V-MAGE: A Game Evaluation Framework for Assessing Vision-Centric Capabilities in Multimodal Large Language Models
Pith reviewed 2026-05-22 20:03 UTC · model grok-4.3
The pith
Leading multimodal AI models match humans on simple visual tasks but lag far behind in complex interactive scenarios that demand reasoning and orchestration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
V-MAGE is a game evaluation framework designed to assess vision-centric capabilities in MLLMs through interactive, continuous-space video game scenarios. Benchmarking reveals that while leading models approach human-level performance in simple tasks, their performance drops significantly in complex scenarios requiring advanced reasoning and task orchestration. This highlights fundamental limitations in current MLLMs' ability to perform vision-grounded, interactive frame-by-frame control in simulated continuous-time environments.
What carries the argument
The V-MAGE framework, consisting of five video games with over 30 evaluation scenarios in free-form visually complex environments, evaluated using a dynamic ELO-based ranking system to compare models across different difficulties.
If this is right
- Models need targeted advances in dynamic perception to close gaps in interactive control.
- The identified drops in complex scenarios point to limits in current reasoning for task orchestration.
- V-MAGE supplies a structured way to track improvements in vision-grounded decision making over time.
- Persistent gaps underscore challenges in frame-by-frame visual processing for continuous environments.
Where Pith is reading between the lines
- Similar game setups could help test how these models might handle real-world tasks like robot navigation or object manipulation.
- Extending the scenarios to new games might uncover additional weaknesses in perception under varied conditions.
- Training approaches focused on sequential visual feedback could help reduce the observed performance differences.
Load-bearing premise
The chosen video games and scenarios in free-form continuous-space environments accurately reflect the dynamic perception and interactive reasoning abilities that matter for real-world applications.
What would settle it
If leading models achieve comparable results to humans on a different set of real-world interactive visual control tasks that do not involve the selected games, this would indicate the performance gaps may not generalize beyond the chosen scenarios.
Figures






















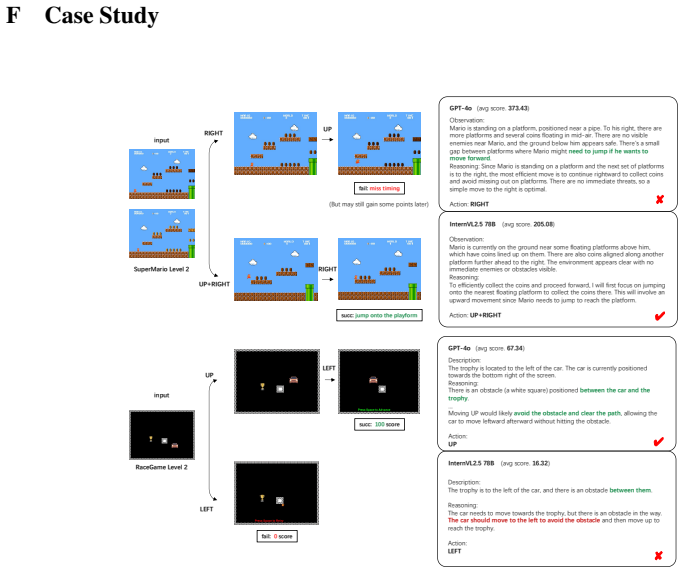





read the original abstract
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in visual-text processing. However, existing static image-text benchmarks are insufficient for evaluating their dynamic perception and interactive reasoning abilities. We introduce Vision-centric Multiple Abilities Game Evaluation (V-MAGE), a novel game-based evaluation framework designed to systematically assess MLLMs' visual reasoning in interactive, continuous-space environments. V-MAGE features five distinct video games comprising over 30 carefully constructed evaluation scenarios. These scenarios are set in free-form, visually complex environments that require models to interpret dynamic game states and make decisions based solely on visual input, thereby closely reflecting the conditions encountered by human players. To ensure robust and interpretable comparisons across models, V-MAGE employs a dynamic ELO-based ranking system that accounts for varying difficulty levels and task diversity. Benchmarking state-of-the-art MLLMs against human baselines reveals that while leading models approach human-level performance in simple tasks, their performance drops significantly in complex scenarios requiring advanced reasoning and task orchestration. This persistent performance gap highlights fundamental limitations in current MLLMs' ability to perform vision-grounded, interactive frame-by-frame control in simulated continuous-time environments. Through extensive analyses, we demonstrate the utility of V-MAGE in uncovering these limitations and providing actionable insights for improving the visual and reasoning capabilities of MLLMs in dynamic, interactive settings. Code is publicly available at https://github.com/CSU-JPG/V-MAGE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces V-MAGE, a game-based evaluation framework using five video games and over 30 scenarios in free-form continuous-space environments to assess vision-centric capabilities of MLLMs. It benchmarks state-of-the-art models against human baselines with a dynamic ELO ranking system and claims that leading MLLMs approach human-level performance on simple tasks but exhibit significant drops in complex scenarios requiring advanced reasoning and task orchestration, highlighting limitations in vision-grounded interactive frame-by-frame control.
