameters (3)
- time step count (1 or 2)
- 4-bit fixed-point precision
- mixed-level pruning ratio
axioms (1)
- domain assumption Standard TSMC 28nm CMOS process parameters for power and area estimation
Reference graph
Works this paper leans on
-
[1]
Automatic speech recognition: systematic literature review,
S. Alharbi et al. , “Automatic speech recognition: systematic literature review,”IEEE Access, vol. 9, pp. 131 858–131 876, 2021
work page 2021
-
[2]
A fully integrated 1.7mW attention-based automatic speech recognition processor,
Y .-L. Liou et al., “A fully integrated 1.7mW attention-based automatic speech recognition processor,” IEEE Transactions on Circuits and Sys- tems II: Express Briefs , vol. 69, no. 10, pp. 4178–4182, 2022
work page 2022
-
[3]
D. Kadetotad et al., “An 8.93 TOPS/W LSTM recurrent neural network accelerator featuring hierarchical coarse-grain sparsity for on-device speech recognition,” IEEE Journal of Solid-State Circuits, vol. 55, no. 7, pp. 1877–1887, 2020
work page 2020
-
[4]
T. Tambe et al., “A 16-nm SoC for noise-robust speech and NLP edge AI inference with bayesian sound source separation and attention-based DNNs,” IEEE Journal of Solid-State Circuits , vol. 58, no. 2, pp. 569– 581, 2023
work page 2023
-
[5]
Attention-based models for speech recognition,
J. K. Chorowski et al., “Attention-based models for speech recognition,” Advances in Neural Information Processing Systems , vol. 28, 2015
work page 2015
-
[6]
Listen, attend and spell: a neural network for large vocabulary conversational speech recognition,
W. Chan et al. , “Listen, attend and spell: a neural network for large vocabulary conversational speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 4960–4964
work page 2016
-
[7]
A. Vaswani et al. , “Attention is all you need,” in Advances in Neural Information Processing Systems , 2017
work page 2017
-
[8]
Streaming automatic speech recognition with the transformer model,
N. Moritz, T. Hori, and J. Le, “Streaming automatic speech recognition with the transformer model,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2020, pp. 6074– 6078
work page 2020
-
[9]
Interactive feature fusion for end-to-end noise-robust speech recognition,
Y . Hu et al. , “Interactive feature fusion for end-to-end noise-robust speech recognition,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2022, pp. 6292–6296
work page 2022
-
[10]
S. Zheng et al. , “An ultra-low power binarized convolutional neural network-based speech recognition processor with on-chip self-learning,” IEEE Transactions on Circuits and Systems I: Regular Papers , vol. 66, no. 12, pp. 4648–4661, 2019
work page 2019
-
[11]
Deep learning incorporating biologically inspired neural dynamics and in-memory computing,
S. Wozniak et al. , “Deep learning incorporating biologically inspired neural dynamics and in-memory computing,” Nature Machine Intelli- gence, vol. 2, no. 6, pp. 325–336, 2020
work page 2020
-
[12]
A tandem learning rule for effective training and rapid inference of deep spiking neural networks,
J. Wu et al. , “A tandem learning rule for effective training and rapid inference of deep spiking neural networks,” IEEE Transactions on Neural Networks and Learning Systems , vol. 34, no. 1, pp. 446–460, 2023
work page 2023
-
[13]
Input-aware dynamic timestep spiking neural networks for efficient in-memory computing,
Y . Li et al. , “Input-aware dynamic timestep spiking neural networks for efficient in-memory computing,” arXiv preprint arXiv:2305.17346 , 2023
-
[14]
Deep spiking neural networks for large vocabulary automatic speech recognition,
J. Wu et al. , “Deep spiking neural networks for large vocabulary automatic speech recognition,” Frontiers in Neuroscience, vol. 14, 2020
work page 2020
-
[15]
Spiking neural networks with improved inherent recurrence dynamics for sequential learning,
W. Ponghiran and K. Roy, “Spiking neural networks with improved inherent recurrence dynamics for sequential learning,” in Proceedings of the AAAI Conference on Artificial Intelligence , vol. 36, no. 7, 2022, pp. 8001–8008
work page 2022
-
[16]
Towards energy-efficient, low-latency and accurate spiking LSTMs,
G. Datta et al. , “Towards energy-efficient, low-latency and accurate spiking LSTMs,” arXiv preprint arXiv:2210.12613 , 2022
-
[17]
Sparse compressed spiking neural network accelerator for object detection,
H.-H. Lien and T.-S. Chang, “Sparse compressed spiking neural network accelerator for object detection,” IEEE Transactions on Circuits and Systems I: Regular Papers , vol. 69, no. 5, pp. 2060–2069, 2022