Significance. If the performance-gap results hold under rigorous controls, this work is significant for providing a dynamic benchmark that addresses gaps in static image-text evaluations for MLLMs. The public code release supports reproducibility, and the ELO-based system offers a principled way to handle task diversity. The empirical findings with external human baselines can inform targeted improvements in interactive visual reasoning.
major comments (1)
- Abstract: the central claim of significant performance drops in complex scenarios would benefit from explicit reporting of error bars, statistical significance tests, or details on scenario construction and prompting controls to confirm the gap is not an artifact of the evaluation protocol.
minor comments (2)
- Abstract: the description of 'free-form, visually complex environments' could include one concrete example of a scenario to illustrate the dynamic perception requirements.
- The ELO ranking description should clarify how difficulty levels are normalized across the five games to ensure interpretable cross-model comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for minor revision. We address the major comment below.
read point-by-point responses
-
Referee: Abstract: the central claim of significant performance drops in complex scenarios would benefit from explicit reporting of error bars, statistical significance tests, or details on scenario construction and prompting controls to confirm the gap is not an artifact of the evaluation protocol.
Authors: We agree that strengthening the central claim with additional statistical rigor and methodological transparency is beneficial. In the revised manuscript, we will add error bars to the key performance figures in the results section, report statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the differences between simple and complex scenarios, and expand Section 3 with explicit details on scenario construction criteria and prompting controls. These changes will be briefly referenced in the abstract to support the reported performance gaps. revision: yes
Circularity Check
No significant circularity; empirical benchmark only
full rationale
This is an empirical evaluation paper that introduces game-based scenarios, applies a standard dynamic ELO ranking system, and reports performance gaps against independent human baselines. No load-bearing derivations, fitted-parameter predictions, self-definitional steps, or self-citation chains appear in the abstract or described framework. The central claims rest on external measurements rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Selected video games capture dynamic perception and interactive reasoning abilities relevant to real-world use cases
Forward citations
Cited by 5 Pith papers
-
Orak: A Foundational Benchmark for Training and Evaluating LLM Agents on Diverse Video Games
Orak is a foundational benchmark providing training data, interfaces, and evaluation tools for LLM agents across diverse video game genres.
-
SPIKE: An Adaptive Dual Controller Framework for Cost-Efficient Long-Horizon Game Agents
SPIKE dual-controller framework raises success rates 5-9 points and cuts tokens 55% in StarDojo agents by reusing strategic plans across stable segments and escalating only at detected events.
-
GameWorld: Towards Standardized and Verifiable Evaluation of Multimodal Game Agents
GameWorld is a new benchmark providing standardized interfaces, 34 games, 170 tasks, and verifiable outcome metrics to evaluate multimodal large language model agents in video game environments.
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
The paper organizes research on generalist game AI into Dataset, Model, Harness, and Benchmark pillars and charts a five-level progression from single-game mastery to agents that create and live inside game multiverses.
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
This work traces four eras of generalist game players across dataset, model, harness, and benchmark pillars and charts a five-level roadmap ending in agents that create and evolve within game multiverses.
Reference graph
Works this paper leans on
-
[1]
Mario can jump (actions involving UP) only if he is on the ground or on a solid surface like a platform or pipe
-
[2]
You can make six types of actions to control Mario:
If Mario is in mid-air, he can only use LEFT or RIGHT to adjust his position, or NONE to continue falling or moving with momentum. You can make six types of actions to control Mario:
-
[3]
UP: Makes Mario jump upward (only available when Mario is on the ground or solid platforms)
-
[4]
LEFT: Moves Mario left
-
[5]
RIGHT: Moves Mario right
-
[6]
UP+LEFT: Makes Mario jump upward and left simultaneously (only available when on the ground or solid platforms)
-
[7]
UP+RIGHT: Makes Mario jump upward and right simultaneously (only available when on the ground or solid platforms)
-
[8]
Note that DOWN has no effect and cannot be used, so you should never attempt to use it
NONE: No new action is performed; Mario continues to be affected by gravity (if airborne) or momentum from previous movements. Note that DOWN has no effect and cannot be used, so you should never attempt to use it. You should think step by step and respond with the following format, remember to respond with plain text without any special characters or sym...
-
[9]
UP: Makes the bird rise a bit of distance
-
[10]
DOWN: Makes the bird fall a bit of distance
-
[11]
KEEP: The bird will keep the current position. You should think step by step and response with the following format, remember to response the plain text without any special characters or symbols, DO NOT response in markdown or Latex format. Observation: ... (describe the current position of the bird and the gap.) Reasoning: ... (think step by step and exp...
-
[13]
NONE: The bird will falls a bit due to gravity
-
[14]
KEEP: The bird will keep the current position. You should think step by step and response with the following format, remember to response the plain text without any special characters or symbols, DO NOT response in markdown or Latex format. Response: Observation: ... (describe the current position of the bird and the gap.) Reasoning: ... (think step by st...
-
[15]
UP: Makes the bird rise
-
[16]
NONE: The bird may fall a bit due to gravity. You should think step by step and response with the following format, remember to response the plain text without any special characters or symbols, DO NOT response in markdown or Latex format. Response: Observation: ... (describe the current position of the bird and the gap.) Reasoning: ... (think step by ste...
-
[17]
LEFTUP: Moves the left paddle up
-
[18]
LEFTDOWN: Moves the left paddle down
-
[19]
RIGHTUP: Moves the right paddle up
-
[20]
RIGHTDOWN: Moves the right paddle down
-
[21]
NONE: No action. You should think step by step and respond with the following format, remember to respond with plain text without any special characters or symbols, DO NOT respond in markdown or Latex format. Observation: ... (describe the current positions of both paddles, the ball, and the ball's movement trajectory.) Reasoning: ... (think step by step ...
-
[22]
Use JUMP to jump over red spikes on the ground
-
[23]
Use SLIDE to duck and kick green enemies to eliminate them
-
[24]
Use LEFT or RIGHT to move around obstacles, such as purple walls or spikes
-
[25]
Use RISE to return to a normal running position after a SLIDE
-
[26]
You can make six types of actions to control the character:
NONE is a valid action to maintain the current state if no immediate action is needed. You can make six types of actions to control the character:
-
[27]
JUMP: Makes the character jump upward, useful for avoiding ground obstacles like red spikes
-
[28]
LEFT: Moves the character to the left
-
[29]
RIGHT: Moves the character to the right
-
[30]
SLIDE: Makes the character duck and slide forward, useful for dealing with green enemies or passing under certain obstacles
-
[31]
RISE: Returns the character to a normal running position after sliding
-
[32]
NONE: No new action is performed; the character maintains their current trajectory. You should think step by step and respond with the following format, remember to respond with plain text without any special characters or symbols, DO NOT respond in markdown or Latex or any other format. Response: Observation: ... (Describe the character's current positio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.