work page 2060
-
[18]
SpinalFlow: an architecture and dataflow tailored for spiking neural networks,
S. Narayanan et al., “SpinalFlow: an architecture and dataflow tailored for spiking neural networks,” in ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA) , 2020, pp. 349–362
work page 2020
-
[19]
A 24.3µJ/image SNN accelerator for DVS-gesture with WS-LOS dataflow and sparse methods,
L. Kang et al., “A 24.3µJ/image SNN accelerator for DVS-gesture with WS-LOS dataflow and sparse methods,” IEEE Transactions on Circuits and Systems II: Express Briefs , doi: 10.1109/TCSII.2023.3282589
-
[20]
Training spiking neural networks using lessons from deep learning,
J. K. Eshraghian et al., “Training spiking neural networks using lessons from deep learning,” Proceedings of the IEEE, vol. 111, no. 9, pp. 1016– 1054, 2023
work page 2023
-
[21]
N. Rathi and K. Roy, “DIET-SNN: a low-latency spiking neural network with direct input encoding and leakage and threshold optimization,” IEEE Transactions on Neural Networks and Learning Systems , vol. 34, no. 6, pp. 3174–3182, 2023
work page 2023
-
[22]
Temporal efficient training of spiking neural network via gradient re-weighting,
S. Deng et al. , “Temporal efficient training of spiking neural network via gradient re-weighting,” in International Conference on Learning Representations (ICLR), 2022. 11
work page 2022
-
[23]
Efficient processing of deep neural networks: a tutorial and survey,
V . Sze et al. , “Efficient processing of deep neural networks: a tutorial and survey,” Proceedings of the IEEE , vol. 105, no. 12, pp. 2295–2329, 2017
work page 2017
-
[24]
Rethinking the value of network pruning,
Z. Liu et al., “Rethinking the value of network pruning,” inInternational Conference on Learning Representations (ICLR) , 2019
work page 2019
-
[25]
Towards model compression for deep learning based speech enhancement,
K. Tan and D. Wang, “Towards model compression for deep learning based speech enhancement,” IEEE/ACM Transactions on Audio, Speech, and Language Processing , vol. 29, pp. 1785–1794, 2021
work page 2021
-
[26]
Quantizing deep convolutional networks for efficient inference: A whitepaper
R. Krishnamoorthi, “Quantizing deep convolutional networks for effi- cient inference: a whitepaper,” arXiv preprint arXiv:1806.08342 , 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
C.-Y . Lin and B.-C. Lai, “Supporting compressed-sparse activations and weights on SIMD-like accelerator for sparse convolutional neural networks,” in Asia and South Pacific Design Automation Conference (ASP-DAC), 2018, pp. 105–110
work page 2018
-
[28]
A novel zero weight/activation-aware hardware architecture of convolutional neural network,
D. Kim, J. Ahn, and S. Yoo, “A novel zero weight/activation-aware hardware architecture of convolutional neural network,” in Design, Automation & Test in Europe Conference & Exhibition (DATE) , 2017, pp. 1462–1467
work page 2017
-
[29]
EIE: efficient inference engine on compressed deep neural network,
S. Han et al. , “EIE: efficient inference engine on compressed deep neural network,” in ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA) , 2016, pp. 243–254
work page 2016
-
[30]
Cnvlutin: ineffectual-neuron-free deep neural net- work computing,
J. Albericio et al. , “Cnvlutin: ineffectual-neuron-free deep neural net- work computing,” in ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA) , 2016, pp. 1–13
work page 2016
-
[31]
DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech DISC 1-1.1,
J. S. Garofolo et al. , “DARPA TIMIT acoustic-phonetic continous speech corpus CD-ROM. NIST speech DISC 1-1.1,” NASA STI/Recon technical report n , vol. 93, p. 27403, 1993
work page 1993
-
[32]
The PyTorch-Kaldi speech recognition toolkit,
M. Ravanelli, T. Parcollet, and Y . Bengio, “The PyTorch-Kaldi speech recognition toolkit,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , 2019, pp. 6465–6469. Chih-Chyau Yang received the B.S. degree in electrical engineering from National Cheng-Kung University (NCKU), Taiwan in 1996, and the M.S. degree in electro...
work page 2019
-
[33]
He is currently a principal engineer at Taiwan Semiconductor Research Institute (TSRI), Taiwan. His research interests include VLSI design, com- puter architecture, and platform-based SoC design methodologies. Tian-Sheuan Chang (S’93–M’06–SM’07) received the B.S., M.S., and Ph.D. degrees in electronic engineering from National Chiao-Tung University (NCTU)...
work page 1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.